ElasticSearch
文章目录
- 全文检索基础
- 一、什么是全文检索?
-
- 1.全文检索流程
- 2.相关概念
-
- 2.1. 索引库
- 二. ElasticSearch简介
-
- 2.1 什么是ElasticSearch
- 2.2 ElasticSearch的使用案例
- 2.3 ElasticSearch对比Solr
- 三.ElasticSearch相关概念(术语)
-
- 3.1概述
- 3.2 Elasticsearch核心概念
-
- 3.2.1 索引 index
- 3.2.2 类型 type
- 3.2.3 字段Field
- 3.2.4 映射 mapping
- 3.2.5 文档 document
- 3.2.6 接近实时 NRT
- 3.2.7 集群 cluster
- 3.2.8 节点 node
- 3.2.9 分片和复制 shards&replicas
- 四、Elasticsearch 安装
- 五.ElasticSearch的客户端操作
-
- 5.1 elasticsearch-head
全文检索基础
提示:以下是本篇文章正文内容,下面案例可供参考
一、什么是全文检索?
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
1.全文检索流程
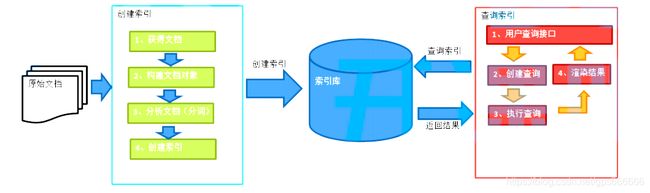
2.相关概念
2.1. 索引库
索引库就是存储索引的保存在磁盘上的一系列的文件。里面存储了建立好的索引信息以及文档对象
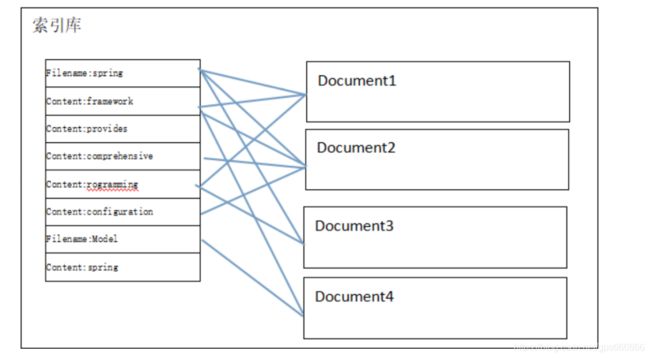
一个索引库相当于数据库中的一张表。
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。每个文档都有一个唯一的编号,就是文档id。
2. document对象
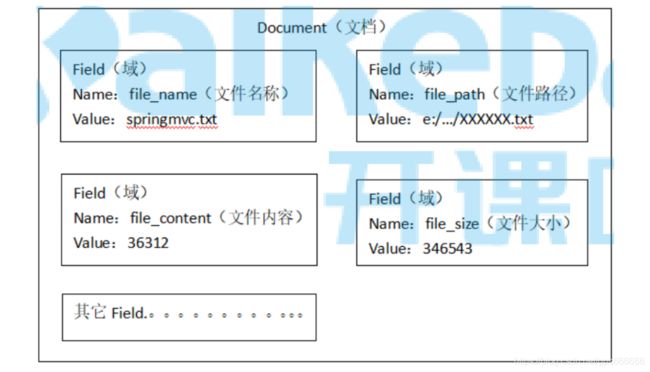
document对象相当于表中的一条记录。
3.field对象
如果我们把document看做是数据库中一条记录的话,field相当于是记录中的字段。field是索引库中存储数据的最小单位。field的数据类型大致可以分为数值类型和文本类型,一般需要查询的字段都是文本类型的,field的还有如下属性:
- 是否分词:是否对域的内容进行分词处理。前提是我们要对域的内容进行查询。
- 是否索引:将Field分析后的词或整个Field值进行索引,只有索引方可搜索到。
- 比如:商品名称、商品简介分析后进行索引,订单号、身份证号不用分词但也要索引,这些将来都要作为查询条件。
- 是否存储:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取 比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
term对象 从文档对象中拆分出来的每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。term中包含两部分一部分是文档的域名,另一部分是单词的内容。term是创建索引的关键词对象。
二. ElasticSearch简介
2.1 什么是ElasticSearch
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2.2 ElasticSearch的使用案例

