AIGC实战——自编码器(Autoencoder)
AIGC实战——自编码器
-
- 0. 前言
- 1. 自编码器原理
- 2. 数据集与模型分析
-
- 2.1 Fashion-MNIST 数据集
- 2.2 自编码器架构
- 3. 去噪自编码器
-
- 3.1 编码器
- 3.2 解码器
- 3.3 连接编码器和解码器
- 3.4 训练自编码器
- 3.5 重建图像
- 4. 可视化潜空间
- 5. 生成新图像
- 小结
- 系列链接
0. 前言
自编码器 (Autoencoder) 是一种无监督学习的神经网络模型,用于学习输入数据的低维表示。它由编码器和解码器两部分组成,通过将输入数据压缩到潜空间表示(编码),然后将其重构为与原始输入尽可能相似的形式(解码)。在本节中,我们将使用 Keras 构建一个标准的自编码器,以理解自编码器的工作原理。
1. 自编码器原理
自编码器的目标是最小化输入与重构输出之间的重构误差,通过这个过程来学习数据中的有用特征。在训练过程中,自编码器首先将输入数据传递给编码器 (Encoder),编码器将数据映射到低维的潜空间表示(也称嵌入,或编码)。然后,解码器 (Decoder) 接收编码后的表示,并尝试将其重构为原始输入,以最小化重构误差。

自编码器是一个被训练来执行编码和解码任务的神经网络,使得这个过程的输出尽可能接近原始输入。自编码器可以用作生成模型,因为我们可以解码我们想要的潜空间中的任何点(即使那些不是原始输入的嵌入),以产生一个新颖的输出结果。
2. 数据集与模型分析
2.1 Fashion-MNIST 数据集
在本节中,我们将使用 Fashion-MNIST 数据集,其包含了 10 个类别的 70,000 张灰度图像,每个类别有 7,000 张图像,这些类别分别对应于不同类型的服装和鞋子,包括T恤、裤子、套衫、连衣裙、外套、凉鞋、运动鞋、手提包、踝靴和运动衫。每张图像的大小为 28 x 28 像素,像素值介于 0 到 255 之间,表示图像中每个像素的灰度级别,下图展示了数据集中的一些示例图像。

Fashion-MNIST 数据集已经预置在 TensorFlow 库中,可以使用以下代码下载:
from tensorflow.keras import datasets
(x_train, y_train), (x_test, y_test) = datasets.fashion_mnist.load_data()
数据集中,每张图像都为 28 × 28 的灰度图像(像素值介于 0 和 255 之间),需要进行预处理,以确保将像素值缩放置 0 和 1 之间。我们还将每个图像填充为 32 × 32,以便能够更加方便的通过神经网络操作张量形状:
def preprocess(imgs):
"""
图像预处理
"""
imgs = imgs.astype("float32") / 255.0
imgs = np.pad(imgs, ((0, 0), (2, 2), (2, 2)), constant_values=0.0)
imgs = np.expand_dims(imgs, -1)
return imgs
接下来,我们需要了解自编码器的整体结构,以便使用 Keras 进行实现。
2.2 自编码器架构
自编码器是一个由两部分组成的神经网络:
- 编码器网络:将高维输入数据(如图像)压缩成低维嵌入向量
- 解码器网络:将给定的嵌入向量解压缩还原回原始域(如解还原回图像)
自编码器网络架构如下图所示,输入图像被编码为嵌入向量 z,然后再解码回原始像素空间。
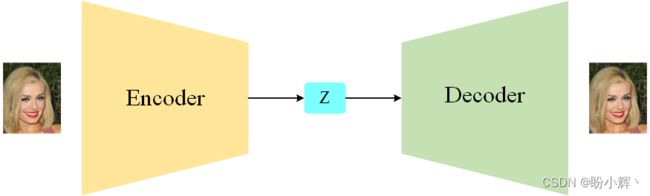
通过编码器和解码器之后,自编码器被训练用于重构图像。之所以要重构已经存在的图像集合,是因为自编码器中的嵌入空间(也称为潜空间)具有重要作用,在该空间中进行抽样可以用于生成新的图像。
嵌入 (z) 是将原始图像压缩成低维潜空间的表示,这是因为通过选择潜空间中的任意点,我们可以通过解码器生成新图像,因为解码器已经学习到如何将潜空间的点转换成可行的图像。
在我们构建的神经网络中,将图像嵌入到一个二维潜空间中。这有助于我们可视化潜空间,方便的在二维空间中绘制点。实际应用中,为了能够捕捉图像中更多的细微特征差别,自编码器的潜空间通常会有多个维度。
3. 去噪自编码器
