tensorflow笔记(编程理论部分)
TensorFlow笔记(编程理论部分)
注:该笔记是阅读TensorFlow深度学习算法原理与编程实战第三章后做的框架梳理和部分个人见解。
Tensorflow之名由Tensor和Flow组成,Tensor意为张量,可以理解为数组;Flow意为流动,指张量数据沿着边在不同的节点间流动并发生转化。
1.1 计算图
TensorFlow中的各种操作,如加权求和,激活函数等,都被编排成一个图,称为计算图。计算图有着和流程图一样的作用。
计算图让分布式训练和部署到各种环境更为容易,这对于多个GPU或TPU上的分布式训练尤为重要。
1.1.1 计算图组成
计算图由节点(nodes)和边(edges)组成。
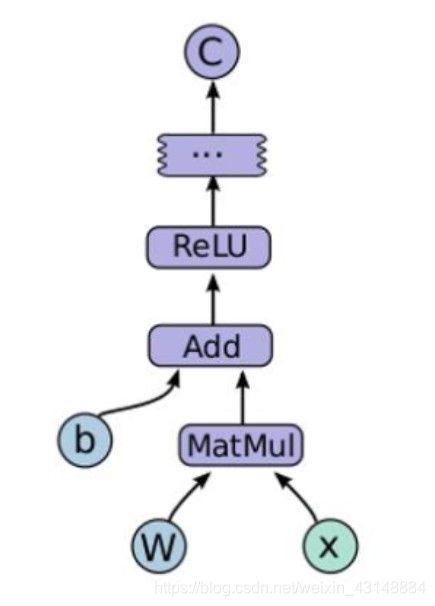
计算图中的每一个运算操作都可以视为一个节点,每一个节点可以有任意个输入和输出。节点表示操作符Operator,又称为算子,比如下图中的add运算操作可以看作一个节点。下图中,如果w和x是一个常量,为了计算方便,那么tensorflow会将常量转换成一种输出值永远固定的计算,因此w和x也被称作节点。
如果一个运算的输入取值是另一个运算的输出,那么称两个运算存在依赖关系,存在依赖关系的两个节点之间通过边连接。但是有一种特殊的边不存在数据流动,起依赖控制的作用(学艺不精,可能到后面才能懂)。
1.1.2 Graph Execution和Eager Execution模式。
在tensorflow1.x中,计算图的使用可以概括如下:
1)确定计算图的构建逻辑。
2)创建一个会话(Session)(之后会有简单介绍),指定该会话所属计算图,并在会话中执行我们所编写的计算图逻辑。
我们在tensorflow1.x中执行如下语句(我们在tensorflow2.0中使用tensorflow1.0代码,下同):
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
a=tf.constant([1.0,2.0],name="a")
b=tf.constant([3.0,4.0],name="b")
result=a+b
print(a)
print(b)
print(result)
with tf.Session() as sess:
print(sess.run(result))
得到如下结果:
Tensor(“a:0”, shape=(2,), dtype=float32)
Tensor(“b:0”, shape=(2,), dtype=float32)
Tensor(“add:0”, shape=(2,), dtype=float32)
[4. 6.]
