SpringCloud-3-基础组件(zuul,gateway,sleuth)
目录
1 微服务网关概述
1.1 服务网关的概念
1.1.1 什么是微服务网关
1.1.2 作用和应用场景
1.2 常见的API网关实现方式
1.3 基于Nginx的网关实现
1.3.1 Nginx介绍
1.3.3 准备工作
1.3.4 配置Nginx的请求转发
1.3.5 访问nginx
2 微服务网关Zuul
2.1 Zuul简介
2.2 搭建Zuul网关服务器
2.3 Zuul中的路由转发
2.3.1 面向服务的路由
2.3.2 简化的路由配置
2.3.3 默认的路由规则
2.3.4 Zuul加入后的架构
2.4 Zuul中的过滤器
2.4.1 ZuulFilter简介
2.4.2 生命周期
2.4.3 自定义过滤器
2.5 服务网关Zuul的核心源码解析
2.6 Zuul网关存在的问题
3 微服务网关GateWay
3.1 Gateway简介
3.1.1 简介
3.1.2 核心概念
3.2 入门案例
3.2.1 入门案例
3.2.2 路由规则
实例:
3.2.3 动态路由
3.2.4 重写转发路径
3.3 过滤器
3.3.1 过滤器基础
3.3.2 局部过滤器
3.3.3 全局过滤器
3.4 统一鉴权
3.4.1 鉴权逻辑
3.4.2 代码实现
3.5 网关限流
3.5.2 基于Filter的限流
3.5.3 基于Sentinel的限流
3.6 网关高可用
3.7 执行流程分析
4 微服务的链路追踪概述
4.1 微服务架构下的问题
4.2 Sleuth概述
4.2.1 简介
4.2.2 相关概念
4.3 链路追踪Sleuth入门
4.4 Zipkin的概述
4.5 Zipkin Server的部署和配置
4.6 客户端Zipkin+Sleuth整合
4.7 基于消息中间件收集数据
4.7.1 RabbitMQ的安装与启动
4.8 存储跟踪数据
4.8.1 准备数据库
1 微服务网关概述


- 客户端会请求多个不同的服务,需要维护不同的请求地址,增加开发难度
- 在某些场景下存在跨域请求的问题
- 加大身份认证的难度,每个微服务需要独立认证
因此,我们需要一个微服务网关,介于客户端与服务器之间的中间层,所有的外部请求都会先经过微服务网关。客户端只需要与网关交互,只知道一个网关地址即可,这样简化了开发还有以下优点:
- 易于监控
- 易于认证
- 减少了客户端与各个微服务之间的交互次数

