Yolov5 口罩识别
自定义口罩数据集进行目标检测
目录
- 自定义口罩数据集进行目标检测
-
- Yolov5 代码地址
- 数据集
-
- 一、手动收集标记数据集
- 二、使用公开数据集
- 改动源码
- 训练结果
- 迁移学习
- 制作自定义数据集的注意事项
Yolov5 代码地址
https://github.com/ultralytics
数据集
数据集可以手动标记或者使用公开数据集
一、手动收集标记数据集
使用Labelimg软件标记,网上有很多介绍
软件下载
二、使用公开数据集
https://public.roboflow.com/
以口罩数据集为例: 口罩数据集
训练图片只有105张,比较少,仅用作实验,实际做项目时每个类别的图片至少有1500张,并且图片应用场景要多种多样。
下载解压后后改名为MASK,内容如下(可能有区别),要用的只有 train和valid文件夹。
改动源码
Yolov5
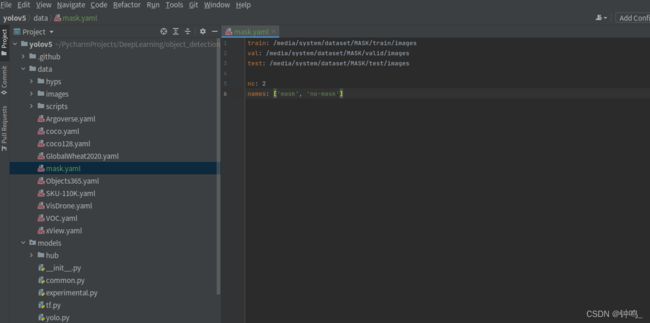
下载好yolov5源码,打开后在data文件夹下新建mask.yaml,填入以下信息,前三行改为自己MASK文件的绝对路径
train: /media/system/dataset/MASK/train/images
val: /media/system/dataset/MASK/valid/images
test: /media/system/dataset/MASK/test/images
nc: 2
names: ['mask', 'no-mask']
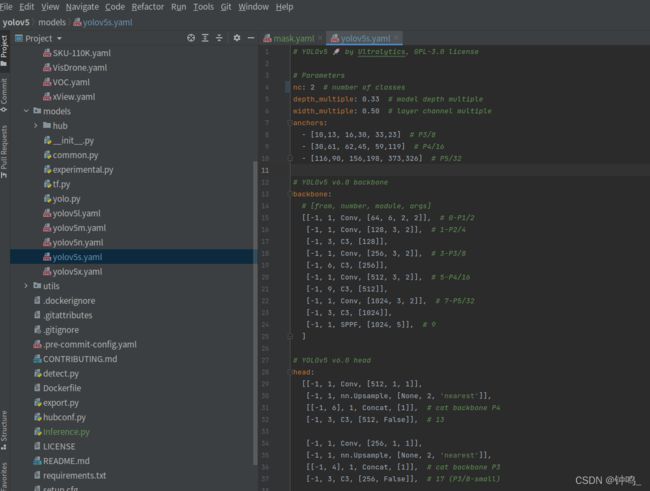
数据集中只有mask和no-mask2个类别,修改yolov5/models/yolov5s.yaml,将第四行的 nc = 80修改为nc = 2
接下来执行训练命令
python3 train.py --img 640 --batch 8 --epochs 500 --data data/mask.yaml --cfg models/yolov5s.yaml --weights ''
会自动下载Yolov5s的预训练模型进行训练
训练结果
打开wandb注册账号,登录,按照提示操作
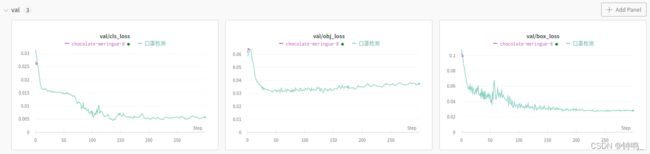
训练过程会在wandb中清楚地显示出来,方便调参。
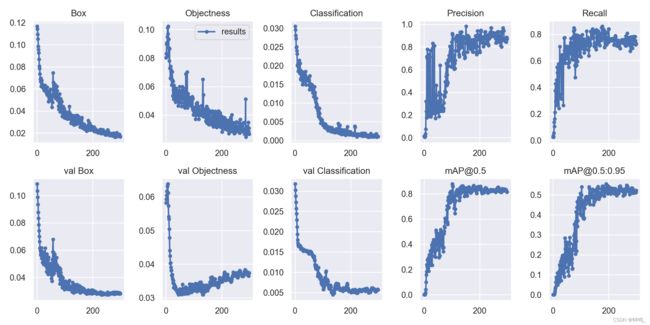
总的结果
训练结果测试
mAP
 train的三个损失函数
train的三个损失函数
 val的三个损失函数
val的三个损失函数
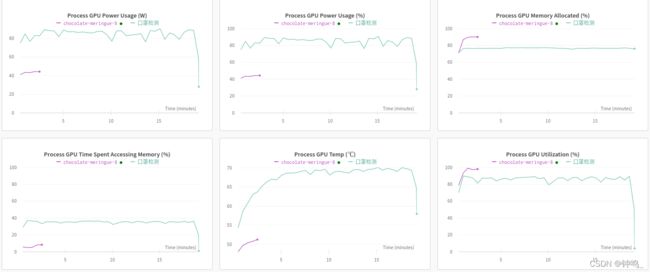
 GPU监控
GPU监控
学习速率
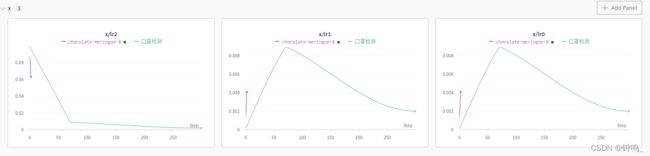
可以看出虽然训练样本很少,但是训练的结果还是不错的。这主要是因为用了yolov5在coco数据集上预训练的模型,特征比较丰富,而且口罩检测的类别少,只有两类,区分度较大,带不带口罩很容易看出来。
