性能测试学习笔记
性能测试学习笔记
测试基础
性能测试并不是并发越大,响应时间越快,那性能一定就越好。
性能测试需要依赖服务器硬件,所以要分析性能,需掌握服务器知识
作为性能测试工程师来说,我们需要对系统行为做分析:系统调用是如何执行的,CPU是如何调度线程,有限大小的内存是如何影响性能的,或者是文件系统是如何处理IO的,这些都是我们判断系统瓶颈的依据和线索。
性能测试流程

不同角色看性能
黑盒测试的角度
黑盒测试只关注应用的单步响应时间
开发角度
(1)架构合理性
(2)数据库设计合理性
(3)代码
(4)系统里的内存的使用方式
(5)系统里线程使用方式
(6)系统是否有恶性,不合理竞争
管理员角度
(1)硬件资源利用率
(2)JVM
(3)DB
(4)还有哪些硬件能提高系统性能
(5)系统能否支持7*24的服务
(6)扩展性,兼容性,最大容量,可能的瓶颈
性能测试的角度
(1)服务器的硬件性能
(2)根据需求和历史数据制定性能目标
(3)建立性能通过模型
(4)对开发代码框架和硬件框架进行性能分析
(5)针对开发发布版本的基准测试
(6)执行软件性能验收及稳定性测试
(7)生产环境的配置和优化
(8)制定性能测试的测试用例
(9)制定性能测试的场景设计
(10)协调各部门配合
(11)特定的性能分析
性能测试相关术语
(1)负载:模拟业务操作对服务器造成压力的过程
(2)性能测试:模拟用户负载来测试系统在负载情况下,系统的响应时间吞吐量等指标是否满足需求
(3)配置测试:通过合理调配资源,用测试的手段测试在不同配置下系统的性能,从而为设备选择,设备配置提供参考
(4)负载测试:在一定软硬件的环境下,通过不断加大负载来确定在满足性能指标情况下能够承受用户的最大数量
(5)压力/强度测试:在一定软硬件环境下,通过高负载的手段来使服务器资源处于极限状态,测试系统在极限状态下长时间运行是否稳定,确定稳定的指示包括TPS,RT。CPU Using,Mem Using等
(6)稳定性测试:在一定软硬件环境下,长时间运行一定负载,确定系统在满足性能指标的情况下是否能稳定运行(满足性能要求1.5到2倍负载量进行测试)
(7)TPS:每秒成功的事务数
(8)RT/ART:响应时间/平均响应时间(一个事务完成需要的时间)
(9)PV:每秒用户访问页面的次数
(10)Vuser:虚拟用户
(11)Concurrency并发:狭义并发:多个用户同时进行同一操作,广义并发:多个用户,不同时间进行不同操作。
(12)场景:模拟真实用户访问的业务处理过程
(13)思考时间:模拟用户在实际操作中的停顿操作
(14)标准差:标准差越小系统越稳定,如响应时间标准差等。
性能测试通过标准
业内对于性能测试有一些通用的通过标准,这里给出一个Web项目性能测试通过标准,作为样板

基本都遵循2/5/10,2s以内最佳
- 在2秒之内给客户响应被用户认为是“非常有吸引力”的用户体验。
- 在5秒之内响应客户被认为“比较不错”的用户体验
- 在10秒内给用户响应被认为“糟糕”的用户体验
- 如果超过10秒还没有得到响应,那么大多用户会认为这次请求是失败的
说明:
上图的样本只是通用标准,可作为参考,对于一些特殊的项目或者场景,则不适用。如秒杀活动或者某猫双十一活动,上述响应时间、超时概率等相关指标均可适当放宽。
另外需要强调的是,每个项目对于是否通过的标准不尽相同,实际执行中,优先以项目需求中给出的要求为准,如果没有给出明确通过标准,再参考选取业内的一些通用标准或者和公司相关参与者沟通确定,这个标准必须在需求分析和方案评审时敲定下来。
具体问题具体分析,性能测试通过标准亦是如此。
性能测试工具(JMter)
JMter体系结构
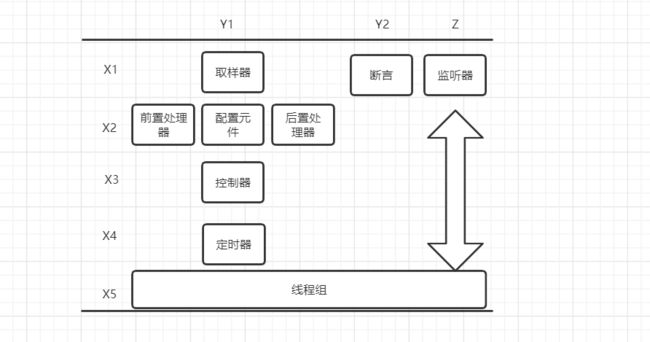
X1-X5是负载模拟的一个过程,使用这些组件来完成负载的模拟
Y1:包含的是负载模拟部分,负载模拟用户请求
Y2:结果验证部分,负责验证结果正确性
