开源大模型部署及推理所需显卡成本必读之一
一、系统内存与架构
在人工智能大模型训练的过程中,常常会面临显存资源不足的情况,其中包括但不限于以下两个方面:1.经典错误:CUDA out of memory. Tried to allocate ...;2.明明报错信息表明显存资源充足,仍然发生 OOM 问题。为了深入理解问题的根源并寻求解决方案,必须对系统内存架构以及显存管理机制进行进一步的探究。本文将为读者带来对这些基础知识的全面学习与了解。

系统内存与两块GPU设备的交互示意图
系统存储:
- L1/L2/L3:多级缓存,其位置一般在CPU芯片内部;
- System DRAM:片外内存,如:内存条;
- Disk/Buffer:外部存储,如:磁盘或者固态硬盘。
GPU设备存储:
- L1/L2 cache:多级缓存,其位置在GPU芯片内部;
- GPU DRAM:通常所指的显存;
- 设备存储还包含许多片上存储单元,后面进行详细介绍。
传输通道: 存储与存储之间通过传输协议/通道进行数据交换。
- PCIE BUS:PCIE标准的数据通道,数据就是通过该通道从显卡到达主机;
- BUS:总线。计算机内部各个存储之间交互数据的通道;
- PCIE-to-PCIE:显卡之间通过PCIE直接传输数据;
- NVLINK:显卡之间的一种专用的数据传输通道,由NVIDIA公司推出。
模型训练涉及到多个关键概念,下面是显存和内存之间的关系以及在训练过程中的作用:
- 显卡GPU:GPU的内存硬件存储介质与CPU的类似,主要的区别是设计的结构有所差异。GPU内存硬件的分类,按照是否在芯片上面可以分为片上(on chip)内存和片下(off chip)内存,片上内存主要用于缓存(cache)以及少量特殊存储单元(如texture),特点:速度快,存储空间小;片下内存主要用于全局存储(global memory) 即常说的显存,特点:速度相对慢,存储空间大。GPU的内部存储分为片上存储和片下存储,指的硬件所在位置,为了满足GPU的应用场景,对存储功能进行了细分,包括:局部内存(local memory)、全局内存(global memory)、常量内存(constant memory)、图像/纹理(texture memory)、共享内存(shared memory)、寄存器(register)、L1/L2缓存、常量内存/纹理缓存(constant/texture cache)。
- 显存(GPU显存):显存是位于图形处理单元(GPU)上的内存,用于存储模型的参数、权重、中间计算结果以及训练数据的一部分。由于GPU在并行计算方面的强大性能,显存通常用于高效地执行模型的前向传播、反向传播和优化算法。显存的大小限制了可以训练的模型大小以及每次批量处理的样本数量。
- 内存(系统内存):内存是计算机系统中的主要存储区域,用于存储程序代码、数据和运行时状态。在AI模型训练过程中,内存主要用于存储模型的源代码、训练数据的加载、预处理以及一些中间计算结果。与显存相比,内存通常具有更大的容量,但速度相对较慢。
在AI模型训练过程中,显存和内存之间的交互是关键的:
- 数据加载与预处理:训练数据通常存储在内存或者分布式存储中,然后通过批量加载到显存中进行训练。在加载数据时,可能需要进行预处理(如归一化、数据增强等),这些预处理步骤可能会涉及内存和显存之间的数据传输。
- 前向传播和反向传播:在训练期间,模型的前向传播(计算输出)和反向传播(计算梯度)都涉及显存中的模型参数和权重。这些计算会在GPU上高效执行,利用了其并行计算能力。
- 梯度计算与参数更新:在反向传播过程中,计算得到的梯度用于更新模型的参数和权重。这一过程可能涉及到从显存到内存的数据传输,因为参数更新可能需要在内存中进行。
