Flink cdc +doris生产遇到的问题汇总-持续更新
问题:
我有个表主键是字符串类型 然后cdc去读取的时候 自己split了很久 checkpoint一直显示执行中,我看日志打印是info :
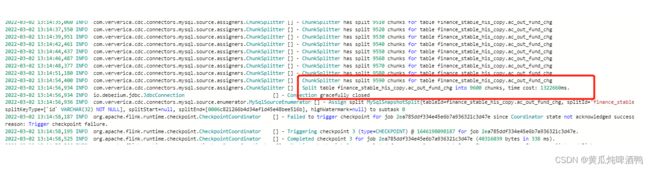
checkpoint一直卡在那里
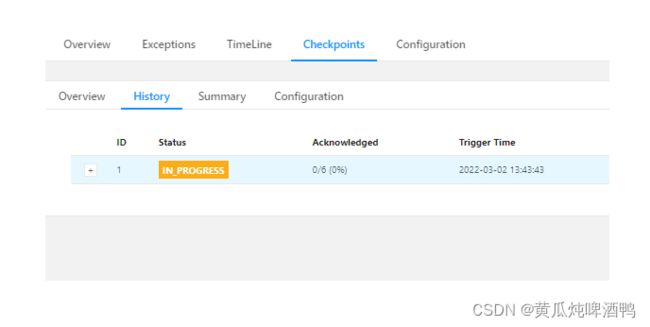
程序一直等待中:

原因:倒全量数据 chunlSplitter 花费了太长时间,这个在社区提问看有没有解决方案。
知识备份:
阿里云Flink CDC文档地址:
MySQL的CDC源表 - 实时计算Flink版 - 阿里云
cdc参数:
WITH参数
| 参数 | 说明 | 是否必填 | 数据类型 | 备注 |
|---|---|---|---|---|
| connector | 源表类型。 | 是 | STRING | 可以填写为mysql-cdc或者mysql,二者等价。 |
| hostname | MySQL数据库的IP地址或者Hostname。 | 是 | STRING | 无。 |
| username | MySQL数据库服务的用户名。 | 是 | STRING | 无。 |
| password | MySQL数据库服务的密码。 | 是 | STRING | 无。 |
| database-name | MySQL数据库名称。 | 是 | STRING | 数据库名称支持正则表达式以读取多个数据库的数据。 |
| table-name | MySQL表名。 | 是 | STRING | 表名支持正则表达式以读取多个表的数据。 |
| port | MySQL数据库服务的端口号。 | 否 | INTEGER | 默认值为3306。 |
| server-id | 数据库客户端的一个数字 ID。 | 否 | STRING | 该ID必须是MySQL集群中全局唯一的。建议针对同一个数据库的每个作业都设置一个不同的ID。默认会随机生成一个5400~6400的值。 该参数也支持ID范围的格式,例如5400-5408。在开启增量读取模式时支持多并发读取,此时推荐设定为ID范围,使得每个并发使用不同的ID。 |
| scan.incremental.snapshot.enabled | 是否开启增量快照。 | 否 | BOOLEAN | 默认开启增量快照。增量快照是一种读取全量数据快照的新机制。与旧的快照读取相比,增量快照有很多优点,包括:
如果您希望Source支持并发读取,每个并发的Reader需要有一个唯一的服务器ID,因此server-id必须是5400-6400这样的范围,并且范围必须大于等于并发数。 |
| scan.incremental.snapshot.chunk.size | 表的chunk的大小(行数)。 | 否 | Integer | 默认值为8096。当开启增量快照读取时,表会被切分成多个chunk读取。在读完chunk的数据之前,chunk的数据会先缓存在内存中,因此chunk 太大,可能导致内存OOM。chunk越小,故障恢复的粒度也越小,但也会降低吞吐。 |
| scan.snapshot.fetch.size | 当读取表的全量数据时,每次最多拉取的记录数。 | 否 | Integer | 默认值为1024。 |
| scan.startup.mode | 消费数据时的启动模式。 | 否 | STRING | 参数取值如下:
|
| server-time-zone | 数据库在使用的会话时区。 | 否 | STRING | 例如Asia/Shanghai,该参数控制了MySQL中的TIMESTAMP类型如何转成STRING类型。更多信息请参见Debezium时间类型。 |
| debezium.min.row.count.to.stream.results | 当表的条数大于该值时,会使用分批读取模式。 | 否 | INTEGER | 默认值为1000。Flink采用以下方式读取MySQL源表数据:
|
| connect.timeout | 在尝试连接MySQL数据库服务器之后,连接器在超时之前应该等待的最大时间。 | 否 | Duration | 默认值为30秒。 |
版本:
Flink版本 1.13
Flink cdc版本 2.1.1
场景说明:
使用flink cdc stream api 读取mysql整库数据直接写入doris
大概100G数据量,大概几十个表,大表小表,字段多,字段少,单个字段类型复杂等等情况都包含了。
出现情况:
任务运行一段时间之后挂掉,出现问题:
2022-02-11 18:33:59,461 INFO com.ververica.cdc.connectors.mysql.source.enumerator.MySqlSourceEnumerator [] - Assign split MySqlSnapshotSplit{tableId=plateform_stable_copy.order_address, splitId='plateform_stable_copy.order_address:196', splitKeyType=[`id` INT NOT NULL], splitStart=[17079248], splitEnd=[17165910], highWatermark=null} to subtask 0
2022-02-11 18:33:59,976 INFO com.ververica.cdc.connectors.mysql.source.enumerator.MySqlSourceEnumerator [] - The enumerator receives finished split offsets FinishedSnapshotSplitsReportEvent{finishedOffsets={plateform_stable_copy.order_address:196={ts_sec=0, file=mysql-bin.006361, pos=441499143, gtids=bcd981b2-d261-11e9-9c67-00163e068674:1-18305222, row=0, event=0}}} from subtask 0.
2022-02-11 18:33:59,977 INFO com.ververica.cdc.connectors.mysql.source.enumerator.MySqlSourceEnumerator [] - Assign split MySqlSnapshotSplit{tableId=plateform_stable_copy.order_address, splitId='plateform_stable_copy.order_address:197', splitKeyType=[`id` INT NOT NULL], splitStart=[17165910], splitEnd=[17252572], highWatermark=null} to subtask 0
2022-02-11 18:34:00,079 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Triggering checkpoint 57 (type=CHECKPOINT) @ 1644575640072 for job 01f4e4416ccf488091611165e921b83b.
2022-02-11 18:34:00,760 ERROR org.apache.flink.runtime.util.FatalExitExceptionHandler [] - FATAL: Thread 'SourceCoordinator-Source: dataSourceStream -> processStream' produced an uncaught exception. Stopping the process...
java.lang.Error: This indicates that a fatal error has happened and caused the coordinator executor thread to exit. Check the earlier logsto see the root cause of the problem.
at org.apache.flink.runtime.source.coordinator.SourceCoordinatorProvider$CoordinatorExecutorThreadFactory.newThread(SourceCoordinatorProvider.java:114) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at java.util.concurrent.ThreadPoolExecutor$Worker.(ThreadPoolExecutor.java:619) ~[?:1.8.0_181]
at java.util.concurrent.ThreadPoolExecutor.addWorker(ThreadPoolExecutor.java:932) ~[?:1.8.0_181]
at java.util.concurrent.ThreadPoolExecutor.processWorkerExit(ThreadPoolExecutor.java:1025) ~[?:1.8.0_181]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1167) ~[?:1.8.0_181]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_181]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_181]
2022-02-11 18:34:00,768 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Trying to recover from a global failure.
java.lang.Error: This indicates that a fatal error has happened and caused the coordinator executor thread to exit. Check the earlier logsto see the root cause of the problem.
