Linux命令详解大全(附带指令讲解案例)
Linux命令详解
在linux命令详解(1)
linux命令详解(2)
linux命令详解(3)
linux命令详解(4)
linux命令详解(5)
linux命令详解(6)
linux命令详解(7)
linux命令详解(8)
linux命令详解(9)
基础上添加一些新的指令,
备注:快捷查看指令 ctrl+f 进行搜索会直接定位到需要的知识点和命令讲解,后续的会比前面的更详细以及对之前的内容修改和更新补充[以后续更新的为最新](如有不正确的地方欢迎各位小伙伴在评论区提意见,小编会及时修改)
基本指令操作
# 查看远端Linux的ip地址
ip a 或者 ip addr
# 清屏
clear
# 查看当前系统时间
date
#关机
poweroff 或者 init 0
#重启
reboot 或者 init 6
#修改主机名
hostnamectl set-hostname 新名字
#列出指定文件夹下的内容
ls
语法:
ls [参数] 路径
注意:参数可选
参数介绍:
-a 列出指定路径下的内容,包含隐藏文件
-l 列出指定路径下内容的详细信息[例如:权限,时间,所属组,所属用户]
-h 以人类可阅读的方式列出文件夹大小[一般与 -l 参数连用]
--full-time 以完整的时间格式输出 [不能与其他参数连用]
-t 根据最后一次修改的时间排序 展示内容[由新到旧]
-F 在不同的文件结尾 输出不同的特殊符号
以 / 结尾的就是文件夹
以 * 结尾的就是可执行文件
以 @ 结尾的就是软连接(快捷方式)
普通文件,结尾什么都没有
以. 开头的是隐藏文件
-d 显示文件夹本身信息(不输出文件夹内部信息)
-r 逆转排序
-S 针对文件大小进行排序 (默认是从大到小)
-Sr 从小到大排序
-i 显示出文件的 inode信息[文件的元数据(文件大小,位置,权限,文件的唯一标识)]
常见的用法
-- 查看指定目录下的信息
ls -l 路径 或者 ll 路径
-- 查看指定目录下的所有信息(包含隐藏文件)
ls -la 路径
案例1:列出根目录下所有内容的详细信息
ls -a -l /
参数可以合并:ls -la /
案例2:列出 /opt下所有内容的详细信息
ls -la /opt
-- 查看当前用户
whoami
-- 查看当前主机名
hostname
-- 查看当前命令行所在工作目录的绝对路径(print work directory)
pwd
-- 用户切换
su - 用户名
-- 创建用户
sudo useradd -m 用户名 [创建普通用户]
sudo passwd 用户名 [设置普通用户密码]
注意:
root账户切换普通用户,直接切换即可
普通用户切换 root 用户 需要输入密码
-- 退出当前用户 [切换到另外一个用户]
logout
或者
exit
注意:
1.一般情况下,linux的命令参数都是可选的 不同的参数作用不一样
2.linux命令之间,必须有一个或多个空格
路径表述
# windows系统下路径表述
|-C盘
|- 文件夹
|-文件夹
|-文件
|-a.txt
|-文件
|-文件
|-文件夹
|-D盘
|-F盘
# Linux系统下路径表述
---- 一切皆文件
/ 根目录
/
|-文件夹
|-文件夹
|-文件
|-文件
|-文件
|-文件夹
#linux系统中路径表述
1. 绝对路径(以 / 开头)
/文件
/文件夹/文件
2. 相对路径
./ 当前目录下
../ 上一层目录下
例如:
/opt/a.txt 绝对路径
./a.txt 当前目录下的 a.txt文件
../a.txt 上一层目录下的a.txt文件
说明
|-/opt/abc/a.txt
|-/opt/a.txt
此时我们处于abc文件夹下 ../a.txt --------> /opt/a.txt
目录说明
/boot 存放的是内核与启动文件
/dev 存放的硬件(设备)相关信息的文件
/etc 存放系统的配置文件
/etc/sysconfig/network-scripts/ifcfg-ens33:设置网络环境,例如动态、静态ip 设置是否支持远程连接......
/etc/resolv.conf:设置DNS域名解析
例如: 张三---手机号
www.baidu.com-----275.168.220.8
/etc/hostname : 设置主机名
/etc/motd : 设置开机显示
案例:
vim /etc/motd
/etc/os-release:查看发行版 版本号
/home 普通用户的主目录
/media 可卸载存储介质挂载点
/mnt mount文件系统临时挂载点
/opt 应用程序包
/proc: 系统内存的映射目录,提供内核与进程信息
/proc/meminfo:系统内存信息
/proc/cpuinfo:关于处理器的信息 例如 类型,厂家,型号,性能等
/proc/loadavg:系统负载信息 uptime结果
/proc/mounts:已加载的文件系统列表
/root 特权用户(管理员)目录
/run 存放的是组件运行时所需要的文件[文件夹]
/srv 存放服务相关的数据
/sys 虚拟文件系统,记录核心系统的硬件信息
/tmp 存放临时文件
/usr 存放用户应用程序
/var 存放运行时内容会发生变化的文件 例如 日志
/var/log:记录系统及软件运行信息
/var/log/messages:系统级别日志文件
/var/log/secure:用户登录信息的日志文件
/var/log/dmesg:记录硬件信息加载情况(日志文件)
date指令简介
# 查看日期 date '+参数'
# 查看服务器的时间
案例:
[root@bai /]# date
2023年 10月 23日 星期一 11:38:48 CST
# 日期说明
一个日期包含: 年 月 日 星期 小时 分钟 秒 毫秒 纳秒 时区
# 日期查看参数说明
%F 只显示当前年月日(2023-10-23)
%X 只显示当前时间的时分秒(17时50分20秒)
%c 直接显示日期与时间(年月日 星期 时分秒)
%x 直接显示日期(年月日)
%T 显示时分秒 HH:MM:SS [24小时进制]
%r 显示时分秒 [12小时进制]
# 提取日期属性
%Y 完整的年份(四位的年份)(2023 2020)
%y 年份的末两位(2023--->23 2020 ---> 20)
%m 月份
%d 日(月份中的日)
%H 小时(24进制的小时)
%M 分钟(00 ~ 59)
%S: 秒
%p: 显示本地 AM PM
# 其他日期属性
%Z 显示时区
%w 一周中的第几天(0 ~ 6) 注意 星期日 0
%a 星期几(简写,比如 星期一显示一)
%A 星期几(全称)
%b 月份(简写)
%B 月份(全称)
%s 从1970年1月1日0时0分0秒 到现在 过了多少秒
案例:
# 展示当前系统时间 格式 YYYY-mm-dd HH:MM:SS
[root@bai /]# date '+%Y-%m-%d %H:%M:%S'
2023-10-23 11:54:53
文件管理
文件类型(了解)
# 查看指定路径下(目录)文件类型
ls -l -d 目录
或者
ll -d 目录
# 文件类型
- 普通文件(文本文件,二进制文件,压缩文件,音频,视频.....)
l 即符号链接文件 又称为软连接(快捷方式)[浅蓝色]
d 目录文件[浅蓝色]
b 设备文件[类似于硬盘 U盘]
c 设备文件[字符设备文件 比如我们的 打印机]
s 即套字文件 用于实现两个进程之间进行通信
p 管道文件
. 隐藏文件
案例1:
-- 查看下列文件类型,能找出几种?
[root@bai /]# ll -d /etc/hosts
-rw-r--r--. 1 root root 158 6月 7 2013 /etc/hosts # - 开头 属于普通文件
[root@bai /]# ll -d /bin/ls
-rwxr-xr-x. 1 root root 117672 4月 11 2018 /bin/ls # -开头 属于普通文件
补充:
一次性查看好多文件(文件夹)
ls -l -d 目录1 目录2 ....
目录切换
cd 指令 ------ 目录切换
例如 cd / 切换到根目录下
cd /etc 切换到etc目录下
# 切换到当前目录(原地踏步)
cd .
# 切换到当前目录的上一层目录
cd ..
# 直接回到家目录
cd 或者 cd ~
# 回到上一次的目录
cd -
例如:
cd / # 回到根目录下
cd /etc # 切换到 /etc 目录下
cd - # 回到根目录[回到上一次的目录]
# 去到指定目录
cd 目录 #目录可以是相对路径 也可以是绝对路径
[root@bai /]# cd / # 切换到根目录
[root@bai /]# cd /etc # 切换到 etc 目录下
[root@bai etc]# pwd # 查看当前目录
/etc
[root@bai etc]# cd dhcp # 切换到当前目录下的 dhcp文件夹
[root@bai dhcp]# cd .. # 回到上一层目录
[root@bai etc]# cd ./dhcp # 切换到当前目录下的 dhcp文件夹
[root@bai dhcp]# cd # 直接切换到当前用户的家目录
[root@bai ~]# cd / # 切换回根目录 ~ 也是 家目录的标识
[root@bai /]# cd ~ # 直接切换到当前用户的家目录[root账户在 /root 目录下,其他用户在 /home目录下]
[root@bai ~]# cd - # 切换到上一次的工作目录
文件夹/文件的创建
文件夹的创建
# 创建一个文件夹
mkdir 可选参数 文件夹名字[包含路径]
例如:
[root@bai /]# mkdir /abc
等价于
[root@bai /]# mkdir abc
注意:
1.若未添加路径描述,默认在当前目录下
2. mkdir 文件夹 语法特点是:只能在已经存在的目录下创建文件夹,并且只能创建一层文件夹
```
```powershell
mkdir -p 文件夹1/文件夹2 # 可以创建多级文件夹
参数:
-p 递归创建多级文件夹
# 案例
[root@bai /]# mkdir -p /peiqi/xiaopeiqi1
mkdir -v 文件夹 # 显示创建时的详细信息
批量创建文件夹
# 批量创建文件夹
mkdir {文件夹1,文件夹2,文件夹3}
# 案例1 在 根目录下创建 test1 test2 test3 三个文件夹
[root@bai /]# mkdir {test1,test2,test3}
# 案例2 在 /peiqi 下 创建 xiaopeiqi2 xiaopeiqi3 xiaopeiqi4
[root@bai /]# mkdir /peiqi/{xiaopeiqi2,xiaopeiqi3,xiaopeiqi4}
# 案例3 在 /abc 文件夹下创建 100个文件夹 file1 file2 file3 ...... file100
[root@bai /]# mkdir /abc/file{1..100}
[root@bai /]# mkdir -v /def/peiqi #-v 会显示文件夹的创建过程
mkdir: 已创建目录 "/def/peiqi"
[root@bai /]# mkdir -p -v /a/b # 递归创建文件夹并显示具体过程
mkdir: 已创建目录 "/a"
mkdir: 已创建目录 "/a/b"
文件的创建
用法: touch [可选参数] 文件
作用:
1. 创建普通文件
在linux系统中,文件的后缀格式仅仅只是一个名字而已,通过 touch命令创建的都是普通文件
2. 修改文件的时间
# 创建一个文件
# 在 /a/b文件夹下创建 xiaopeiqi1.txt 文件
[root@bai /]# touch /a/b/xiaopeiqi.txt
[root@bai /]# ll /a/b
总用量 0
-rw-r--r--. 1 root root 0 10月 23 15:41 xiaopeiqi.txt
# 创建多个文件·
touch 文件1 文件2 文件3;
# 案例
1. 在当前目录下创建三个文件 a.txt b.txt c.txt
[root@bai d]# touch a.txt b.txt c.txt
2. 在 /c 目录下创建三个文件 a.txt b.txt c.txt
[root@bai d]# touch /c/a.txt /c/b.txt /c/c.txt
3. 批量创建多个文件
-- 在/abc 文件夹下创建 baizhi1.txt baizhi2.txt baizhi3.txt ..... baizhi100.txt
[root@bai /]# touch /abc/baizhi{1..100}.txt
[root@bai /]# ls -la /ab
注意: {1..100} {a..z} 前提是可排序(可比较大小)
4. 创建隐藏文件
touch /目录/.demo.txt
# 修改文件的创建时间
touch -t # 修改文件的创建时间
案例1:
-- 将 xiaopeiqi.txt 文件创建时间修改为 10月24号9点30分 [默认是系统年份]
[root@baizhi b]# touch -t 10240930 xiaopeiqi.txt
-- 将 xiaopeiqi.txt 文件创建时间修改为 2030-10-23 09:30
[root@bai b]# touch -t 203010230930 xiaopeiqi.txt
注意: 日期修改范围 年月日时分
# 将a.txt文件的创建时间 充当 文件b 的创建时间
touch -r 文件a 文件b
或者
touch --reference=文件a 文件b
案例2:
-- 创建 yangdd.txt 文件 且创建时间和 xiaopeiqi.txt 的时间一致
[root@bai b]# touch -r xiaopeiqi.txt yangdd.txt
[root@bai b]# ll --full-time ./
总用量 0
-rw-r--r--. 1 root root 0 2030-10-23 09:30:00.000000000 +0800 xiaopeiqi.txt
-rw-r--r--. 1 root root 0 2030-10-23 09:30:00.000000000 +0800 yangdd.txt
[root@bai b]# touch --reference=xiaopeiqi.txt cpx.txt
[root@bai b]# ll --full-time ./
总用量 0
-rw-r--r--. 1 root root 0 2030-10-23 09:30:00.000000000 +0800 cpx.txt
-rw-r--r--. 1 root root 0 2030-10-23 09:30:00.000000000 +0800 xiaopeiqi.txt
-rw-r--r--. 1 root root 0 2030-10-23 09:30:00.000000000 +0800 yangdd.txt
文件创建(2)
# 输出语句 ----> 指令运行以后,在操作界面打印内容
echo 内容 # 将内容在界面中打印展示
[root@bai ~]# echo HelloWorld
HelloWorld
# 借助 echo 完成文件创建,并传输文件内容
语法:
echo 内容 > 文件
注意:
1. 若文件不存在,则新建并传输内容
2. 若文件存在,则新内容覆盖原始文件内容
语法:
echo 内容 >> 文件
注意:
1. 若文件不存在,则新建并传输内容
2. 若文件存在,则新内容追加在原始内容之后
文件拷贝(复制)
用法: cp [可选参数] 源文件 目标文件
参数:
-r 递归式复制目录 即复制目录下所有的子目录和文件
-d 复制的时候保持软链接(快捷方式)
-p 等价于 --preserve=模式,所有权,时间戳,复制文件时保持源文件的权限,时间属性[完美复刻]
-a 等价于 -pdr
-i --interactive 覆盖前询问提示(生成的文件和当前目录下已经存在的文件冲突)
# 1. 复制普通文件
cp 文件1 文件2 # 复制一份文件1,生成文件2
# 2. 复制整个文件夹
cp -r 文件夹1 文件夹2 #将文件夹1所有内容复制 生成 文件夹2
# 3. 复制文件并修改生成文件的路径
cp 目录1/文件1 目录2/文件2 # 将文件1复制到目录2下 若文件2名字缺失 新文件名字与文件1 保持一致
# 4. 覆盖前提示
cp 文件1 文件2 # 当前目录下已经存在文件2 询问是否覆盖
等价于
cp -i 文件1 文件2
# 5. 批量复制多个文件
cp 文件1 文件2 文件3 文件夹 # 将文件1 文件2 文件3 拷贝到 指定文件夹下
系统指令别名
alias
系统指令别名
cp ----- 简写(别名)
等价
cp -i ---- 指令完整写法
# 查看指定别名对应的指令
type -a 别名
[root@bai b]# type -a ll
ll 是 `ls -l --color=auto' 的别名
# 设置别名
1. 查看 指定文件夹的 详细信息,隐藏文件,时间戳
ls -la --full-time 目录
设置别名
alias 别名='命令'
例如: alias nb='ls -la --full-time'
[root@bai b]# alias nb='ls -la --full-time'
[root@bai b]# alias
alias cp='cp -i'
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias nb='ls -la --full-time'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
[root@bai b]# type -a nb
nb 是 `ls -la --full-time' 的别名
[root@bai b]# nb /a
总用量 4
drwxr-xr-x. 4 root root 61 2023-10-23 16:40:49.133677006 +0800 .