- 批量处理和优化算法:大多数训练过程中会使用批量处理(mini-batch)的方式,每个批次的数据都会在显存中加载和处理。优化算法(如梯度下降)的执行通常涉及显存中的参数和梯度计算。
显存和内存在AI模型训练中扮演着关键角色,它们之间的高效协同工作有助于加速训练过程并降低资源消耗。同时,合理的显存管理和数据处理策略可以提高训练效率和性能。
在模型训练阶段和推理阶段,优化内存使用都是非常重要的,因为内存是有限资源,合理管理内存可以提高性能和效率。以下是在这两个阶段分别优化内存的一些方法:
模型训练阶段优化内存:
- 批量处理(Mini-Batch):使用批量处理技术可以有效减少每次迭代中的内存使用。在每个迭代中,只需要加载和处理一个批次的数据,而不是全部数据,这可以显著减少内存需求。
- 数据预处理和增强:在加载数据之前,对数据进行预处理(如归一化、裁剪等)和数据增强(如随机翻转、旋转等)可以减少需要存储的中间结果,从而降低内存使用。
- 梯度累积(Gradient Accumulation):在某些情况下,可以将多个小批次的梯度累积起来,然后一次性进行参数更新。这样可以减少每次梯度计算产生的内存消耗。
- 混合精度训练:使用混合精度训练(例如,使用半精度浮点数)可以减少模型参数和梯度的内存占用,同时保持训练稳定性。这需要硬件和深度学习框架的支持。
- 模型并行和数据并行:对于大型模型,可以将模型分成多个部分,分别在不同的GPU上训练(模型并行),或者将不同批次的数据分布在不同GPU上进行处理(数据并行)。这可以减少单个GPU上的内存需求。
推理阶段优化内存:
- 轻量化模型设计:在推理阶段,可以考虑使用轻量级模型结构,如移动设备上的MobileNet、EfficientNet等,以减少内存占用和计算量。
- 模型剪枝和量化:通过模型剪枝(移除冗余参数)和量化(降低参数精度)可以显著减少模型的内存占用,同时保持合理的性能。
- 模型压缩和量化:使用模型压缩技术(如Knowledge Distillation)可以将复杂模型的知识传递给一个更小的模型,从而在内存占用和性能之间找到平衡点。
- Batch Size设置:在推理阶段,较小的批次大小可以减少内存使用。但要注意,过小的批次大小可能会影响推理性能。
- 内存复用和延迟加载:在推理过程中,可以考虑使用内存复用技术,即重复使用某些中间计算结果,以减少重复计算和内存开销。另外,使用延迟加载可以在需要时才加载数据,减少内存占用。
总之,在模型训练和推理阶段都有许多策略可以优化内存使用。选择适合您应用场景的策略,可以提高性能、减少资源消耗,并确保您的计算资源得到了最大程度的利用。
二、模型训练重要指标
最重要的两个指标:
- 显存占用
- GPU利用率
显存占用和GPU利用率是两个不一样的东西,显卡是由GPU计算单元和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。显存可以看成是空间,类似于内存。
- 显存用于存放模型、数据;
- 显存越大,所能运行的网络也就越大;
GPU计算单元类似于CPU中的核,用来进行数值计算。衡量GPU计算量的单位通常是FLOPS,即每秒浮点运算次数(Floating Point Operations Per Second):每秒能执行的flop数量。FLOPS值越大,计算能力越强大、速度越快。
神经网络模型占用显存的包括:
- 模型自身的参数
- 模型的输出
2.1 参数的显存占用
只有有参数的层,才会占用显存。这部份的显存占用和输入无关,模型加载完成之后就会占用。
有参数的层:
- 卷积
- 全连接
- BatchNorm
- Embedding层
- ... ...
无参数的层:
- 多数的激活层(Sigmoid/ReLU)
- 池化层
- Dropout
- ... ...
