3. hdfs概述与高可用原理
简述
HDFS(Hadoop Distributed File System)是一种Hadoop分布式文件系统,具备高度容错特性,支持高吞吐量数据访问,可以在处理海量数据(TB或PB级别以上)的同时最大可能的降低成本。
HDFS适用于大规模数据的分布式读写,特别是读多写少的场景。
架构
hdfs由四大组件组成,分别是NameNode、DataNode、ZKFC,journalnode
NameNode: 管理所有文件的元数据信息,并且负责与客户端交互
DataNode: 文件的实际存储位置,定时向NameNode上报数据块信息
ZKFC: 监控NameNode的运行状态,做主从切换
journalnode: 共享存储,数据同步用
高可用
高可用一般是指NameNode的高可用,NameNode是典型的主从架构,主节点负责与客户端交互,从节点负责与主节点同步备份
对于高可用集群,我们会启动两个NameNode,一个是Active NameNode,另一个是Standby NameNode,两个NameNode承担不同角色。Active
NameNode负责处理DataNode和Client的请求,Standby NameNode向 Active NameNode 同步最新的元数据信息,当Active
NameNode异常,Standby NameNode会感知到并切换成Active
高可用原理
通过ZKFC实现高可用,是一个zk集群的客户端,它会定期的像本地的NameNode发送心跳检查(这是一个HealthyMonitor线程),所有每一个NameNode都需要一个ZKFC,如果心跳检查成功,那么NameNode是正常的,否则就是一个失效的节点
如何确定谁为主,通过锁实现
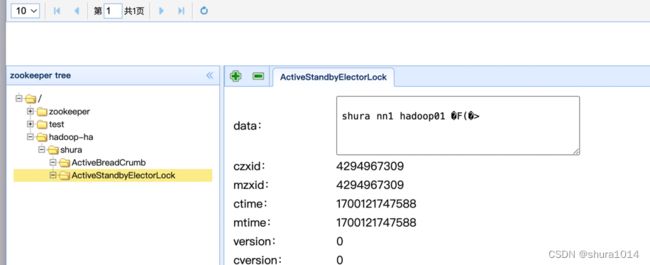
NameNode选举成功后会在zk上创建一个临时节点
/hadoop-ha/{namespace}/ActiveStandbyElectorLock,没有选举成功的zkfc就会监听这个节点。通过zk的watcher机制来知道节点的变化,主要关注的是NodeDelete的事件
如果active异常,那么zkfc会主动删除锁节点,处于standby的NameNode会收到锁节点删除事件,于是会马上去创建锁节点,如果创建成功,那么该NameNode就切换为active
状态
如果整台机器都宕机,导致zkfc不能主动删除锁节点,但是由于锁节点是一个临时节点,zkfc会话结束,也会自动删除的
脑裂
出于某种原因,可能active的NameNode节点正常,但是无法向zk上报心跳,导致与zk建立的session关闭,这个时候ActiveStandbyElectorLock临时节点将被删除,另一个NameNode将会进行选主操作,这个时候就可能出现两个active
解决方案,隔离fence
在zk上还有一个持久的节点ActiveBreadCrumb,如上图所示,这个节点也是保存了Active
NameNode的信息,正常情况下,删除ActiveStandbyElectorLock也会一并删除ActiveBreadCrumb,但是异常情况下,临时节点可以自动删除,持久节点却不会,当另一个NameNode来选主成功后会注意到这个节点,于是会对旧的NameNode进行fencing,对旧的NameNode调用transitionToStandby转为standby状态,如果调用失败,那么就执行我们配置的fence措施
比如我们会配置如下信息
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
表示直接ssh到目标主机,杀死对应进程
还有一种叫 shellfence,可以自定义脚本
成功执行fence后,选主成功的NameNode切换为active状态
数据同步
NameNode主备切换,如何做到与之前数据一致?
引入了JournalNode,NameNode会与一组JournalNode进行通信,当active
执行写操作时,它会持久的把修改的记录记录到大多数的JournalNode中,standby就可以从JournalNode中读取edits日志,并且不断的监视这个日志的修改,将修改的记录应用到自己的命名空间
当发生故障转移时,备用的NameNode确保已经从JournalNode读取所有的edits内容。这样就可以保证状态同步。
JournalNode也是需要高可用部署,一般部署3、5、7个,最多容忍(N-1)/2个故障
总结
以上就是对hdfs的介绍,后面文章将不再介绍,直接实战
欢迎关注,学习不迷路!