dr-xr-xr-x. 25 root root 4096 2023-10-23 15:33:58.688504641 +0800 ..
drwxr-xr-x. 2 root root 148 2023-10-23 16:50:38.988993905 +0800 b
-rw-r--r--. 1 root root 0 2023-10-23 16:40:09.485522155 +0800 chenpx.txt
-rw-r--r--. 1 root root 0 2023-10-23 16:40:49.133677006 +0800 cpx.txt
drwxr-xr-x. 2 root root 130 2023-10-23 17:04:36.027418341 +0800 peiqi
# 取消别名
unalias 别名;
mv指令
mv 命令 就是 move的缩写,作用用于移动文件 或者 重命名文件。
语法
mv [可选参数] 源文件 目标文件。
参数:
-i 覆盖前询问[目标目录下已经存在指定文件]
-f 覆盖前不询问
# 将 /a/cpx.txt 移动到 /def/peiqi 文件夹下 ------> 文件移动
[root@bai b]# mv /a/cpx.txt /def/peiqi/
# 将 /a/chenpx.txt 移动到 /def/peiqi 文件夹下 并重命名为 demo.txt
[root@bai peiqi]# mv /a/chenpx.txt /def/peiqi/demo.txt
# 批量移动文件[移动的文件,名字有规律]
mv /a/b/cpx* /def/peiqi/
# 将 /a/peiqi/ 下的 所有 cpx开头的文件 移动到 /def/peiqi 下 直接覆盖不再询问
[root@bai peiqi]# mv -f /a/peiqi/cpx* /def/peiqi/
# 将 /a/cpx5.txt到cpx10.txt移动到/a/a1 下
[root@centos-128 test]# mv -f /a/cpx{5..10}.txt /a/a1
# 移动文件夹
mv 源文件夹 目标目录
# 将/a 文件夹 移动到 /c文件夹中
[root@bai peiqi]# mv /a /c/
文件/文件夹删除
rm 命令 就是 remove的含义 删除一个或者多个文件[删除文件夹]
rm [可选参数] 目标文件[夹]
参数:
-f 强制删除,不提示确认
-i 在删除前进行提示确认
-r 在删除文件夹时使用
-d 删除空目录
-I 在删除超过三个文件或者递归删除前要求确认
-v 详细显示进行的步骤
案例:
[root@bai /]# rm /c/a.txt
rm:是否删除普通空文件 "/c/a.txt"?y
[root@bai /]# rm -f /c/b.txt
[root@bai /]#
[root@bai /]# rm /abc/file100
rm: 无法删除"/abc/file100": 是一个目录
[root@bai /]# rm -r /abc/file100
rm:是否删除目录 "/abc/file100"?y
[root@bai /]# rm -rf /c/a
[root@bai /]#
[root@bai /]# rm -rf /c/d/* ---> 删除d目录下所有内容,但是保留 d文件夹
[root@bai /]# rm -rf /c/d ----> 连同d目录一并删除
[root@bai /]# rm -d /abc/file11 ----> file11 file12 必须是空目录
rm:是否删除目录 "/abc/file11"?y
[root@bai /]# rm -df /abc/file12
[root@bai /]# rm -r -v -f /c
已删除"/c/.你看不见我.txt"
已删除目录:"/c/d"
已删除目录:"/c"
注意:
rm -rf /* -- 删库跑路 禁用
帮助指令
# man帮助指令
语法: man 指令
进入man指令以后 按下
q ---- 退出
空格(上下方向键) ---- 上下移动
语法: 指令 --help
语法: help 指令 ------> 只能展示内置的指令 指令位于 bin目录 sbin目录
语法: info 指令
从互联网上获取Linux中文文档网站
Linux开关机指令
# 重启
语法: shutdown -r 参数
举例:
shutdown -r 10 # 10分钟后重启
shutdown -r 0 # 立刻重启
shutdown -r now # 立刻重启 ------ 企业级用法
# 关机
语法: shutdown -h 参数
举例:
shutdown -h 10 #10分钟后关机
shutdown -h 0 # 立刻关机
shutdown -h now # 立刻关机 ---- 企业级用法
# 其他指令
reboot 重启
poweroff 关机 立刻关闭系统,同时切断电源
halt 关机 立刻关闭系统,需要手动切断电源
init 6 切换运行级别为6 此级别代表重启
init 0 切换运行级别为0 此级别代表关机
logout 注销退出当前用户
exit 注销退出当前用户
ctrl+d 注销退出当前用户
文件查看
cat指令
查看普通文件内容,查看一个文件的全部内容 # 注意文件内容大小
语法:
cat [参数] 文件
参数:
-n 显示行号
-A 包括控制字符(换行符/制表符) $ ---->换行符
head指令
查看文件内容的前几行 ----> 可以查看大体量文件
语法:
head 文件 # 默认查看前10行
head -数字 文件 # 指定查看文件前几行
或者
head -n 数字 文件
tail指令
tail 查看文件内容的尾部
语法:
tail [可选参数] 文件
tail -n 文件 # 查看文件后n行信息
参数:
-f # 一般用于查看动态变化的文件 例如: 日志
动态查看文件的尾部
tail -f 文件 # 实时查看文件的后10行信息
tail -f -n 5 文件 # 实时查看文件的后5行信息
或者
tail -5f 文件
grep指令
grep过滤关键字 ---- 针对文件内容进行过滤(筛选)
[root@bai /]# grep 'root' /etc/passwd # 过滤文件中带有root的行 [精确查找]
注意:
'' 可以省略 一般用于区分指令关键字
# 筛选所有以root开头的 行 ^---->以....开头
[root@bai /]# grep '^root' /etc/passwd
# 筛选所有以 nologin 结尾的行 $ -----> 以......结尾
[root@bai /]# grep 'nologin$' /etc/passwd
less指令
分页展示
语法:
less 文件
分页展示以后,指令:
空格 ----> 翻页
回车键 ----> 下一行
方向键 ↑ 方向键 ↓ ------> 上下滚动
/关键字 ------> 在文件中查找指定的关键字,并高亮展示
n -----> 搜索时,往下翻
N -----> 搜索时,往上翻
more指令
分页显示文件内容 ---- 底部会展示文件内容查看进度百分比 看完直接退出
语法:
more 文件名
分页展示以后,指令:
空格 -----> 翻页
回车 -----> 下一行
cut指令
cut --- 在文件中每一行 提取 片段
语法:
cut [可选参数] [片段区间] 文件
参数
-c 以字符为单位进行提取
-d 自定义分隔符 默认以tab为分隔符
-f 与-d 连用 指定显示的区域
案例:
# 1.提取文件中每一行的第 4 个字符
[root@bai /]# cut -c 4 /etc/passwd
# 2.提取文件中每一行的 第 4 ~ 7 个字符
[root@bai /]# cut -c 4-7 /etc/passwd
# 3.提取文件中每一行的前7个字符
[root@bai /]# cut -c 1-7 /etc/passwd
或者
[root@bai /]# cut -c -7 /etc/passwd
# 4.从第10个字符开始,一直到最后 截取文件内容中的每一行
[root@bai /]# cut -c 10- /etc/passwd
# 5.获取每一行的 第4个字符 第6个字符
[root@bai /]# cut -c 4,6 /etc/passwd
# 6.以 : 为分隔符切割每行内容 并获取 第一个片段
[root@bai /]# cut -d : -f 1 /etc/passwd
# 7.以 : 为分隔符切割每行内容 并获取 第 1 ~ 3个片段
[root@bai /]# cut -d : -f 1-3 /etc/passwd
# 8.以 : 为分隔符切割每行内容 并获取 第5个及以后所有的片段
[root@bai /]# cut -d : -f 5- /etc/passwd
# 9.以 : 为分隔符切割每行内容 并获取 前5个片段
[root@bai /]# cut -d : -f -5 /etc/passwd
sort指令
sort 命令将输入的文件内容按照规则排序,然后输出结果
语法:
sort [选项参数] 文件
参数:
-b : 忽略前导的空白区域
-n : 根据字符串数值比较
-r : 反转
-u : 去重排序 配合 -c
-t : 使用指定的分隔符代替空格
-k 位置1: 在位置1开始排序规则
案例:
# 对文件第一个字符进行排序 默认从小到大
sort -n /abc/a.txt
# 对文件第一个字符进行排序 降序
sort -n -r /abc/a.txt
# 对排序的结果去重
sort -u a.txt
# 指定分隔符号,指定区域进行排序
sort -n -t "." -k 4 ip.txt
uniq指令
uniq命令可以输出或者忽略文件中的重复行 ---- 经常与 sort 连用
语法:
uniq [可选参数] 文件
# 去除连续的重复行
语法:
uniq 文件名
# 结合sort使用
sort -n a.txt | uniq
# 统计每一行的重复次数 结合 sort使用 先让重复内容连续,然后在使用uniq进行次数统计
sort -n a.txt | uniq -c
# 只找出文件中的重复行[出现2次及以上] 且 统计次数
sort -n a.txt | uniq -c -d
# 只找出文件中只出现一次的行,且统计次数
sort -n a.txt | uniq -c -u
# 查看哪些ip被使用了
sort -n -t "." -k 4 ip.txt | uniq -c
文件编辑
指令:
vi / vim
语法:
vim 文件 / vi 文件 # 打开文件
注意:
vim 默认机器是不安装的,需要手动安装这个工具命令
# 安装指令
yum install vim -y
说明:
1.通过 yum 软件管理工具 安装命令 vim 且默认是 yes 这个命令要保证机器可以上网
2.当 vim/vi 打开不存在的文件时 默认会新建文件
文件模式:
1. 工作模式
2. 命令模式
3. 编辑模式
4. 尾行模式
5. 可视模式
1. vim 文件 # 进入命令模式 只能查看无法修改文件内容
2. 进入编辑模式
i #在光标处进入编辑模式
a #在当前光标后面进入编辑模式
A #在行尾进入编辑模式
o(小写字母) #在光标的下一行进入编辑模式
O(大写字母) #在光标的上一行进入编辑模式
命令模式
光标定位键盘:
hjkl # h[左] j[下] k[上] l[右]
0 $ # 0[光标所在行 行首] $[光标所在行 行尾]
gg # 页首 --- 文本顶端
G 或者 shift+g # 页尾 ---- 文本底部
3G # 进入第3行 4G[进入第4行]
/关键词 #查找字符 n[下一个] N[上一个]
命令模式下的文本编辑
yy #复制当前行
p #粘贴 ----- 粘贴到本行的下一行
3yy 5yy #从光标处开始复制3行 或者 复制 5行
ygg # 从当前光标复制到页首
yG # 从当前光标复制到页尾
dd # 删除一行[删除光标所在行]
3dd #从光标开始删除3行
dgg #从光标处删除到页首
dG #从光标处删除到页尾
d^ #删除当前光标所在行之前的内容
P[大写字母] # 粘贴到本行的上一行
x #删除光标所在处的字符
D #从光标处删除到行尾
u #撤销
r #可以用于修改光标处的字符
尾行模式(底线模式)
shift+: 或者 : # 由命令模式进入尾行模式
:3 # 进入第3行
:w # 保存
:q # 退出
:wq #保存并退出
:q! #强制退出不保存
:wq! #强制保存并退出
:set nu # 设置行号
:set nonu # 取消行号
:set list #显示控制字符[可以筛选行内容末尾有空格的 行数据]
进入其他模式
#批量操作文件内容时
ctrl+v #进入可视块模式
shift+v #进入可视行模式
查找替换
语法:
:s /原内容/新内容/ # 将光标处 的原内容替换为新内容
:3 s/原内容/新内容/ # 替换指定行[替换第3行的内容]
:1,3 s/原内容/新内容/ # 替换第 1 ~ 3行的内容
:% s/原内容/新内容/ # 替换所有行[只会替换每一行中第一个原内容]
:% s/原内容/新内容/g # 替换行内所有的关键字
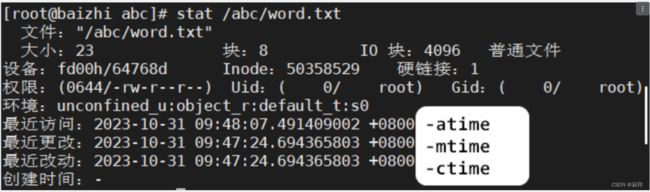
文件基本信息
语法:
stat 文件
详细的展示文件时间:
访问时间
修改时间 ----- 修改内容
改变时间 ----- 修改文件属性,例如 权限 名字
Linux用户管理
root的权限:
安装Centos时,需要设置root账户的管理员密码, root就相当于是超级用户,拥有最高的系统所有权,能够管理系统的各项功能
比如:
添加普通用户/删除普通用户 启动/关闭进程 开启/禁用硬件设备....
