ExoPlayer架构详解与源码分析(8)——Loader
系列文章目录
ExoPlayer架构详解与源码分析(1)——前言
ExoPlayer架构详解与源码分析(2)——Player
ExoPlayer架构详解与源码分析(3)——Timeline
ExoPlayer架构详解与源码分析(4)——整体架构
ExoPlayer架构详解与源码分析(5)——MediaSource
ExoPlayer架构详解与源码分析(6)——MediaPeriod
ExoPlayer架构详解与源码分析(7)——SampleQueue
ExoPlayer架构详解与源码分析(8)——Loader
文章目录
- 系列文章目录
- 前言
- ProgressiveMediaPeriod
- Loader
- ExtractingLoadable
- BundledExtractorsAdapter
- Extractor
- 总结
前言
ProgressiveMediaPeriod的左半部分SampleQueue已经在上篇讲完,相对今天说的这部分还算简单,ProgressiveMediaPeriod右半部分主要为Loader,而Loader中及包含数据的获取也包含数据的解析,本篇主要分析Loader的整体机构和数据解析部分结构。
ProgressiveMediaPeriod
还是先预习下上篇的整体结构,本篇主要分析右半半部分的Loader:
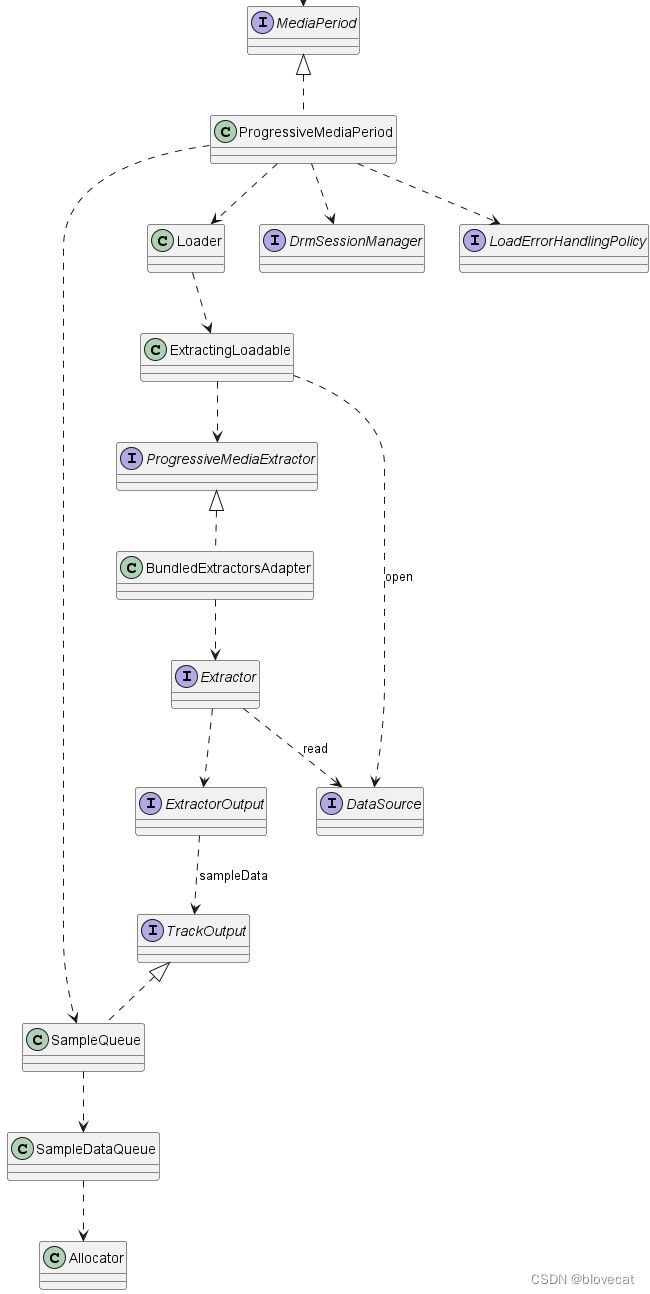
图中Loader数据的加载主要靠DataSource,而解析部分主要为Executor
Loader
Loader本质上就是就是一个线程池,初始化时就创建了一个ExecutorService,启动时实例化出一个LoadTask放入线程池中执行。
private final ExecutorService downloadExecutorService;
public Loader(String threadNameSuffix) {
this.downloadExecutorService =
Util.newSingleThreadExecutor(THREAD_NAME_PREFIX + threadNameSuffix);
}
public <T extends Loadable> long startLoading(
T loadable, Callback<T> callback, int defaultMinRetryCount) {
Looper looper = Assertions.checkStateNotNull(Looper.myLooper());//获取当前启动线程的looper
fatalError = null;
long startTimeMs = SystemClock.elapsedRealtime();
new LoadTask<>(looper, loadable, callback, defaultMinRetryCount, startTimeMs).start(0);
return startTimeMs;
}
LoadTask初始化时会传入当前线程的looper和callback,通过looper将后台线程的信息传递到启动线程的callback中执行,所以startLoading的线程必须要包含一个looper,callback也将在启动现场上调用。通常情况下启动线程就是内部播放线程,具体参照之前将的线程模型。
//@LoadTask.java
@Override
public void run() {
try {
boolean shouldLoad;
synchronized (this) {
shouldLoad = !canceled;
executorThread = Thread.currentThread();
}
if (shouldLoad) {
TraceUtil.beginSection("load:" + loadable.getClass().getSimpleName());
try {
loadable.load();//执行loadable
} finally {
TraceUtil.endSection();
}
}
synchronized (this) {
executorThread = null;
// Clear the interrupted flag if set, to avoid it leaking into a subsequent task.
Thread.interrupted();
}
if (!released) {
sendEmptyMessage(MSG_FINISH);//将执行结果通过handler发给启动线程looper
}
...
}
@Override
public void handleMessage(Message msg) {
if (released) {
return;
}
if (msg.what == MSG_START) {
execute();
return;
}
if (msg.what == MSG_FATAL_ERROR) {
throw (Error) msg.obj;
}
finish();
long nowMs = SystemClock.elapsedRealtime();
long durationMs = nowMs - startTimeMs;
Loader.Callback<T> callback = Assertions.checkNotNull(this.callback);
if (canceled) {
callback.onLoadCanceled(loadable, nowMs, durationMs, false);
return;
}
switch (msg.what) {
case MSG_FINISH:
try {
callback.onLoadCompleted(loadable, nowMs, durationMs);//执行完毕,在启动线程上调用callback
...
}
}
可以看到最终是调用了loadable.load方法
这个loadable定义在ProgressiveMediaPeriod的ExtractingLoadable中
ExtractingLoadable
ExtractingLoadable主要包含2个东西DataSource和ProgressiveMediaExtractor,DataSource负责从媒体数据源获取数据,而ProgressiveMediaExtractor则负责将获取的数据解析出Format和Metadata等sample到SampleQueue中,由此完成数据的加载
看下最核心的load方法。
@Override
public void load() throws IOException {
int result = Extractor.RESULT_CONTINUE;
while (result == Extractor.RESULT_CONTINUE && !loadCanceled) {//循环多次读取和sample数据
try {
long position = positionHolder.position;//获取当前的读取位置
dataSpec = buildDataSpec(position);//构建dataSource的dataSpec
long length = dataSource.open(dataSpec);//打开读取的流,返回实际数据的长度
if (length != C.LENGTH_UNSET) {
length += position;//获取加载后的长度
onLengthKnown();
}
...
progressiveMediaExtractor.init(//初始化ProgressiveMediaExtractor
extractorDataSource,//传入dataSource,此时的dataSource已经open可以直接通过调用dataSource的read获取数据
uri,
dataSource.getResponseHeaders(),
position,//当前读取位置
length,//流加载后的总长度
extractorOutput);//传入output,最终会关联输出到SampleQueue中
...