从前三句print()函数打印情况来看,虽然在会话之前定义好计算图,但是打印出的结果不包含具体的数值而只是计算图上的节点(括号里第一项引号中的a,b和add)。会话Session中使用了run()函数执行了result,按照计算图的逻辑,它是由a和b相加而来,所以打印出了结果中第四行的具体数值[4. 6.]。
上述先定义计算图然后在会话中执行计算图的办法属于tensorflow的Graph Execution执行模式。
我们在tensorflow2.0中执行如下的代码:
import tensorflow as tf
a=tf.constant([1.0,2.0],name="a")
b=tf.constant([3.0,4.0],name="b")
result=a+b
print(a)
print(b)
print(result)
得到如下结果:
tf.Tensor([1. 2.], shape=(2,), dtype=float32)
tf.Tensor([3. 4.], shape=(2,), dtype=float32)
tf.Tensor([4. 6.], shape=(2,), dtype=float32)
此处tf.constant用于创建常量,相当于一个节点,返回的时一个Tensor。我们再次打印了a、b和result的值,可以发现这个计算过程在没有会话的情况下就被执行了,这就是Eager Execution模式。
相对于定义静态图然后到Session中执行不可变的静态图的Graph Execution模式,Eager Execution模式引入了PyTorch的动态图机制,使得模型更便于调试,模型的运行过程与代码的运行过程一致(目前还没有深刻体会)。但是Eager Excecution因为Python解释器执行得比较慢且需要的计算比较复杂,一些计算图中可以被放到GPU上运行提高速度的部分在该执行模式下失去了优化机会,程序运行的可能也比较慢。
1.1.3 Autograph执行模式
Autograph是将Python代码更自动、灵活地转换为Tensorflow的计算图,它可以将Python代码(包括控制流、print()等)转换为TensorFlow的计算图(Graph)代码。它的出现是为了平衡Eager Execution和Graph Execution两种执行模式。对于一部分以Eager Execution风格编写的代码,Autograph可以自动完成按照计算图执行这以转换过程,这样同时获得了Eager Execution执行的编写简易性和Graph Execution的性能优势。
Autograph模式需要使用函数装饰器,在Python的语法里,函数装饰器可以让函数在明确的特定运算模式下执行。通俗来说,被装饰的函数放在另一个函数内实现,这个另一个函数也被称为元函数。函数装饰器由@符号开头,后面跟着的是一个元函数。
在tensorflow2.0中,function可以直接用来装饰函数:
import tensorflow as tf
@tf.function
def simpleplus(x,y):
return tf.add(x,y)
a=tf.Variable([1.0,2.0],name="a")
b=tf.Variable([3.0,4.0],name="b")
print(simpleplus(a,b))
这段代码定义了simpleplus()函数实现两个矩阵相加,因为该函数被@function装饰,所以该函数是autograph的,它被组织成计算图。a和b是通过Variable类创建的两个变量。
1.2 张量——TensorFlow 的数据模型
1.2.1 概念
张量,可以简单地理解为不同维度的数组。n阶张量可以管理的数据是n维的数组。
张量只是引用了程序中运算结果,而不是一个真正的数组。张量保存的是运算结果的属性,而不是真正的数字。下面的例子可以作为说明:
在1.x版本下:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
a=tf.constant([1.0,2.0],name="a")
b=tf.constant([3.0,4.0],name="b")
result=a+b
print(result)
上述输出的结果是:
Tensor(“add:0”, shape=(2,), dtype=float32)
这是一个典型的张量表示,从结果可以看出,打印出来的result结果,可以说属于Graph Execution模式中的前半部分工作。不包含具体数值而只是计算图上的节点。是典型的包含result的3个属性,从a和b得到result的操作(op)、形状(shape)和数据类型(dtype)。
其中,操作(op)属性:可以被看作一个张量的名字,或者作为一个张量的唯一标识符。其命名具有一定的规则,因为计算图中的每一个节点都表示一个运算,而张量则是将节点的运算结果属性保存了下来。操作命名的格式为“node:src_output”,其中node就是节点的名称(如上述result打印结果的ad,可以在图中找到该节点,src_output表示这个张量是节点的第几个输出(编号从0开始)。
形状(shape)属性:描述了一个张量大小的信息,用来刻画张量的形状。
数据类型(dtype)属性:每一个张量都会有唯一的数据类型
在2.x版本下:
import tensorflow as tf
a=tf.constant([1.0,2.0],name="a")
b=tf.constant([3.0,4.0],name="b")
result=a+b
print(result)
上述输出的结果是:
tf.Tensor([4. 6.], shape=(2,), dtype=float32)
因为tensorflow2.0默认使用的就是Eager Execution执行模式,所以result的打印结果保留了准确的数值。
tensorflow2.0设计了一个Tensor类来保存数值结果、形状和数据类型在内的张量的信息。每一个张量都是一个tf.Tensor对象。
1.2.2 使用张量
使用张量没有特殊的使用规则,但是tensorflow会检查所有参与某个运算的张量的数据类型,当发现不匹配时就会报错。
tensorflow支持14中不同的数据类型,大体上可分为四类:整数型、实数型、布尔型和复数型。如果不指定dtype类型,tensorflow默认不带小数点的为int32,带小数点的为float32。
1.3 会话
在1.1.2的tensorflow1.x中的代码,我们可知,已经组织好的数据以及定义好的运算需要放到会话中才能正式开始执行,开发人员使用Session类创建会话,然后开始执行计算图。
tensorflow2.0直接取消了会话。那它怎么开始执行计算图呢?
