数据结构 第4章(串、数组和广义表)
目录
- 1. 串的定义
- 2. 串的存储结构及其运算
-
- 2.1 串的存储结构
-
- 2.1.1 串的顺序存储
- 2.1.2 串的链式存储
- 2.2 串的模式匹配算法
-
- 2.2.1 BF 算法
- 2.2.2 KMP 算法(看不懂)
- 测试代码
- 3. 数组
-
- 3.1 数组的类型定义
- 3.2 数组的顺序存储
- 3.3 特殊矩阵的压缩存储
-
- 3.3.1 对称矩阵
- 3.3.2 三角矩阵
-
- (1) 上三角矩阵
- (2) 下三角矩阵
- 3.3.3 对角矩阵
- 4. 广义表
-
- 4.1 广义表的定义
- 4.2 广义表的存储结构
-
- 4.2.1 头尾链表的存储结构
- 4.2.2 扩展线性链表的存储结构
1. 串的定义
-
串(string)(或字符串):由零个或多个字符组成的有限序列,记为 s = “a_1 a_2 ··· a_n” (n ≥ 0)
- s :串的名,用双引号括起来的字符序列是串的值
- a_i (1 ≤ i ≤ n) :可以是字母、数字或其他字符
- n :串的长度
- 空串(null string):零个字符的串,长度为零
-
子串:串中任意连续的字符组成的子序列
-
主串:包含子串的串
-
位置:字符在序列中的序号
-
子串在主串中的位置:以子串的第一个字符在主串中的位置来表示
a = "abcd"; b = "ABCD"; c = "abcdABCD"; d = "abcd ABCD"; // a 和 b 都是 c 和 d 的子串 // a 在 c 和 d 中的位置都是 1 // b 在 c 中的位置是 5 // b 在 d 中的位置是 6
-
-
相等:两个串的值相等
- 两个串的长度相等
- 各个对应位置的字符都相等
-
空格串(blank string):由一个或多个空格组成的串
- 不是空串
- 长度为串中空格字符的个数
- 用符号 “∅” 来表示 “空串”
2. 串的存储结构及其运算
2.1 串的存储结构
- 串多采用顺序存储结构
2.1.1 串的顺序存储
- 定长顺序存储结构
#define MAXLEN 10
typedef struct {
char ch[MAXLEN + 1]; // 存储串的一维数组
int length; // 串的当前长度
} SString;
- 堆式顺序存储结构
typedef struct {
char *ch; // 若为非空串,则按串长分配存储区,否则 ch 为 NULL
int length; // 串的当前长度
} HString;
2.1.2 串的链式存储
#define CHUNKSIZE 5
typedef struct Chunk {
char ch[CHUNKSIZE];
struct Chunk *next;
} Chunk;
typedef struct {
Chunk *head; // 串的头指针
Chunk *tail; // 串的尾指针
int length; // 串的当前长度
} LString;
2.2 串的模式匹配算法
-
模式匹配 / 串匹配:子串的定位运算
-
补:以下代码均使用定长顺序存储结构
- 不推荐,过于繁琐
- 直接定义字符串,使用 strlen() 获取字符串长度
2.2.1 BF 算法
- BF:Brute - Force
- 步骤
- 利用计数指针 i 和 j 指示主串 S 和模式(子串) T 中当前正待比较的字符位置,i 初值为 pos,j 初值为 1
- i 和 j 均分别小于等于 S 和 T 的长度时,则循环执行以下操作
- S.ch[i] 和 T.ch[j] 比较
- 相等:i 和 j 分别指示字符串中下个位置,继续比较后续字符
- 不等:指针后退重新开始匹配,从主串的下一个字符起再重新和模式的第一个字符比较
- S.ch[i] 和 T.ch[j] 比较
void Index_BF(SString S, SString T, int index) {
int i = index;
int j = 0;
while (i < S.length && j < T.length )
{
if (S.ch[i] == T.ch[j])
{
i++;