模型的参数数目:
- Linear(M->N)全连接参数数目:M×N
- Conv2d(Cin, Cout, K)卷积参数数目:Cin × Cout × K × K
- BatchNorm(N) BatchNorm参数数目:2N
- Embedding(N,W) Embedding参数数目:N × W
参数占用显存 = 参数数目 × n
- n = 4 : float32
- n = 2 : float16
- n = 8 : double64
Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用 4 Byte显存。
在PyTorch中,执行 model = MyModel().cuda() 之后就会输出占用显存大小,占用的显存大小基本与上述分析的显存差不多(会稍大一些,因为其它开销)。
2.2 梯度与动量的显存占用
模型中与输入无关的显存占用包括:
- 参数 W
- 梯度 dW(一般与参数一样)
- 优化器的动量(普通SGD没有动量,momentum-SGD动量与梯度一样,Adam优化器动量的数量是梯度的两倍)
2.3 输入输出的显存占用
输入输出的显存主要看输出的feature map 的形状:
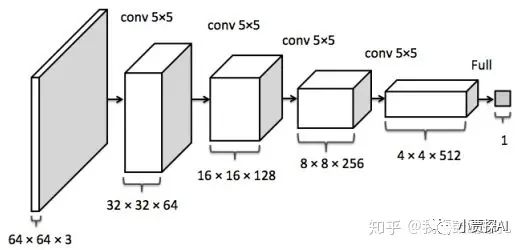
模型输出的显存占用:
- 需要计算每一层的feature map的形状(多维数组的形状)
- 需要保存输出对应的梯度用以反向传播(链式法则)
- 显存占用与 batch size 成正比
- 模型输出不需要存储相应的动量信息。
- 深度学习中神经网络的显存占用,我们可以得到如下公式:
显存占用 = 模型显存占用 + batch\_size × 每个样本的显存占用
可以看出显存不是和batch-size简单的成正比,尤其是模型自身比较复杂的情况下:比如全连接很大,Embedding层很大。
另外需要注意:
- 输入(数据,图片)一般不需要计算梯度
- 神经网络的每一层输入输出都需要保存下来,用来反向传播,但是在某些特殊的情况下,我们可以不要保存输入。比如ReLU,在PyTorch中,使用nn.ReLU(inplace = True) 能将激活函数ReLU的输出直接覆盖保存于模型的输入之中,节省不少显存。
2.3 节省显存的方法
在深度学习中,一般占用显存最多的是卷积等层的输出,模型参数占用的显存相对较少,而且不太好优化。
节省显存方法:
- 降低batch-size
- 下采样(NCHW -> (1/4)*NCHW)
- 减少全连接层(一般只留最后一层分类用的全连接层)
总结
- 时间更宝贵,尽可能使模型变快(减少flops)
- 显存占用不是和batch size简单成正比,模型自身的参数及其延伸出来的数据也要占据显存
- batch size越大,速度未必越快。在你充分利用计算资源的时候,加大batch size在速度上的提升很有限
尤其是batch-size,假定GPU处理单元已经充分利用的情况下:
- 增大batch size能增大速度,但是很有限(主要是并行计算的优化)
- 增大batch size能减缓梯度震荡,需要更少的迭代优化次数,收敛的更快,但是每次迭代耗时更长。
- 增大batch size使得一个epoch所能进行的优化次数变少,收敛可能变慢,从而需要更多时间才能收敛(比如batch\_size 变成全部样本数目)。
在模型整个训练过程中中,占用显存大概分以下几类:
- 模型中的参数(卷积层或其他有参数的层)
- 模型在计算时产生的中间参数(即输入图像在计算时每一层产生的输入和输出)
- backward的时候产生的额外的中间参数
- 优化器在优化时产生的额外的模型参数 但其实,我们占用的显存空间为什么比我们理论计算的还要大,原因大概是因为深度学习框架一些额外的开销。
如何进一步优化
除了算法层的优化,最基本的优化方式如下:
- 减少输入数据单条的大小
- 减少batch\_size,减少每次的输入数据批量大小
- 多使用下采样,池化层
- 一些神经网络层可以进行小优化,利用relu层中设置inplace
- 购买显存更大的显卡
- 深度学习框架侧
三、显存经典异常
了解显存管理机制主要是为了减少显存碎片化带来的影响。也就解决了我们经常遇到的一些问题:为什么报错信息里提示显存够,但还是遇到了 OOM?
