Redis 字符串String数据结构

Redis 是一个开源的基于内存的数据结构存储,Redis 是远程字典服务(Remote Dictionary Server )的简写 ,它通常被用作数据库,缓存,消息代理和流引擎。Redis提供的数据结构有string,hashes,lists,sets,sorted sets五种,Redis内置了复制,Lua脚本,LRU驱动事件,事务以及不同级别的磁盘持久方法。并提供了高可用的Redis 哨兵和Redis集群方案
下载redis源码
下载地址: Download | Redis

下载源码结构如下:
1.redisObject数据结构
redis常用五种数据类型 string, hash, list, set, zset(sorted set) ,redis内部使用一个redisObject对象来表示key和 value, 查看redis-6.2.6\src\server.h 文件,可以看到redisObject结构定义
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;1) type (4个bit位):代表一个value对象具体是何种数据类型,在server.h文件中也可以查到type定义,type 可以是string,hash,list.set.zset. 例如type=string代表value 存储的是一个普通字符串,可以通过type命令查看,查看redis-6.2.6\src\server.h 文件可以找到type定义
/* A redis object, that is a type able to hold a string / list / set */
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */2) encoding(4个bit位):表示不同数据类型在 redis内部的存储方式, 查看redis-6.2.6\src\server.h 文件可以找到encoding定义
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */3)LRU_BITS(24个bit位),表示最近一次的访问时间,当内存达到最大的时,此属性用于协助删除数据
4)refcount (4个byte位):引用计数,当refcount为0的时,表示可以回收当前对象
5)void *ptr (8个byte位):指向底层数据实现的指针
一个字节(Byte)由8个位(bit)组成 。 一个redisObject大小为16个字节, 即:
4bit+4bit+24bit+4byte+8byte = 16byte
2.字符串底层编码
String是最简单的类型,一个key对应一个value,String类型的数据最大1G。在list、set和zset中包含的独立的元素类型都是String类型。 字符串的底层实现其实有三种编码
| 类型 | 编码 | 对象 |
| REDIS_STRING | REDIS_ENCODING_INT | 使用整数值实现的字符串对象 |
| REDIS_STRING | REDIS_ENCODING_EMBSTR | 使用 embstr 编码的简单动态字符串实现的字符串对象 |
| REDIS_STRING | REDIS_ENCODING_RAW | 使用简单动态字符串(SDS)实现的字符串对 |
1)如果一个字符串对象保存的是数字的时候, 并且数字可以用 long 类型来表示, 那么字符串对象会将整数值保存在字符串对象结构的 ptr 属性里面(将 void* 转换成 long ), 并将字符串对象的编码设置为 int 。
2)如果字符串对象保存的是一个字符串值, 则先根据存储的字符串体积进行分区, 如果这个字符串值的长度大于 44字节, 那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值, 并将对象的编码设置为 raw 。
3)如果字符串对象保存的是一个字符串值,则先根据存储的字符串体积分区 ,如果这个字符串值的长度小于等于 44字节, 那么字符串对象将使用 embstr 编码的方式来保存这个字符串值。
做一个测试理解上述三种情况,可以通过object encoding keyname 指令查看编码格式,可以通过type keyname查看value底层的数据结构
RDM Redis Console
Connecting...
已连接。
10.0.2.104_docker:0>select 15
"OK"
//1.通过set 保存3个KEY
10.0.2.104_docker:15>set key1 1
"OK"
10.0.2.104_docker:15>set key2 hello
"OK"
10.0.2.104_docker:15>set key3 helloworldhelloworldhelloworldhelloworldhelloworld
"OK"
//2.通过 object encoding keyname方式查看对应的编码格式
10.0.2.104_docker:15>object encoding key1
"int"
10.0.2.104_docker:15>object encoding key2
"embstr"
10.0.2.104_docker:15>object encoding key3
"raw"
//3.通过 type keyname方式查看某个key对应的value底层存储的数据结构
10.0.2.104_docker:15>type key1
"string"
10.0.2.104_docker:15>type key2
"string"
10.0.2.104_docker:15>type key3
"string"
10.0.2.104_docker:15>3. embstr 结构
打开下载的redis sources源码查看redis-6.2.6\src\object.c 可以找到以下源码
/* Create a string object with EMBSTR encoding if it is smaller than
* OBJ_ENCODING_EMBSTR_SIZE_LIMIT, otherwise the RAW encoding is
* used.