1.1 服务网关的概念
1.1.1 什么是微服务网关
1.1.2 作用和应用场景
1.2 常见的API网关实现方式
1.3 基于Nginx的网关实现
1.3.1 Nginx介绍
1.3.3 准备工作
- 启动 shop_service_order 微服务,单独请求地址:http://127.0.0.1:9001/
- 启动 shop_service_product 微服务,单独请求地址:http://127.0.0.1:9002/
- 安装资料中提供的ngnix。找到ngnix.exe双击运行即可
1.3.4 配置Nginx的请求转发
在\nginx-1.8.0\conf\nginx.conf中配置
location /api-order {
proxy_pass http://127.0.0.1:9001/;
}
location /api-product {
proxy_pass http://127.0.0.1:9002/;
}1.3.5 访问nginx
localhost:80
2 微服务网关Zuul
2.1 Zuul简介
- 动态路由:动态将请求路由到不同后端集群
- 压力测试:逐渐增加指向集群的流量,以了解性能
- 负载分配:为每一种负载类型分配对应容量,并弃用超出限定值的请求
- 静态响应处理:边缘位置进行响应,避免转发到内部集群
- 身份认证和安全: 识别每一个资源的验证要求,并拒绝那些不符的请求。Spring Cloud对Zuul进行了整合和增强。
2.2 搭建Zuul网关服务器
org.springframework.cloud
spring-cloud-starter-netflix-zuul
@SpringBootApplication
//开启zuul网关功能
@EnableZuulProxy
//eureka的服务发现
@EnableDiscoveryClient
public class ZuulServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZuulServerApplication.class,args);
}
}
server:
port: 8080 #端口
spring:
application:
name: api-zuul-server #服务名称2.3 Zuul中的路由转发
zuul:
routes:
#已商品微服务
product-service: #路由id,随便写
path: /product-service/** #映射路径 #localhost:8080/product-service/sxxssds
url: http://127.0.0.1:9001 #映射路径对应的实际微服务url地址- product-service:配置路由id,可以随意取名
- url:映射路径对应的实际url地址
- path:配置映射路径,这里将所有请求前缀为/product-service/的请求,转发到http://127.0.0.1:9002处理
2.3.1 面向服务的路由
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
@SpringBootApplication
//开启zuul网关功能
@EnableZuulProxy
//eureka的服务发现
@EnableDiscoveryClient
public class ZuulServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZuulServerApplication.class,args);
}
}#配置Eureka
eureka:
client:
service-url:
defaultZone: http://localhost:9000/eureka/
instance:
prefer-ip-address: true #使用ip地址注册zuul:
routes:
#已商品微服务
product-service: #路由id,随便写
path: /product-service/** #映射路径 #localhost:8080/product-service/sxxssds
serviceId: service-product #配置转发的微服务的服务名称
2.3.2 简化的路由配置
- zuul.routes.
.path=/xxx/** : 来指定映射路径。 - zuul.routes.
.serviceId=/product -service :来指定服务名。
zuul:
routes:
#已商品微服务
#如果路由id 和 对应的微服务的serviceId一致的话
service-product: /product-service/**
2.3.3 默认的路由规则
- 默认情况下,一切服务的映射路径就是服务名本身。
zuul:
routes:
#已商品微服务
#如果当前的微服务名称 service-product , 默认的请求映射路径 /service-product/**
# /service-order/2.3.4 Zuul加入后的架构

2.4 Zuul中的过滤器
2.4.1 ZuulFilter简介
/**
* 自定义的zuul过滤器
* 继承抽象父类
*/
@Component
public class LoginFilter extends ZuulFilter {
/**
* 定义过滤器类型
* pre
* routing
* post
* error
*/
public String filterType() {
return "pre";
}
/**
* 指定过滤器的执行顺序
* 返回值越小,执行顺序越高
*/
public int filterOrder() {
return 1;
}
/**
* 当前过滤器是否生效
* true : 使用此过滤器
* flase : 不使用此过滤器
*/
public boolean shouldFilter() {
return true;
}
/**
* 指定过滤器中的业务逻辑
*/
public Object run() throws ZuulException {
//System.out.println("执行了过滤器");
}
}
- shouldFilter :返回一个 Boolean 值,判断该过滤器是否需要执行。返回true执行,返回false不执行。
- run :过滤器的具体业务逻辑。
- filterOrder :通过返回的int值来定义过滤器的执行顺序,数字越小优先级越高。
- filterType :返回字符串,代表过滤器的类型。包含以下4种:
- pre :请求在被路由之前执行
- routing :在路由请求时调用
- post :在routing和errror过滤器之后调用
- error :处理请求时发生错误调用
2.4.2 生命周期

正常流程:
- 请求到达首先会经过pre类型过滤器,而后到达routing类型,进行路由,请求就到达真正的服务提供者,执行请求,返回结果后,会到达post过滤器。而后返回响应。
- 整个过程中,pre或者routing过滤器出现异常,都会直接进入error过滤器,再error处理完毕后,会将请求交给POST过滤器,最后返回给用户。
- 如果是error过滤器自己出现异常,最终也会进入POST过滤器,而后返回。
- 如果是POST过滤器出现异常,会跳转到error过滤器,但是与pre和routing不同的时,请求不会再到达POST过滤器了。
- 请求鉴权:一般放在pre类型,如果发现没有访问权限,直接就拦截了
- 异常处理:一般会在error类型和post类型过滤器中结合来处理。
- 服务调用时长统计:pre和post结合使用。
2.4.3 自定义过滤器

代码实现:
/**
* 自定义的zuul过滤器
* 继承抽象父类
*/
@Component
public class LoginFilter extends ZuulFilter {
/**
* 定义过滤器类型
* pre
* routing
* post
* error
*/
public String filterType() {
return "pre";
}
/**
* 指定过滤器的执行顺序
* 返回值越小,执行顺序越高
*/
public int filterOrder() {
return 1;
}
/**
* 当前过滤器是否生效
* true : 使用此过滤器
* flase : 不使用此过滤器
*/
public boolean shouldFilter() {
return true;
}
/**
* 指定过滤器中的业务逻辑
* 身份认证:
* 1.所有的请求需要携带一个参数 : access-token
* 2.获取request请求
* 3.通过request获取参数access-token
* 4.判断token是否为空
* 4.1 token==null : 身份验证失败
* 4.2 token!=null : 执行后续操作
* 在zuul网关中,通过RequestContext的上下问对象,可以获取对象request对象
*/
public Object run() throws ZuulException {
//System.out.println("执行了过滤器");
//1.获取zuul提供的上下文对象RequestContext
RequestContext ctx = RequestContext.getCurrentContext();
//2.从RequestContext中获取request
HttpServletRequest request = ctx.getRequest();
//3.获取请求参数access-token
String token = request.getParameter("access-token");
//4.判断
if (token ==null) {
//4.1 如果token==null ,拦截请求,返回认证失败
ctx.setSendZuulResponse(false); // 拦截请求
ctx.setResponseStatusCode(HttpStatus.UNAUTHORIZED.value());
}
//4.2 如果token!=null ,继续后续操作
return null;
}
}
2.5 服务网关Zuul的核心源码解析

2.6 Zuul网关存在的问题

- 性能问题 :Zuul1x版本本质上就是一个同步Servlet,采用多线程阻塞模型进行请求转发。简单讲,每来一个请求,Servlet容器要为该请求分配一个线程专门负责处理这个请求,直到响应返回客户端这个线程才会被释放返回容器线程池。如果后台服务调用比较耗时,那么这个线程就会被阻塞,阻塞期间线程资源被占用,不能干其它事情。我们知道Servlet容器线程池的大小是有限制的,当前端请求量大,而后台慢服务比较多时,很容易耗尽容器线程池内的线程,造成容器无法接受新的请求。
- 不支持任何长连接,如websocket
3 微服务网关GateWay
3.1 Gateway简介
3.1.1 简介
3.1.2 核心概念
- 路由(route):路由是网关最基础的部分,路由信息由一个ID、一个目的URL、一组断言工厂和一组Filter组成。如果断言为真,则说明请求URL和配置的路由匹配。
- 断言(predicates) :Java8中的断言函数,Spring Cloud Gateway中的断言函数输入类型是Spring5.0框架中的ServerWebExchange。Spring Cloud Gateway中的断言函数允许开发者去定义匹配来自Http Request中的任何信息,比如请求头和参数等。
- 过滤器(fifilter):一个标准的Spring webFilter,Spring Cloud Gateway中的Filter分为两种类型,分别是Gateway Filter和Global Filter。过滤器Filter可以对请求和响应进行处理。
3.2 入门案例
3.2.1 入门案例
org.springframework.cloud
spring-cloud-starter-gateway
@SpringBootApplication
public class GatewayServerApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayServerApplication.class,args);
}
} cloud: #配置SpringCloudGateway的路由
gateway:
routes:
- id: product-service
uri: lb://service-product
predicates:
- Path=/product/**- id:我们自定义的路由 ID,保持唯一
- uri:目标服务地址
- predicates:路由条件,Predicate 接受一个输入参数,返回一个布尔值结果。该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(比如:与,或,非)。
- fifilters:过滤规则,暂时没用。
3.2.2 路由规则

实例:




3.2.3 动态路由
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
#eureka注册中心
eureka:
client:
service-url:
defaultZone: http://localhost:9000/eureka/
instance:
prefer-ip-address: true #使用ip地址注册 cloud: #配置SpringCloudGateway的路由
gateway:
routes:
- id: product-service
uri: lb://service-product
predicates:
- Path=/product/**3.2.4 重写转发路径
cloud: #配置SpringCloudGateway的路由
gateway:
routes:
- id: order-service
uri: lb://service-order
predicates:
- Path=/order-service/**
filters:
- RewritePath=/order-service/(?.*), /$\{segment} 3.3 过滤器
3.3.1 过滤器基础
(1)过滤器的生命周期
- PRE: 这种过滤器在请求被路由之前调用。我们可利用这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等。
- POST:这种过滤器在路由到微服务以后执行。这种过滤器可用来为响应添加标准的 HTTPHeader、收集统计信息和指标、将响应从微服务发送给客户端等。

- GatewayFilter:应用到单个路由或者一个分组的路由上。
- GlobalFilter:应用到所有的路由上。
3.3.2 局部过滤器
3.3.3 全局过滤器

3.4 统一鉴权
3.4.1 鉴权逻辑
- 当客户端第一次请求服务时,服务端对用户进行信息认证(登录)
- 认证通过,将用户信息进行加密形成token,返回给客户端,作为登录凭证
- 以后每次请求,客户端都携带认证的token
- 服务端对token进行解密,判断是否有效。
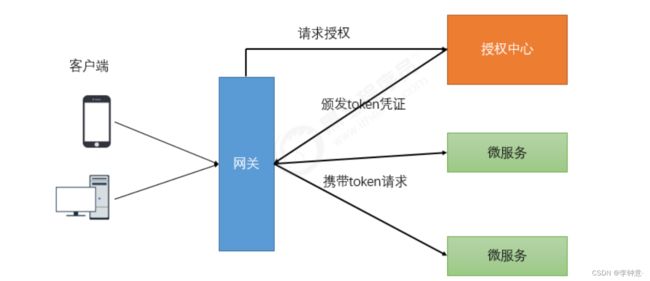
3.4.2 代码实现
/**
* 自定义一个全局过滤器
* 实现 globalfilter , ordered接口
*/
//@Component
public class LoginFilter implements GlobalFilter,Ordered {
/**
* 执行过滤器中的业务逻辑
* 对请求参数中的access-token进行判断
* 如果存在此参数:代表已经认证成功
* 如果不存在此参数 : 认证失败.
* ServerWebExchange : 相当于请求和响应的上下文(zuul中的RequestContext)
*/
public Mono filter(ServerWebExchange exchange, GatewayFilterChain chain) {
System.out.println("执行了自定义的全局过滤器");
//1.获取请求参数access-token
String token = exchange.getRequest().getQueryParams().getFirst("access-token");
//2.判断是否存在
if(token == null) {
//3.如果不存在 : 认证失败
System.out.println("没有登录");
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete(); //请求结束
}
//4.如果存在,继续执行
return chain.filter(exchange); //继续向下执行
}
/**
* 指定过滤器的执行顺序 , 返回值越小,执行优先级越高
*/
public int getOrder() {
return 0;
}
} - 自定义全局过滤器需要实现GlobalFilter和Ordered接口。
- 在fifilter方法中完成过滤器的逻辑判断处理
- 在getOrder方法指定此过滤器的优先级,返回值越大级别越低
- ServerWebExchange 就相当于当前请求和响应的上下文,存放着重要的请求-响应属性、请求实
- 例和响应实例等等。一个请求中的request,response都可以通过 ServerWebExchange 获取
- 调用 chain.filter 继续向下游执行
3.5 网关限流





3.5.2 基于Filter的限流
org.springframework.boot
spring-boot-starter-actuator
org.springframework.boot
spring-boot-starter-data-redis-reactive
server:
port: 8080 #端口
spring:
application:
name: api-gateway-server #服务名称
redis:
host: localhost
pool: 6379
database: 0
cloud: #配置SpringCloudGateway的路由
gateway:
routes:
- id: product-service
uri: lb://service-product
predicates:
- Path=/product-service/**
filters:
# - name: RequestRateLimiter
# args:
# # 使用SpEL从容器中获取对象 即限流规则
# key-resolver: '#{@userKeyResolver}'
# # 令牌桶每秒填充平均速率
# redis-rate-limiter.replenishRate: 1
# # 令牌桶的上限
# redis-rate-limiter.burstCapacity: 3
- RewritePath=/product-service/(?.*), /$\{segment} - burstCapacity,令牌桶总容量。
- replenishRate,令牌桶每秒填充平均速率。
- key-resolver,用于限流的键的解析器的 Bean 对象的名字。它使用 SpEL 表达式根据#{@beanName}从 Spring 容器中获取 Bean 对象。
@Configuration
public class KeyResolverConfiguration {
/**
* 编写基于请求路径的限流规则
* //abc
* //基于请求ip 127.0.0.1
* //基于参数
*/
//@Bean
public KeyResolver pathKeyResolver() {
//自定义的KeyResolver
return new KeyResolver() {
/**
* ServerWebExchange :
* 上下文参数
*/
public Mono resolve(ServerWebExchange exchange) {
return Mono.just( exchange.getRequest().getPath().toString());
}
};
}
/**
* 基于请求参数的限流
*
* 请求 abc ? userId=1
*/
@Bean
public KeyResolver userKeyResolver() {
return exchange -> Mono.just(
exchange.getRequest().getQueryParams().getFirst("userId")
//exchange.getRequest().getHeaders().getFirst("X-Forwarded-For") 基于请求ip的限流
);
}
}
- timestamp:存储的是当前时间的秒数,也就是System.currentTimeMillis() / 1000或者Instant.now().getEpochSecond()
- tokens:存储的是当前这秒钟的对应的可用的令牌数量
- 对不同接口的限流
- 被限流后的友好提示
3.5.3 基于Sentinel的限流
- route 维度:即在 Spring 配置文件中配置的路由条目,资源名为对应的 routeId
- 自定义 API 维度:用户可以利用 Sentinel 提供的 API 来自定义一些 API 分组
- GatewayFlowRule :网关限流规则,针对 API Gateway 的场景定制的限流规则,可以针对不同route 或自定义的 API 分组进行限流,支持针对请求中的参数、Header、来源 IP 等进行定制化的限流。
- ApiDefinition :用户自定义的 API 定义分组,可以看做是一些 URL 匹配的组合。比如我们可以定义一个 API 叫 my_api ,请求 path 模式为 /foo/** 和 /baz/** 的都归到 my_api 这个 API分组下面。限流的时候可以针对这个自定义的 API 分组维度进行限流。
com.alibaba.csp
sentinel-spring-cloud-gateway-adapter
1.6.3
/**
* sentinel限流的配置
*/
//@Configuration
public class GatewayConfiguration {
private final List viewResolvers;
private final ServerCodecConfigurer serverCodecConfigurer;
public GatewayConfiguration(ObjectProvider> viewResolversProvider,
ServerCodecConfigurer serverCodecConfigurer) {
this.viewResolvers = viewResolversProvider.getIfAvailable(Collections::emptyList);
this.serverCodecConfigurer = serverCodecConfigurer;
}
/**
* 配置限流的异常处理器:SentinelGatewayBlockExceptionHandler
*/
@Bean
@Order(Ordered.HIGHEST_PRECEDENCE)
public SentinelGatewayBlockExceptionHandler sentinelGatewayBlockExceptionHandler() {
return new SentinelGatewayBlockExceptionHandler(viewResolvers, serverCodecConfigurer);
}
/**
* 配置限流过滤器
*/
@Bean
@Order(Ordered.HIGHEST_PRECEDENCE)
public GlobalFilter sentinelGatewayFilter() {
return new SentinelGatewayFilter();
}
/**
* 配置初始化的限流参数
* 用于指定资源的限流规则.
* 1.资源名称 (路由id)
* 2.配置统计时间
* 3.配置限流阈值
*/
@PostConstruct
public void initGatewayRules() {
Set rules = new HashSet<>();
// rules.add(new GatewayFlowRule("product-service")
// .setCount(1)
// .setIntervalSec(1)
// );
rules.add(new GatewayFlowRule("product_api")
.setCount(1).setIntervalSec(1)
);
GatewayRuleManager.loadRules(rules);
}
}
- 基于Sentinel 的Gateway限流是通过其提供的Filter来完成的,使用时只需注入对应的SentinelGatewayFilter 实例以及SentinelGatewayBlockExceptionHandler 实例即可。
- @PostConstruct定义初始化的加载方法,用于指定资源的限流规则。这里资源的名称为 order-service ,统计时间是1秒内,限流阈值是1。表示每秒只能访问一个请求。
/**
* 自定义限流处理器
*/
@PostConstruct
public void initBlockHandlers() {
BlockRequestHandler blockHandler = new BlockRequestHandler() {
public Mono handleRequest(ServerWebExchange serverWebExchange, Throwable throwable) {
Map map = new HashMap();
map.put("code",001);
map.put("message","不好意思,限流啦");
return ServerResponse.status(HttpStatus.OK)
.contentType(MediaType.APPLICATION_JSON_UTF8)
.body(BodyInserters.fromObject(map));
}
};
GatewayCallbackManager.setBlockHandler(blockHandler);
} * 配置初始化的限流参数
* 用于指定资源的限流规则.
* 1.资源名称 (路由id)
* 2.配置统计时间
* 3.配置限流阈值
*/
@PostConstruct
public void initGatewayRules() {
Set rules = new HashSet<>();
rules.add(new GatewayFlowRule("product-service")
.setCount(1)
.setIntervalSec(1)
);
rules.add(new GatewayFlowRule("product_api")
.setCount(1).setIntervalSec(1)
);
GatewayRuleManager.loadRules(rules);
} /**
* 自定义API限流分组
* 1.定义分组
* 2.对小组配置限流规则
*/
@PostConstruct
private void initCustomizedApis() {
Set definitions = new HashSet<>();
ApiDefinition api1 = new ApiDefinition("product_api")
.setPredicateItems(new HashSet() {{
add(new ApiPathPredicateItem().setPattern("/product-service/product/**"). //已/product-service/product/开都的所有url
setMatchStrategy(SentinelGatewayConstants.URL_MATCH_STRATEGY_PREFIX));
}});
ApiDefinition api2 = new ApiDefinition("order_api")
.setPredicateItems(new HashSet() {{
add(new ApiPathPredicateItem().setPattern("/order-service/order")); //完全匹配/order-service/order 的url
}});
definitions.add(api1);
definitions.add(api2);
GatewayApiDefinitionManager.loadApiDefinitions(definitions);
} 3.6 网关高可用


3.7 执行流程分析

4 微服务的链路追踪概述
4.1 微服务架构下的问题
- 如何快速发现问题?
- 如何判断故障影响范围?
- 如何梳理服务依赖以及依赖的合理性?
- 如何分析链路性能问题以及实时容量规划?
4.2 Sleuth概述
4.2.1 简介
4.2.2 相关概念
- Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
- Trace:一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式大数据工程,你可能 需要创建一个trace。
- Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
- cs - Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟
- ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间
- cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间

4.3 链路追踪Sleuth入门
org.springframework.cloud
spring-cloud-starter-sleuth
logging:
level:
root: info
org.springframework.web.servlet.DispatcherServlet: DEBUG
org.springframework.cloud.sleuth: DEBUG4.4 Zipkin的概述

- Collector:收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
- Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。
- RESTful API:API 组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等。
- Web UI:UI 组件,基于 API 组件实现的上层应用。通过 UI 组件用户可以方便而有直观地查询和分析跟踪信息。
- 一个 Eureka 服务注册中心,这里我们就用之前的 eureka 项目来当注册中心。
- 一个 Zipkin 服务端。
- 多个微服务,这些微服务中配置Zipkin 客户端。
4.5 Zipkin Server的部署和配置
- 默认Zipkin Server的请求端口为 9411
- Zipkin Server的启动参数可以通过官方提供的yml配置文件查找
- 在浏览器输入 http://127.0.0.1:9411即可进入到Zipkin Server的管理后台
4.6 客户端Zipkin+Sleuth整合
org.springframework.cloud
spring-cloud-starter-zipkin
#修改zipkin使用rabbitmq采集数据
zipkin:
#base-url: http://127.0.0.1:9411/ #server的请求地址
sender:
#type: web #数据的传输方式 , 已http的形式向server端发送数据
type: rabbit #向rabbitmq中发送消息
sleuth:
sampler:
probability: 1 #采样比4.7 基于消息中间件收集数据

4.7.1 RabbitMQ的安装与启动
- RABBIT_ADDRESSES : 指定RabbitMQ地址
- RABBIT_USER: 用户名(默认guest)
- RABBIT_PASSWORD : 密码(默认guest)

org.springframework.cloud
spring-cloud-sleuth-zipkin
org.springframework.amqp
spring-rabbit
zipkin:
sender:
#数据的传输方式 , 已http的形式向server端发送数据
type: rabbit #向rabbitmq中发送消息
sleuth:
sampler:
probability: 1 #采样比
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
listener: # 这里配置了重试策略
direct:
retry:
enabled: true
simple:
retry:
enabled: true- 修改消息的投递方式,改为rabbit即可。
- 添加rabbitmq的相关配置
- 请求的耗时时间不会出现突然耗时特长的情况
- 当ZipkinServer不可用时(比如关闭、网络不通等),追踪信息不会丢失,因为这些信息会保存在Rabbitmq服务器上,直到Zipkin服务器可用时,再从Rabbitmq中取出这段时间的信息
4.8 存储跟踪数据
4.8.1 准备数据库
/*
SQLyog Ultimate v11.33 (64 bit)
MySQL - 5.5.58 : Database - zipkin
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`zipkin` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `zipkin`;
/*Table structure for table `zipkin_annotations` */
DROP TABLE IF EXISTS `zipkin_annotations`;
CREATE TABLE `zipkin_annotations` (
`trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` varchar(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` blob COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` int(11) NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` bigint(20) DEFAULT NULL COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` int(11) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` binary(16) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` smallint(6) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` varchar(255) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',
UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`span_id`,`a_key`,`a_timestamp`) COMMENT 'Ignore insert on duplicate',
KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`span_id`) COMMENT 'for joining with zipkin_spans',
KEY `trace_id_high_3` (`trace_id_high`,`trace_id`) COMMENT 'for getTraces/ByIds',
KEY `endpoint_service_name` (`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames',
KEY `a_type` (`a_type`) COMMENT 'for getTraces',
KEY `a_key` (`a_key`) COMMENT 'for getTraces',
KEY `trace_id` (`trace_id`,`span_id`,`a_key`) COMMENT 'for dependencies job'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED;
/*Data for the table `zipkin_annotations` */
/*Table structure for table `zipkin_dependencies` */
DROP TABLE IF EXISTS `zipkin_dependencies`;
CREATE TABLE `zipkin_dependencies` (
`day` date NOT NULL,
`parent` varchar(255) NOT NULL,
`child` varchar(255) NOT NULL,
`call_count` bigint(20) DEFAULT NULL,
UNIQUE KEY `day` (`day`,`parent`,`child`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED;
/*Data for the table `zipkin_dependencies` */
/*Table structure for table `zipkin_spans` */
DROP TABLE IF EXISTS `zipkin_spans`;
CREATE TABLE `zipkin_spans` (
`trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` bigint(20) NOT NULL,
`id` bigint(20) NOT NULL,
`name` varchar(255) NOT NULL,
`parent_id` bigint(20) DEFAULT NULL,
`debug` bit(1) DEFAULT NULL,
`start_ts` bigint(20) DEFAULT NULL COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` bigint(20) DEFAULT NULL COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',
UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`id`) COMMENT 'ignore insert on duplicate',
KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`id`) COMMENT 'for joining with zipkin_annotations',
KEY `trace_id_high_3` (`trace_id_high`,`trace_id`) COMMENT 'for getTracesByIds',
KEY `name` (`name`) COMMENT 'for getTraces and getSpanNames',
KEY `start_ts` (`start_ts`) COMMENT 'for getTraces ordering and range'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED;
/*Data for the table `zipkin_spans` */
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=root