自编码器可用于清除图像中的噪声,因为编码器能够学习到潜空间中的随机噪声位置对于重构原始图像是无用的。对于去噪任务而言,二维潜空间无法从输入中编码足够的相关信息。但相应的,如果我们想将自编码器用作生成模型,一味地增加潜空间的维度很快会产生其它问题。
3.1 编码器
在自编码器中,编码器的作用是将输入图像映射到潜空间中的嵌入向量,我们所构建的编码器架构如下图所示:

首先创建一个用于接收图像的输入层,并将其依次通过三个 Conv2D 层,每一层捕捉越来越高级的特征。在卷积层中,使用步幅为 2,将每个层的输出大小减半,同时增加通道数。最后一个卷积层展平后连接到一个包含2个单元(表示二维潜空间)的全连接层:
# 编码器
# 定义编码器的输入层(图像)
encoder_input = layers.Input(
shape=(IMAGE_SIZE, IMAGE_SIZE, CHANNELS), name="encoder_input"
)
# 依次堆叠 Conv2D 层
x = layers.Conv2D(32, (3, 3), strides=2, activation="relu", padding="same")(
encoder_input
)
x = layers.Conv2D(64, (3, 3), strides=2, activation="relu", padding="same")(x)
x = layers.Conv2D(128, (3, 3), strides=2, activation="relu", padding="same")(x)
shape_before_flattening = K.int_shape(x)[1:]
# 将最后一个卷积层展平为一个向量
x = layers.Flatten()(x)
# 使用全连接层将此向量连接到 2D 嵌入
encoder_output = layers.Dense(EMBEDDING_DIM, name="encoder_output")(x)
# 定义编码器的 Keras 模型,该模型接受一个输入图像并将其编码成一个 2D 嵌入向量
encoder = models.Model(encoder_input, encoder_output)
print(encoder.summary())
可以调整卷积层和过滤器的数量,以了解架构对模型参数的总数、模型性能和模型运行时间的了解。
3.2 解码器
解码器是编码器的镜像,其使用转置卷积替代卷积层,解码器网络架构如下所示:

需要注意的是,解码器不一定必须和编码器使用同样的架构,它可以是任何形式,只要解码器最后一层的输出与编码器的输人大小相同即可,因为损失函数会逐像素比较输入图像与重建结果。
转置卷积层
标准的卷积层可以通过将 strides 设置为 2,在两个维度(高度和宽度)上将输入张量的大小减半。
转置卷积层 (Convolutional Transpose Layers) 的原理与标准卷积层相同(在图像上滑动滤波器),但不同之处在于将 strides 设置为 2 会使输入张量在两个维度上的大小加倍。
在转置卷积层中,strides 参数决定了在图像中像素之间的填充零的数量,如下图所示,一个 3 × 3 × 1 的滤波器(灰色)在一个 3 × 3 × 1 的图像(蓝色)上滑动,strides 设置为 2,将得到一个 6 × 6 × 1 的输出张量(绿色)。
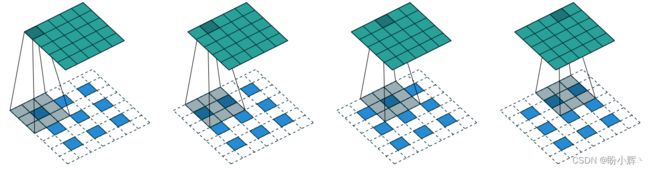
在 Keras 中,可以使用 Conv2DTranspose 层对张量执行转置卷积操作。通过堆叠转置卷积层,可以以步幅为 2 的速度逐渐扩展每个层的大小,直到将嵌入还原为原始图像尺寸 32 × 32:
# 解码器
# 定义解码器的输入(嵌入向量)
decoder_input = layers.Input(shape=(EMBEDDING_DIM,), name="decoder_input")
# 将输入连接到一个全连接层
x = layers.Dense(np.prod(shape_before_flattening))(decoder_input)
# 将向量形状调整为一个可以作为第一个 Conv2DTranspose 层输入的张量
x = layers.Reshape(shape_before_flattening)(x)