迁移学习
为了加快训练速度,可以采用迁移学习,冻结前面的特征层,只训练后面的检测层或者其他自定义的卷积层
data/yolov5s.yaml
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
yolov5 基本框架是24层,但是yolov5s模型参数较少,对模型进行了缩放,深度变成了三分之一,宽度变成了二分之一。
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
不用管他,因为yolov5的所有模型都是24层,只不过不同模型的每一层不一样而已。
看到每个模块的名称:
for k, v in model.named_parameters():
print(k)
# Output
model.0.conv.conv.weight
model.0.conv.bn.weight
model.0.conv.bn.bias
model.1.conv.weight
model.1.bn.weight
model.1.bn.bias
model.2.cv1.conv.weight
model.2.cv1.bn.weight
...
model.23.m.0.cv2.bn.weight
model.23.m.0.cv2.bn.bias
model.24.m.0.weight
model.24.m.0.bias
model.24.m.1.weight
model.24.m.1.bias
model.24.m.2.weight
model.24.m.2.bias
算法在源码中是这样实现的:
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f'freezing {k}')
v.requires_grad = False
如果要冻结0到9层,只需要如下命令:
python train.py --freeze 10
如果要训练所有特征层,只训练最后的Detect layer,只需要输入:
python train.py --freeze 24
完整的训练过程应该是:
- 冻结backbone层,只训练head层
- 解冻backbone层进行训练,冻结head层
- 将学习速率调小,训练整个网络
当样本分类较少,或者样本数量较少时,也可以直接冻结除了Detect层之外的所有层,就是说将预训练模型当做特征提取器使用。
制作自定义数据集的注意事项
-
每个分类的图像推荐大于1500张图片。
-
每个分类标注的实例大于10000个。
-
收集的图片要多种多样,需要不同时间,不同的季节,不同的天气,不同的照明,不同角度,不同的来源的图片。
-
标签一致性。必须标记所有图像中所有类的所有实例。应该被标记的实例不能缺少标记。
-
标签准确性。标签必须紧密包围每个对象。被框住得到对象和边界框之间不能有空间,要很紧密。所有标记的对象都要有标签。
-
丰富的背景。数据集除了有被标记的实例的图像之外,还需要有没有任何标记的图像,建议大约收集0-10%的背景图像来帮助减少FPs。