*
* The current limit of 44 is chosen so that the biggest string object
* we allocate as EMBSTR will still fit into the 64 byte arena of jemalloc. */
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}当字符串长度小于等于44字节的时候,创建embeddedString对象保存字符串,否则创建rawsString对象保存字符串。
embstr和raw都使用redisObject结构和sdshdr结构来表示字符串对象, embstr的创建只需分配一次内存并且是连续的内存,也只释放一次内存,raw分配两次内存redisObject 和sds的分别处理, 内存也不是连续的。所以相比较来说对于短字符串来说embstr更具有优势
4. raw使用动态字符串SDS
Redis中没有直接使用C语言的字符串,而是构建了一套自己的抽象类型,名为简单动态字符串(Simple dynamic String),简称SDS ,如果保存的是字符串且大于44字节,那么就会使用SDS结构来保存
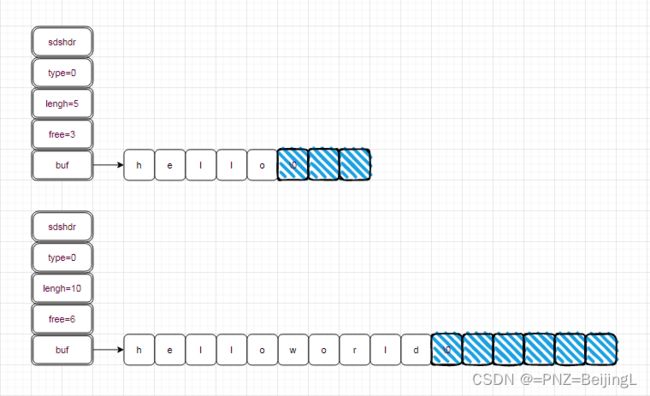
早期的Redis中sds结构( redis-3.2之前的版本),len为长度,free表示空长度,
struct sdshdr{
unsigned int len;
unsigned int free;
char buf[];
};例如 :要存储hello字符串,,此时会分配8字节的空间 len为5,free为3,如果要存储helloworld ,此时超过8就需要扩容, 扩容的时候会调用addlen函数将8扩容为16,此时len变成了10而free变成了6
随着redis版本发布,free字段被alloc字段代替。打开下载的redis sources源码查看redis-6.2.6\src\sds.h 可以找到定义
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};- len: 标记char[]的长度, 有点类似我们C#中List的length一个意思
- alloc: alloc表示实际空间大小, 也就是原来的len+free的数值,
-
buf[]: 存放元素的数组
SDS意思是“简单动态字符串” ,动态扩展也是SDS的最奇妙之处,SDS扩展的时候处理步骤如下
- 计算出大小是否足够.则不变
- 计算开辟空间至满足所需大小。
- 如果len < 1M,开辟与已使用大小len相同长度的空闲
- 如果len >= 1M,开辟1M长度的空闲free空间
打开下载的redis sources源码查看redis-6.2.6\src\sds.c 可以找到源码定义
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
/* 当前可用空间*/
size_t avail = sdsavail(s);
size_t len, newlen, reqlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
size_t usable;
/* 空间足够的时候返回s*/
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
/*计算新字符串长度*/
reqlen = newlen = (len+addlen);
assert(newlen > len); /* Catch size_t overflow */
/*长度和SDS_MAX_PREALLOC比较,其中SDS_MAX_PREALLOC=1024*1024=1M*/
if (newlen < SDS_MAX_PREALLOC)
//小于1M 两倍
newlen *= 2;
else
//大于等于1M时扩1M
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
assert(hdrlen + newlen + 1 > reqlen); /* Catch size_t overflow */
if (oldtype==type) {
//新数据结构和旧数据结构相同
newsh = s_realloc_usable(sh, hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
newsh = s_malloc_usable(hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
usable = usable-hdrlen-1;
if (usable > sdsTypeMaxSize(type))
usable = sdsTypeMaxSize(type);
sdssetalloc(s, usable);
return s;
}问题:为什么体积大于等于44个字节后,编码格式由embstr 变成sds?
这个问题在网上有两种说法:
第一种说法:在Redis中存储数据最小SDS结构是3个字节, RedisObject占用16个字节,也就是说一个最小的字符串是19个字节,末尾还有一个"\0", redis内存分配器分配内存最大是64字节,64-20=44。所以设计embstr可存储最大度为44字节的字符串
另一种说法:因为linux操作系统中的缓存行大小通常默认就是64字,所以64-20=44,当小于等于44个字节的时候,sds+元空间+指针大小是小于一个cache_line大小的,将数据体积尽可能地控制在了一个缓存行大小内能够有效地提高计算机的计算效率,
这两种说法个人觉得都有道理,但从官网或者其他权威资料中没有找到相关说明
问题:SDS 结构优势在哪里?