Z:负载结果的收集。监听器不仅可以放在线程组之内,也可以放在线程组之外
1、X1 取样器
概念:取样器(采样器)用来模拟用户操作,向服务器发出http请求,webservice请求或者java请求等。(脚本,主要进行脚本的控制)
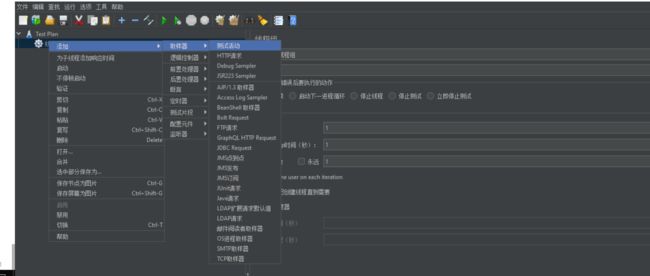
2、X1 断言
概念:断言用来验证结果是否正确。loadrunner中称之为检查点
访问路径:测试计划→断言
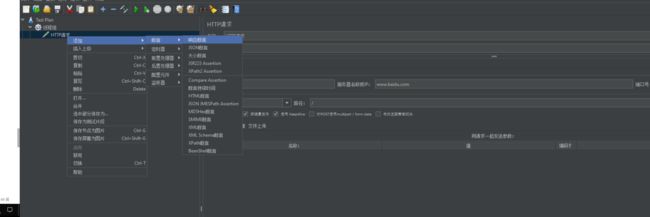
3、X1监听器
概念:测试结果需要添加监听器来收集
监听器有两个任务:
(1)添加结果监听,并且可以保存测试结果到文件,这些结果数据可以供再次分析使用
(2)展示结果,以表格及图形的形式展现结果,方便测试人员分析测试结果。
访问路径:测试计划→监听器
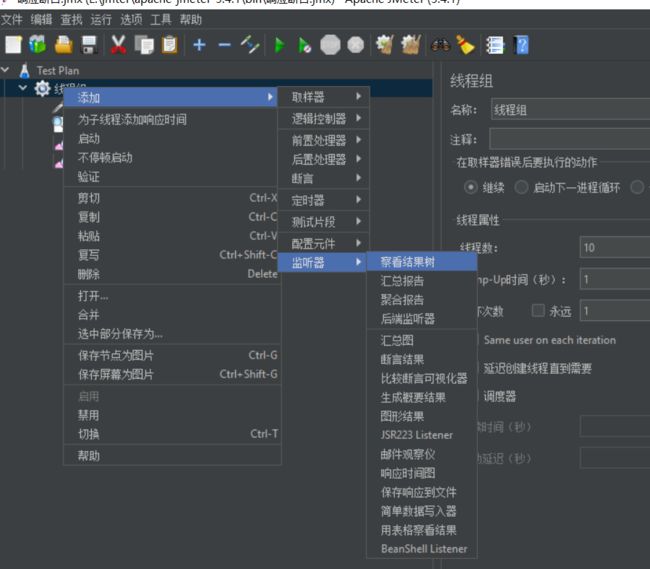
注意:“查看结果树”一般只在调试中使用,正式测试需要去掉(因为耗IO),改为使用聚合报告
4、X2 前置处理器
概念:测试脚本开发过程中,我们在请求发送前可能会做一些环境或者参数的准备工作
访问路径:测试计划→前置处理器

5、X2 配置元件
概念:性能测试中为了模拟大量用户操作我们往往需要做参数化,jmeter的参数化可以通过配置元件来完成,比如CSV/DATA/SET/CONFIG,它可以帮助我们从文件中读取测试数据。
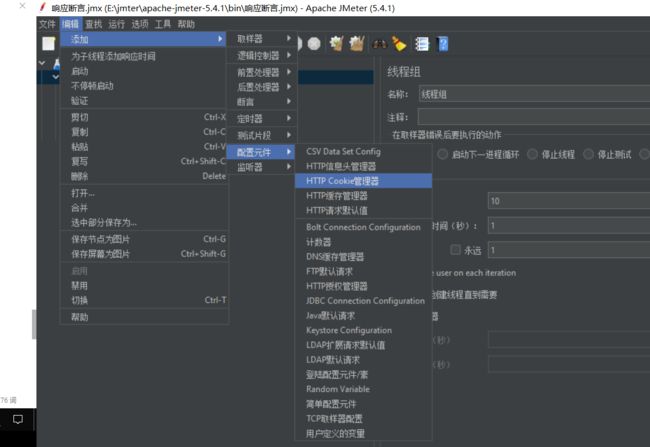
访问路径:测试计划→配置元件
6、X2 后置处理器
概念:后置处理器一般放在取样器之后,用来处理服务器的返回结果。比如web应用服务的SessionID
后置处理器就是专门用来对相应数据做处理的元件,JMeter的关联就是通过后置处理器来完成的。
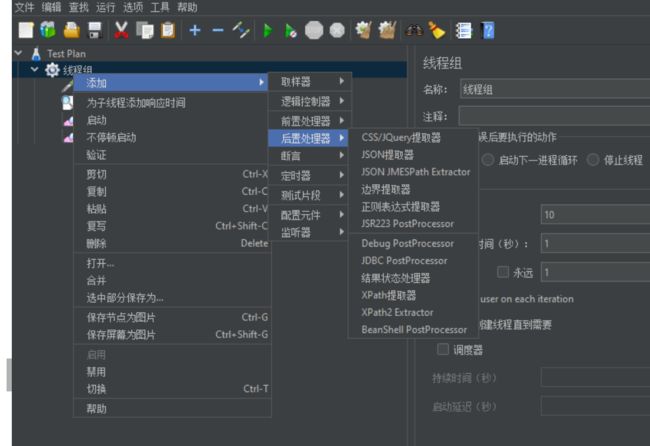
访问路径:测试计划→后置处理器
7、X3 逻辑控制器
概念:控制器用来完成我们的各种需求
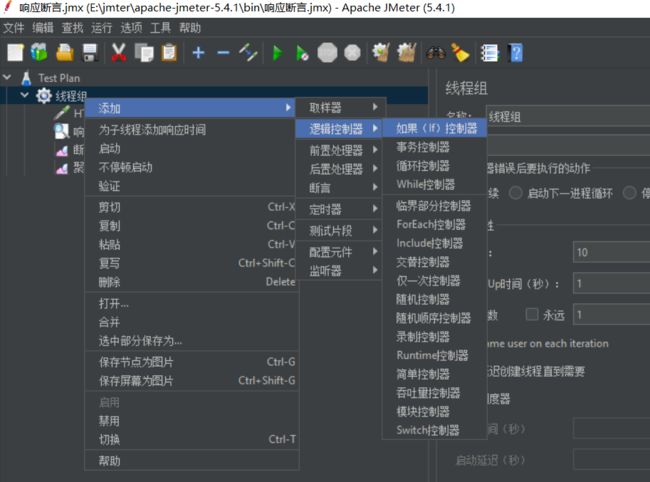
访问路径:测试计划→线程组→逻辑控制器
8、X4 定时器
概念:为了足够真实的模拟用户负载,我们会需要模拟这些请求在同一时刻发送。定时器还有很多其他不同的功能
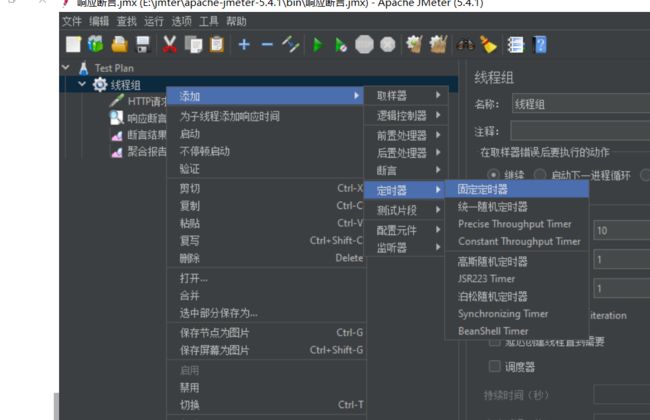
访问路径:测试计划→线程组→定时器
9、X5 线程组
概念:性能测试需要模拟大量用户负载的情况,线程组就是用来完成这个工作的,在此元件中我们可以设置运行的线程数(就是模拟多少用户、一线程一用户),还可以设置运行时长、定时运行等。另外第三方插件(JMeter Plugin)的扩展也让JMeter的场景设计更加丰富(场景设置)
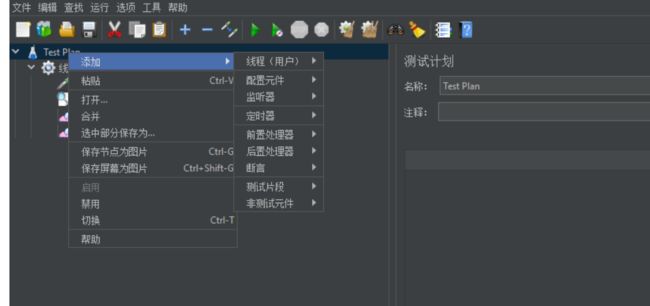
访问路径:测试计划→Threads(users)
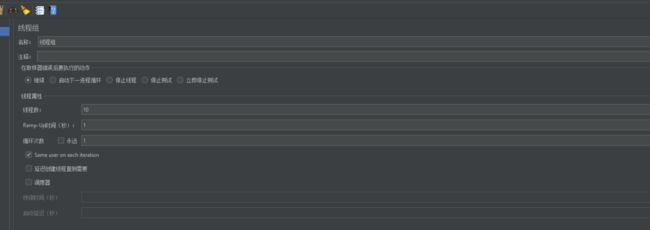
线程数:一共多少用户,对我们被测系统进行访问
Ramp-Up Period(in seconds):加压策略, 表示每个用户启动的延迟时间,上述我设为1秒,表示系统将在1秒结束前启动我设置的1000个用户,如果设置为1000秒,那么系统将会在1000秒结束前启动这1000个用户,开始用户的延迟为1秒, 如果我设置为0秒,则表示立即启动所有用户。
循环次数:如果你要限定循环次数为10次的话,可以取消永远的那个勾,然后在后面的文本框里面填写10;在这里我们勾上永远,表示如果不停止或者限定时间将会一直执行下去, 是为了方便调度器的调用。
调度器
持续时间:表示脚本持续运行的时间,以秒为单位,比如如果你要让用户持续不断登录1个小时,你可以在文本框中填写3600。如果在1小时以内,结束时间已经到达,它将会覆盖结束时间,继续执行。