while (result == Extractor.RESULT_CONTINUE && !loadCanceled) {
try {
//当未open时阻塞当前执行,主要作用是当上层正在决定是否要继续加载时阻塞住下一次加载,
//当上层决定完可以继续加载时loadCondition.open()
//这里的上层决定一般由LoadControl做出,后面会讲到
loadCondition.block();
} catch (InterruptedException e) {
//如果不继续加载线程会等待,直到调用Loader的cancel方法会executorThread.interrupt();结束当前线程
throw new InterruptedIOException();
}
result = progressiveMediaExtractor.read(positionHolder);//读取并解析数据到,传入positionHolder用于更新下一次读取位置
long currentInputPosition = progressiveMediaExtractor.getCurrentInputPosition();//获取当前已经读取到的位置
//如果当前进度达到必要去继续加载检查的阈值时调用上层加载检查判断是否下次加载,这个阈值有个默认值为1024*1024
if (currentInputPosition > position + continueLoadingCheckIntervalBytes) {
position = currentInputPosition;
loadCondition.close();//阻塞下次加载
handler.post(onContinueLoadingRequestedRunnable);//通过回调询问上层是否需要继续加载
}
}
} finally {
if (result == Extractor.RESULT_SEEK) {//如果解析器返回RESULT_SEEK
result = Extractor.RESULT_CONTINUE;//就会再次open数据源,此时的Uri还是同一个,但是position可能已经在解析器中重新指定
} else if (progressiveMediaExtractor.getCurrentInputPosition() != C.INDEX_UNSET) {
positionHolder.position = progressiveMediaExtractor.getCurrentInputPosition();
}
DataSourceUtil.closeQuietly(dataSource);//关闭当前流
}
}
}
这里有2个While循环,第一个While循环说明同一个数据源可能会从不同的位置被打开多次,当内循环中解析数据需要SEEK跳过一段数据时就会,返回RESULT_SEEK,这个时候跳出内循环,再次执行外循环。下面会讲到什么时候需要SEEK数据,另外我们注意到Loader从打开数据加载操作1M(默认值)数据时就会阻塞住内循环,停止向SampleQueue中写入数据,而是向上层讯问是否需要继续加载数据,如果上层决定继续加载更多数据,就会调用ProgressiveMediaPeriod continueLoading解开阻塞的锁继续加载。因为我们知道数据是加载到内存中的,如果无限制的加载肯定是不行的,需要有节制的加载和释放数据。
接下看下ProgressiveMediaExtractor的实现BundledExtractorsAdapter。
BundledExtractorsAdapter
这个类相当于包裹了一个Extractor,最终读取工作其实是转发给Extractor,初始化时确认当前流对应的Extractor
@Override
public void init(
DataReader dataReader,
Uri uri,
Map<String, List<String>> responseHeaders,
long position,
long length,
ExtractorOutput output)
throws IOException {
//包装输入流
ExtractorInput extractorInput = new DefaultExtractorInput(dataReader, position, length);
this.extractorInput = extractorInput;
if (extractor != null) {
return;
}
//extractorsFactory通过网络请求的返回的Content-Type和文件的后缀名获取按优先级创建一个Extractor列表
Extractor[] extractors = extractorsFactory.createExtractors(uri, responseHeaders);
if (extractors.length == 1) {
this.extractor = extractors[0];
} else {
for (Extractor extractor : extractors) {
try {
//通过调用extractor方法获取流的头部信息最终确定当前流是否可以用这个extractor来解析,如TS就是通过判断0x47同步位来确定的
if (extractor.sniff(extractorInput)) {
this.extractor = extractor;
break;
}
} catch (EOFException e) {
// Do nothing.
} finally {
Assertions.checkState(this.extractor != null || extractorInput.getPosition() == position);
extractorInput.resetPeekPosition();
}
}
if (extractor == null) {//没有支持解析的extractor报错
throw new UnrecognizedInputFormatException(
"None of the available extractors ("
+ Util.getCommaDelimitedSimpleClassNames(extractors)
+ ") could read the stream.",
Assertions.checkNotNull(uri));
}
}
extractor.init(output);//初始化extractor
}
@Override
public int read(PositionHolder positionHolder) throws IOException {
return Assertions.checkNotNull(extractor)
.read(Assertions.checkNotNull(extractorInput), positionHolder);//将数据的读取解析转发给extractor
