python特性和属性_你可能不知道的10个Python Pandas的技巧和特性(1)
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
Pandas是一个基础库,用于分析、数据处理和数据科学。它是一个庞大的项目,有大量的选择和奥秘。
本教程将以Buzzfeed清单体介绍一些使用较少但惯用的Pandas功能,这些功能为你的代码提供更好的可读性、通用性和速度。
如果你对Python Pandas库的核心概念感到满意,那么希望你能在本文中找到一两个以前没有遇到过的技巧。(如果你刚开始学习该库,Pandas 10分钟是一个很好的开始。)
注意:本文中的示例用Pandas版本0.23.2和Python 3.66进行测试。不过,它们应该也适用于旧版本。
1. 解释器启动时的配置选项和设置
你可能曾经遇到过Pandas丰富的选项和设置系统。
在解释器启动时设置定制的Pandas选项可以节省大量生产力,尤其是在脚本环境中工作。你可以使用pd.set_option()通过Python或ipython启动文件配置你的核心内容。
选项使用点标记,如pd.set_option('display.max_colwidth', 25),这非常适用于一个嵌套的选项字典:

如果你启动一个解释器会话,将看到启动脚本中的所有内容都已执行,并且自动为你导入Pandas和选项套件:

让我们通过UCI机器学习存储库上的一些有关鲍鱼的数据来演示启动文件中设置的格式。数据将在第14行截断,浮点数的精度为4位:
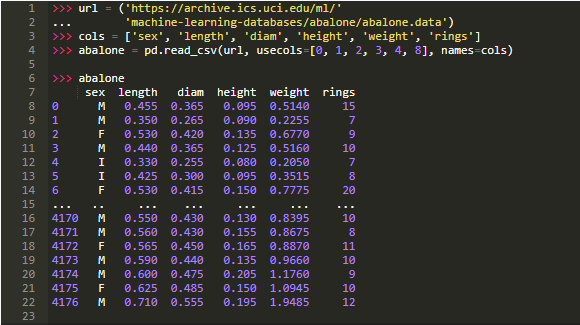
稍后还会在其他示例中出现这个数据集。
2. 用Pandas测试模块制作Toy数据结构
在Pandas测试模块中有很多隐藏的便捷功能,它们用于快速建立拟现实Series和DataFrames:

大约有30个,你可以通过调用模块对象上的dir()来查看完整的列表。这里有几个:

这些可以用于基准测试、测试断言、以及对你不太熟悉的Pandas方法的实验。
3. 利用Accessor方法
也许你听说过术语accessor,它有点像getter(虽然在Python中很少使用getter和setter)。为了我们的目的,你可以将Pandas accessor看作一个属性,作为其它方法的接口。
Pandas Series有三个:
![]()
是的,上面的定义很有意思,让我们先看几个例子,然后讨论内部结构。
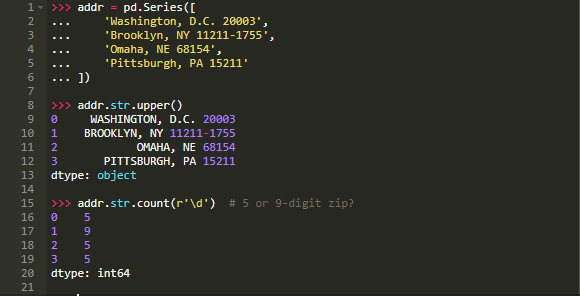
.cat是用于分类数据的,.str是针对字符串(对象)数据的,而.dt是用于类似于日期时间的数据。让我们从.str开始:设想你有一些原始的城市/州/邮编数据,作为Pandas Series中的一个字段。
Pandas字符串方法是矢量化的,这意味着它们对整个数组进行操作,而没有显式的for循环:
举个更复杂的例子,假设你希望将城市/州/邮编三个要素整齐地分到DataFrame字段中。
可以将正则表达式传递给.str.extract(),以“提取”Series中每个单元格的部分。在.str.extract()中,.str是accessor,.str.extract()是一个accessor方法:
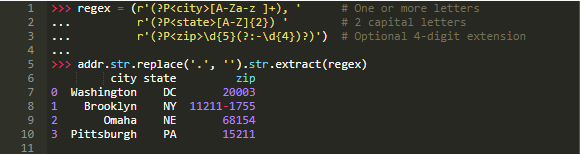
这也说明了所谓的方法链,其中.str.extract(regex)在addr.str.replace('.', '')的结果上被调用,该方法清理了句点的使用,从而得到一个好的双字符状态缩写。
稍微了解一下这些accessor方法是如何工作的,作为你应该首先使用它们,而不是像addr.apply(re.findall, ...)这样的东西的原因,这是很有帮助的。
每个accessor本身就是一个真正的Python类:
然后使用CachedAccessor将这些独立类“附加”到Series类。当类用CachedAccessor包装时,会发生一点魔法。
CachedAccessor的灵感来自“缓存属性”设计:每个实例只计算一次属性,然后用普通属性替换。它通过重载.__get__()方法来实现这一点,该方法是Python的描述符协议的一部分。
注意:如果您想了解更多关于其工作原理的内部信息,请参阅Python Descriptor HOWTO和这篇关于缓存属性设计的文章。Python 3还引入了 functools.lru_cache(),它提供了类似的功能。
第二个accessor, .dt是用于类似日期时间的数据。它在技术上属于Pandas的DatetimeIndex,如果在Series上调用,它首先转换为DatetimeIndex :
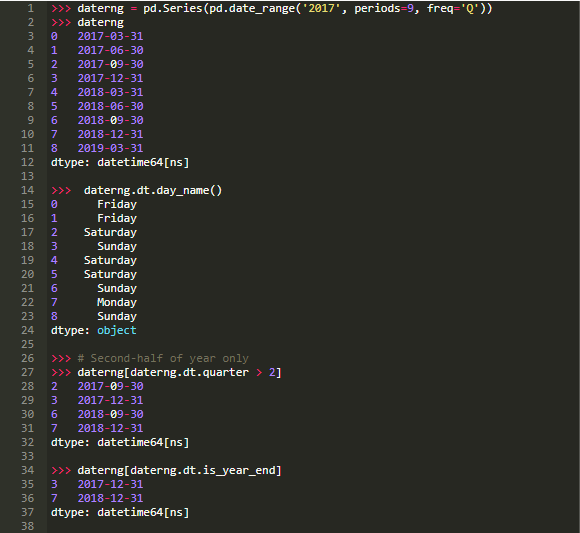
第三个accessor ,.cat,只用于分类数据,你很快将在它自己的部分中看到。
4.从组件列创建DatetimeIndex
说到类似datetime的数据,如上面的daterng,可以从多个组成列创建一个Pandas DatetimeIndex,这些组成列共同构成一个日期或日期时间:
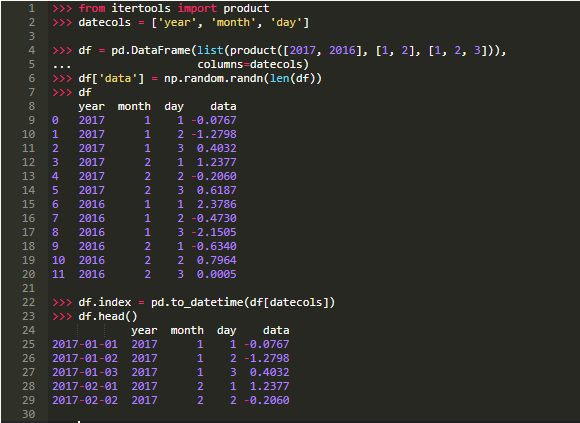
最后,你可以删除旧的单个列并转换为Series:

传递DataFrame的直觉是,DataFrame类似于Python字典,其中列名是键,各个列(Series)是字典值。这就是为什么pd.to_datetime(df[datecols].to_dict(orient='list'))在这种情况下也会起作用的原因。这反映了Python的datetime.datetime的构造,你可以在其中传递关键字参数,如datetime.datetime(year=2000, month=1, day=15, hour=10)。
5. 使用分类数据节省时间和空间
Pandas的一个强大特性是它的分类dtype。
即使你并不总是使用RAM中的千兆字节数据,你也可能遇到这样的情况,即直接操作大型DataFrame似乎挂起超过几秒钟。
Pandas object dtype通常是转换到类别数据的最佳候选。(object是Python str、异构数据类型或“其他”类型的容器。)字符串在内存中占用大量空间:

注意:我使用sys.getsizeof()来显示序列中每个单独的值占用的内存。请记住,这些是Python对象,这些对象在一开始就有一些开销。(sys.getsizeof('')将返回49字节。)
还有colors.memory_usage(),它总结了内存使用情况,并依赖于底层NumPy数组的.nbytes属性。不要太拘泥于这些细节:重要的是类型转换导致的相对内存使用,正如您接下来将看到的。
现在,如果我们把上面的独特颜色映射到一个占用更少空间的整数中呢?下面是一个简单的实现:
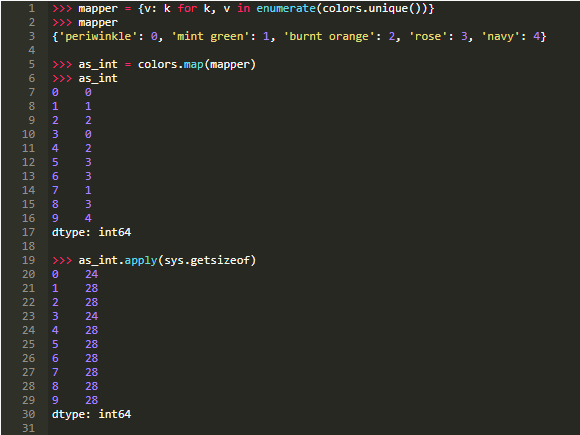
注意:另一种方法是Pandas的pd.factorize(colors):
![]()
无论哪种方式,都是将对象编码为枚举类型(分类变量)。
你会立刻注意到,与object dtype使用完整字符串相比,内存使用量几乎减少了一半。
在accessor一节中,我提到了.cat(分类)accessor。上面的mapper粗略的说明Pandas的Categoricaldtype内部正在发生:
“Categorical的内存使用与类别的数量加上数据的长度成正比。相反,对象dtype是数据长度的常数倍。”(来源)
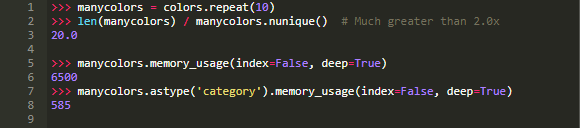
在上面的colors中,每一个唯一值(类别)都有2个值的比率:
![]()
结果,从转换到分类的内存节省是好的,但不是很大:

但是,如果用大量的数据和很少的唯一值(考虑人口统计或字母测试分数的数据)来夸大上述比例,则所需的内存减少超过10倍:
另一个好处是计算效率也得到了提升:对于分类Series,字符串操作是在.cat.categories属性上执行的,而不是在Series的每个原始元素上执行的。
换言之,操作在每一个唯一类别进行,并将结果映射回值。分类数据有一个.cat accessor ,它是一扇窗用于操作属性和方法来处理类别:

事实上,您可以手动再现类似于上面的示例:

为了精确地模拟早期手动输出,你需要做的是重新排序代码:
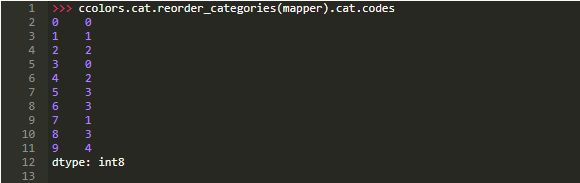
注意,dType是NumPy的int8,一个8位有符号整数,可以取值为-127到128。(只需要一个字节来表示内存中的值。在内存使用方面,64位有符号ints将被过度使用。)我们的粗略示例默认情况下得到int64数据,而Pandas足够聪明,能够将分类数据向下转换到尽可能小的数字dtype。
.cat的大多数属性与查看和操作底层类别本身有关:
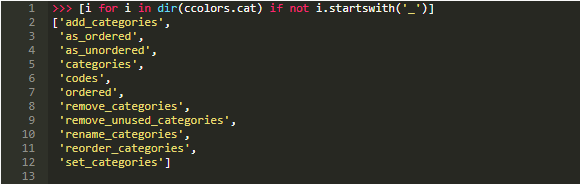
不过,也有一些注意事项。分类数据一般不那么灵活。例如,如果插入以前没出现过的值,则需要先将此值添加到..categories容器中:

如果你计划设置值或修正数据而不是派生新的计算,则Categorical类型可能不那么灵活。英文原文:https://realpython.com/python-pandas-tricks/
译者:张新英