# 逐层堆叠 Conv2DTranspose 层
x = layers.Conv2DTranspose(
128, (3, 3), strides=2, activation="relu", padding="same"
)(x)
x = layers.Conv2DTranspose(
64, (3, 3), strides=2, activation="relu", padding="same"
)(x)
x = layers.Conv2DTranspose(
32, (3, 3), strides=2, activation="relu", padding="same"
)(x)
decoder_output = layers.Conv2D(
CHANNELS,
(3, 3),
strides=1,
activation="sigmoid",
padding="same",
name="decoder_output",
)(x)
# 定义解码器的 Keras 模型,将潜空间中的嵌入解码为原始图像域
decoder = models.Model(decoder_input, decoder_output)
print(decoder.summary())
3.3 连接编码器和解码器
为了同时训练编码器和解码器,需要定义一个模型,表示图像通过编码器后再通过解码器转换回图像的流程。
# 自编码器
autoencoder = models.Model(
encoder_input, decoder(encoder_output)
)
print(autoencoder.summary())
以上代码定义完整的自编码器的 Keras 模型,该模型接收图像输入,通过编码器传递,再传回到解码器中,生成原始图像的重建图像。
# 编译自编码器
autoencoder.compile(optimizer="adam", loss="binary_crossentropy")
定义了模型后,只需要使用损失函数和优化器对其进行编译,损失函数通常选择原始图像与重建图像各个像素之间的均方根误差 (Root Mean Squared Error, RMSE) 或二元交叉熵。
选择损失函数
优化 RMSE 损失意味着生成的输出将在平均像素值周围对称分布(因为过高或过低的估计都会受到相同的惩罚)。
另一方面,二元交叉熵损失是非对称的,相比 RMSE,二元交叉熵会更重地惩罚极端错误。例如,如果真实像素值较高(比如 0.7),则生成像素值为 0.8 的惩罚要大于生成像素值为 0.6 的惩罚;如果真实像素值较低(比如 0.3),则生成像素值为 0.2 的惩罚要大于生成像素值为 0.4 的惩罚。
因此,二元交叉熵损失相比 RMSE 损失会产生稍微模糊一些的图像(二元交叉熵倾向于将预测推向 0.5),而 RMSE 则可能会导致明显的像素化边缘。在进行充分尝试后,我们可以选择适合实际问题的最佳选择。
3.4 训练自编码器
接下来,我们将原始图像作为输入和输出训练自编码器:
autoencoder.fit(
x_train,
x_train,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
shuffle=True,
validation_data=(x_test, x_test),
)
自编码器训练完成后,我们需要检查的是它是否能够准确地重建输入图像。
3.5 重建图像
将测试集中的图像通过自编码器进行传递,并将输出与原始图像进行比较来测试重建图像的能力:
n_to_predict = 5000
example_images = x_test[:n_to_predict]
example_labels = y_test[:n_to_predict]
predictions = autoencoder.predict(example_images)
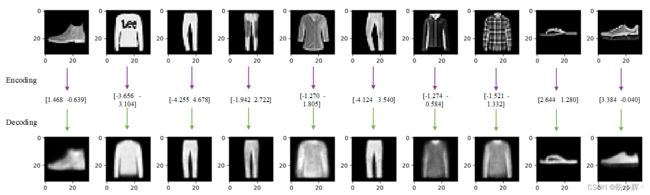
在上图中,可以看到示例原始图像(顶部行),编码后的 2D 向量以及解码后的重建图像(底部行)。重建效果并不完美,解码过程中仍然有一些原始图像的细节没有被捕捉到。这是因为将每个图像缩减为二维嵌入向量,自然会丢失一些信息。
4. 可视化潜空间
接下来,我们继续研究编码器如何在潜在空间中表示图像。可以通过将测试集传递给编码器并绘制结果嵌入来可视化图像在潜在空间中的嵌入:
# 编码样本图像
embeddings = encoder.predict(example_images)
print(embeddings[:10])
# 在2D空间可视化潜向量
figsize = 8
plt.figure(figsize=(figsize, figsize))
plt.scatter(embeddings[:, 0], embeddings[:, 1], c="black", alpha=0.5, s=3)
plt.show()
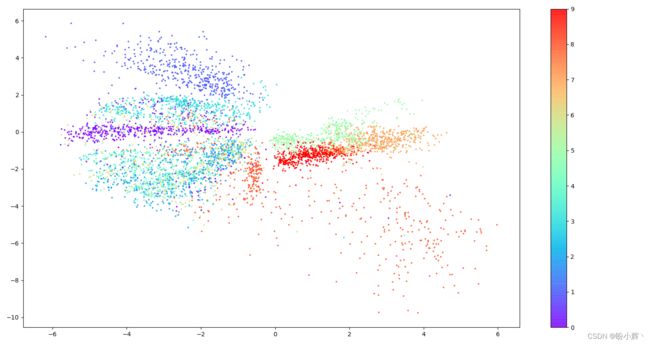
在生成的散点图中,每个点表示一个已被嵌入到潜在空间中的图像。
为了更好地理解潜空间的结构,我们可以利用 Fashion-MNIST 数据集中附带的标签(描述了每个图像中物品的类型)。根据相应图像的标签为每个点着色,在结果图像中,可以看到,尽管在训练过程中从未向模型展示过服装标签,但自编码器自然地将外观相似的物品分组到潜空间的相邻部分。
5. 生成新图像
通过在潜在空间中采样一些点,并使用解码器将其转换回像素空间来生成新的图像:
mins, maxs = np.min(embeddings, axis=0), np.max(embeddings, axis=0)
# 在潜空间中采样点
grid_width, grid_height = (6, 3)
sample = np.random.uniform(
mins, maxs, size=(grid_width * grid_height, EMBEDDING_DIM)
)
# 解码采样点
reconstructions = decoder.predict(sample)
生成图像示例如下图所示,图中同时显示了它们在潜空间中的嵌入。

每个蓝色点对应图示右侧的一个图像,其嵌入向量显示在生成图像下方,可以看到生成的不同图像具有不同的逼真程度。通过观察潜空间中点的整体分布,可以得到如下结论:
- 有些物品类别在一个非常小的区域内表示,而有一些则在一个更大的区域内表示
- 分布关于点
(0, 0)不对称,也没有上下界。例如,正y轴值的点要远多于负值的点,甚至一些点的y轴值超过8。 - 彩色图像之间存在较大的间隙,自编码器无法确保将间隙处的点解码成合理的图像
上述现象使得从潜空间中进行采样变得相当具有挑战性。将潜空间与解码后的网格点图像叠加在一起,我们就可以开始理解为什么解码器并不总是能够生成令人满意的图像。

首先,可以看到,如果在一个有界空间中均匀地选择点,更有可能采样出解码后像一个包 (ID 8) 而不是一个踝靴 (ID 9) 的嵌入向量,因为潜空间中包(橙色)所占据的区域比踝靴(红色)要大。
其次,我们无法提前预知如何在潜空间中选择随机点,因为这些点的分布是未定义的。从技术上讲,我们可以在二维平面中选择任何点,这使得从潜空间中进行采样成为一个问题。
最后,在潜空间中存在一些没有任何原始图像编码的空白区域。例如,在区域边缘有大片的白色空间,自编码器没有强制确保这些点可以解码出可识别的图像,因为在训练集中很少有图像能够被编码到这里。
即使中心点也可能无法解码为完好的图像。这是因为自编码器并没有强制要求空间连续。例如,即使点 (-1,-1) 能够解码为一个令人满意的凉鞋图像,但没有机制确保点 (-1.1,-1.1) 也能够生成一个令人满意的凉鞋图像。
在二维空间中,自编码器只有少数几个维度可以使用,所以必须将图像分组压缩在一起,导致图像分组之间的空间相对较小。当我们在潜空间中使用更多维度来生成更复杂的图像(如人脸)时,这个问题会变得更加明显。如果我们让自编码器自由使用潜空间来编码图像,那么相似点之间就会有出现巨大的空白,因为自编码器中没有相应机制确保在这些空白空间生成合理的图像。
小结
自编码器通常由两部分组成:编码器和解码器。编码器将输入数据转化为低维编码表示,而解码器则将这个编码表示转化回原始数据的表示。在训练过程中,自编码器试图最小化重构误差,即输入数据与解码器输出之间的误差。通过使用这种方式,自编码器可以学习到数据的压缩表示,并且保留了数据的主要特征信息。利用自编码器可以利用潜空间向量生成新图像,但仍存在诸多问题,无法确保潜空间中的所有点均可以生成逼真图像。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)