论文阅读——Blind Super-Resolution Kernel Estimation using an Internal-GAN
## Absract:
超分(SR)方法通常是假设低分辨率图像(LR)是通过固定的、理想的下采样核对未知高分辨率图像(HR)中下采样得到的(如:Bicubic downscaling)。然而,与合成的超分数据集相比,真实LR图像的退化核是未知的。当假设的下采样核偏离真实核时,SR方法的性能会显著下降。这进一步说明,真正的SR核是在LR图像patch上递归最大化的核,可以理解为多种退化核的组合。作者论文中说明了如何使用深度内部学习实现这种强大的跨尺度递归性。作者引入了“KernelGAN”,一个特定于图像的 Internal-GAN,它在测试时仅对LR测试图像进行训练,并学习其内部patch的分布。它的生成器生成一个下采样版的LR测试图像,这样它的判别器就不能区分下采样版图像的patch分布和原始LR图像的patch分布。生成器经过训练后,使用正确特定于图像的SR内核进行下采样操作。KernelGAN是完全无监督的,除了输入图像本身之外,不需要任何训练数据,并且当插入现有的SR算法时,可以在盲SR中获得最先进的结果。
## Introduction:
超分基本模型假设:
 公式(1)
公式(1)
LR是使用一些核Ks(SR核)通过缩放因子s对高分辨率图像HR下采样得到的。
真实LR图像的SR核受到传感器光学和手持相机微小相机运动的影响,即使由相同的传感器拍摄,每张LR图像也会产生不同的非理想SR核。
“KernelGAN”一种特定于图像的 Internal-GAN,它估计了能最好地保留LR图像各尺度patchs分布的SR核。KernelGAN的生成器被训练成生成一个缩小版的LR测试图像,这样判别器就无法区分缩小版图像的patch分布和原始LR图像的patch分布。换句话说,G训练欺骗D,让D相信缩小图像的所有patch实际上都来自原始图像。生成器经过训练后,使用正确特定于图像的SR核进行缩小操作。
本文创新点:
1)最先用估计未知SR核的数据集不变深度学习方法(从真实LR图像获取真实SR的关键步骤)。KernelGAN是完全无监督的,除了输入图像本身之外,不需要任何训练数据。
2)当插入到现有的SR算法中时,KernelGAN导致了最先进的盲SR结果。
3)据作者所知,是深度线性网络(目前主要用于理论分析)的首次实际应用,具有实际优势。
##Overview of the Approach:
给定输入图像,需要找到其底层特定于图像的SR内核。寻找最能保留LR图像各尺度patch分布的核。更具体地说是“生成”一个缩小的图像(例如2倍),使其补丁分布尽可能接近LR图像。
GAN通常学习大型图像数据集中图像的分布。因此作者用GAN学习patch中的分布。internal GAN在单个输入图像上进行训练,并学习其独特的内部patch分布。KernelGAN受到InGAN的启发,也是一种特定于图像的GAN,在单个输入图像上进行训练。它由降尺度发生器(G)和鉴别器(D)组成。G和D是全卷积的,这意味着网络应用于patch而不是整个图像。给定一个输入图像LR, G将其降尺度。在patch级别上,对D来说是很难区分它是patch还是输入图像LR。
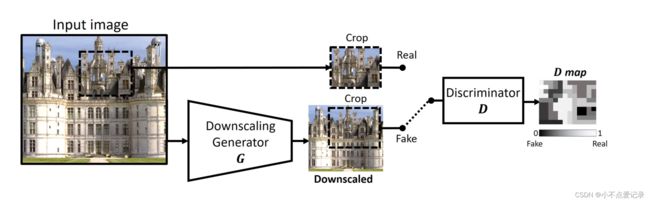 图1. 网络结构
图1. 网络结构
D训练输出一个热图,称为D-map(见图1),表示对于每个像素,其周围的patch从原始patch分布中绘制出来的可能性有多大。它交替训练真实图(输入图像的裁剪)和虚假图(G的输出)。损失是输出D-map和标签图之间的像素级MSE差。训练D的标签是从原始LR图像中提取裁剪图的全1映射,和从降尺度图像中提取裁剪图的全0映射。
KernelGAN的目标定义为:
一旦收敛,生成器G *就隐式地构成了特定LR图像的理想SR降尺度函数。
## Discriminator:
鉴别器D的目的是了解输入图像LR的patch分布,区分分布属于真实的patch还是G生成的虚假patch。
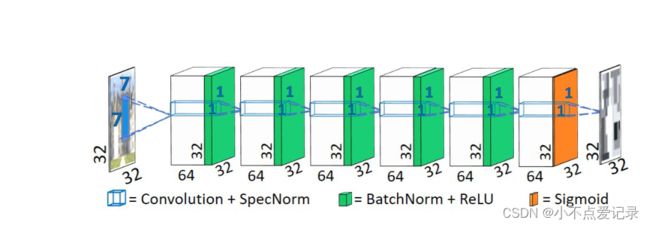 图2. 判别器内部结构
图2. 判别器内部结构
作者使用了全卷积判别器,通过输出一个heat-map(D map)来判别每一块 7x7 图像块的分布。
## Deep Linear Generator:
作者调研发现深度线性网络(由一系列没有激活的线性层组成)与单一线性层(即线性回归)的表达能力完全相同,且优点更多。作者使用了5个隐含卷积层,每个层有64个通道。前3个滤波器是7×7、5×5、3×3,其余的是1×1,整体相当于感受野为 13x13 的卷积核。这种滤波器的设置可以保持相同的感受野,同时在第一层后面设置大于1×1的过滤器,可以使内核中心拥有更高的值。为了提供合理的初始点,第一次迭代,生成器的输出被限制为与输入的理想降尺度相似。一旦满足,这个约束就会被丢弃。
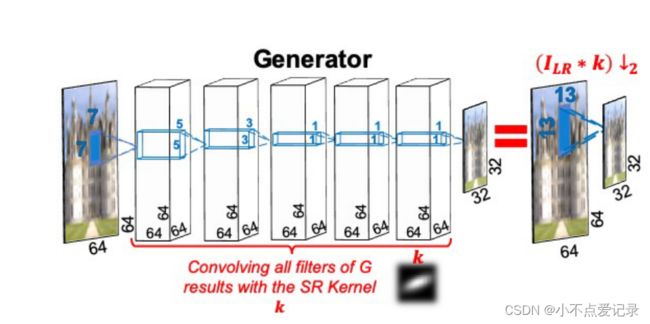 图3 生成器(G网络里的卷积层参数进行矩阵连乘,从而生成一个kernel,使用这个kernel可以对图像进行downsample,从而进行SR)
图3 生成器(G网络里的卷积层参数进行矩阵连乘,从而生成一个kernel,使用这个kernel可以对图像进行downsample,从而进行SR)
Extracting the explicit kernel:
在训练过程中,生成器G对特定LR输入图像的当前估计降尺度操作。图像特定的核是由G的训练权重隐式捕获的。作者从G中显示提取核。原因有二:一是想要获取紧凑的降尺度卷积核,而不是降尺度网络;二是是允许在核上应用显式的和有物理意义的先验。这是等式2中正则化项R的目标,它将假设空间减少到服从某些限制的似是而非的核的子集。这样的限制是,核的总和为1并且居中,所以它不会移动图像。正则化还改善了优化过程中产生过于分散和平滑核的错误倾向。然而,仅仅提取核是不够的,这种提取必须是可微的,这样正则化损耗才能通过它反向传播。在每次迭代中,我们应用可微操作计算核(用stride 1依次卷积G的所有滤波器)。最后将正则化损失项R应用到优化目标中。
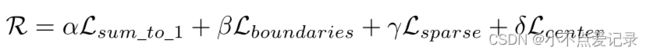 公式(3)
公式(3)

SR核不仅与图像相关,而且依赖于所需的比例因子,但不同尺度的SR核之间存在简单的关系。我们能够从G获得SR ×4的内核,该内核通过×2进行了降尺度训练。