j++;
}
else {
i = ++index;
j = 0;
}
}
if (j > T.length - 1)
{
printf("Index_BF Success\n");
printf("Index from %d to %d\n", index, index + j - 1);
}
else
{
printf("Error\n");
}
}

-
最好情况:每次不成功的匹配都发生在模式串的第一个字符与主串中相应字符的比较
S = "aaaaaba"; T = "ba"; -
设主串长度为 n ,子串长度为 m ,匹配成功概率处处相等,则平均比较次数为
∑ i = 1 n − m + 1 p n ( i − 1 + m ) = 1 n − m + 1 ∑ i = 1 n − m + 1 i − 1 + m = 1 2 ( n + m ) \sum_{i=1}^{n-m+1}{p_n(i-1+m)} = \frac{1}{n-m+1}\sum_{i=1}^{n-m+1}{i-1+m} = \frac{1}{2}(n+m) i=1∑n−m+1pn(i−1+m)=n−m+11i=1∑n−m+1i−1+m=21(n+m)
因此,最好情况下的平均时间复杂度为 O(n+m)
2.2.2 KMP 算法(看不懂)
- 每当一趟匹配过程中出现字符比较不等时,不回溯 i 指针,而是利用已经得到的 “部分匹配” 的结果将模式向右 “滑动” 尽可能远的距离后,继续进行比较
void Index_KMP(SString S, SString T) {
int next[10];
// 根据模式串 T,初始化 next 数组
Next(T, next);
int i = 1;
int j = 1;
while (i <= S.length && j <= T.length)
{
// j==0 :模式串的第一个字符就和当前测试的字符不相等
// S[i-1] == T.ch[j-1] :如果对应位置字符相等,两种情况下,指向当前测试的两个指针下标i和j都向后移
if (j == 0 || S.ch[i-1] == T.ch[j-1])
{
i++;
j++;
}
else
{
// 如果测试的两个字符不相等,i不动,j变为当前测试字符串的next值
j = next[j];
}
}
if (j > T.length)
{
printf("Success\n");
}
else
{
printf("Error\n");
}
}
void Next(SString T, int* next) {
int i = 1;
next[1] = 0;
int j = 0;
while (i < T.length)
{
if (j == 0 || T.ch[i-1] == T.ch[j-1])
{
i++;
j++;
next[i] = j;
}
else
{
j = next[j];
}
}
}
测试代码
#include 3. 数组
3.1 数组的类型定义
- 数组是由类型相同的数据元素构成的有序集合,每个元素称为数组元素,每个元素受 n (n≥1)个线性关系的约束,每个元素在 n 个线性关系中的序号 i_1 ,i_2 ,··· ,i_n 称为该元素的下标,可以通过下标访问该数据元素
- n 维数组:数组中每个元素处于 n (n≥1)个关系中
3.2 数组的顺序存储
-
数组一般不做插入或删除操作,因此,采用顺序存储结构
-
随机存取结构
-
假设每个数据元素站 L 个存储单元,则二维数组 A[0 ··· m-1, 0 ··· n-1](下标从 0 开始,共有 m 行 n 列)中任一元素 a_ij 的存储位置可由下式确定
L O C ( i , j ) = L O C ( 0 , 0 ) + ( n ∗ i + j ) L LOC(i, j) = LOC(0, 0) + (n*i+j)L LOC(i,j)=LOC(0,0)+(n∗i+j)L
LOC(i, j) 是 a_ij 的存储位置,LOC(0, 0) 是 a_00 的存储位置 -
n 维数组 A[0 ··· b_1-1, 0 ··· b_2-1, ··· , 0 ··· b_n-1] 的数据元素存储位置的计算公式