启动延迟:表示脚本延迟启动的时间,在点击启动后,如果启动时间已经到达,但是还没有到启动延迟的时间,那么,启动延迟将会覆盖启动时间,等到启动延迟的时间到达后,再运行系统。
启动时间:表示我们脚本开始启动的时间,当你不想立即启动脚本测试,但是启动脚本的时间不会再电脑旁的时候,你可以设定一个启动的时间,然后再运行那里点击启动,系统将不会立即运行,而是会等到你填写的时间才开始运行。
结束时间:与启动时间对应,表示脚本结束运行的时间。
注意:如果我们需要用到调度器来设定持续时间,如果线程数不够多到持续时间结束,我们就必须将循环次数勾选为永远,特别地,如果线程组里面有其他的循环,我们也需将该循环次数勾选为永远(如我上面录制的脚本中的Step1也是一个循环,需要将永远勾选),否则,按我如上配置,将永远去掉勾选,文本里填1,那么无论你将持续时间启动时间结束时间等设置多少,系统运行1000次后,将会停止不再运行。
10、Test Fragment
概念:它是一个辅助的组件,在此节点下几乎可以放置任何JMeter测试组件,但它一般不会被运行。他的作用如下
(1)在脚本开发过程中可以用来备份元件
(2)TestFragment下的元件可以被模块控制器调用,我们可以利用它来模块化请求(把一个业务封装成一个方法供复用)供模块控制器调用
访问路径:测试计划→Test Fragment
11、工作台
概念:它也不能直接参与运行,他的功能有:
(1)在运用JMeter录制http协议脚本时就用到他,我们可以在它下面建立一个http代理服务器原件,设置代理信息然后进行录制
访问路径:工作台→添加→非测试元件
(2)设置服务器监控(HTTP Mirror Server)
(3)显示当前JMeter属性信息
(4)备份脚本,特别是我们在脚本调试过程中可以把它作为一个元件暂存区
JMter 测试计划要素
(1)要素一:脚本中测试计划只有一个
(2)要素二:测试计划中至少有一个线程组
(3)要素三:至少有一个取样器
(4)要素四:至少有一个监听器
JMter 环境介绍
(1)Jmter是由Java开发,所以需要有JDK环境,建议jdk1.8
(2)Jmter安装官网 https://jmeter.apache.org/ 下载解压 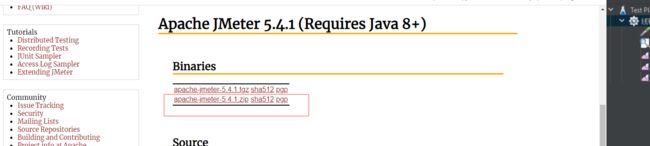
解压后 点击 apache-jmeter-5.4.1\bin目录下的Jmter.bat 启动Jmter
本章小结
jmter的运行逻辑如下
(1)运用取样器模拟用户请求,如果需要有数据和环境准备就用配置管理器,如果需要对响应数据进行处理就用后置处理器
(2)使用线程组来设置运行场景,利用逻辑控制器来控制业务
(3)利用断言和监视器来收集结果
(4)JMter支持远程运行,弥补单台负载不足的情况。
JMter Http 协议录制
使用BlazeMeter录制脚本
(1) 在谷歌浏览器上安装BlazeMeter插件
进入该网址搜索插件 https://huajiakeji.com/
下载成功后 得到如下所示的文件
![]()
这里我把格式改成了zip格式 然后解压
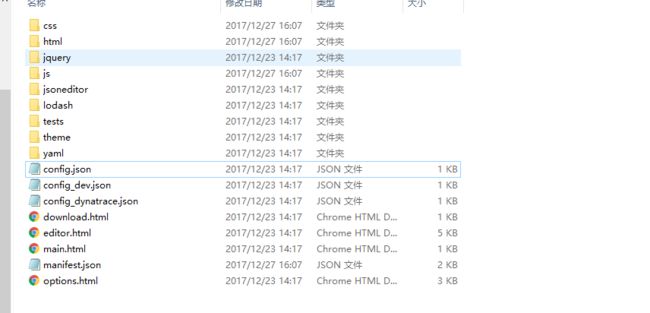
解压完成后来到 谷歌浏览器的扩展程序 选择开发者模式
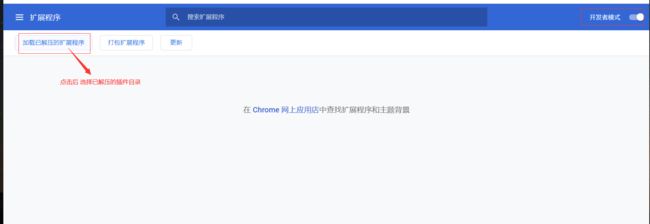
安装成功
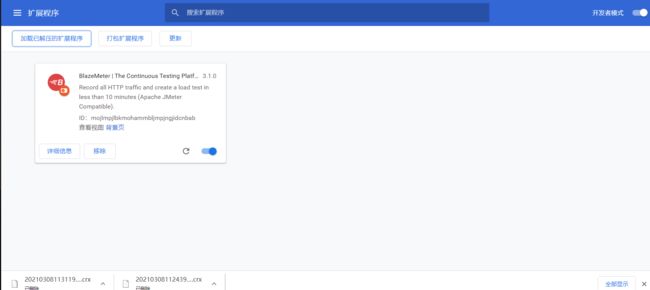
暂缓(因为谷歌登陆不上)
JMter 实战
简单接口性能测试
用springboot写一个简单的Java接口项目
package com.example.hello;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @ClassName Hello
* @Deacription TODO
* @Author zhihaop
* @Date 2021/3/9 13:47
**/
@RestController
@RequestMapping("/h")
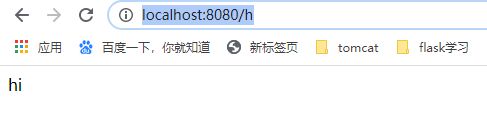
public class Hello {
@GetMapping
public String helloWorld(){
return "hi";
}
}
启动成功
下面我们来针对这个接口做一个简单的性能测试
(1)在测试计划里新建一个线程组并修改线程名
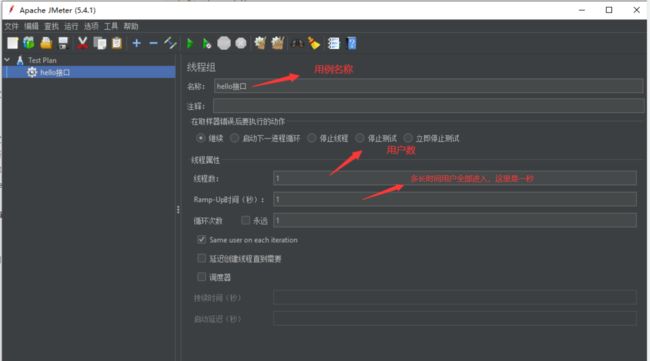
Ramp-up Period(in seconds)
决定多长时间启动所有线程。如果使用10个线程,ramp-up period是100秒,那么JMeter用100秒使所有10个线程启动并运行。每个线程会在上一个线程启动后10秒(100/10)启动。Ramp-up需要要充足长以避免在启动测试时有一个太大的工作负载,并且要充足小以至于最后一个线程在第一个完成前启动。 一般设置ramp-up=线程数启动,并上下调整到所需的。
用于告知JMeter 要在多长时间内建立全部的线程。默认值是1。如果未指定ramp-up period ,也就是说ramp-up period 为零, JMeter 将立即建立所有线程。假设ramp-up period 设置成T 秒, 全部线程数设置成N个, JMeter 将每隔T/N秒建立一个线程。
Ramp-Up Period(in-seconds)代表隔多长时间执行,0代表同时并发
(2)添加一个http请求的取样器
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U73UTpK6-1616135018132)(C:\Users\zhihaop\AppData\Roaming\Typora\typora-user-images\image-20210309141428518.png)]
(3)添加一个响应断言 断言响应码为200
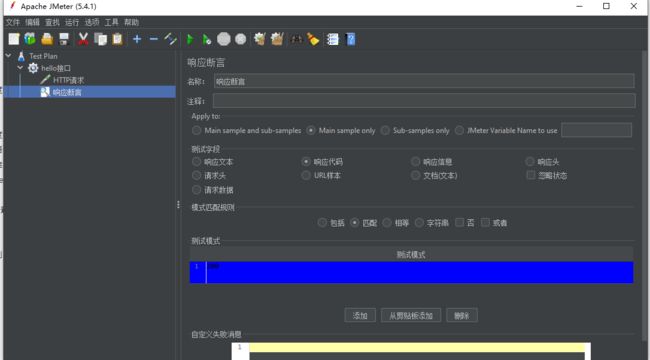
(4)添加两个监听器 查看结果树和聚合报告 获取http请求响应内容和相应的性能数据报告
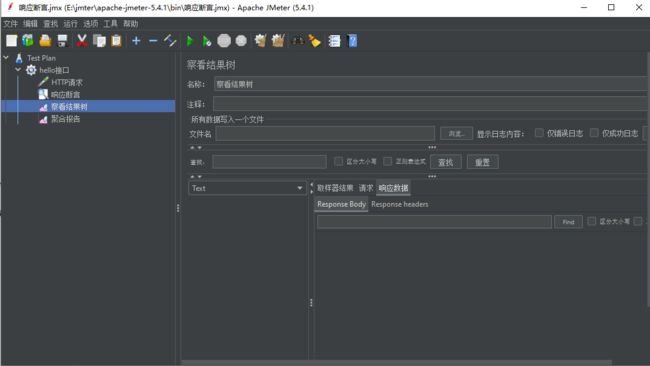
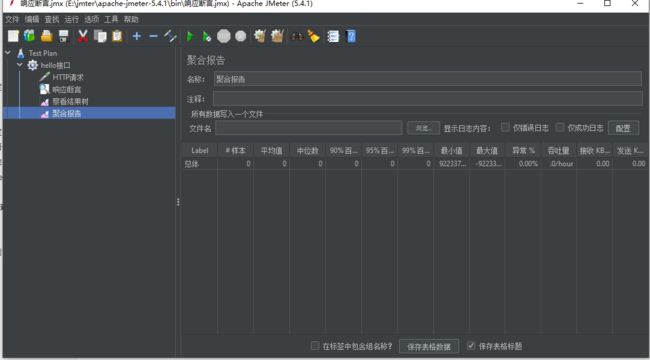
然后 修改用户个数为100 点击运行 查看结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VFfRlecW-1616135018145)(C:\Users\zhihaop\AppData\Roaming\Typora\typora-user-images\image-20210309142218960.png)]
得到如图所示的聚合报告
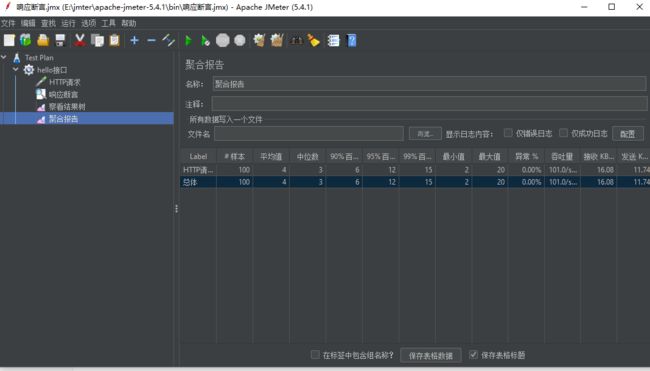
性能监控诊断
操作系统性能分析介绍
应用程序在运行的时候,操作系统会根据用户的需求来进行分配和调度,需要把内存,CPU,网络,磁盘等资源分配给对应的应用程序以便他顺利执行,以及在程序执行结束后回收他的资源以便再利用,但操作系统所能够提供的资源是一定的,从性能测试的角度而言,我们需要监控分析系统各类资源的使用情况,使系统所有的资源得到最大程度的发挥,以低廉的成本达到各应用的最佳性能,实现资源最大利用。
对于用户而言,他们最直观的感受是程序或网站的响应时间
用户响应时间 = 网络时间+服务器响应时间
网络时间可能受到网络延时和拥堵等因素影响,除此之外 ,系统的可靠性,稳定性也是我们需要考虑的,当系统出现问题的时候,我们需要从应用程序,操作系统,服务器设备,网络环节,系统资源等多方面综合排查,定位分析问题然后集中解决问题。
系统性能分析思路
系统性能分析因素-CPU
(1)我们需要了解系统处理器的情况,如逻辑处理器,处理器型号,主频率,cache 大小,是否支持超线程。
(2)关注CPU的使用率(一般期望cpu的闲置率不少于20%)
查看cpu使用率
[root@sss ~]# top
top - 16:54:38 up 7 days, 5:13, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 77 total, 2 running, 75 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.3 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1882232 total, 813020 free, 330164 used, 739048 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1386608 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
17215 root 0 -20 127504 12176 9560 S 0.7 0.6 21:46.45 AliYunDun
2770 root 20 0 573932 17232 6088 S 0.3 0.9 1:11.38 tuned
1 root 20 0 43548 3844 2588 S 0.0 0.2 0:06.54 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:08.75 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
... ...
%us:表示用户空间程序的cpu使用率(没有通过nice调度)
%sy:表示系统空间的cpu使用率,主要是内核程序。
%ni:表示用户空间且通过nice调度过的程序的cpu使用率。
%id:空闲cpu
%wa:cpu运行时在等待io的时间
%hi:cpu处理硬中断的数量
%si:cpu处理软中断的数量
%st:被虚拟机偷走的cpu
注:99.0 id,表示空闲CPU,即CPU未使用率,100%-99.0%=1%,即系统的cpu使用率为1%。
系统性能分析因素-内存
(1)当可用内存过小,系统进程会被阻塞,应用将会变得非常缓慢,有时会失去响应,严重会触发内存溢出从而引起应用程序直接被系统杀死,更严重会引起系统重启。当内存过大也是一种浪费。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7Ns1geAI-1616135018152)(C:\Users\zhihaop\AppData\Roaming\Typora\typora-user-images\image-20210310144803995.png)]
内存使用率=330164 used/1882232 total
(2)虚拟内存也是在内存里需要考虑的性能指标,当物理内存不够时,会释放一部分很长时间没有什么操作的程序空间,这些空间被临时保存在虚拟内存中,然后释放出来的物理内存会给需要的程序使用,这样系统总是在内存不够时,才进行内存的交换,有时可以越过性能瓶颈,节省系统升级的费用。
虚拟内存 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l1VVtYE3-1616135018154)(C:\Users\zhihaop\AppData\Roaming\Typora\typora-user-images\image-20210310144848036.png)]
系统性能分析因素-网络
在系统中,要考虑网络是否可达,防火墙是否开启,端口的访问,带宽是否有被限制,路由的寻址,网络的时延等问题。
系统性能分析因素-I/O
I/O读写的性能直接影响系统程序的性能,I/O时系统中最慢的部分,针对I/O的场景模型,需要考虑的有IO的TPS,平均I/O数据,平均队列长度,平均服务时间,IO利用率等指标。
系统性能因素-总结
(1)大量的网络吞吐量会导致占用CPU的资源
(2)大量的CPU开销会尝试更多内存的使用
(3)其他因数互相影响,如内存使用过多会导致大量内存被置换到虚拟内存,导致CPU和I/O的瓶颈。
CPU定位分析
[zhihaopcq@localhost ~]$ vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 11784 71084 36 302764 0 3 252 12 79 171 1 1 97 0 0
CPU 使用率= 1-id%
[zhihaopcq@localhost ~]$ sar -u
Linux 3.10.0-957.el7.x86_64 (localhost.localdomain) 2021年03月10日 _x86_64_ (1 CPU)
14时19分32秒 LINUX RESTART
14时20分01秒 CPU %user %nice %system %iowait %steal %idle
14时30分01秒 all 3.16 0.16 2.13 0.20 0.00 94.34
14时40分02秒 all 0.58 0.00 0.45 0.01 0.00 98.96
14时50分01秒 all 0.28 0.00 0.42 0.01 0.00 99.30
15时00分01秒 all 0.27 0.00 0.41 0.00 0.00 99.32
15时10分01秒 all 0.27 0.00 0.41 0.01 0.00 99.32
15时20分02秒 all 0.25 0.00 0.37 0.00 0.00 99.37
平均时间: all 0.80 0.03 0.70 0.04 0.00 98.43
CPU 使用率= 1-%idle
[zhihaopcq@localhost ~]$ mpstat -P ALL
Linux 3.10.0-957.el7.x86_64 (localhost.localdomain) 2021年03月10日 _x86_64_ (1 CPU)
15时31分02秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
15时31分02秒 all 1.17 0.02 1.22 0.05 0.00 0.02 0.00 0.00 0.00 97.52
15时31分02秒 0 1.17 0.02 1.22 0.05 0.00 0.02 0.00 0.00 0.00 97.52
CPU 使用率= 1-%idle
| 模块 | 类型 | 度量方法 | 衡量标准 |
|---|---|---|---|
| CPU | 使用情况 | mpstat -P ALL ,vmstat,sar -u | 注意>=50%,告警>=70%,严重>=90% |
内存定位分析
| 模块 | 类型 | 度量方法 | 衡量标准 |
|---|---|---|---|
| 内存 | 使用情况 | free,vmstat,sar -r,ps | 注意>=50%,告警>=70%,严重>=80% |
[zhihaopcq@localhost ~]$ free
total used free shared buff/cache available
Mem: 995896 658820 75136 24648 261940 94972
Swap: 2097148 18952 2078196
[zhihaopcq@localhost ~]$ vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 18952 77296 36 262660 0 3 159 10 74 150 1 1 98 0 0
网络定位分析
在性能测试中为了减少网络对性能测试的影响,一般在局域网下进行测试
| 模块 | 类型 | 度量方法 | 衡量标准 |
|---|---|---|---|
