【深度】详细解读与评测OpenAI DevDay的最新API更新与应用
原文:https://www.toutiao.com/article/7299498535408665088/?log_from=d9f79b9fe2182_1699572121760
专注LLM深度应用,关注我不迷路
周二凌晨,全球无数AI科技工作者与极客们翘首以盼的首届OpenAI开发者大会上,仅仅四十分钟的主题演讲掌声不断,带给全球AI届大量的震撼与惊喜,很多人惊呼,AI届的iPhone时刻真的已经到来。会上宣布的GPT模型升级与新能力发布,都已经成为这两天耳熟能详的热门话题(参考:今天凌晨,OpenAI首届开发者大会带来的几大更新)。OpenAI也在当天即向全球开发者更新了带有大量新特性的API Beta版,瞬间引起了互联网极客们的狂欢,各种GPT-4V、Dall-E3、Assistants API的有趣用例也被疯狂传播。
本文将带领大家领略OpenAI最新放出的应用API更新,涵盖了本次DevDay上发布的几项重大能力升级:
- GPT-4 Turbo
- GPT-4 Vision(多模态)
- Assistants API
GPT-4 Turbo
首先是GPT-4 Turbo这个新的模型(测试版本的模型名称为gpt-4-1106-preview),很显然这是一个GPT-4的升级版本(其实OpenAI也对GPT-3.5模型进行了同步升级,将原来的普通模型与16k模型统一到了新的gpt-3.5-turbo-1106模型)。除了模型本身的128K上下文、数据截止到2023年4月以外,对应用层面来说最有意义的两个提升是JSON模式与可重现输出。
JSON模式
对于直接使用ChatGPT的个人用户没有太大意义,但是对于API使用者特别是企业用户来说,很多时候需要大模型输出结构化的JSON数据,但是在实际使用中来,由于大模型输出的不确定性,经常会出现无效输出的现象。现在,你可以通过设定API该参数,确保生成有效的JSON字符串。

需要注意的是:即使指定了该参数,你仍然必须在Prompt中给出明确要求生成JSON的指示,否则会出错。此外,仍然可能由于tokens限制导致输出被截断,进而导致无法解析输出。因此你必须对API返回的end_reason做判断,自行处理。
可重现的输出
大模型的使用者都知道,即使在完全一致的输入下,也无法确保大模型输出完全一致的响应。现在,你可以通过API参数进行控制,确保输出的可重现(输入一致的情况下)。我们认为,这可适用于以下应用场景:
- 在借助于大模型实现文本转换时(比如Q&A提取),你希望相同的数据能够生成一致的输出,以方便后续的排重
- 在排除一个复杂的大模型工作流程中的故障时,希望相同的输入能获得确定的输出,以更好的重现错误
- 对不同的提示在不同的模型中的输出进行基准/性能测试时,你需要减少相同输入下的不确定性,确保评估环境的一致性
具体使用方法为:在需要获得一致性响应的调用中设定一个相同的seed值,比如1234,那么在所有其他的输入参数相同时(prompt,temprature等),你将获得一致的输出,消除随机性。

此外,在输出中有一个system_fingerprint参数用来表示每次调用的OpenAI基础环境指纹,如果该指纹不一样,即使其他参数一致,结果也可能不一致。
GPT-4 Vision
所有能够访问GPT-4 API的开发者现在可以通过新的模型gpt-4-vision-preview来调用带有视觉能力的GPT-4 Turbo。GPT-4V包含了传统GPT-4的全部能力,只是是增加了图片理解能力,在使用上没有太多的不同:
在API中使用参数传入图片URL网络地址或者直接传入base64编码的图片内容即可:

几个应用重点
- 可以支持一次传入多个图片,GPT会读取理解多个图片中的信息并回答你的问题
- 允许通过detail参数来打开低保真或者高保真的图像理解,两者的区别是高保真可以理解更多的图像细节,当然,也会消耗更多的Tokens
- 由于普通的GPT API都是无状态API,因此如果你需要一个带有图片的多轮对话,你不得不在每次发出请求时都携带对话中的所有图片信息,所以采用网络URL是一个更好的携带图片的方法
- OpenAI会在对话结束后删除图片,不会保存,更不会用来训练模型
使用成本:很贵
官方给出的GPT-4V API的大致成本(tokens)计算方式:取决于图片的大小与detail参数。
- low detail模式下,不同的输入图片大小成本都为大约85 tokens;
- high detai模式下,不同的输入图片大小将根据能够裁剪成512*512的图片数量计算,并加上一个额外固定token数量。一个1024*1024的图片大约需要消耗765个tokens,一个2048*4096的图片大约1105个tokens。我们参考GPT-4 Turbo的tokens价格来做一个估算:

- 如果采用low detail模式,1美元大致可以处理1176张图片,与分辨率无关;
- 如果都采用high detail模式,以高清分辨率1920x1080的图片来计算,1美元只能处理约90张图片;对应到视频,如果是一个30帧/秒的视频,那么也就是1美元只能处理约3秒钟的视频
GPT-4V的应用
关于GPT-4V的应用,其实在之前微软的论文中几乎涵盖了所有的可能性,现在也有很多网友创造的耳目一新脑洞大开的应用(可以参考我们之前的文章:【深度】全面解读多模态GPT-4V能力:微软166页论文“浓缩版”),比如:
- 借助摄像头捕获图像,与机器人做视频对话
- 提取视频连续图像,让借助TTS生成旁白
- 借助摄像头让AI指导自己练瑜伽
- 画出设计草图让AI生成页面代码
这里推荐一个OpenAI官方的cookbook中的一个例子作为学习:借助GPT-4V和TTS的API为视频生成画外音(notebook:
https://github.com/openai/openai-cookbook/blob/main/examples/GPT_with_vision_for_video_understanding.ipynb),其大致思路是:

另外一个典型的应用就是对多模态文本的RAG处理。这个问题很多开发人员都遇到过,比如企业内部的PDF文档中的图片,如何来实现向量化后的检索,并能够传入大模型增强回答。在我们之前的文章中有详细描述(参考GPT4-V之前:企业私有知识库中半结构化与多模态数据的RAG方案思考),现在有了GPT-4V可以更加完美的实现这一方案。
Assistants API
OpenAI本次推出的最激动人心的特性,也是其在AI Agents领域最重要的布局。在之前的视频中已经演示了通过OpenAI的Playground环境来体验Assistants API的威力:
不支持的音频/视频格式
00:00 / 00:00
简单的说,通过该API,你可以简单的创建具备完整的长短期记忆、工具使用、自主规划能力的AI Agent/Assistant。这个Agent可以借助大模型、工具和上传的知识来响应用户输入,并输出结果文字或者文件。
Agent能力解读
我们来看看Assistants API是如何具备AI Agent所必需的规划、记忆、工具这三大能力。
- 任务规划:显然,任务规划执行的大脑就是GPT大模型,目前模型可以支持3.5与4.0的模型,当然,最新的GPT4 Turbo肯定是最优的选择。那么相比于LangChain这样的构建框架,Assistants API最重要的就是:简单!无需了解提示工程,无需知道ReAct模式,毕竟模型就是自己的,所以自己最清楚怎么使用模型。
- 短期记忆:即在一次任务与对话过程中的上下文记忆,在Assistants API中引入了Thread概念。Thread可以理解成一次对话过程中的服务端会话,你无需在每次API时传入所有的历史对话(就像普通的Chat API那样),Thread会自动存储消息,并管理长度,以防止超出模型的最大上下文长度。
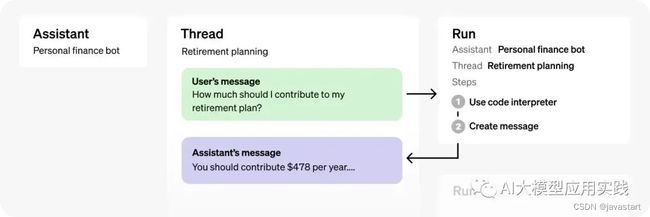
Assistants API的工作原理图,Thread用来保存你和Agent之间的一次对话过程的消息,Run则代表Agent在一次对话中的自主工作过程,其输入来自于Thread,结果保存到Thread。你可以往Thread放一个用户输入消息,然后开始一次Run,AI会借助各种工具完成任务,最后返回输出,并把结果保存在Thread。通过这样的循环,你可以与Agent进行持久的交互,获得最终结果。
- 长期记忆:你可以在Assistant层面给你的机器人补充私有知识(文件),这些文件会长期保存,不会随着thread的消失而删除,并且在必要的时候Agent会从这些文件中检索来帮助处理任务。
- 工具使用:这是AI Agent最强大的地方,也是智能体具备自主行动能力的关键。目前,每个Agent最多可以使用128个工具,支持主要的三种类型工具为:
- 代码解释器(Code Interpreter):能够接受文字或文件输入,并自行编写代码在沙箱运行完成任务。输入输出的文件可以是csv、PDF、JSON、Office文件、ZIP文件、各种代码文件、图片文件等。
- 知识检索(Retriever):从外部传入的知识文件中检索,用来增强大模型,比如你企业的产品介绍、或者常见问答等。也即RAG,但使用更简单,给文件即可,OpenAI会自行嵌入与检索。
- 函数调用(function):赋予了Agent强大的扩展能力。用来在你的AI Agent工作过程中嵌入调用自定义工具的能力。比如:创建一个预订车票的机器人,你需要AI Agent在必要的时候告诉你需要查询车票信息。那么你可以向这个机器人描述你的车票查询接口与作用,Agent会在需要的时候返回你需要调用的接口及参数,并暂时中断运行过程,等待你把车票查询的结果给他后继续运行。
最后我们看一个X上面有人分享的创建基于网站内容回答的AI助理,只用了30行代码:
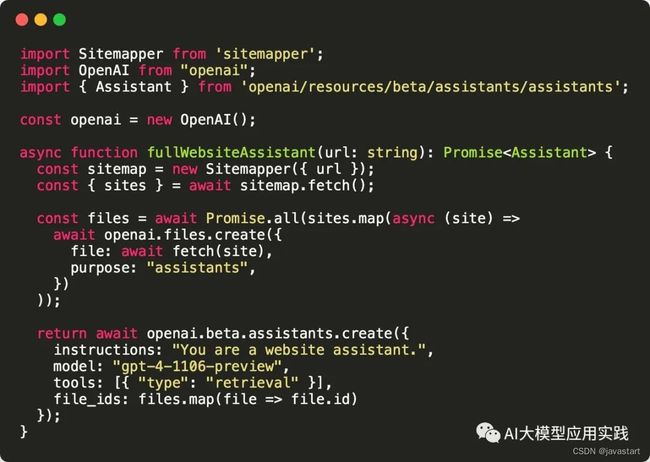
代码演示一个assistant的创建过程:首先通过sitemapper来获得网站爬取的全部url,然后通过url爬取网站内容生成文件,最后把文件交给Assistants API生成assistant。然后你可以对这个Assistant提问关于这个网站上的内容。
一点思考
本次OpenAI的更新展示了其强大的实力与未来更清晰的战略,当然,也有人担心OpenAI这次掀了很多初创企业的桌子,甚至担忧未来将形成一家独大的局面,我们认为无需过度忧虑。
- AI产业生态正在逐渐清晰化,生态不会消失,只会洗牌与重构;在初期有一些局部的优化或许会比较残酷,但从长远看只会让生态更健康,只要找到合适的位置,就有生存的空间。而对于OpenAI这样的公司,抓住产业链上的关键环节,构建与培养一个生态环境也更符合其定位与战略。
- 基础技术与平台很伟大,但是也需要上层的应用来释放真正的价值,否则一切都是镜中花。而应用层面更需要百花齐放才能繁荣,这方面可参考智能手机时代的App Store,对于中小企业甚至个人开发者,在巨人的肩膀上深挖AI的应用应该是坚定的方向。
- 从本次更新看,集中在基础模型优化、AI应用构建工具、GPT Store等,一方面是基础模型,一方面是应用构建平台。而这里的应用就是以AI Agents为主要方向的面向个人及企业的各类智能体,AI时代的iPhone生态似乎已经呼之欲出。