L O C ( j 1 , j 2 , ⋅ ⋅ ⋅ , j n ) = L O C ( 0 , 0 , ⋅ ⋅ ⋅ , 0 ) + ( b 2 ∗ ⋅ ⋅ ⋅ ∗ b n ∗ j 1 + b 3 ∗ ⋅ ⋅ ⋅ ∗ b n ∗ j 2 + ⋅ ⋅ ⋅ + b n ∗ j n − 1 + j n ) L LOC(j_1, j_2, ···, j_n) = LOC(0,0,···,0)+(b_2*···*b_n*j_1 + b_3*···*b_n*j_2 + ··· + b_n*j_{n-1} + j_n)L LOC(j1,j2,⋅⋅⋅,jn)=LOC(0,0,⋅⋅⋅,0)+(b2∗⋅⋅⋅∗bn∗j1+b3∗⋅⋅⋅∗bn∗j2+⋅⋅⋅+bn∗jn−1+jn)L= L O C ( 0 , 0 , ⋅ ⋅ ⋅ , 0 ) + ( ∑ i = 1 n − 1 j i ∏ k = i + 1 n b k + j n ) L = LOC(0,0,···,0)+(\sum_{i=1}^{n-1}{j_i}\prod_{k=i+1}^{n}{b_k}+j_n)L =LOC(0,0,⋅⋅⋅,0)+(i=1∑n−1jik=i+1∏nbk+jn)L
缩写成
L O C ( j 1 , j 2 , ⋅ ⋅ ⋅ , j n ) = L O C ( 0 , 0 , ⋅ ⋅ ⋅ , 0 ) + ∑ i = 1 n c i j i LOC(j_1, j_2, ···, j_n) = LOC(0,0,···,0)+\sum_{i=1}^{n}{c_ij_i} LOC(j1,j2,⋅⋅⋅,jn)=LOC(0,0,⋅⋅⋅,0)+i=1∑nciji
c_n = L ,c_{i-1} = b_i * c_i ,1 < i ≤ n
3.3 特殊矩阵的压缩存储
3.3.1 对称矩阵
-
a_ij = a_ji ,1 ≤ i ,j ≤ n
-
存储下三角(包括对角线)中的元
-
假设 sa [n(n+1)/2] 作为 n 阶对称矩阵 A 的存储结构
-
sa [k] 和矩阵元 a_ij 之间的对应关系为
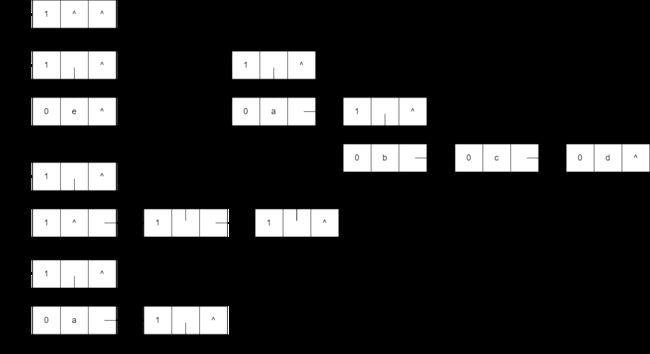
k = { i ( i − 1 ) 2 + j − 1 当 i ≥ j j ( j − 1 ) 2 + i − 1 当 i < j k=\begin{cases} \frac{i(i-1)}{2} + j - 1 \quad 当 i ≥ j \\ \frac{j(j-1)}{2} + i - 1 \quad 当 i < j\end{cases} k={2i(i−1)+j−1当i≥j2j(j−1)+i−1当i<j
-
推导过程
-
对称矩阵一共具有的元素数量为
n ∗ ( n + 1 ) 2 \frac{n*(n+1)}{2} 2n∗(n+1) -
下标范围为
[ 0 , n ∗ ( n + 1 ) 2 − 1 ] [0, \frac{n*(n+1)}{2} - 1] [0,2n∗(n+1)−1]
a_nn 的下标为
n ∗ ( n + 1 ) 2 − 1 \frac{n*(n+1)}{2} - 1 2n∗(n+1)−1
a_n1 的下标为
n ∗ ( n + 1 ) 2 − ( n − 1 ) − 1 = n ∗ ( n − 1 ) 2 \frac{n*(n+1)}{2} - (n - 1) - 1= \frac{n*(n-1)}{2} 2n∗(n+1)−(n−1)−1=2n∗(n−1)
a_nj 的下标为
n ∗ ( n − 1 ) 2 + j − 1 \frac{n*(n-1)}{2} + j - 1 2n∗(n−1)+j−1
a_ij 的下标为
i ∗ ( i − 1 ) 2 + j − 1 \frac{i*(i-1)}{2} + j - 1 2i∗(i−1)+j−1
-
3.3.2 三角矩阵
- 存储其上(下)三角中的元素之外,再加一个存储常数 c 的存储空间即可
(1) 上三角矩阵
- sa [k] 和矩阵元 a_ij 之间的对应关系为