1. 降低复杂度
C语言中字符串只是简单的字符的数组,当使用strlen获取字符串长度的时候,内部其实是直接顺序遍历数组的内容,找到对应的’\0’对应的字符,从而计算出字符串的长度。即O(N)。SDS:只需要访问SDS的len属性就能得到字符串的长度,复杂度为O(1)。
2.杜绝缓冲区溢出:
Redis是C语言编写的,并没有方便的数据类型来进行内存的分配和释放(C++ STL String),必须手动进行内存分配和释放。对于字符串的拼接、复制等操作,C语言开发者必须确保目标字符串的空间足够大,不然就会出现溢出的情况。当使用SDS的API对字符串进行修改的时候,API内部第一步会检测字符串的大小是否满足。如果空间已经满足要求,那么就像C语言一样操作即可。如果不满足,则扩展buf的空间之后再进行操作。每次操作之后,len和free的值会做相应的修改。
3.减少修改字符串时带来的内存重分配次数
Redis主要通过以下两种策略来处理内存问题。字符串长度增加操作时,进行空间预分配,字符串长度减少操作时,惰性空间释放, 即当执行字符串长度缩短的操作的时候,SDS并不直接重新分配多出来的字节,而是减小len值,增大free,buf的空间大小不变化。来避免内存重分配。SDS也提供直接释放未使用空间的API,在需要的时候,也能真正的释放掉多余的空间。
4.二进制处理安全
C语言字符串除了末尾之外不能出现’\0’,否则会被程序认为是字符串的结尾。这就使得C字符串只能存储文本数据,而不能保存图像,音频等二进制数据。使用SDS就不需要依赖控制符,而是用len来指定存储数据的大小,所有的SDS API都会以处理二进制的方式来处理SDS的buf的数据。程序不会对buf的数据做任何限制、过滤或假设,数据写入的时候是什么,读取的时候依然不变
5.兼容部分C字符串函数
同上,也是由于C语言字符串除了末尾之外不能出现’\0’,因此很多的C字符串的操作都是适用于SDS->buf的。比如当buf里面存的是文本字符串的时候,大多数通过调用C语言的函数就可以。
5.字符串命令
下表列出了常用的 redis 字符串命令 ,列表摘自菜鸟教程 Redis 字符串(String) | 菜鸟教程 ,起初是自己写的,后来修改用下面的列表代替, 个人觉得教程的描述更加详细,有兴趣的朋友可以看看
| 序号 | 命令及描述 |
|---|---|
| 1 | SET key value 设置指定 key 的值。 |
| 2 | GET key 获取指定 key 的值。 |
| 3 | GETRANGE key start end 返回 key 中字符串值的子字符 |
| 4 | GETSET key value 将给定 key 的值设为 value ,并返回 key 的旧值(old value)。 |
| 5 | GETBIT key offset 对 key 所储存的字符串值,获取指定偏移量上的位(bit)。 |
| 6 | MGET key1 [key2..] 获取所有(一个或多个)给定 key 的值。 |
| 7 | SETBIT key offset value 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。 |
| 8 | SETEX key seconds value 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。 |
| 9 | SETNX key value 只有在 key 不存在时设置 key 的值。 |
| 10 | SETRANGE key offset value 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始。 |
| 11 | STRLEN key 返回 key 所储存的字符串值的长度。 |
| 12 | MSET key value [key value ...] 同时设置一个或多个 key-value 对。 |
| 13 | MSETNX key value [key value ...] 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。 |
| 14 | PSETEX key milliseconds value 这个命令和 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间,而不是像 SETEX 命令那样,以秒为单位。 |
| 15 | INCR key 将 key 中储存的数字值增一。 |
| 16 | INCRBY key increment 将 key 所储存的值加上给定的增量值(increment) 。 |
| 17 | INCRBYFLOAT key increment 将 key 所储存的值加上给定的浮点增量值(increment) 。 |
| 18 | DECR key 将 key 中储存的数字值减一。 |
| 19 | DECRBY key decrement key 所储存的值减去给定的减量值(decrement) 。 |
| 20 | APPEND key value 如果 key 已经存在并且是一个字符串, APPEND 命令将指定的 value 追加到该 key 原来值(value)的末尾。 |
参考资料:
Josiah L. Carlson著 - Redis 字符串(String) | 菜鸟教程
前一篇:Redis 目录与配置说明