2.3 ElasticSearch对比Solr

三.ElasticSearch相关概念(术语)
3.1概述
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。Elasticsearch比传统关系型数据库如下:

3.2 Elasticsearch核心概念
3.2.1 索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
3.2.2 类型 type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
3.2.3 字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
3.2.4 映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
3.2.5 文档 document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
3.2.6 接近实时 NRT
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
3.2.7 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
3.2.8 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
3.2.9 分片和复制 shards&replicas
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因: 1)允许你水平分割/扩展你的内容容量。 2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
四、Elasticsearch 安装
- docker镜像下载 docker pull elasticsearch:5.6.8
- 安装es容器 docker run -di --name=kkb_es -p 9200:9200 -p 9300:9300 elasticsearch:5.6.8
- 9200端口(Web管理平台端口) 9300(服务默认端口)
- 浏览器输入地址访问:http://192.168.211.132:9200/
- 开启远程连接
登录容器
docker exec -it kkb_es /bin/bash
查看目录结构 输入: dir
root@07f22eb41bb5:/usr/share/elasticsearch# dir
NOTICE.txt README.textile bin config data lib logs modules plugins
进入config目录
cd config
查看文件
root@07f22eb41bb5:/usr/share/elasticsearch/config# ls
elasticsearch.yml log4j2.properties scripts
修改elasticsearch.yml文件
root@07f22eb41bb5:/usr/share/elasticsearch/config# vi elasticsearch.yml
bash: vi: command not found
vi命令无法识别,因为docker容器里面没有该命令,我们可以安装该编辑器。
设置apt下载源
docker cp ~/sources.list kkb_es:/etc/apt/sources.list
安装vim编辑器
apt-get updateapt-get
install vim
安装好了后,修改elasticsearch.yml配置
vi elasticsearch.yml
同时添加下面一行代码:
cluster.name: my-elasticsearch
重启docker
docker restart kkb_es
五.ElasticSearch的客户端操作
实际开发中,主要有三种方式可以作为elasticsearch服务的客户端:
- 第一种,elasticsearch-head插件
- 第二种,使用elasticsearch提供的Restful接口直接访问
- 第三种,使用elasticsearch提供的API进行访问
5.1 elasticsearch-head
ElasticSearch不同于Solr自带图形化界面,我们可以通过安装ElasticSearch的head插件,完成图形化界面的效果,完成索引数据的查看。安装插件的方式有两种,在线安装和本地安装。本文档采用本地安装方式进行head插件的安装。elasticsearch-5-*以上版本安装head需要安装node和grunt
1.下载head插件:https://github.com/Shuaishuaizai/elasticsearch-head
2.将elasticsearch-head-master压缩包解压到任意目录,但是要和elasticsearch的安装目录区别开
3.下载nodejs:https://nodejs.org/en/download/
安装完毕,可以通过cmd控制台输入:node -v 查看版本号
将grunt安装为全局命令 ,Grunt是基于Node.js的项目构建工具
在cmd控制台中输入如下执行命令:
cnpm install -g grunt-cli
进入elasticsearch-head-master目录启动head,在命令提示符下输入命令:
>npm install
>grunt server
打开浏览器,输入 http://localhost:9100,看到如下页面:

如果不能成功连接到es服务,需要修改ElasticSearch的config目录下的配置文件:config/elasticsearch.yml,增加以下两句命令:
http.cors.enabled: true
http.cors.allow-origin: "*"
然后重新启动ElasticSearch服务。