k = { ( i − 1 ) ( 2 n − i + 2 ) 2 + j − 1 当 i ≥ j n ( n + 1 ) 2 当 i < j k=\begin{cases} \frac{(i-1)(2n-i+2)}{2} + j - 1 \quad 当 i ≥ j \\ \frac{n(n+1)}{2} \quad\quad\quad\quad\quad\quad\quad 当 i < j\end{cases} k={2(i−1)(2n−i+2)+j−1当i≥j2n(n+1)当i<j

(2) 下三角矩阵
- sa [k] 和矩阵元 a_ij 之间的对应关系为
k = { i ( i − 1 ) 2 + j − 1 当 i ≥ j n ( n + 1 ) 2 当 i < j k=\begin{cases} \frac{i(i-1)}{2} + j - 1 \quad\quad\quad 当 i ≥ j \\ \frac{n(n+1)}{2} \quad\quad\quad\quad\quad\quad 当 i < j\end{cases} k={2i(i−1)+j−1当i≥j2n(n+1)当i<j

3.3.3 对角矩阵
4. 广义表
4.1 广义表的定义
-
广义表是线性表的推广,也称为列表
-
一般记作 LS = (a_1, a_2, ··· , a_n)
- LS 是广义表的名称
- n 是其长度
-
3 个重要结论
-
广义表的元素可以是子表,而子表的元素还可以是子表
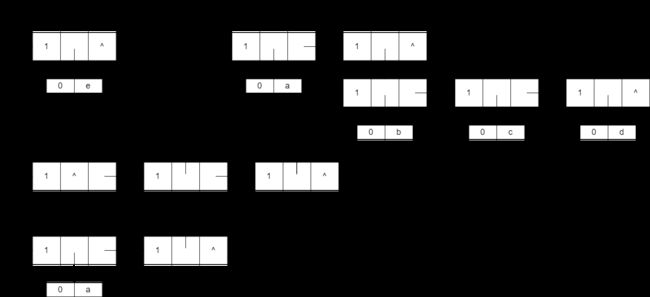
A = (a, (b, c)); -
广义表可为其他广义表所共享
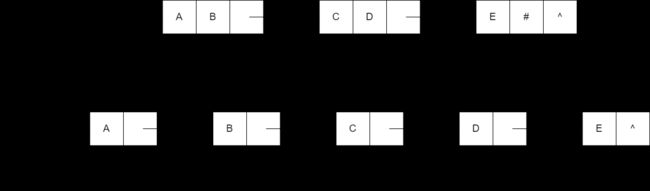
A = (); B = (e); C = (a, (b, c, d)); D = (A, B, C); // n = 3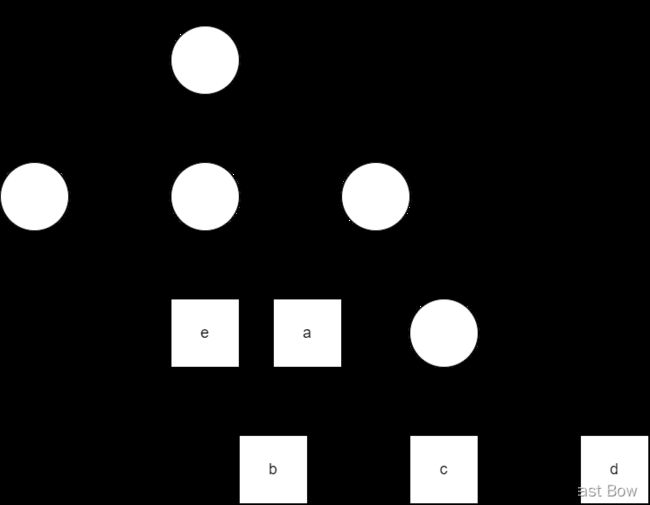
-
广义表可以是一个递归表
E = (a, E); // n = 2
-
-
2 个重要的运算
- 取表头 GetHead(LS)
- 取出的表头为非空广义表的第一个元素
- 可以是一个单原子
- 也可以是一个子表
- 取出的表头为非空广义表的第一个元素
- 取表尾 GetTail(LS)
- 取出的表尾为除去表头之外,由其余元素构成的表
AB = (a, b); C = (c); ABC = (AB, C); GetHead(ABC) == AB; GetTail(ABC) == (C); GetHead(AB) == a; GetTail(AB) == (b); GetHead(C) == c; GetTail(C) == (); - 取表头 GetHead(LS)
4.2 广义表的存储结构
- 广义表中的数据元素可以有不同的结构(原子,列表),因此,采用链式存储结构
4.2.1 头尾链表的存储结构
- 构成
- 表结点:表示广义表
- 标志域
- 指向表头的指针域
- 指向表尾的指针域
- 原子结点:表示原子
- 标志域
- 值域
- 表结点:表示广义表
typedef enum {ATOM, LIST} ElemTag; // 枚举
// ATOM == 0 : 原子
// ATOM == 1 : 子表
typedef struct GLNode {
ElemTag tag; // 用于区分原子结点和表结点
union { // 联合
AtomType atom; // 原子结点值域,用户自行定义
struct { // 表结点的指针域
struct GLNode *hp; // 表头
struct GLNode *tp; // 表尾
} ptr;
};
} *Glist;
- 3 个特点
- 除空表得到表头指针为空外,对任何非空广义表,其表头指针均指向一个表的结点
- 该结点中的 hp 域指向广义表表头(原子结点,表结点)
- tp 域指向广义表表尾(若表尾为空,则指针为空,否则为表结点)
- 容易分清列表中的原子和子表所在层次
- 最高层的表结点个数即为广义表的长度
- 除空表得到表头指针为空外,对任何非空广义表,其表头指针均指向一个表的结点
4.2.2 扩展线性链表的存储结构
- 无论原子结点还是表结点均由 3 个域组成
- 表结点:
- 标志域
- 指向表头的指针域
- 指向表尾的指针域
- 原子结点:
- 标志域
- 值域
- 指向表尾的指针域
- 表结点: