spring三级缓存解决循环依赖
一、循环依赖:
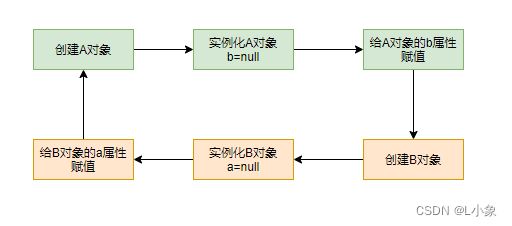
简单说就是 A类中有B属性,B类中有A属性。创建A对象时发现有B属性,就开始创建B对象,此时时又发现B对象中有A属性,又要创建A对象,产生循环依赖现象。示例图:
二、Spring解决循环依赖
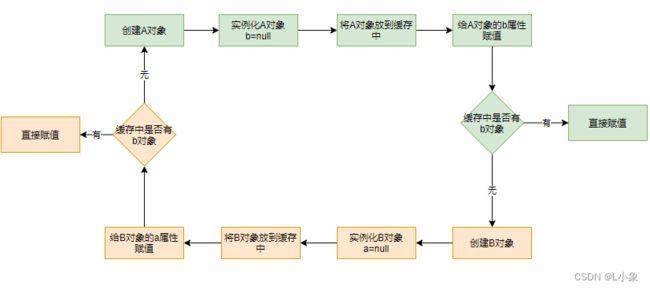
使用缓存解决循环依赖的流程图
spring的三级缓存
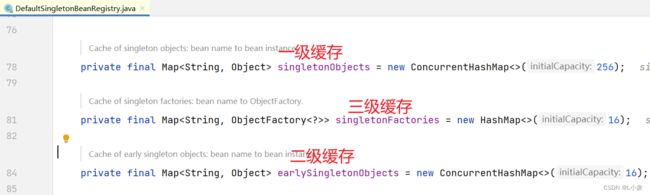
一级缓存(singletonObjects):单例池,已经完成实例化、初始化的对象。
二级缓存(earlySingletonObjects):早期单例对象,已经实例化、未初始化的对象。用于决绝循环依赖问题。
三级缓存(singletonFactoryies):单例工厂,存放对象的lambda表达式。用于解决存在代理的循环依赖问题。
创建过程
创建过程中标志性的方法:

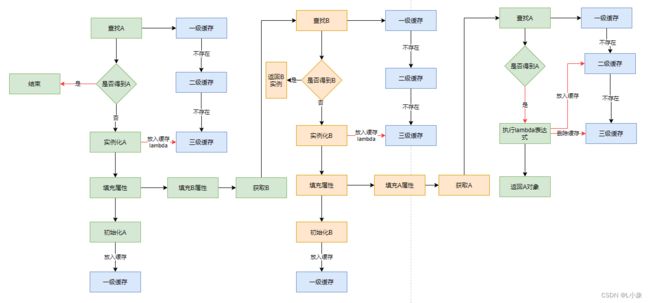
创建过程流程图:
1、创建A
步骤一:查找A
查询一级缓存 -----> 查询二级缓存----> 查询三级缓存
三个级别的缓存中都没有A,创建A
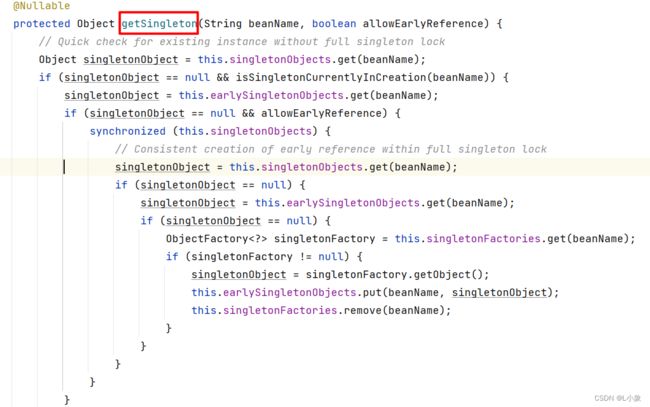
步骤二:创建A
调用lambda的getObjtct()方法,执行 createBean() 操作。
createBean内部会执行方法:createBean ---> doCreateBean ---> createBeanInstance ---> instantiateBean ---> populateBean

A示例化后,会将A示例、beanName、RootBeanDefiniton封装成lambda表达式,放到三级缓存中,待出现循环依赖时使用。
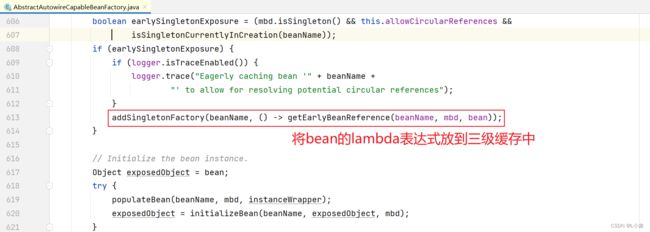
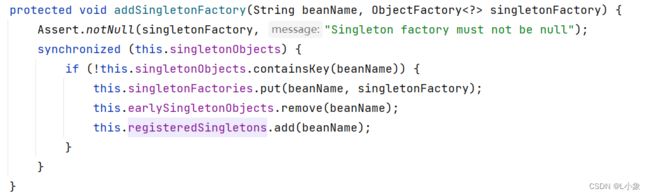
步骤三:A填充属性
执行 AbstractAutowireCapableBeanFactory 类的 createBean 中 populateBean,给A填充属性。
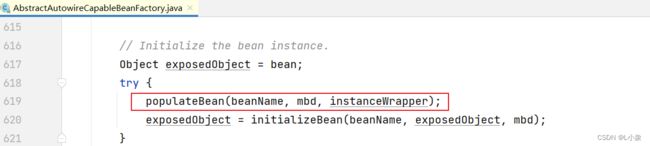
填充B属性:获取B,执行获取B的操作(执行下面步骤:2、创建B)
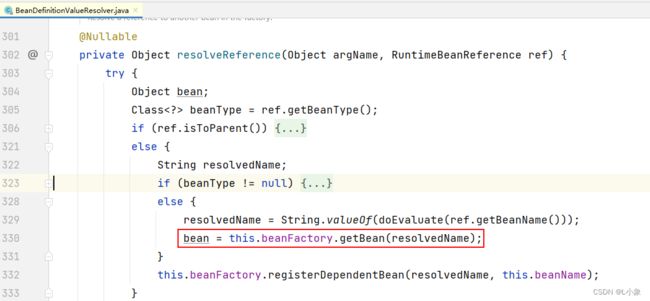
步骤四:初始化A
确定最终的A,如果没有AOP代理操作,直接返回原始对象,如果存在AOP代理,返回的就是代理对象A。
将初始化之后的A放到一级缓存中。
2、创建B
步骤一:查找B
查询一级缓存 -----> 查询二级缓存----> 查询三级缓存,没有发现B,执行实例化B的操作。
步骤二:创建B
执行方法:createBean ---> doCreateBean ---> createBeanInstance ---> instantiateBean
步骤三:B填充属性
执行 populateBean()方法进行属性填充。填充B实例中A的属性,开始获取A:
查找A:查询一级缓存 -----> 查询二级缓存----> 查询三级缓存,发现三级缓存汇总有A:执行lambda表达式获得最终的A实例;将A实例放到二级缓存中,并三级缓存中删除。
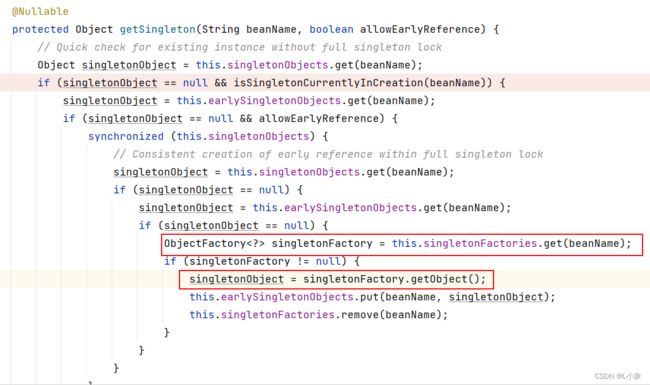
提前暴露A:A正在创建中,此时对象B需要A对象,就会提前将A对象暴露出来,放到二级缓存中。此时的A是半成品,但却是最终的类型(原始类型/代理类型)
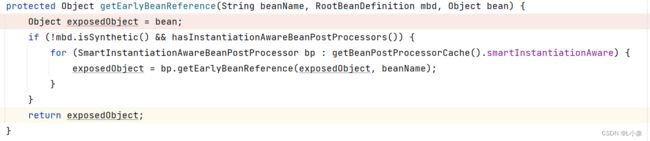
得到A实例之后,将值复制给B实例的A属性。此时B对象填充完毕。
步骤四:初始化B
确定最终的B,如果没有AOP代理操作,直接返回原始对象,如果存在AOP代理,返回的就是代理对象B。将初始化之后的B放到一级缓存中。
此时回到给A填充属性步骤:将B实例赋值给A实例的B属性,A实例化完成。之后对A初始化,得到最终的A对象,并将A对象放到一级缓存(单例池)中,A创建完成。
三、问题
1、为什么三级缓存的作用主要是解决aop循环依赖问题?
代理对象实现:首先通过实例化生成原始对象,再通过初始化生成代理对象。
当出现循环依赖时,会出现对象还未初始化完成,就需要被暴露使用。此时必须确定出到底是原始对象还是代理对象。所以通过lambda表达式的方式,相当于一中回调机制来确定出最终是代理对象还是原始对象。
填充对象属性、实例化对象:
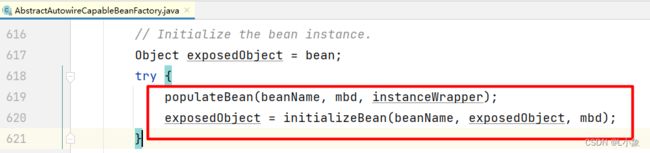
B填充属性时需要提前暴露出来A,即执行三级缓存中的lambda表达式:
A实例化完成,B实例化、初始化完成时,循环依赖效果图:
此时A是原始对象,A中的B属性是最终对象,B对象中的A属性是最终的代理对象。A执行完初始化之后,也会变成代理对象被放入一级缓存。
假如没有三级缓存,此时A对象是原始对象,B对象中的A对象也是原始对象。A经过初始化之后生成代理对象被放入一级缓存中。此时最终的A对象是代理对象,B使用的是A的原始对象,将会出现对象不一致的问题。