经典异常 CUDA OOM
malloc 分配失败的情况下的错误信息:
CUDA out of memory. Tried to allocate 1.24 GiB (GPU 0; 15.78 GiB total capacity; 10.34 GiB already allocated; 456.50 MiB free; 14.21 GiB reserved in total by PyTorch)
- Tried to allocate:指本次 malloc 时预计分配的 alloc\_size;
- total capacity:由 cudaMemGetInfo 返回的 device 显存总量;
- already allocated:由统计数据记录,当前为止请求分配的 size 的总和;
- free:由 cudaMemGetInfo 返回的 device 显存剩余量;
- reserved:BlockPool 中所有 Block 的大小,与已经分配的 Block 大小的总和。即:reserved = already allocated + sum size of 2 BlockPools
注意: reserved + free 并不等同于 total capacity,因为 reserved 只记录了通过 PyTorch 分配的显存,如果用户手动调用 cudaMalloc 或通过其他手段分配到了显存,是没法在这个报错信息中追踪到的(又因为一般 PyTorch 分配的显存占大部分,分配失败的报错信息一般也是由 PyTorch 反馈的)。
在这个例子里,device 只剩 456.5MB,不够 1.24GB,而 PyTorch 自己保留了 14.21GB(储存在 Block 里),其中分配了 10.3GB,剩 3.9GB。那为什么不能从这 3.9GB 剩余当中分配 1.2GB 呢?原因肯定是显存碎片化了。
实现自动碎片整理的关键特性:split
通过环境变量会指定一个阈值 max\_split\_size\_mb,实际上从变量名可以看出,指定的是最大的可以被 "split" 的 Block 的大小。
被 split 的操作很简单,当前的 Block 会被拆分成两个 Block,第一个大小正好为请求分配的 size,第二个则大小为 remaining,被挂到当前 Block 的 next 指针上(这一过程见源码 L570~L584)。这两个 Block 的地址自然而然成为连续的了。随着程序运行,较大的 Block(只要仍小于阈值 max\_split\_size\_mb)会不断被分成小的 Block。值得注意的是,由于新 Block 的产生途径只有一条,即通过步骤三中的 alloc\_block 函数经由 cudaMalloc 申请,无法保证新 Block 与其他 Block 地址连续,因此所有被维护在双向链表内的有连续地址空间的 Block 都是由一个最初申请来的 Block 拆分而来的。
一段连续空间内部(由双向链表组织的 Blocks)如图所示:

当 Block 被释放时,会检查其 prev、next 指针是否为空,及若非空是否正在被使用。若没有在被使用,则会使用 try\_merge\_blocks (L1000) 合并相邻的 Block。由于每次释放 Block 都会检查,因此不会出现两个相邻的空闲块,于是只须检查相邻的块是否空闲即可。这一检查过程见 free\_block 函数(L952)。又因为只有在释放某个 Block 时才有可能使多个空闲块地址连续,所以只需要在释放 Block 时整理碎片即可。
关于阈值 max\_split\_size\_mb ,直觉来说应该是大于某个阈值的 Block 比较大,适合拆分成稍小的几个 Block,但这里却设置为小于这一阈值的 Block 才进行拆分。个人理解是,PyTorch 认为,从统计上来说大部分内存申请都是小于某个阈值的,这些大小的 Block 按照常规处理,进行拆分与碎片管理;但对大于阈值的 Block 而言,PyTorch 认为这些大的 Block 申请时开销大(时间,失败风险),可以留待分配给下次较大的请求,于是不适合拆分。默认情况下阈值变量 max\_split\_size\_mb 为 INT\_MAX,即全部 Block 都可以拆分。可能有的人有开始有了疑问:如果全部 Block 都拆分了,碎片整理后还是OOM怎么办?
四、总结
在训练规模庞大的模型训练时,GPU显得至关重要,然而,GPU资源的可用性常常面临严重不足的局面。这种情况可能由于模型尺寸过大,导致显存空间不足,进而影响训练进程的顺利进行。为了克服这一难题,我们迫切需要深入探究其根本原因,并对其背后的工作原理有深入的理解。只有这样,才能针对具体情况施以恰当的策略,实现对GPU资源的有效利用,确保训练任务能够高效进行。
五、版权说明
转载自智源社区老刘说NLP
更多技术文档请访问365文档