root权限必须很好的去把握 否则一个错误的指令可能会摧毁系统
root
UID 好比身份证号 root用户的UID是 0
GID 好比家庭编号(户口本编号) root 用户的GID 是 0
普通用户
UID 从 1000 开始 由 超级管理员创建 -----> 任何一个用户在创建时,都会在系统中创建一个同名的组[主属组]
GID
虚拟用户(系统用户)
UID 1 ~ 999
/etc/passwd
用户组group
为了方便管理同一组的用户。 ---- GID 是组与组之间的区别
|-假设一个公司有多个部门,每个部门有很多员工。
|- 可以对技术部门设置部门内的权限---- 可以访问公司的数据库
|- 员工可以独立赋予权限
用户和组的关系
1. 一对一 一个用户可以存在一个组里,组里就一个成员
2. 一对多 一个用户可以加入多个组
3. 多对一 多个用户可以在一个组中,这些用户和组有相同的权限
4. 多对多 多个用户存在多个组中
Linux的一大特性
多用户,多任务
所谓多用户多任务是指同一时间,有多个用户登录同一个系统执行不同的任务 ---- 互不影响
为了保证多用户,多任务正常执行,不出问题 ----- 设置不同的权限 Linux就是通过权限划分来管理实现多用户 多任务。
用户管理
用户相关的信息 ------ /etc/passwd
组相关的信息 ------ /etc/group
用户组
# 创建组
groupadd [可选参数] 组名 # 未指定gid时 默认从1000开始 依次递增 [从当前最大值开始进行递增]
# 创建组并制定gid
groupadd 组名 -g 组id
# 修改组
groupmod [参数] 组名
参数:
-g : 修改组id ---------> id值从 1000 开始
-n : 修改组名
# 删除组
groupdel 组名
案例:
# 创建 test 组
[root@bai abc]# groupadd test
# 创建 demo组 并设定 gid
[root@bai abc]# groupadd demo -g 1005
# 将 test 的gid 修改为 1003
[root@bai abc]# groupmod -g 1003 test
语法:
groupmod -g 新的gid 组名
# 将test的名字修改为 demo
[root@bai abc]# groupmod -n demo test
语法:
groupmod -n 新组名 原组名
# 删除 hr 组
[root@bai abc]# groupdel hr
语法:
groupdel 组名
删除组的注意事项:
1.用户的主属组不能删除 ------ 创建用户时,会自动分配主属组[且主属组与用户同名]
2.若组内存在用户,该组不可删除
/etc/group
```
```powershell
# 展示系统中所有组名
cut -d ":" -f 1 /etc/group
# 展示系统中所有组名 + gid
cut -d ":" -f 1,3 /etc/group
用户管理
/etc/passwd
shell的解释器版本
/bin/sh -- 默认
/bin/bash --- 默认
/sbin/nologin -- 虚拟用户[系统用户] 无法登陆,切换
/dash ubuntu
/csh unix
/tsh unix
1. 系统上的每个进程(每个运行的程序) 都是作为 系统用户 运行的
2. 每个文件是由一个特定用户拥有
3. 访问文件和文件夹 受到用户限制

用户创建
语法:
useradd 用户名; # 创建用户
特点:
1.新建用户的同时,会自动构建一个所属组 --- 组名和用户名一致 gid 自动增长
2. /home 目录下 ----> 用户的家目录 每创建一个用户 都会在 /home下创建对应的家目录
查看用户密码
/etc/shadow
# 创建用户 带参数
# 创建用户 user03 并制定id 为 1010
语法:
useradd user03 -u 1010
语法:
# 创建用户并指定shell
语法:
useradd 用户名 -s /sbin/nologin
# 创建用户并指定 附属组
语法:
useradd 用户名 -G 组名 # 附属组必须事先存在
案例:
[root@bai /]# useradd user06 -G user05
[root@bai /]# id user06
uid=1013(user06) gid=1013(user06) 组=1013(user06),1012(user05)
# 创建用户 并指定 主属组
语法:
useradd 用户名 -g 主属组的id
参数:
-c : 创建用户时,备注文字[保存在 passwd的备注栏中]
案例:
[root@bai ~]# useradd user10 -c 它是一个测试用户
28 user10:x:1016:1016:它是一个测试用户:/home/user10:/bin/bash
参数:
-d : 指定用户登录时的起始目录
案例:
[root@bai ~]# useradd user11 -d /home/peiqi # 将其他用户的家目录当做自己的 --- 会导致命令提示符消失
useradd:用户“user11”已存在
参数:
-e : 指定账号的到期时间
案例:
[root@bai ~]# useradd user13 -c user13能用到2023年10月27号 -e '2023-10-27'
参数:
-f : 缓冲天数 是指密码过期后多少天关闭该账号
-m: 自动建立用户的登录目录[默认就是家目录]
-M: 不要自动建立用户的登录目录
-r: 创建系统账户
-D: 参数用来修改配置文件 /etc/default/useradd 文件的默认值
例如:
[root@bai ~]# useradd -D -s /bin/bash
#1. 判断用户是否已存在
语法:
id 用户名
举例:
[root@bai abc]# id user01
uid=1001(user01) gid=1005(user01) 组=1005(user01)
用户标识 所属组标识 所属组
[root@bai abc]# id user02
id: user02: no such user
#2. 查看当前正在使用的用户
语法:
whoami
#3.删除用户
语法:
userdel -r 用户名 # 删除用户的同时,删除对应的家目录
创建用户流程
1. useradd 用户名
|- 系统会读取 /etc/login.defs(用户定义文件) 和 /etc/default/useradd(用户默认配置文件),借助这两个文件定义的规则 创建新用户
|- 向 /etc/passwd 和 /etc/group 文件添加 用户信息和组信息 向 /etc/shadow 中添加用户密码,/etc/gshadow 中添加组密码
|- 根据 /etc/default/useradd 文件中的配置信息创建用户的家目录
|- 把 /etc/skel 中所有的文件复制到 新用户的家目录中
/etc/login.defs
14 #QMAIL_DIR Maildir
15 MAIL_DIR /var/spool/mail # 系统发送邮件的位置
16 #MAIL_FILE .mail
25 PASS_MAX_DAYS 99999 # 密码最长使用天数
26 PASS_MIN_DAYS 0 # 密码更换最短时间
27 PASS_MIN_LEN 5 # 密码最短长度
28 PASS_WARN_AGE 7 # 密码失效前几天 警告
29
30 #
31 # Min/max values for automatic uid selection in useradd
32 #
33 UID_MIN 1000 # 新建普通用户最小的 uid
34 UID_MAX 60000 # 新建普通用户最大的 uid
35 # System accounts
36 SYS_UID_MIN 201 # 新建系统用户 最小的 uid
37 SYS_UID_MAX 999 # 新建系统用户最大的 uid
38
39 #
40 # Min/max values for automatic gid selection in groupadd
41 #
42 GID_MIN 1000 # 新建普通用户 最小的 gid
43 GID_MAX 60000 # 新建普通用户 最大的 gid
44 # System accounts
45 SYS_GID_MIN 201 # 新建系统用户最小的 gid
46 SYS_GID_MAX 999 # 最大的gid
60 CREATE_HOME yes # 是否自动创建家目录
61
62 # The permission mask is initialized to this value. If not specified,
63 # the permission mask will be initialized to 022.
64 UMASK 077 # 默认的权限掩码
65
66 # This enables userdel to remove user groups if no members exist.
67 #
68 USERGROUPS_ENAB yes
69
70 # Use SHA512 to encrypt password.
71 ENCRYPT_METHOD SHA512 # 密码加密算法
[root@bai ~]# cat -n /etc/default/useradd
1 # useradd defaults file
2 GROUP=100
3 HOME=/home # 在 /home 目录下 创建用户的家目录
4 INACTIVE=-1 # 开启用户过期
5 EXPIRE=
6 SHELL=/bin/bash # 新用户默认的解释器
7 SKEL=/etc/skel # 用户环境变量文件的存放目录
8 CREATE_MAIL_SPOOL=yes
9
用户密码
# root账户可以给其他用户设置密码 普通用户设置密码以后才可以进行登录
语法:
passwd 用户名
案例:
[root@bai abc]# passwd user02
更改用户 user02 的密码 。
新的 密码:
无效的密码: 密码少于 8 个字符
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
# root账户重置自己的密码
语法:
passwd
案例:
[root@bai abc]# passwd
更改用户 root 的密码 。
新的 密码:
无效的密码: 密码少于 8 个字符
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
注意:
#普通用户修改自己的密码
1. 需要提供原密码
2. 新密码必须遵守规范(包含大小写字母 不能出现单词 必须包含特殊符号 @ # $ % 数字 长度不低于8)
3. 限定修改次数
#passwd的实际应用
#设置 user15的密码: 7天内用户不得修改密码 60天不能改 临近过期前10天通知用户 过期30天以后禁止用
户登录
案例:
[root@bai ~]# passwd user15 -n 7 -x 60 -w 10 -i 30
[root@bai ~]# passwd -S user15 # 查看用户密码的状态
user15 PS 2023-10-26 7 60 10 30 (密码已设置,使用 SHA512 算法。)
参数说明:
-n : 至少多少天不可修改密码
-x : 最多多少天不能修改
-w : 过期前多少天通知用户
-i : 过期多少天禁止用户登录
# 批量更新密码
语法:
chpasswd
案例:
[root@bai ~]# chpasswd ------》 root用户可以使用
user03:111
user04:222
操作结束 按 ctrl+d 保存退出
# 切换用户
方式一:
su 用户名
# 直接切换,没有完全切换环境变量
案例:
[root@bai ~]# su gaosc
[gaosc@bai root]$ env|egrep "USER|MAIL|PWD|LOGNAME"
USER=gaosc
MAIL=/var/spool/mail/root
PWD=/root
LOGNAME=gaosc
方式二:
su - 用户名
案例:
[root@bai ~]# su - gao
上一次登录:四 10月 26 09:46:18 CST 2023pts/0 上
[gao@bai ~]$ env|egrep "USER|MAIL|PWD|LOGNAME"
USER=gao
MAIL=/var/spool/mail/gao
PWD=/home/gao
LOGNAME=gao
[gao@bai ~]$ logout
注意:
root 切换其他普通用户 直接切换
普通用户 切换回 root 需要管理员密码
用户操作
# 修改用户名 -----> 只修改用户名,其他(uid gid 所属组)不变
语法:
usermod -l 新名字 原名
案例:
[root@bai ~]# usermod -l user666 user02
[root@bai ~]# id user02
id: user02: no such user
[root@bai ~]# id user666
uid=1002(user666) gid=1006(user02) 组=1006(user02)
# 修改 gid
语法:
usermod 用户名 -g 新的gid # 新的gid必须事先存在 更换主属组
# 修改uid
语法:
usermod -u 新的uid 用户
案例:
[root@bai ~]# usermod -u 1003 user03
# 修改用户登录的shell
语法:
usermod -s 登录方式 用户名
案例:
[root@bai ~]# usermod -s /sbin/nologin user03
# 修改用户的家目录
语法:
usermod 用户名 -d 指定的家目录
提权
不同用户,可以访问的文件范围,所拥有的权限都不相同。
例如: 群主(root) 管理系统工作量太大时,可以设置管理员 (普通用户 ---[提权 sudo]--- 管理员)
配置sudo 目的在于 让运维干活方便 权限把控,同时又不威胁系统安全


如何恢复命令提示符
1. 确保 /home 目录下存在正确的用户家目录[若不存在,就新建]
2. 登录 root 账户 然后复制初始化系统文件
cp /etc/skel/.bash* /home/家目录/
案例:
[root@baii ~]# mkdir -p /home/user15
[root@baii ~]# cp /etc/skel/.bash* /home/user15/
whoami相关指令
1.
语法:
whoami # 显示当前终端登录的用户
案例:
sh-4.2# whoami
root
2.
语法:
w 指令 #显示当前已经登录系统的用户信息
案例:
# sh-4.2 代表 shell解释器的版本为 sh
sh-4.2# w
15:39:32 up 1 day, 5:55, 2 users, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
gaosc tty1 15:39 12.00s 0.00s 0.00s -bash
root pts/0 192.168.127.1 09:38 4.00s 0.02s 0.01s w
# 展示结果解析
1. 显示的是系统时间,系统从启动到运行的时间,系统运行中的用户数量和平均负载
2. 第二行信息
user: 用户名
TTY: 用户使用终端号
FROM:标识用户从哪来 [终端所在机器的 ip地址]
LOGIN@ : 登录系统的时间
IDLE: 代表终端空闲时间
JCPU: 该终端所有进行以及子进程使用系统的总时间
PCPU: 活动进程使用系统的时间
WHAT: 用户执行的进程名称
3.
语法:
who ----- 等同于 w 的简化版
案例:
[root@bai ~]# who
gaosc tty1 2023-10-26 15:39
root pts/0 2023-10-26 09:38 (192.168.127.1)
4. last、lastlog 命令查看当前机器所有用户最近的登录信息
案例:
# last命令显示已登录的用户列表和登录时间
[root@centos-128 ~]# last
root pts/0 192.168.240.1 Thu Oct 26 18:42 still logged in
root pts/0 192.168.240.1 Thu Oct 26 17:23 - 18:41 (01:18)
root pts/0 192.168.240.1 Thu Oct 26 17:23 - 17:23 (00:00)
root pts/0 192.168.240.1 Thu Oct 26 08:29 - 17:22 (08:53)
# lastlog 命令显示当前机器所有用户最近的登录信息
[root@bai ~]# lastlog
户名 端口 来自 最后登陆时间
root pts/0 192.168.240.1 四 10月 26 18:42:16 +0800 2023
bin **从未登录过**
baizhi pts/0 四 10月 26 14:03:28 +0800 2023
xiaozhang **从未登录过**
xiaoli **从未登录过**
xiaowang **从未登录过**
demo **从未登录过**
user1 pts/0 四 10月 26 18:48:19 +0800 2023
user2 **从未登录过**
user3 **从未登录过**
组成员管理
注意:
只针对已存在的用户
# 给组添加账户
语法:
gpasswd -a 用户 组名
案例:
[root@bai ~]# gpasswd -a user04 yangdd
正在将用户“user04”加入到“yangdd”组中
用户 有 自己的 所属组 ----> 主组 gid
用户 后续可以加入其他组 ----> 附属组
# 给组添加多个用户
gpasswd -M 用户1,用户2,用户3 组名;
案例:
[root@bai ~]# gpasswd -M gao,user03,user666 yangdd
[root@bai ~]# id gao
uid=1000(gao) gid=1000(gao) 组=1000(gao),1003(yangdd)
[root@bai ~]# id user03
uid=1003(user03) gid=1010(user03) 组=1010(user03),1003(yangdd)
主属组id 主属组 附属组
# 从组中删除用户
gpasswd -d 用户名 组名
案例:
[root@bai ~]# gpasswd -d gaosc yangdd # 无法从主属组 中移除 当前用户
正在将用户“gaosc”从“yangdd”组中删除
[root@bai ~]# id gao
uid=1000(gao) gid=1000(gao) 组=1000(gao)
权限控制
Linux文件权限
[root@bai abc]# ls -la /abc
总用量 28
drwxr-xr-x. 3 root root 109 10月 26 16:51 .
dr-xr-xr-x. 23 root root 4096 10月 24 10:40 ..
-rw-r--r--. 1 root root 72 10月 26 16:46 a.txt
-rw-r--r--. 1 root root 419 10月 24 17:59 b.txt
-rw-r--r--. 1 root root 68 10月 25 10:15 demo.txt
-rw-r--r--. 1 root root 150 10月 25 09:50 file13.txt
drwxr-xr-x. 2 root root 6 10月 23 15:29 file99
-rw-r--r--. 1 root root 11 10月 24 14:34 filetxt
-rw-r--r--. 1 root root 92 10月 26 16:51 ip.txt

文件
读 r ------ > cat/less/more/sort/head/tail等查看文件内容的指令
写 w -----> vim echo vi 等编辑指令
执行 x -----> 指令[文件系统中鼠标双击]
文件夹
读 r ----> ls 列出此目录下的所有文件
写 w ----> 可以在目录下新建文件,删除文件,cp mv
执行 x -----> cd 目录
#如何知道我和文件之间的权限
1. 明确身份 [属主 属组 其他人]
2. 文件属于你本人 属于你们组 其他人
3. 查看权限码 [r w x -]
#数字与权限之间的对应关系:
r ----- 4
w ----- 2
x ----- 1
a.txt的对外权限
-rw-r--r--
或者
644
#注意 :
权限控制的指令测试,使用其他用户
权限设置
chmod : 为文件或者文件夹 设置访问权限
chown : 改变文件或者文件夹的 属主 属组
更改文件的属主(所有者) 属组(所属组)
chown指令
# 修改文件的属组 属主
语法:
chown 用户 文件名 ---- 修改属主
chown :组 文件名 ---- 修改属组
chown 用户:属组 文件名 --- 修改属主、属组
chown 用户 文件夹 --- 修改文件夹的属主[对其内部的文件,子文件夹没有影响]
chown -R 用户 文件夹 ---- 递归修改
参数:
-R 递归处理所有的文件以及子文件夹
-v 为处理的所有文件显示诊断信息
1.修改文件属主[属组]
语法:
chown 用户名 文件
chown [可选参数] 用户名 文件夹
chown :组名 文件
2.同时修改属主和属组
chown [-R -v] 用户:组 文件[夹]
chmod指令
chmod 命令主要用来变更文件或者目录的权限。
在UNIX系统中,文件或者目录的控制
读
写
执行
注意: 若权限修改针对的是软链接(快捷方式)------> 受影响的是文件自身

# 设置文件的属主可读
chmod u+r 文件
# 设置文件的属组可读
chmod g+r 文件
# 设置文件的其他人可读
chmod o+r 文件
chmod o=r 文件 # 将其他人对文件的操作 设定为 可读[不可写 不可执行]
# 设置文件的所有人可读
chmod ugo+r 文件
或者
chmod a+r 文件
# 文件的属主、属组可写 其他人不可写
chmod ug+w,o-w 文件
# 文件的属主可以执行
chmod u+x 文件
# 文件的属主增加可执行,属组增加可读,其他人取消执行权限
chmod u+x,g+r,o-x 文件
# 设置文件的所有人都可读可写可执行
chmod a+rwx 文件
# 将属主的权限设定为 可读可写可执行 属组权限设定为可读可执行 其他人设定为可读可执行
chmod 755 a.txt
# 属主[可读可写] 属组[可读] 其他人[可读]
chmod 644 a.txt
# 所有人都无权限
chmod 0 a.txt
# 属主是0权限 属组是可读可写 其他人是 可读可执行
chmod 65 a.txt 等价于 chmod 065 a.txt
# 属主是0权限 属组是0权限 其他人是 可读
chmod 4 a.txt 等价于 chmod 004 a.txt
注意:
使用数字设定权限时,不要与 ugo 连用
4 2 1
r w x
组合
0 无权限
1 可执行
2 可写
4 可读
3 可写可执行
5 可读可执行
6 可读可写
7 可读可写可执行 4+2
# 仅对文件夹进行权限设置
chmod 权限 文件夹
# 对文件夹及内部子目录,内部文件 统一设定权限
chmod -R 权限 文件夹
chgrp指令
1. chgrp 命令用来改变文件或者目录 的 属组
2. chgrp 命令用来改变指定文件 的属组
其中 组名 可以使用 gid[用户组的id] 也可以是 组名
语法:
chgrp [可选参数] 组 文件[文件夹]
参数:
-c : 效果类似于 -v 只汇报更改的部分
-v : 汇报所有内容[包含未变的 更改的]
-h : 只对符号链接[快捷方式的软链接]的文件进行修改
-R : 递归处理[将指定目录及子目录一并处理]
-f : 不显示错误信息
umask指令
1. umask 命令用来限制新文件权限 ----- 权限掩码 也称之为 遮罩码 , 防止 文件或者目录 创建的时候
权限过大
2. 对于文件[文件夹]
文件 777[包含可执行文件] 666[普通文件]
目录 777
3. 当新文件被创建时,其最初的权限是由 umask 决定
4. 用户每次注册进入系统时,umask命令都会被执行 并自动设置掩码 改变 新建文件初始的权限
#记录umask默认配置的文件
/etc/profile
59 if [ $UID -gt 199 ] && [ "`/usr/bin/id -gn`" = "`/usr/bin/id -un`" ]; then
60 umask 002
61 else
62 umask 022
63 fi
64
umask 值 含义是 Linux文件默认属性需要减掉的权限
# linux普通文件最大的默认权限值为 666 目录最带的默认权限值 777
新建的文件或者文件夹 削减 权限
linux系统预置的umask值为 022 那么用户新建普通文件时 a.txt
666
- 022
----------
644 ----> -rw-r--r--
umask 的语法参数
-p : 以umask开头 以数字形式显示 权限掩码
-S : 以字符形式显示 权限掩码
案例:
# 查看root账户的 umask
[root@bai ~]# umask
0022
解析:
0 提权参数
0 属主掩码
2 属组掩码
2 其他人掩码
案例:
# 以字母形式显示权限掩码
[root@bai ~]# umask -S
u=rwx,g=rx,o=rx
解析:
u=rwx 新建文件时 属主的权限 rwx
g=rx 新建文件时 属组的权限 rx
o=rx 新建文件时 其他人的权限 rx
案例:
# 以数字形式展示 umask
[root@bai abc]# umask -p
umask 0022
# 基于root 账户 创建 /abc/def 文件夹
mkdir /abc/def # def文件夹初始权限 755 777-022=755 drwxr-xr-x
drwxr-xr-x. 2 root root 6 10月 27 16:28 def
# 基于root 账户 创建 /abc/oppo.txt
touch /abc/oppo.txt # oppo.txt文件初始权限 644 普通文件= 666 - 022 = 644 -rw-r--r--
-rw-r--r--. 1 root root 0 10月 27 16:29 oppo.txt
# 基于root 账户 创建 /bin/dd
[root@bai abc]# touch /bin/dd
[root@bai abc]# ls -l /bin/dd # 777-022=755 -rwxr-xr-x
-rwxr-xr-x. 1 root root 74896 10月 27 17:16 /bin/dd
# 修改当前用户的umask值
umask 新值 # 只是临时修改,用户重新登录以后 umask 会恢复默认值
# 修改用户的 umask 权限掩码以后 新建文件 采用的 文件[最大权限 777] 目录[最大权限 777]
chattr指令
chattr 命令用于更改文件的扩展属性 比 chmod 更改权限 更底层
语法:
chattr [可选参数] 文件
语法参数:
-R : 递归更改目录属性
-V : 显示命令的执行过程
模式:
+ : 增加模式
- : 移除模式
= : 指定模式
A : 不让系统修改文件最后访问时间
a : 只能向文件中添加数据,不得删除更改内容
i : 文件不能被删除,改名,修改内容
案例1:
# 给 d.txt 增加 i 模式
[root@bai file]# chattr +i d.txt
[root@bai file]# rm -f d.txt # 删除失败
# 查看 d.txt 的模式
[root@bai file]# lsattr d.txt
-------i------ d.txt
# 取消 i 模式
[root@bai file]# chattr -i d.txt
# 查看 d.txt 的模式
[root@bai file]# lsattr d.txt
------------- d.txt
案例2:
# 演示 a 模式 : 只能向文件中增加内容 不得更改
[root@bai file]# touch a.txt
[root@bai file]# chattr +a a.txt
[root@bai file]# echo "测试数据" > a.txt # 覆盖
-bash: a.txt: 不允许的操作
[root@bai file]# echo "测试数据" >> a.txt # 追加
[root@bai file]# lsattr a.txt
-----a---------- a.txt
[root@bai file]# chattr -a a.txt
[root@bai file]# lsattr a.txt
---------------- a.txt
[root@bai file]# echo "测试数据" > a.txt
lsattr指令
lsattr 命令用于查看文件的第二扩展属性(看底层模式) ---- 结合 chattr使用
lsattr 文件 # 查看 chattr 给文件改动的模式
语法:
lsattr [可选参数] 文件
参数:
-R : 递归列出目录以及子目录下的 chattr设置的模式 该参数默认存在
-V :显示程序版本
-v : 显示文件版本
-a : 列出目录中的所有文件 包括隐藏文件的属性
-d : 只列出当前目录的模式 不展示子目录的模式
案例:
[root@bai user03]# lsattr file1
----i----------- file1/a.txt
----i----------- file1/b.txt
[root@bai user03]# lsattr -d file1
----i----------- file1
提权补充[高级权限设置]
#高级权限 suid sgid sticky
suid -----> 提升权限[只针对二进制文件(命令)生效,其他不管用] 4
sgid -----> 组继承[只能对目录设置] 2
sticky ----> 权限控制 1
设置特殊权限
# 字符写法
chmod u+s 文件 #[二进制命令文件] -----> 对某个命令进行提权,不管谁使用该命令,效果都等同于管理员
chmod u-s 文件
# 数字写法
chmod 4777 file
chmod 0777 file
案例:
[root@bai ~]# cat /root/file.txt # root用户可以执行 cat指令
[root@bai ~]# su - user03 # 切换普通用户
上一次登录:一 10月 30 09:51:25 CST 2023pts/0 上
[user03@bai ~]$ cat /root/file.txt # 普通用户无法行驶 cat 指令
cat: /root/file.txt: 权限不够
[user03@bai ~]$ su - root
密码:
上一次登录:一 10月 30 10:01:50 CST 2023pts/0 上
[root@bai ~]# which cat
/bin/cat
[root@bai ~]# chmod u+s /bin/cat # 切换回 root账户 对二进制文件 cat[指令] 提权
[root@baizhi ~]# su - user03
上一次登录:一 10月 30 10:02:59 CST 2023pts/0 上
[user03@bai ~]$ cat /root/file.txt # 提权以后 user03也可以运行该指令
[user03@bai ~]$
# 字符写法
chmod g+s 目录 # 使某个目录下的文件在创建时,新建文件的所属组继承该目录的所属组
chmod g-s 目录
例如
/
|- bai
|-abc [属主是 user03 属组是user03]
|-file.txt [属组 user03]
# 数字写法
chmod 2777 目录
案例:
[root@bai ~]# cd /home/user03
[root@bai user03]# ll
总用量 0
drwxrwxr-x. 2 user03 user03 19 10月 30 10:19 baizhi # bai目录的属组是 user03
drwxrwxr-x. 2 user03 user03 32 10月 27 17:46 file
drwxr-xr-x. 2 root root 32 10月 27 17:50 file1
-rw-rw-rw-. 1 user03 user03 0 10月 27 18:01 testA.txt
-rw-rw-r--. 1 user03 user03 0 10月 30 09:52 user03.txt
[root@bai user03]# cd bai
[root@bai bai]# ll
总用量 0
-rw-rw-r--. 1 user03 user03 0 10月 30 10:19 a.txt
[root@bai bai]# touch b-root.txt # 切换 root登录 新建文件的属组是 root组
[root@bai bai]# ll
总用量 0
-rw-rw-r--. 1 user03 user03 0 10月 30 10:19 a.txt
-rw-r--r--. 1 root root 0 10月 30 10:20 b-root.txt
[root@bai bai]# chmod g+s /home/user03/bai # 后续无论哪个用户新建的文件 属组都是 user03
[root@bai bai]# touch c-root.txt
[root@bai bai]# ll
总用量 0
-rw-rw-r--. 1 user03 user03 0 10月 30 10:19 a.txt
-rw-r--r--. 1 root root 0 10月 30 10:20 b-root.txt
-rw-r--r--. 1 root user03 0 10月 30 10:21 c-root.txt # 验证
#字符写法
chmod o+t 目录 # 使某个目录下的所有文件 只有创建者和root可以删除 其他不行
chmod o-t
#数字写法
chmod 1777 目录
# sticky 只针对目录有效,对于目录的作用是 当用户在该目录下新建文件或者子目录时,只有自己(属主)和root有权删除
提权区别
sudo : 有针对性的 例如针对某个用户能够以 root 的身份来执行指令
suid : 针对基本所有用户 任何用户在执行 被 suid 权限的程序(指令) 都是以 root 身份执行的
sudo提权细节
visudo
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
gaosc ALL=(ALL) ALL # 任意位置,任意指令 gaosc 都可操作
user03 NOPASSWD:/bin/mkdir,/bin/rm,/bin/ls /home # user03 在 /home 目录下可以执行 mkdir,rm,ls指令
管道与重定向
重定向
1. 标准输入,标准正确输出,标准错误输出
2. 进程在运行过程中根据需要会打开很多文件,每次打开文件会有一个数字标识,这个数字标识叫做 文件描述符
3. 进程使用文件描述符来管理打开的文件
4. 每一个打开的程序都有自己的文件描述符
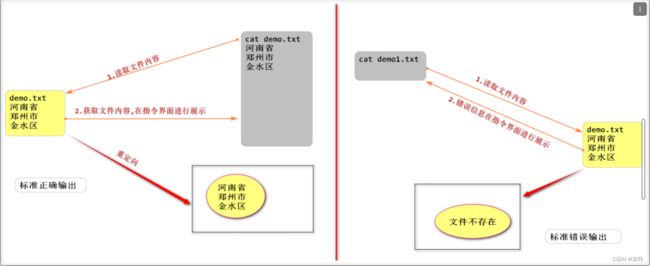
0 : 标准输入(键盘)
1 : 标准正确输出
2 : 标准错误输出
3+ : 进行在执行过程中打开的其他文件
& : 表示正确错误混合输出
输出重定向
> 覆盖
>> 追加
标准正确输出: 1> 1>> 此处 等价于 > >>
标准错误输出: 2> 2>>
#案例1: 标准正确输出重定向
[root@bai ~]# date
2023年 10月 30日 星期一 14:32:20 CST
[root@bai ~]# date 1> /abc/date.txt # 此时若文件不存在,会新建
[root@bai ~]# cat /abc/date.txt
2023年 10月 30日 星期一 14:34:40 CST
[root@bai ~]# date > /abc/date.txt # > 标准正确输出重定向----覆盖
[root@bai ~]# cat /abc/date.txt
2023年 10月 30日 星期一 14:35:51 CST
[root@bai ~]# date 1>> /abc/date.txt # >> 标准正确输出重定向----追加(换行)
[root@bai ~]# cat /abc/date.txt
2023年 10月 30日 星期一 14:35:51 CST
2023年 10月 30日 星期一 14:36:31 CST
# 标准错误输出重定向
[root@centos-128 /]# ll /bc
ls: 无法访问/bc: 没有那个文件或目录
[root@centos-128 /]# ll /bc 2>> /a/err.txt
[root@centos-128 /]# cat /a/err.txt
ls: 无法访问/bc: 没有那个文件或目录
[root@bai /]# ls /abc /home /qwe 2>> /abc/error.txt # 错误信息输出到 error.txt文件中,正确的在控制台(操作界面)展示
# 正确和错误的都输出到相同位置
[root@bai /]# ls /home /abc /qwe &> /abc/test.txt
#正确的输出到一个文件中 错误的输出到另外一个文件中
[root@bai /]# ls /abc /qwe 1>> /abc/a.txt 2>> /abc/c.txt
标准正确输出重定向 标准错误输出重定向
#正确的输出到文件中 错误的结果输出到垃圾桶(回收站)[内容不会保留]
# /dev/null 垃圾桶,回收站
[root@bai /]# ls /abc /qwe >> /abc/a.txt 2>> /dev/null
echo
会将其后输入的内容送往标准输出(打印)
语法:
echo 内容 >> 文件(脚本)
#案例
[root@bai /]# echo "HelloWorld"
HelloWorld
[root@bai /]# echo "HelloWorld" 1>> /abc/word.txt
[root@bai /]# cat -n /abc/word.txt
1 HelloWorld
输入重定向
标准输入: < 或者 0<
默认情况下,cat命令会接受标准输入设备(键盘)的输入,并显示在控制台(操作界面) 。 可以使用文件来代替键盘作为
输入设备 那么该命令会以指定的文件作为输入设备 将文件中的内容读取并显示到控制台
[root@bai /]# cat /etc/passwd
[root@bai /]# cat < /etc/passwd
解析:
虽然执行结果相同,但是第一行代表是以键盘作为输入设备 而第二行代码 是以 /etc/passwd 文件作为输入设备
将/etc/passwd 作为 cat 的输入 读出 /etc/passwd 的内容
通过输入重定向创建文件
cat(2) > 文件(3) << 输入源(1)
cat > 文件 << EOF
用来创建文件或者脚本时进行使用,并向文件中输入信息,并且输入的任何内容都会被写入文件中
案例:
[root@bai /]# cat > /abc/demo.txt <
> 床前明月光
> 疑是地上霜
> 举头望明月
> 低头思故乡
> EOF
[root@bai /]# cat /abc/demo.txt
床前明月光
疑是地上霜
举头望明月
低头思故乡
# 首先借助 EOF 将键盘作为输入设备,然后将输入的内容传递给 cat , cat 会将接收的内容 重定向输出到文件中
# 利用重定向建立多行的文件 ---- 脚本创建多行文件
[root@bai /]# cat > create_demo.sh <
> #!/bin/bash
> ls -la /abc
> EOF
[root@bai /]# ./create_demo.sh
管道
将一个指令的输出,作为另外一个指令的输入
语法:
指令1 | 指令2 | 指令3
案例:
# 查找指定目录下符合要求的文件
[root@bai /]# ls /etc | grep 'fire'
firewalld
# 将 /etc/passwd 文件中的用户名按照 UID 进行排序
[root@bai /]# sort -n -t ":" -k 3 /etc/passwd # 以:分隔 将第三列按数字进行排序
# 将 /etc/passwd 文件中的用户名按照UID进行排序 降序展示
[root@bai /]# sort -n -r -t ":" -k 3 /etc/passwd
# 以 : 分隔 将第三列按照字数升序 查看前5行
[root@bai /]# sort -t ":" -n -k 3 /etc/passwd | head -n 5
# 以 : 分隔 将第三列按照字数降序 查看后10行
[root@bai /]# sort -t ":" -n -k 3 /etc/passwd | tail
# 先按照uid升序排列获取后10行,在按照 gid 降序排列展示
[root@bai /]# sort -t ":" -n -k 3 /etc/passwd | tail | sort -t ":" -k 4 -n -r
文件查找
find指令
find命令用来在指定目录下查找文件。
注意:
任何位于参数之前的字符串都会被当做目录来看待
如果使用该命令,未设置任何参数 ----- find命令在当前目录下查找子目录和子文件,将查找到的子目录和文件进行展示。
用法:
find [-H] [-L] [-P] [-Olevel] [-D help|tree|search|stat|rates|opt|exec] [path...] [expression]
find 处理符号链接 要查找的路径 参数 限定条件 执行动作。
语法:
find 查找目录和文件
find 路径 -命令参数
路径作用是告诉find去哪找你要的内容
案例:
# 根据名字 进行全盘检索 /
find 从哪找 名字叫什么
# 获取 /abc 目录下所有的 以.txt结尾的文件
[root@bai /]# find /abc -name "*.txt"
# 在 /abc 下查找 .txt 文件 但是最多找三级目录 /abc 属于一级 /abc/def 属于二级
[root@bai dir1]# find /abc -maxdepth 3 -name "*.txt"
参数:
1. -P[可以省略] 要查找的路径
2. -maxdepth 设置最大目录层级
3. -mindepth 设置最小目录层级
4. -atime access 按照文件访问的时间进行查找 [单位是 天]
5. -ctime change 按照文件的改变的状态查找文件[单位是 天]
6. -mtime motify 按照文件修改motify时间查找[单位是天 最常用]
7. -name 按照文件名字查找 支持通配符 * ? []
8. -group 按照文件的所属组查找
9. -perm 按照文件的权限查找
10. -size n 按照文件的大小进行查找 其中 n 代表后缀
b : 代表512位元组的区块[如果用户没有指定后缀,默认就是 b]
c :表示字节数
k : 表示KB [1KB=1024字节]
w : 字 [2字节]
M : 兆 [10MB=10240KB]
G :千兆[1G=1024MB]
11. -type 查找某一类型的文件
b : 块设备文件
d : 目录
c : 字符设备文件
p : 管道文件
l : 符号链接
f :普通文件
s : socket文件
12. -user : 按照文件属主查找文件
13. -path : 配合 -prune 参数排除指定目录
14. -prune : 使find命令不在指定的目录中查找
15. -delete : 删除找出的文件
16. -exec 或者 -ok : 对匹配的文件执行相应的 shell命令
17. -print : 将匹配的结果标准输出
18. ! 取反[经常和其他参数连用,表达取反]
19. -a -o : 取交集 并集 作用类似于 && 或
案例:
# 从当前目录下 寻找 以 0 - 9 开头的文件
[root@bai abc]# find . -name "[0-9]*" # 将当前目录下所有 0 ~ 9开头的文件和文件夹都检索并展示
# 从当前目录下 寻找 以 0 - 9 开头的文件夹
[root@bai abc]# find . -name "[0-9]*" -type d
# 获取所有以 0 ~ 9 开头的文件并删除
[root@bai abc]# find . -name "[0-9]*" -type f -delete
#时间(atime mtime ctime)
解析:
1. 访问时间(-atime/天 -amin/分钟):用户最近一次访问时间 (若仅为查看,访问时间不变 若文件修改并发起查看,时间改变)
2. 更改时间(-mtime/天 -mmin/分钟): 文件最后一次修改时间(数据内容变动)
3. 改动时间(-ctime/天 -cmin/分钟):文件数据元(例如权限)最后一次修改时间
文件任何数据改变(change变化) 无论元数据变动或是对文件 mv cp
文件内容被修改时 mtime ctime 会变化
当 change 更新以后 第一次访问该文件(cat less more) atime第一次会更新,后面atime不会在更新保持不变
补充:
touch -t : 使用指定的时间戳来记录文件的创建时间
touch -a : 更新 access time 同时还会更新 ctime 为当前时间
touch -m : 更新 modify time 同时还会更新 ctime 为当前时间
touch -c : 不能创建新文件
案例1:
# 获取指定文件夹下 两天内 被访问过的文件
[root@bai abc]# find /abc -atime -2 -type f
# 获取指定文件夹下,一天以内内容变化的文件
[root@bai abc]# find /abc -mtime -1 -type f
# 获取指定文件夹下,恰好两天内被访问过的文件
[root@bai abc]# find /abc -atime 2 -type f
# 获取指定文件夹下,两天以上被访问过的文件
[root@baizhi abc]# find /abc -atime +2 -type f
说明:
find . -type f -atime -2 # 查找两天内被访问的文件 (48小时内)
find . -type f -atime 2 # 查找恰好两天内被访问的文件(48 ~ 72小时内)
find . -type f -atime +2 #查找两天前被访问的文件(48小时以上)
案例2:
# 获取 /abc下所有的文件
find /abc -type f
# 获取 /abc 下所有的 非文件
find /abc ! -type f
[root@bai abc]# find /abc -type f -size +10M # 获取 /abc 文件夹下大小超过 10MB 的 文件
[root@bai abc]# find /abc -type f -size 100k # 获取当前目录下文件大小恰好为100KB的文件
[root@bai abc]# find /abc -type f -size +10k # 获取当前目录下文件大小超过10KB的文件
[root@bai abc]# find /abc -type f -size +100c # 获取当前目录下文件大小超过 100 字节 的文件
# 查看文件大小
[root@bai abc]# du -h 文件 # 查看文件大小
# 获取 /abc 文件夹下 除 /abc/def 以外 所有的 .txt 文件
[root@bai abc]# find /abc -path /abc/def -prune -o -name "*.txt" -print

# 获取 /abc/def/dir1 下所有的.txt 结尾的文件 执行删除
[root@bai abc]# find /abc/def/dir1 -name "*.txt" -type f -ok rm {} \;
< rm ... /abc/def/dir1/abc_def_dir1_a.txt > ? y
< rm ... /abc/def/dir1/abc_def_dir1_b.txt > ? y
# 获取 /abc/def 下所有的 .txt 结尾的文件 并移动到 /abc/dir1下
[root@bai abc] find /abc/def -name "*.txt" -type f -exec mv {} /abc/dir1 \; # 移动文件不做提示
或者
[root@bai abc] find /abc/def -name "*.txt" -type f -ok mv {} /abc/dir1 \; # 移动文件做提示
# 获取 /log 目录下 30天以前的日志 拷贝到 /old-30 文件夹中
[root@bai abc] find /log -type f -mtime +30 -name "*.log" -exec cp {} /old-30 \;
xargs指令
xargs指令 称为 管道命令,构造参数。
给命令传递参数的一个过滤器。也是组合多个命令的一个工具,它可以把一个数据流分割成足够小的块,
方便过滤器和命令进行处理 [把其他命令给它的数据 传递给 它后面的命令做参数]
语法:
命令1 |{xargs进行过滤} 命令2
参数:
-d : 为输入指定一个分隔符 默认分隔符是空格
-i : {} 代表找出的文件 语法: xargs -i {} mv {} 目录
-I : 使用字符串代表找出的文件 语法: xargs -I str mv str 目录
-n : 选线限制单个命令行的参数个数
案例测试文件:
[root@centos-128 a]# cat file.txt
1 2 3 4 5 6
7 8 9 10 11 12
案例1:
# 将文件内容平铺在一行上进行展示
[root@centos-128 a]# xargs < file.txt
1 2 3 4 5 6 7 8 9 10 11 12
[root@centos-128 a]# cat file.txt | xargs
1 2 3 4 5 6 7 8 9 10 11 12
案例2:
# 将文件内容加工展示,限定每行展示 5个字符
[root@centos-128 a]# cat file.txt | xargs -n 5
1 2 3 4 5
6 7 8 9 10
11 12
[root@centos-128 a]# xargs -n 5 < file.txt
1 2 3 4 5
6 7 8 9 10
11 12
案例测试文件:
[root@centos-128 a]# echo "小二,小黑,小白"
小二,小黑,小白
案例3:
# 指定分隔符,对内容进行分割
[root@centos-128 a]# echo "小二,小黑,小白" | xargs -d ","
小二 小黑 小白
案例4:
# 批量移动文件[以当前目录为搜索目录]
1. 检索获取满足条件的文件
2. 批量移动
[root@bai abc] find . -name "*.txt" -type f | xargs -i mv {} 目录
# alltxt代表检索出的文件 -I 代表检索文件的变量 可以随意命名(不能是关键字)
[root@bai abc] find . -nam "*.txt" -type f | xargs -I alltxt mv alltxt 目录
# 检索单个文件,并移动改名
[root@bai abc] find . -name "a.txt" | xargs -i mv {} /def/test.txt
案例5:
指令1 | 指令2
将指令1 的执行结果 交给 指令2 ----- 指令1 的执行结果是 字符串
# 对 ls cp rm 管道无法执行
可以通过 xargs
# 查找根目录下所有的sh文件,并拷贝到指定目录下
例如: find / -type f -name "*.sh" | xargs -i cp {} /目录
# cp 源文件 目标文件
# ls [参数] 文件
find / -type f -name "*.sh" | xargs ls -l
find /abc -type f -name "*.txt" | xargs rm -f # 删除/abc下所有的 .txt 文件
案例6:
# 获取 /abc 下所有 .txt结尾文件的详细信息
ls -l /abc/*.txt # 列出 /abc 目录下的 .txt 文件 不包含子目录下的 txt
[root@bai test2]# find /test2 -type f -name "*.txt" | xargs ls -l
[root@bai test2]# find /test2 -type f -name "*.txt" | xargs -i ls -l {}
[root@bai test2]# find /test2 -type f -name "*.txt" | xargs -I allTxt ls -l allTxt
# 将 /test2 下所有的 .txt结尾文件 复制到 /test3下
[root@bai test2]# mv /test2/*.txt /test3 # 只会复制 test2 目录下 子目录下的txt文件未操作
[root@bai test2]# find /test3 -type f -name "*.txt" | xargs -I alltxt cp alltxt /test4
# 获取 /abc 下所有的 .txt结尾的文件 移动到 /test3 下
[root@bai test2]# mv /test2/*.txt /test3 # 移动了 test2 下的 txt文件 子目录下的txt文件未操作
[root@bai test2]#[root@baizhi test2]# find /test2 -type f -name "*.txt" | xargs -I allTxt mv
allTxt /test3
# 获取 /abc 下所有的 .txt结尾的文件 删除
[root@bai test2]# rm -f /test2/*.txt # 删除的只是 test2 目录下 子目录下的未操作
[root@bai test2]# find /test4 -type f -name "*file.txt" | xargs rm -f
注意:
1. 单条指令可以实现的效果,尽量不要使用管道,效率低
wc指令
wc命令用于统计文件的行数、单词数、字节数
参数:
-c 打印字节数
-m 打印字符数
-l 打印行数
-L 打印最长行(内容最多的那一行)的长度
-w 打印单词数
案例测试文件:
[root@centos-128 a]# cat > word.txt << EOF
> hello jjjjj aaaaa aaaaa aaaaa aaaaa aaaaa qqqqq
> EOF
案例:# 统计文件的行数
[root@centos-128 a]# cat word.txt | wc -l
1
# 统计单词的数量
[root@bai abc]# echo "Hello World test HelloWorld demo" | wc -w
5
# 统计字符数
[root@bai abc]# echo "gaosc" | wc -m # "gaosc" 实际为 "gaosc$"
6
[root@bai abc]# echo "gaosc" > word.txt
[root@bai abc]# cat word.txt
gaosc
[root@bai abc]# cat -n -A word.txt
1 gaosc$
[root@bai abc]# cat -E word.txt
gaosc$
[root@bai abc]# echo "gaosc" | cat -A
gaosc$
注意 :
cat -A 等价与 cat -E 展示内容的时候加上 $
# 统计文件中内容最多哪一行的字符数
[root@centos-128 a]# cat -E word.txt | wc -L
48
[root@centos-128 a]# cat word.txt | wc -L
47
# 统计在线用户数
who | wc -l
tr指令
tr命令可以从标准输入中替换、缩减或者删除字符 将结果写入标准输出
语法:
tr [可选参数] 内容
参数:
-d 删除所有限定的字符
-s 去除重复的限定字符
案例:
# 去除 所有数字
[root@bai abc]# echo "public static 123 void main my 456 name 789 is 666 gaosc" | tr -d '0-9'
public static void main my name is gaosc
# 去除所有小写字母
[root@bai abc]# echo "public static 123 void main my 456 name 789 is 666 gaosc" | tr -d 'a-z'
123 456 789 666
# 去除重复的限定字符
[root@bai abc]# echo "iiii ooo ppp qqq" | tr -s 'a-z' # a - z 所有重复字符去重[保留一个]
i o p q
# 去除 62an 这几个字符
[root@bai abc]# echo "public static 123 void main my 456 name 789 is 666 gaosc" | tr -d '62an'
public sttic 13 void mi my 45 me 789 is gosc
# 去除重复的限定字符
[root@bai abc]# echo "public static 123 void main my 456 name 789 is 666 gaosc" | tr -s '62an'
public static 123 void main my 456 name 789 is 6 gaosc
linux文件属性与管理
文件[文件夹]的属性
1. 索引节点 inode
2. 文件类型
3. 文件权限
4. 硬链接数量
5. 属主,属组,其他人
6. 时间[atime mtime ctime]
# 查看文件(目录)属性的命令
ls -lhi # 详细信息 + 文件大小 + inode号码

文件类型
# windows 下文件类型[文件扩展名]
.docx
.doc
.java
.txt
.py
.mp3
.mp4
.md
.zip
.rar
.gif
.png
.......
对window系统,修改文件的扩展名 -----> 会出现问题 影响使用
# linux 扩展名
Linux文件的扩展名,只是为了方便阅读 与 文件类型没关系
规范上通用写法:
.txt 文本类型[方便阅读]
.conf .cfg .configure 配置文件
.sh .bash 脚本后缀
.py 脚本后缀
.rpm 红帽系统二进制软件包名
.tar .gz .zip 压缩后缀
ls -F # 给文件结尾加上特殊标识
- 普通文件(二进制 图片 日志 txt)
d 文件夹
b 块设备文件 例如 磁盘 光驱
c 设备文件 例如 /dev/tty1 网络串口文件
s 套文字文件 , socket文件进程间的通信
p 管道文件
l link类型 链接文件 快捷方式
#普通文件
通过以下命令生成
echo touch cp cat 重定向
普通文件的特征 以 "-" 开头
|- 纯文本 可以使用 cat命令 读取文件内容 例如 字符 数字 特殊符号
|- 二进制文件 linux命令中 ls cat 命令
#文件夹
文件夹开头是 d 是一种特殊的 linux 文件
mkdir
cp 拷贝文件夹
ls
cd
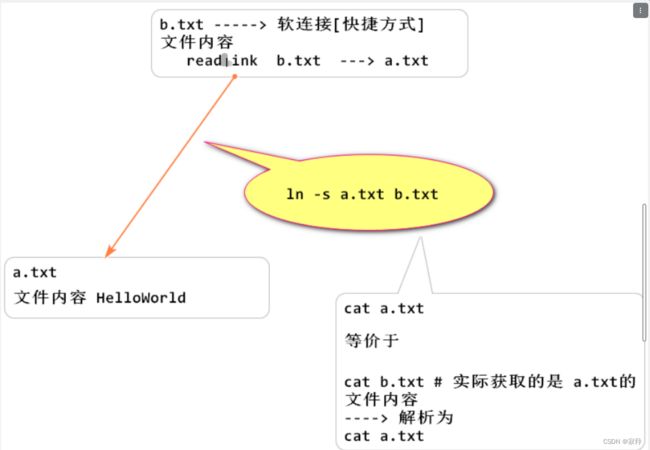
#链接文件
类似于快捷方式
创建软链接
语法:
ln -s 目标 快捷方式文件名
例如: ln -s filetxt.txt file_快捷方式.txt
# lrwxrwxrwx. 1 root root 7 10月 31 16:21 file_快捷方式.txt -> filetxt
# 获取软链接中保存的内容
readlink 软连接的文件名
# 案例
[root@bai abc]# cat file_快捷方式.txt # 实际获取的就是 filetxt 的文件内容
HelloWorld
[root@bai abc]# cat filetxt
HelloWorld
[root@bai abc]# readlink file_快捷方式.txt
filetxt # 软链接的文件内容就是 指向文件的名字
指令文件
[root@bai abc]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@bai abc]# which ls
alias ls='ls --color=auto'
/usr/bin/ls
从上方的目录下逐个寻找,找到返回
# 获取指令使用手册的位置
[root@bai abc] whereis ls
ls: /usr/bin/ls /usr/share/man/man1/ls.1.gz
指令位置 指令使用手册的位置
tar指令
tar 在linux系统中,可以实现 多个文件进行 压缩 打包 解压缩
打包 :将一大堆文件或者目录 汇总成一个整体
压缩 :将大文件压缩成小文件,节省磁盘空间
语法:
tar [可选参数] 包裹的文件名 需要打包的
参数:
-A : 新增文件到已经存在的 备份文件(打包文件)中
-B : 设置区块大小
-c : 新建备份文件(打包文件)
-d : 记录文件的差别
-x : 从备份文件中还原文件(解包)
-t : 列出备份文件的内容
-z : 通过压缩指令处理备份文件 搭配 -c -x 使用(服务于gzip 压缩解压缩指令)
-Z : 通过指令处理备份文件
-f : 指定备份文件
-v : 显示指令的执行过程
-r : 添加文件到已经压缩的文件中
-u : 添加改变了和现有的文件到已经存在的压缩文件中
-j : 支持 bzip2 解压文件
-l : 文件系统边界设置
-k : 保留原有文件不覆盖
-m : 保留文件不被覆盖
-w : 确认压缩文件的正确性
-p: 用原来的文件权限还原文件
重点参数(熟练记忆使用):
-c 打包文件
-z 压缩文件
-x : 从备份文件中还原文件(解包)
-f 指定备份文件,必须写在指令结尾
# 仅打包,不压缩
tar -cvf 打包文件 打包目录
# 案例
[root@bai /]# tar -cvf /abc/打包1.tar /abc/* #将 abc文件夹下所有内容打包
# 打包后 可以使用 gzip 命令 压缩 ----- 节省磁盘空间 ----- 备份
[root@bai /]# tar -zcvf /abc/压缩1.tar.gz /abc/* # 将 abc文件夹下所有内容打包并压缩
注意:
1. f参数必须写在最后,后面要紧跟压缩文件名(打包文件名)
2. tar命令仅为打包 习惯使用 .tar 表示打包文件
3. tar命令加上z参数 打包并压缩 习惯使用 .tar.gz 或者 .tgz 表示压缩文件
# 解压缩 [还原]
[root@bai abc]# tar -zxvf 压缩1.tar.gz ./tarDir/ # 将 压缩1.tar.gz 解压缩到 tarDir目录下
# 查看压缩包中 压缩的内容
[root@bai abc]# tar -ztvf 压缩1.tar.gz
# 解压缩某一个文件
[root@bai abc]# tar -zxvf 压缩1.tar.gz ./tarDir/fileb.txt #将压缩包中的 fileb.txt 解压缩到tarDir目录下
# 解压缩,并指定文件夹
[root@bai abc]# tar -zxvf 压缩文件 -C 指定的文件夹 [-C 可以省略]
# 排除某个文件 其他文件解压缩
tar -zxvf 压缩包 --exclude 文件 # 文件支持范围通配
# 压缩软链接
[root@bai abc]# tar -zcvf 软链接.tar.gz run_软链接.txt #压缩软链接,压缩的就是软链接本身,对指向的文件没有影响
# 压缩软链接时 使用 -h 参数
[root@bai abc]# tar -ztvf filetxt_软链接.tar.gz # 虽然操作的是软链接,但是真正压缩的是软链接指向的文件
gzip指令
tar命令主要是打包(也可以压缩),gzip命令是压缩
语法:
gzip [选项] 参数
案例:
# 对于文件夹,必须是先打包,再压缩
tar -cvf file_打包.tar 目标文件夹 # 先打包
gzip file_打包.tar # 压缩 原来的打包文件被 压缩文件 替换了[节省磁盘空间]
# 列出压缩包文件的内容
[root@bai abc]# gzip -l 0file打包.tar.gz
compressed uncompressed ratio uncompressed_name
127 10240 99.1% 0file打包.tar
压缩后文件大小 压缩前文件大小 压缩比 打包文件
zip指令
zip命令:是一个应用广泛的跨平台压缩工具 压缩文件的后缀是 .zip文件(方便阅读) 支持压缩文件夹
语法:
zip 压缩文件名 要压缩的内容
# 对当前目录下所有的内容进行压缩
zip allAbc.zip ./* # 将当前目录下所有内容压缩 注意文件后缀是 .zip
# 解压缩
unzip allAbc.zip
注意: 系统若未识别 zip 指令(必须联网)
yum install zip
yum install unzip
通配符
概念:
通配符就是键盘上的一些特殊字符,可以实现特殊的功能,例如 指定规则进而搜索文件。
利用通配符 可以更轻松的处理字符信息
比如:
1. * [0 ~ n个任意字符]
gaosc* -----> gaosc gaosc123 gaosc1 gaosc.txt
2. ? [任意一个字符]
gaosc? ----> gaosc1
gaosc??? -----> gaosc123
3. {1..100} ----> 1 2 3 ... 100
{1,2} -----> 1 2
{1..100..2} ----> 1 3 5 7 9 ... 99
4. ^
^高 -----> 以高开头的文件
5. $
sc$ -----> 以sc结尾
常见通配符
| 符号 | 含义 |
|---|---|
| * | 匹配任意0~n个字符 |
| ? | 匹配任意一个字符 有且只有一个 |
| [abcd] | 匹配abcd中任意一个字符 |
| [^abcd]或[!abcd] | 不匹配abcd中任意一个字符 |
| [0-9] | 匹配0-9中任意一个字符 |
| [a-zA-Z] | 匹配a-z或A-Z中任意一个字符 |
特殊通配符
注意:(下面匹配的都是任意一个字符,只有 * 匹配的是0-n个字符)
1. 匹配所有大写字母 [[:upper:]]
# 案例
[root@bai abc]# cat a.txt | grep "[[:upper:]]"
2. 匹配所有小写字母 [[:lower:]]
[root@bai abc]# cat a.txt | grep "[[:lower:]]"
3. 匹配所有字母 [[:alpha:]]
[root@bai abc]# cat a.txt | grep "[[:alpha:]]"
4.匹配所有数字 [[:digit:]]
[root@bai abc]# cat a.txt | grep "[[:digit:]]"
5. 匹配所有字母和数字 [[:alnum:]]
[root@bai abc]# cat a.txt | grep "[[:alnum:]]"
6. 匹配所有的空白字符[空格字符] [[:space:]]
[root@bai abc]# cat a.txt | grep "[[:space:]]"
7. 所有标点符号 [[:punct:]]
[root@bai abc]# cat a.txt | grep "[[:punct:]]"
案例:
# 获取根目录下最大文件夹深度是 3 且所有以 l 开头的文件 且 以 小写字母结尾,中间出现任意一个字符的文件
[root@bai abc]# find / -maxdepth 3 -type f -name "l?[[:lower:]]"
# 获取 /tmp 目录下 以任意一位数字开头 且以非数字结尾的文件
[root@bai abc]# find /tmp -type f -name "[[:digit:]][![:digit:]]"
[root@bai abc]# find /tmp -type f -name "[0-9][^0-9]"
# 获取 根目录下 以 非字母开头 后面跟着一个字母以及其他任意长度字符的文件
1a 1a+ 1aaaa
[root@bai abc]# find / -type f -name "[!a-zA-Z][a-zA-Z]*"
[root@bai abc]# find / -type f -name "[![:alpha:]][[:alpha:]]*"
# 获取 /tmp 目录下所有 以 非字母开头的.txt文件 复制到 /abc 文件夹下
[root@bai abc]# cp /tmp/"[!a-zA-Z]*.txt" /abc
# 获取 /tmp 目录下所有的 .txt 结尾的文件 且 以 y 或者 t 开头
[root@bai abc]# find /tmp -type f -name "[y,t]*.txt"
# 展示根目录下所有的 .sh结尾文件的详细信息
[root@bai test2]# find / -type f -name "*.sh" | xargs ls -l
# 展示根目录下所有的 以 old 开头的文件
[root@bai test2]# find / -type f -name "old*" | ls -l
# 获取根目录下 以 l 开头 中间有一个任意字符 最后是一个小写字母的文件
[root@bai test2]# find / -type f -name "l?[a-z]" | xargs ls -l
# 获取根目录下所有以 l 开头 中间有两个任意字符 以大写或者小写字母结尾的 文件
[root@bai test2]# find / -type f -name "l??[a-zA-Z]" | xargs ls -l
路径相关
~ 当前登录用户的家目录 例如:cd ~ 切换到当前用户的家目录下
- 上一次的工作路径
案例:
[root@bai ~]# cd /test2
[root@bai test2]# cd /
[root@bai /]# cd -
/test2
[root@bai test2]# pwd
/test2
[root@bai test2]#
. 当前工作路径 [或者隐藏文件 .gaosc.txt]
.. 上一层目录 例如: cd .. 回到上一层目录
引号
特殊符号。 单引号 双引号 反引号 [esc按键下面 ``]
介绍:
单引号 '' 所见即所得 强引用 单引号中的内容会原样输出[指令失效 转义字符失效]
双引号 "" 弱引用 能够识别各种特殊的符号:变量 转义字符 解析结果
# 转义字符 \n[换行] \t[tab制表位] \r[回车符号 制表符]
没有引号 一般连续的字符串,数字,路径可以省略 若 遇到特殊字符: 空格 变量 必须加双引号
反引号 `` 常用语引用命令的执行结果 类似于 $(命令)
案例:
touch gao sc; # 创建两个文件 gao sc
touch 'gao sc' # 创建一个文件 gao sc
touch 'ls -l gaosc' #创建一个文件 ls -l gaosc
# 创建以时间为名字的文件
touch date +%F # 创建两个文件分别为 date文件 +%F文件
touch 'date +%F' #创建一个文件 文件名 date +%F
touch "date +%F" # 等同于 单引号的效果
[root@bai test2]# touch "`date +%F`"
[root@bai test2]# touch "$(date +%T)"
# 双引号与 单引号的区别
[root@bai test2]# echo PATH
PATH
[root@bai test2]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@bai test2]# echo "$PATH"
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@bai test2]# echo '$PATH'
$PATH
# 不加引号 双引号 单引号 ----> 填充的指令不会解析
# `指令` $(指令) ----> 指令会先执行,将结果输出使用
# $变量 -----> 输出变量的值 例如 echo $PATH
#自定义变量,并输出变量的值 自定义变量时 变量名="变量值" 变量名后面不要出现空格
gaosc="小黑,小白,小花"
echo $gaosc
# 案例
[root@bai test2]# echo 今年是$(date +%Y)年
今年是2023年
[root@bai test2]# echo 今年是`date +%Y`年
今年是2023年
其他特殊符号
; 分号 :命令分隔符或是结束符
# 1.文件中的注释内容 2.root账户身份提示符
| 管道符 :传递指令的执行结果到另一个指令
$ # 1.$变量 取出变量中保存的值 2. 普通用户的身份提示符
{} # 1.生成序列 2.引用变量作为变量与普通字符的分隔
# ; 分号
1. 表示命令结束 命令;
2. 命令间的分隔符 命令1;命令2
案例
[root@bai ~]# pwd;ls -l /test2 #两个指令都会执行
3. 配置文件的注释符
$
1. linux系统的命令行中 字符串前加 $ 获取 字符串变量中的值
案例
[root@bai ~]# name1="小黑,小白"
[root@bai ~]# echo name1
name1
[root@bai ~]# echo $name1
小黑,小白
# {}
1. 生成序列 1 ~ 9 1 ~ 100 a ~ z A ~ Z
# 案例
[root@bai ~]# echo {1..10}
1 2 3 4 5 6 7 8 9 10
[root@bai ~]# echo {a..z}
a b c d e f g h i j k l m n o p q r s t u v w x y z
[root@bai ~]# echo {A..Z}
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
[root@bai ~]# echo {1..10..2} # 2 代表步长
1 3 5 7 9
# 快速备份文件
[root@baizhi test2]# cp /etc/sysconfig/network-scripts/ifcfg-ens33{,.back.ori}
-rw-r--r--. 1 root root 409 10月 20 17:22 ifcfg-ens33
-rw-r--r--. 1 root root 409 11月 1 17:16 ifcfg-ens33.back.ori
# 目标文件{,后缀} ----> 目标文件 目标文件.后缀
# 将变量括起来作为变量的分隔符
[root@bai test2]# week="周三"
[root@bai test2]# echo $week
周三
[root@bai test2]# echo "$week_oldFile.txt"
.txt
[root@bai test2]# echo "${week}_oldFile.txt" # 此时只会把 {} 中的 week 作为变量解析
周三_oldFile.txt
逻辑操作符
逻辑符既可以在linux系统中直接使用,也可以在bash脚本中使用
&&
指令1&&指令2
若指令1报错,指令2就不执行了
若指令1正确,指令2才执行
||
指令1||指令2
若指令1正确,指令2跳过,不执行
若指令1错误,指令2才执行
!
1. 在bash 中取反 [!abcd]
2. vim 编辑中表达强制的含义 wq! q!
3. 找出最近执行的指令并执行
例如:
!! 再次执行上一次的指令
!ls 列出最近一次 以 ls 开头的指令 并执行
!cd 列出最近一次 以 cd 开头的指令 并执行
案例1:
[root@bai test2]# ls -l /test1 && cd /test1
ls: 无法访问/test1: 没有那个文件或目录 # 指令1错误 指令2跳过未执行
[root@bai test2]# ls -l /test1;cd /test1
ls: 无法访问/test1: 没有那个文件或目录 # 两个指令都执行
-bash: cd: /test1: 没有那个文件或目录
案例2:
[root@bai test2]# ls -l /test1 || cd /test1
ls: 无法访问/test1: 没有那个文件或目录
-bash: cd: /test1: 没有那个文件或目录 # 指令1 错误 指令2 才执行
[root@bai test2]# ls -l /test2 || cd /test1 # 指令1 正确 指令2 跳过
# 查看历史指令
[root@bai test2]# history
# 再次运行某一个历史指令
[root@bai test2]# !行号
正则表达式
1. bash是一个命令处理器(shell的解释器),运行在文本窗口中,并能执行用户输入的指令
2. bash还可以从文件中读取linux命令,该文本就称之为脚本
3. bash还支持通配符,管道,命令替换,条件判断,正则表达式,逻辑控制语句
注意:
1. "黑窗口" 就是文本窗口 可以执行我们的指令 ls cd rm mv....
2. 指令还可以放在文件中,文件的后缀是 .sh
bash执行脚本文件步骤:
1. 准备脚本文件
touch demo.sh
2. 填充文件内容
[root@bai test4]# cat demo.sh
touch hello.py
echo "print('Hello World')" >> hello.py
3. 运行该文件,文件内部的指令会被执行
sh demo.sh
# 1. 新建 hello.py 文件 2. 向hello.py文件追加了 python 的输出语句
4. 运行python文件
python hello.py # 文档窗口打印 HelloWorld
正则表达式
1. 功能与通配符相似
2. 主要用来处理文件,处理字符串信息,处理文本信息
3. 大数据时代,例如 收集了大量的用户信息 想要快速的筛选数据 比如 筛选 邮箱 家庭住址 邮编 ip...
可以使用正则表达式 结合文本 制定筛选条件
使用正则表达式的工具
文本处理工具,都支持正则表达式
1. grep 文本过滤工具 主要从文本中提取我们所需要的信息
2. sed 流编辑器 主要用于对文本进行 替换 删除 增加信息
3. awk 主要用于将文本内容格式化输出
注意:
[root@bai test4]# which awk
/usr/bin/awk
[root@bai test4]# ls -l /bin/awk
lrwxrwxrwx. 1 root root 4 10月 20 17:19 /bin/awk -> gawk
awk-> gawk (awk是gwak的快捷方式,软链接)
正则表达式详解
# 基本正则表达式BRE[basic regular expression]
BRE 对应的元字符 ^ $ . [] *
# 扩展正则表达式ERE[extended regluar expression]
ERE 在 BRE基础上 增加了 () {} ? + |
BRE基本正则表达式
匹配字符
匹配次数
位置锚定(定位)
^ 用于模式(匹配规则)的最左侧, 例如 ^gsc 匹配以 gsc单词开头的行
$ 用于模式的最右侧, 例如 gsc$ 表示以 gsc 单词结尾的行
^$ 组合符 表示 空行
. 匹配任意一个且只有一个字符 不能匹配空行
\ 转义字符 让特殊含义的字符 现出原型,还原本意 例如 \. 代表小数点
* 匹配符号前一个字符连续出现0次或多次 重复0次 代表 空 代表匹配所有内容[不进行单独使用]
.* 组合符 匹配所有内容[包含空行]
^.* 组合符 匹配任意多个字符开头的内容
.*$ 组合符 匹配任意多个字符结尾的内容
[abc] 匹配[]集合内的任意一个字符 a b c 或者 [a-c]
[^abc] 匹配除了 ^ 后面的任意字符 ^ 表示对[abc]取反
ERE扩展正则表达式
+ 匹配前一个字符1次或多次
[字符1字符2] 匹配括号中的字符 1次或多次 例如 [ab]+ 匹配ab一次或多次 [:/]+ 匹配 :/ 一次或多次
? 匹配前一个字符0次或1次
| 表示或者,同时过滤多个字符串
() 分组过滤,被括起来的内容是一个整体
a{n,m} 匹配前一个字符(例如 a)最少 n 次 最多 m 次
a{n,} 匹配前一个字符 最少 n 次
a{,m} 匹配前一个字符 最多 m 次
a{n} 恰好匹配前一个字符n次
# 注意
1. grep命令使用扩展正则表达式 需要添加 -E 参数
2. grep -E 等价于 egrep 但是 egrep已经弃用
3. grep 不加参数 需要在特殊字符前加 \ 识别为正则表达式
grep指令
1. 作用
文本搜索工具,根据用户指定的模式(过滤筛选条件),对目标文件逐行进行匹配检查 打印匹配到的行
2. 模式(过滤筛选条件)
由 正则表达式 及 文本字符 共同组成
3. 语法
grep [可选参数] [模式] 文件
4. 可选参数
-i 忽略字符的大小写
-o 仅展示匹配到的字符串
-v 显示不能被模式匹配的行(取反)
-E 支持使用扩展正则表达式的符号(元字符)
-q 静默模式 不输出任何信息
-n 显示匹配行 与 行号
-c 只统计匹配的行数
-- color 为 grep过滤的结果添加颜色高亮展示 alias grep="grep --color=auto"
-w 只匹配模式的单词(把模式中当做单词 而不再是关键字----精确匹配整个单词)
grep命令是linux系统中最重要的命令之一 , 功能是从文本文件 或者 管道数据流 中筛选 匹配的行 和数据,往往是搭
配正则表达式起到快速筛选的作用
案例:
准备测试数据
# 列出 包含 "root" 的行及行号
[root@bai test4]# grep -n "root" demo.txt
# 列出包含 "ROOT" 的行及行号
[root@bai test4]# grep -n "ROOT" demo.txt
# 列出包含 root [不区分大小写]的行及行号
[root@bai test4]# grep -n -i "root" demo.txt
# 列出不包含 "root"[无论大小写] 的行及行号
[root@bai test4]# grep -n -i -v "root" demo.txt
# 列出包含 root 或者 love 的行及 行号
[root@bai test4]# grep -n "root|love" demo.txt # 因为 | 属于 ERE 必须使用 grep -E
[root@bai test4]# grep -n -E "root|love" demo.txt
# 列出 root 单词所在的行
[root@bai test4]# grep -n -w "root" demo.txt