| 网络 | 使用情况 | 1.sar -n DEV 的收发计数大于网卡上限 2.ifconfig RX/TX 带宽超过网卡上限 3.cat/pro/net/dev 的速率超过上限 4.nicstat的util基本满负荷 | 1.收发包的吞吐率达到网卡上限2.有延迟3.有丢包4.有阻塞 |
IO定位分析
| 模块 | 类型 | 度量方法 | 衡量标准 |
|---|---|---|---|
| IO | 使用情况 | 1.iostat -xz,"%util"2.sar -d,"%util"3.iotop 的利用率很高 4.cat/proc/pid/sched|grep iowait | 注意>=40%,告警>=60%,严重>=80% |
Linux系统负载分析实践
系统的负载多少决定了系统是否忙碌
uptime 命令可以帮助我们查看系统的负载和获取主机运行时间
[root@iZwz9bdvacsset2y3am4cwZ /]# uptime
10:13:58 up 13:37, 1 user, load average: 0.00, 0.01, 0.05
# 10:13:58 : 系统当前时间
# up 13:37 :系统运行时间 (越长系统越稳定)
# 1 user :系统在线用户数
# load average: 0.00, 0.01, 0.05
过去1,5,15分钟的平均负载(当前时间间隔内运行队列中的平均进程数,每个cpu这个值最好不大于0.8,大于1且不大于3的时候,系统其他资源都正常,那么性能时可以接受的,大于5系统性能就有问题了)
w 命令还可以显示当前登陆用户的信息
[root@iZwz9bdvacsset2y3am4cwZ /]# w
10:26:36 up 13:50, 1 user, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 117.107.131.195 10:03 4.00s 0.01s 0.00s w
[root@iZwz9bdvacsset2y3am4cwZ ~]# uptime |awk '{print $(NF-1)}'
0.01,
过去5分钟的平均负载
Linux系统监控分析实践
top 是linux中使用最频繁,也是比较全的命令
默认top只显示平均的cpu使用情况,按下1可以显示所有的cpu使用情况
[root@sss ~]# top
top - 16:54:38 up 7 days, 5:13, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 77 total, 2 running, 75 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.3 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1882232 total, 813020 free, 330164 used, 739048 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1386608 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
17215 root 0 -20 127504 12176 9560 S 0.7 0.6 21:46.45 AliYunDun
2770 root 20 0 573932 17232 6088 S 0.3 0.9 1:11.38 tuned
1 root 20 0 43548 3844 2588 S 0.0 0.2 0:06.54 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:08.75 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
... ...