}
Extractor
主要将媒体数据从容器格式中解析出来,支持很多容器格式,每种都做了实现,有很多下图只列了一部分
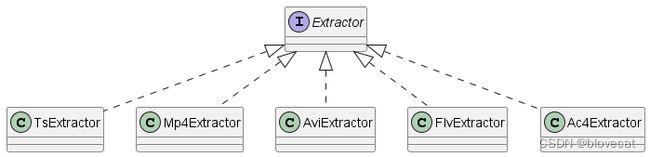
FileTypes类里定义了这些格式,inferFileTypeFromUri可以看出他们与文件后缀之间的对应关系
public static @FileTypes.Type int inferFileTypeFromUri(Uri uri) {
@Nullable String filename = uri.getLastPathSegment();
if (filename == null) {
return FileTypes.UNKNOWN;
} else if (filename.endsWith(EXTENSION_AC3) || filename.endsWith(EXTENSION_EC3)) {
return FileTypes.AC3;
} else if (filename.endsWith(EXTENSION_AC4)) {
return FileTypes.AC4;
} else if (filename.endsWith(EXTENSION_ADTS) || filename.endsWith(EXTENSION_AAC)) {
return FileTypes.ADTS;
} else if (filename.endsWith(EXTENSION_AMR)) {
return FileTypes.AMR;
} else if (filename.endsWith(EXTENSION_FLAC)) {
return FileTypes.FLAC;
} else if (filename.endsWith(EXTENSION_FLV)) {
return FileTypes.FLV;
} else if (filename.endsWith(EXTENSION_MID)
|| filename.endsWith(EXTENSION_MIDI)
|| filename.endsWith(EXTENSION_SMF)) {
return FileTypes.MIDI;
} else if (filename.startsWith(
EXTENSION_PREFIX_MK,
/* toffset= */ filename.length() - (EXTENSION_PREFIX_MK.length() + 1))
|| filename.endsWith(EXTENSION_WEBM)) {
return FileTypes.MATROSKA;
} else if (filename.endsWith(EXTENSION_MP3)) {
return FileTypes.MP3;
} else if (filename.endsWith(EXTENSION_MP4)
|| filename.startsWith(
EXTENSION_PREFIX_M4,
/* toffset= */ filename.length() - (EXTENSION_PREFIX_M4.length() + 1))
|| filename.startsWith(
EXTENSION_PREFIX_MP4,
/* toffset= */ filename.length() - (EXTENSION_PREFIX_MP4.length() + 1))
|| filename.startsWith(
EXTENSION_PREFIX_CMF,
/* toffset= */ filename.length() - (EXTENSION_PREFIX_CMF.length() + 1))) {
return FileTypes.MP4;
} else if (filename.startsWith(
EXTENSION_PREFIX_OG,
/* toffset= */ filename.length() - (EXTENSION_PREFIX_OG.length() + 1))
|| filename.endsWith(EXTENSION_OPUS)) {
return FileTypes.OGG;
} else if (filename.endsWith(EXTENSION_PS)
|| filename.endsWith(EXTENSION_MPEG)
|| filename.endsWith(EXTENSION_MPG)
|| filename.endsWith(EXTENSION_M2P)) {
return FileTypes.PS;
} else if (filename.endsWith(EXTENSION_TS)
|| filename.startsWith(
EXTENSION_PREFIX_TS,
/* toffset= */ filename.length() - (EXTENSION_PREFIX_TS.length() + 1))) {
return FileTypes.TS;
} else if (filename.endsWith(EXTENSION_WAV) || filename.endsWith(EXTENSION_WAVE)) {
return FileTypes.WAV;
} else if (filename.endsWith(EXTENSION_VTT) || filename.endsWith(EXTENSION_WEBVTT)) {
return FileTypes.WEBVTT;
} else if (filename.endsWith(EXTENSION_JPG) || filename.endsWith(EXTENSION_JPEG)) {
return FileTypes.JPEG;
} else if (filename.endsWith(EXTENSION_AVI)) {
return FileTypes.AVI;
} else {
return FileTypes.UNKNOWN;
}
}
从这些代码中可以看出EXO所支持的媒体容器格式。
下篇我们以TS容器格式为例,讲解下TsExtractor,了解媒体数据如何从容器格式中解析出来,最终要交给Readerer渲染的。
总结
Loader主要作用就是将加载逻辑放入线程池中管理,然后通过ExtractingLoadable控制数据的加载,而数据主要由DataSource来获取,解析部分主要为Executor,Executor通过持有已经open的DataSource,不断从DataSource中read出数据用来解析媒体,整个过程都只有一个线程,即使到了数据加载部分也是在同一个线程中同步加载的,在这段同步操作中还将加载的控制权交给了上层组件。下篇将会把TsExtractor作为一个典型的解析器,来分析解析器的具体作用和执行过程。
版权声明 ©
本文为CSDN作者山雨楼原创文章
转载请注明出处
原创不易,觉得有用的话,收藏转发点赞支持