# 使用 grep 列出所有文件内容
[root@bai test4]# grep -n ".*" demo.txt
# 列出所有的注释行和空白行
[root@bai test4]# grep -n -E "^#|^$" demo.txt
# 排除所有的注释行和空行
[root@bai test4]# grep -n -E -v "^#|^$" demo.txt
# 列出所有以 . 结尾的行
[root@bai test4]# grep -n "\.$" demo.txt
# 获取 demo.txt中所有以 H 开头的行
[root@bai test4]# grep -n "^H" demo.txt
# 匹配模式是三位字符,其中后两位是 nu 第一位任意
[root@bai test4]# grep -n ".nu" demo.txt
# 匹配模式是三位字符 其中中间是任意字符 两边是 f h
[root@bai test4]# grep -n "f.h" demo.txt
# 匹配模式为 每行 不区分大小写的 i 出现 0 ~ n次
[root@bai test4]# grep -n -i "i*" demo.txt
# 匹配模式为 左侧为 I 右侧为 o 中间任意次数的任意字符
[root@bai test4]# grep -n "I.*o" demo.txt
# 匹配模式为 出现 a b c 任意一个字符
[root@bai test4]# grep -n "[abc]" demo.txt
# 匹配模式为 未出现 a b c 的任意字符
[root@bai test4]# grep -n "[^abc]" demo.txt
# 匹配模式为 出现 字母的行
[root@bai test4]# grep -n -i "[a-z]" demo.txt
[root@bai test4]# grep -n "[a-zA-Z]" demo.txt
# 匹配所有数字的行
[root@bai test4]# grep -n "[0-9]" demo.txt
# 匹配所有数字 所有字母
[root@bai test4]# grep -n "[0-9a-zA-Z]" demo.txt
[root@bai test4]# grep -n -i "[0-9a-z]" demo.txt
扩展正则表达式演示
案例:
# 找出文件中包含 loe 或者 le 的行
[root@bai test4]# grep -E -n "lo?e" demo.txt
# 找出文件中出现 1 ~ n 次 l 的行
[root@bai test4]# grep -E -n "l+" demo.txt
# 获取文件中出现字符 a 或者 字符 b 的行
[root@bai test4]# grep -n "[ab]" demo.txt
[root@bai test4]# grep -n -E "a|b" demo.txt
# 获取根目录下 所有 名字中包含 a 或者 b的 .txt 文件
[root@bai test4]# find / -type f -name "*.txt" | grep -E "a|b"
# ()
小括号 将一个或者多个字符捆绑在一起 当做一个整体处理
1. 功能一 分组过滤被括起来的内容,括号内的内容是一个整体
2. 功能二 括号中的内容还可以被 后面 的 "\n" n代表数字 表示引用第几个括号的内容
|- \1 表示从左侧开始,第一个括号中的模式所匹配到的字符
|- \2 从左侧开始,第二个括号模式所匹配的字符
# 获取 文件中的 good glad
[root@bai test4]# grep -n -E -o "good|glad" test.txt
[root@bai test4]# grep -n -E "g(oo|la)d" test.txt
# (l..e) 匹配 l在左侧 e 在右侧 中间是任意两个字符 \1 代表引用 前面括号的匹配结果
[root@baizhi test4]# grep -E -n "(l..e).*\1" demo2.txt
# (l..e) 匹配 l在左侧 e 在右侧 中间是任意两个字符 like | love
# (l..e) 匹配 l在左侧 e 在右侧 中间是任意两个字符 love | like
[root@bai test4]# grep -E -n "(l..e).*(l..e)" demo2.txt
# 获取 唯一的获取 root用户
[root@bai test4]# grep -E -n "(r..t).*\1" /etc/passwd
# {n,m}
括号前的字符出现的次数
# 匹配字母a 最少 1次 最多 3次
[root@bai test4]# grep -E "a{1,3}" demo3.txt
# 匹配字母a 最少 2 次 最多 3次
[root@bai test4]# grep -E -o "a{2,3}" demo3.txt
# 逐行匹配字母a 最少 4次
[root@bai test4]# grep -E -o "a{4,}" demo3.txt
# 逐行匹配字母a 最多4次
[root@bai test4]# grep -E "a{,4}" demo3.txt
# 逐行匹配字母a 恰好4次
[root@bai test4]# grep -E -o "a{4}" demo3.txt
sed指令
注意:
sed和awk使用单引号,双引号有特殊解释
1. sed 是 Stream Editor (字符流编辑器),简称流编辑器
2. sed是操作、过滤、转换文本内容的工具
3. 常见功能
结合正则表达式,对文件实现快速的增删改查操作。
查询:过滤(过滤指定字符串) 、 取行(取出指定行)
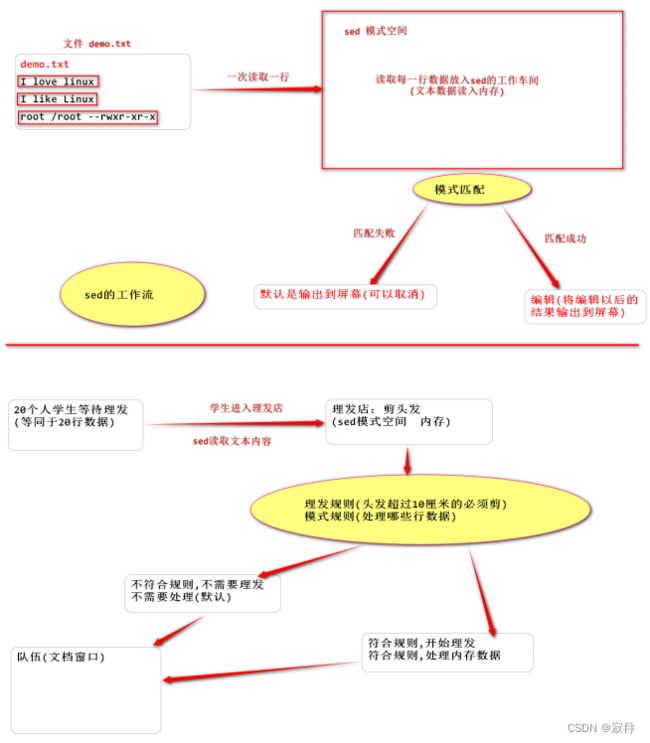
# 语法
sed [可选参数] [(匹配模式)sed内置命令符] 文件 # sed内置命令符作用就是执行动作
参数:
-n 取消默认sed的输出 常与sed内置命令 p 一起用
-i 直接将修改结果写入文件, 未使用 -i sed修改的只是内存数据(对文件数据没有影响)
-e 多次编辑,不需要管道符
-r 支持扩展正则表达式
sed 的内置命令字符 : 用于对文件进行不同的操作,例如 增加,删除,修改,查询打印文件信息
a : append 对文本追加,在指定行后面添加一行或者多行文本
d : delete 删除匹配的行
i : insert 表示插入文本,在指定行之前添加一行或者多行文本
p : print 打印匹配行的内容 通常与 可选参数 -n 一起用
s/正则表达式/替换内容/g 或者 s#正则表达式#替换内容#g
# sed的匹配范围
空地址(没有模式匹配) : 全文处理
单地址 : 指定文件某一行加工
/匹配模式/ : 被模式匹配到的行
范围区间 : 10,20 第10行到20行 10,+5 第10行向下5行(总共六行)
/匹配模式1/,/匹配模式2/ 表示从匹配模式1开始查找到匹配模式2结束(包括匹配模式2那行)
步长 : 1~2 表示 1 3 5 7 9[获取所有奇数行] 2~2 表示 2 4 6 8 10[获取所有偶数行]
案例:
# 输出文件第5-8行内容
[root@bai test4]# sed -n '5,8p' sedDemo.txt # 添加 -n 以后 不再显示默认输出
# 过滤出包含 linuex 的字符串行
[root@bai test4]# sed -n '/linuex/p' sedDemo.txt
# 删除含有 games 的行
[root@bai test4]# sed -n '/games/d' sedDemo.txt # 文件内容未做修改
[root@bai test4]# sed -i '/games/d' sedDemo.txt # 修改以后的文件内容同步到文件(文件内容修改)
# 删除 3行 到最后
[root@bai test4]# sed -i '3,$d' sedDemo.txt
[root@bai test4]# sed -i '3~1d' sedDemo.txt
# 将文件中所有的 a 替换为 p [-i 表示将改动以后的内容同步回文件]
[root@bai test4]# sed -i 's/a/p/g' sedDemo.txt
# 替换所有的 His 为 my 同时将 QQ号修改为 888888
[root@bai test4]# sed -e 's/His/my/g' -e 's/123456789/888888/g' sedDemo.txt
# 在文件第二行追加内容并写入文件
[root@bai test4]# sed -i '2a 明天周六,王者上分 \n后天周日,钓鱼' sedDemo.txt # 追加两行
# 在文件第十行之前添加内容
[root@bai test4]# sed -i '10i 正则表达式 \n通配符' sedDemo.txt
# 在文件每一行之后都添加新内容
[root@bai test4]# sed -i 'a ------------------' sedDemo.txt
# 展示所有文件内容
[root@bai test4]# sed -n 'p' sedDemo.txt # 打印所有行
# 展示文件指定行
[root@bai test4]# sed -n '2p' sedDemo.txt # 打印第2行
# 获取linux主机的ip地址
# 1. 获取 ip 地址
[root@bai test4]# ip a
# 2. 获取 ip 所在行
[root@bai test4]# ip a | sed -n '9p'
# 3. 去除 ip 之前的内容
[root@bai test4]# ip a | sed -n '9p' | sed -e 's#^.*inet.##g'
# 4. 去除 ip 之后的内容
[root@bai test4]# sed 's#/.*##g'
# 5. 合并
[root@bai ~]# ip a | sed -n '9p' | sed -e 's#^.*inet.##g' -e 's#/.*##g'
awk指令
awk 可以进行文本的格式化。 ---- 将文本数据格式化为 专业的 excel 表样式
awk 早期在Unix系统中使用,我们使用的 awk 实际是 gawk GUN awk。
awk 也是一门编程语言 支持条件判断 数组 循环...
语法:
awk 可选参数 模式 {动作} 文件(或者数据)
注意:
动作主要是指数据的"格式"化 ---- 最常用的动作 print 和 printf
# 获取第三列内容
[root@bai test4]# awk '{print $3}' alex.txt
1. 执行的指令内容是 awk '{print $3}' 没有使用参数,也没有使用匹配模式, $3 表示输出文本的第三列信息
2. awk默认的空格就是分隔符,且 多个空格也会识别为一个空格 作为分隔符
3. awk 按 行 处理 一行处理完毕,再处理下一行 根据用户指定的分隔符去工作 没有指定分隔符默认使用 空格
4. 指定了分隔符 awk 把每一行切割后的数据 对应到 内置变量中
注意:
1. $0 表示整行
2. $NF 表示当前分割后的最后一列
# 例如 获取最后一列信息
[root@bai test4]# awk '{print $NF}' alex.txt
3. $(NF-1) 表示分割后倒数第二列
[root@bai test4]# awk '{print $(NF-1)}' alex.txt
awk的内置变量
$n 指定分隔符以后,当前记录的是第 n 列
$0 完整的输入记录
FS 输入分隔符,默认是 空格
NF 分割后,当前行一共有多少列
NR 当前记录数 ---- 多少行
OFS 输出分隔符,默认是 空格
# 一次性输出多列
# 输出第一列,第二列,第三列
[root@bai test4]# awk '{print $1,$2,$3}' alex.txt
# 自定义输出内容
[root@bai test4]# awk '{print "第一列:",$1,"第二列:",$2,"第三列:",$3}' alex.txt
[root@bai test4]# awk '{print "第一列: "$1,"第二列: ",$2,"第三列: ",$3}' alex.txt
#输出所有行信息
[root@bai test4]# awk '{print}' alex.txt
[root@bai test4]# awk '{print $0}' alex.txt
参数:
-F 指定分割字段符
-v 定义或修改一个 awk内部的变量
-f 从脚本文件中读取 awk命令
案例:
# 获取 pwd.txt 文件的第五行信息
[root@bai test4]# awk 'NR==5' pwd.txt
注意:
NR==5 一个等号是赋值的含义 两个等号才是关系运算符
# 获取文件的第 2 ~ 5行
[root@bai test4]# awk 'NR==2,NR==5' pwd.txt
# 给每一行的内容添加行号
添加变量 NR等于行号 $0 表示一整行内容
[root@bai test4]# awk '{print NR,$0}' pwd.txt
# 获取文件的 5 ~ 7行 加上行号
[root@bai test4]# awk 'NR==5,NR==7 {print NR,$0}' pwd.txt
# 获取 pwd.txt 文件的 第一列 最后一列 倒数第二列
[root@bai test4]# awk -F ":" '{print "用户名:",$1,"用户组:",$(NF-1),"登录方式:",$NF}' pwd.txt
awk的输入与输出分隔符
awk 的分隔符分为两种
1. 输入分隔符 awk 默认的是空格 空白字符 FS的默认值 就是 空格 [filed separator]
2. 输出分隔符 OFS [Out filed separator] 默认值也是空格
案例:
测试数据:
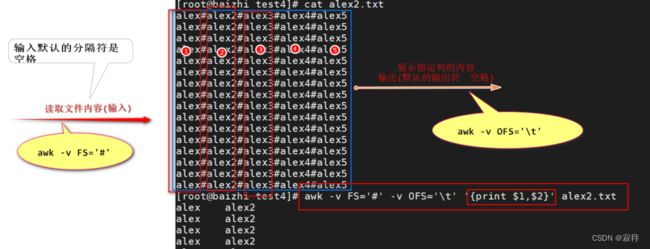
[root@bai test4]# cat alex2.txt
alex#alex2#alex3#alex4#alex5
alex#alex2#alex3#alex4#alex5
alex#alex2#alex3#alex4#alex5
alex#alex2#alex3#alex4#alex5
# 获取 第1列
[root@bai test4]# awk -F '#' '{print $1}' alex2.txt
[root@bai test4]# awk -v FS='#' '{print $1}' alex2.txt
#
[root@bai test4]# awk -v FS='#' -v OFS='\t\t' '{print $1,$2}' alex2.txt
#
[root@bai test4]# awk -v FS='#' -v OFS='-----' '{print $1,$2}' alex2.txt
awk与正则表达式
正则表达式主要与 awk结合使用
|- 不指定模式 awk每一行都会执行动作
|- 指定模式 只有被模式匹配的,符合条件的行才会执行动作
# 获取 pwd.txt中以 root 开头的行
[root@bai test4]# grep '^root' pwd.txt
[root@bai test4]# awk '/^root/{print $0}' pwd.txt
root:x:0:0:root:/root:/bin/bash
注意
awk [可选参数] [-v 内置变量赋值] '/匹配模式/{动作}'
案例:
# 找出所有被禁止登录系统的用户 /sbin/nologin
[root@bai test4]# grep '/sbin/nologin$' pwd.txt
[root@bai test4]# awk '/\/sbin\/nologin$/{print $0}' pwd.txt
# 格式化展示禁止登录系统的用户 [用户名 属组 登录状态]
[root@bai test4]# awk -v FS=':' -v OFS='\t' '/\/sbin\/nologin$/ {print "用户名:",$1,"属组id:",$4,"登录方式:",$NF}' pwd.txt
##文件内容来自授课老师百知昌哥(笔记需要pdf版本的可以私聊小编)