at org.apache.flink.runtime.source.coordinator.SourceCoordinatorProvider$CoordinatorExecutorThreadFactory.newThread(SourceCoordinatorProvider.java:114) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at java.util.concurrent.ThreadPoolExecutor$Worker.(ThreadPoolExecutor.java:619) ~[?:1.8.0_181]
at java.util.concurrent.ThreadPoolExecutor.addWorker(ThreadPoolExecutor.java:932) ~[?:1.8.0_181]
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1367) ~[?:1.8.0_181]
at java.util.concurrent.Executors$DelegatedExecutorService.execute(Executors.java:668) ~[?:1.8.0_181]
at org.apache.flink.runtime.source.coordinator.SourceCoordinator.runInEventLoop(SourceCoordinator.java:312) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.source.coordinator.SourceCoordinator.handleEventFromOperator(SourceCoordinator.java:156) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator.lambda$handleEventFromOperator$0(RecreateOnResetOperatorCoordinator.java:82) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator$DeferrableCoordinator.applyCall(RecreateOnResetOperatorCoordinator.java:291) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator.handleEventFromOperator(RecreateOnResetOperatorCoordinator.java:81) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.operators.coordination.OperatorCoordinatorHolder.handleEventFromOperator(OperatorCoordinatorHolder.java:209) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.scheduler.DefaultOperatorCoordinatorHandler.deliverOperatorEventToCoordinator(DefaultOperatorCoordinatorHandler.java:130) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.scheduler.SchedulerBase.deliverOperatorEventToCoordinator(SchedulerBase.java:997) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.jobmaster.JobMaster.sendOperatorEventToCoordinator(JobMaster.java:548) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_181]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_181]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_181]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_181]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:305) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:212) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:77) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:158) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21) [flink-dist_2.11-1.13.0.jar:1.13.0]
at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21) [flink-dist_2.11-1.13.0.jar:1.13.0]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170) [flink-dist_2.11-1.13.0.jar:1.13.0]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) [flink-dist_2.11-1.13.0.jar:1.13.0]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.actor.Actor$class.aroundReceive(Actor.scala:517) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.actor.ActorCell.invoke(ActorCell.scala:561) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.dispatch.Mailbox.run(Mailbox.scala:225) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.dispatch.Mailbox.exec(Mailbox.scala:235) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) [flink-dist_2.11-1.13.0.jar:1.13.0]
at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107) [flink-dist_2.11-1.13.0.jar:1.13.0]
2022-02-11 18:34:00,788 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Shutting YarnJobClusterEntrypoint down with application status UNKNOWN. Diagnostics Cluster entrypoint has been closed externally..
2022-02-11 18:34:00,789 INFO org.apache.flink.runtime.jobmaster.MiniDispatcherRestEndpoint [] - Shutting down rest endpoint.
2022-02-11 18:34:00,791 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job dev-SingleInstanceData2doris (01f4e4416ccf488091611165e921b83b) switched from state RUNNING to RESTARTING.
2022-02-11 18:34:00,795 INFO org.apache.flink.runtime.blob.BlobServer [] - Stopped BLOB server at 0.0.0.0:12287
2022-02-11 18:34:00,800 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Trying to recover from a global failure.
java.lang.Error: This indicates that a fatal error has happened and caused the coordinator executor thread to exit. Check the earlier logsto see the root cause of the problem.
at org.apache.flink.runtime.source.coordinator.SourceCoordinatorProvider$CoordinatorExecutorThreadFactory.newThread(SourceCoordinatorProvider.java:114) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at java.util.concurrent.ThreadPoolExecutor$Worker.(ThreadPoolExecutor.java:619) ~[?:1.8.0_181]
at java.util.concurrent.ThreadPoolExecutor.addWorker(ThreadPoolExecutor.java:932) ~[?:1.8.0_181]
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1367) ~[?:1.8.0_181]
at java.util.concurrent.Executors$DelegatedExecutorService.execute(Executors.java:668) ~[?:1.8.0_181]
at org.apache.flink.runtime.source.coordinator.SourceCoordinator.runInEventLoop(SourceCoordinator.java:312) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.source.coordinator.SourceCoordinator.handleEventFromOperator(SourceCoordinator.java:156) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator.lambda$handleEventFromOperator$0(RecreateOnResetOperatorCoordinator.java:82) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator$DeferrableCoordinator.applyCall(RecreateOnResetOperatorCoordinator.java:291) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator.handleEventFromOperator(RecreateOnResetOperatorCoordinator.java:81) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.operators.coordination.OperatorCoordinatorHolder.handleEventFromOperator(OperatorCoordinatorHolder.java:209) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.scheduler.DefaultOperatorCoordinatorHandler.deliverOperatorEventToCoordinator(DefaultOperatorCoordinatorHandler.java:130) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.scheduler.SchedulerBase.deliverOperatorEventToCoordinator(SchedulerBase.java:997) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.jobmaster.JobMaster.sendOperatorEventToCoordinator(JobMaster.java:548) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_181]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_181]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_181]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_181]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:305) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:212) ~[flink-dist_2.11-1.13.0.jar:1.13.0]
at org.