那就是把需要构建的计算图整体写到一个函数里,然后使用@tf.function装饰器取装饰这个函数,由于是autograph的,在这个函数执行时计算图会被马上创建然后执行。我们看下面这个例子:
import tensorflow as tf
W=tf.Variable(tf.ones(shape=(2,2)),name="W")
b=tf.Variable(tf.zeros(shape=(2)),name="b")
@tf.function
def forward(x):
return W*x+b
out_1=forward([1,2])
out_2=forward([3,4])
print(out_1)
print(out_2)
使用AutoGraph,将forward()函数使用@tf.function装饰,在调用forward()函数时直接把每个输入作为参数传递即可:
tf.Tensor([[1. 2.][1. 2.]], shape=(2, 2), dtype=float32)
tf.Tensor([[3. 4.][3. 4.]], shape=(2, 2), dtype=float32)
1.4 Variable变量
1.4.1 创建变量
创建变量都可以使用创建类——Variable。创建变量的时候就要为其提供初始值,变量的初始值可以设置成随机数。tf.Variable(initializer,name),参数initializer是初始化参数,name是可自定义的变量名称.
weights=tf.Variable(tf.random.normal([3,4],stddev=1))
上述代码中,weights是声明的一个变量。初始化这个变量,使用random.normal()函数返回一个大小为3*4,元素均值为0(默认),标准差为1的随机数矩阵。
常用的随机数函数如下:
| 函数名称 | 随机数分布 |
|---|---|
| random.normal() | 正态分布 |
| random.poisson() | 泊松分布 |
| random.uniform() | 平均分布 |
| random.gamma() | Gamma分布 |
tensorflow变量的初始值除了可以设置为随机数,还可以设置为常数:
| 函数名称 | 功 能 |
|---|---|
| zeros() | 产生全0的数组 |
| ones() | 产生全1的数组 |
| fill() | 产生一个值为给定数字的数组 |
| constant() | 产生一个给定值的常量 |
1.4.2 变量与张量
在tensorflow使用Variable创建变量会当作一个运算来处理,这个运算的输出结果就是一个具有name、shape和type属性的张量。Variable的定义和初始化时分开的。
我们看下Variable部分的计算图,以1.4.1的代码为例,在这里Assign函数(分配、赋值)操作完成了变量的初始化。Assign这个节点的输入为tf.random.normal()函数的输出,而且输出赋给了变量Variable,这样就完成了变量初始化的过程。
之后Variable通过read操作将值提供到了外面。
然后此处在网上找到变量与张量的区别:(听说torch已经将Variable和Tensor合并了)
1、Variable是可更改的,而Tensor是不可更改的。一个直接的例子就是,Tensor不具有assign函数,而Variable含有。
2、Variable用于存储网络中的权重矩阵等变量,而Tensor更多的是中间结果等。
3、(应该是对于1.x版本)Variable是会显示分配内存空间的(既可以是内存,也可以是显存),需要初始化操作(assign一个tensor),由Session管理,可以进行存储、读取、更改等操作。相反地,诸如Const, Zeros等操作创造的Tensor,是记录在Graph中,所以没有单独的内存空间;而其他未知的由其他Tensor操作得来的Tensor则是只会在程序运行中间出现。
4、Tensor可以使用的地方,几乎都可以使用Variable。
个人感觉在tensorflow2.0因为设计了一个Tensor类来保存数值结果、形状和数据类型在内的张量的信息,和Variable没有本质区别。