%us:表示用户空间程序的cpu使用率(没有通过nice调度)
%sy:表示系统空间的cpu使用率,主要是内核程序。
%ni:表示用户空间且通过nice调度过的程序的cpu使用率。
%id:空闲cpu
%wa:cpu运行时在等待io的时间
%hi:cpu处理硬中断的数量
%si:cpu处理软中断的数量
%st:被虚拟机偷走的cpu
注:99.0 id,表示空闲CPU,即CPU未使用率,100%-99.0%=1%,即系统的cpu使用率为1%。
Tasks: 77 total, 2 running, 75 sleeping, 0 stopped, 0 zombie
显示进程信息:总的77个 2个运行态 75 个睡眠态 0个停止态 0个僵尸态
wa:使用过高要考虑IO的性能是否有瓶颈
Mem:1882232 total :物理内总量
813020 free :空闲内存总量
330164 used :使用的物理内存总量
739048 buff/cache 用作内核缓存的内存量和缓冲的交换区总量
Swap: 0 total :使用的交换区总量
0 free :空闲的交换区总量
0 used :使用的交换区总量
buff/cache 的作用是缩短I/O系统调用的时间,如读写等。
当系统需要使用时,buff/cache的内存可以立即释放,所以 buff/cache可以看成可用内存。
top间隔刷新
操作方法:输入top命令后,按下d进入间隔刷新配置,输入间隔秒数即可
[root@iZwz9bdvacsset2y3am4cwZ ~]# clear
[root@iZwz9bdvacsset2y3am4cwZ ~]# top
top - 13:16:37 up 16:40, 2 users, load average: 0.00, 0.02, 0.05
Tasks: 72 total, 1 running, 71 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.4 us, 0.0 sy, 0.0 ni, 99.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1798688 total, 1360272 free, 154844 used, 283572 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1499800 avail Mem
Change delay from 5.0 to 1
添加进程字段显示列
操作方法:输入top命令后,按下f,此时再按下A就不会显示pid列,输入d就会新增显示UID列
监控脚本
#!/bin/bash
#!/bin/bash
Basic_Top_Cmd() {
delay_time=$1
# & 放在启动参数后面表示设置此进程为后台进程,也即非阻塞性运行,如果不加&,则会执行完该命令后才能执行后面的命令。
top -b -d $delay_time &
}
Check_Status() {
#status_file=$1
while true; do
status_info=`cat $status_file`;
if [ $status_info != "stop" ]; then
sleep $delay_time;
else
kill -9 `cat top.pid | grep pid |awk '{print $2}'`
break;
fi
done
}
Start_Monitor() {
delay_time=$1
result_file=$2
status_file=$3
Basic_Top_Cmd $delay_time >> $result_file 2>&1
monitor_pid=$!
echo monitor_pid: $monitor_pid > top.pid
echo start > $status_file
echo status_file: $status_file >> top.pid
Check_Status > /dev/null 2>$1 &
}
Stop_Monitor(){
echo stop > `cat top.pid |grep status_file | awk '{print $2}'`
ps aux | grep top | awk '{print $2}' | xargs Kill -9
}
input_value=$@
case_mode=$1
echo $input_value |awk -F start '{print $2}'
case $case_mode in
start ) Start_Monitor `echo $input_value | awk -F start '{print $2}'`
;;
stop ) Stop_Monitor
esac
执行脚本
sh xxx.sh start 5 /root/cpu_result /root/status_file
执行此脚本会有格式问题,输入下面命令可以解决
sed -i 's/\r//g' xxx.sh
查看cpu使用情况脚本
#!/bin/bash
result_file=/root/cpu_result
filter_string="print NR,\$8,\$2,\$4,\$12,\$14"
grep Cpu $result_file | awk "{$filter_string}" >cpu.raw_data
[root@iZwz9bdvacsset2y3am4cwZ ~]# cat cpu.raw_data
1 87.5 6.2 6.2 0.0 0.0
2 99.2 0.6 0.2 0.0 0.0
3 99.2 0.4 0.4 0.0 0.0
4 99.0 0.6 0.4 0.0 0.0
5 99.0 0.6 0.4 0.0 0.0
6 99.4 0.4 0.2 0.0 0.0
7 99.0 0.4 0.4 0.0 0.0
8 99.6 0.2 0.2 0.0 0.0
9 99.2 0.4 0.4 0.0 0.0
10 93.8 0.0 6.2 0.0 0.0
11 99.0 0.6 0.2 0.0 0.0
12 99.6 0.2 0.2 0.0 0.0
13 99.2 0.4 0.4 0.0 0.0
14 99.4 0.4 0.2 0.0 0.0
15 99.2 0.4 0.4 0.0 0.0
16 99.2 0.6 0.2 0.0 0.0
17 99.2 0.4 0.4 0.0 0.0
第一列代表统计次数 第二列代表空闲cpu占比 第三列代表用户空间cpu占比 第四列代表内核cpu空间使用率 第五列代表硬件中断的cpu利用率 第六列代表软件中断的cpu利用率。
用情况脚本
#!/bin/bash
result_file=/root/cpu_result
filter_string="print NR,\$8,\$2,\$4,\$12,\$14"
grep Cpu $result_file | awk "{$filter_string}" >cpu.raw_data
[root@iZwz9bdvacsset2y3am4cwZ ~]# cat cpu.raw_data
1 87.5 6.2 6.2 0.0 0.0
2 99.2 0.6 0.2 0.0 0.0
3 99.2 0.4 0.4 0.0 0.0
4 99.0 0.6 0.4 0.0 0.0
5 99.0 0.6 0.4 0.0 0.0
6 99.4 0.4 0.2 0.0 0.0
7 99.0 0.4 0.4 0.0 0.0
8 99.6 0.2 0.2 0.0 0.0
9 99.2 0.4 0.4 0.0 0.0
10 93.8 0.0 6.2 0.0 0.0
11 99.0 0.6 0.2 0.0 0.0
12 99.6 0.2 0.2 0.0 0.0
13 99.2 0.4 0.4 0.0 0.0
14 99.4 0.4 0.2 0.0 0.0
15 99.2 0.4 0.4 0.0 0.0
16 99.2 0.6 0.2 0.0 0.0
17 99.2 0.4 0.4 0.0 0.0
第一列代表统计次数 第二列代表空闲cpu占比 第三列代表用户空间cpu占比 第四列代表内核cpu空间使用率 第五列代表硬件中断的cpu利用率 第六列代表软件中断的cpu利用率。