Odoo 15开发手册第七章 记录集 - 使用模型数据
在前面的章节中,我们概览了模型创建以及如何向模型加载数据。现在我们已有数据模型和相关数据,是时候学习如何编程与其进行交互了。
业务应用需要业务逻辑来计算数据、执行验证或自动化操作。Odoo框架API为开发者提供了工具用于实现这种业务逻辑。大多数时候是查询、转换及写入数据。
Odoo在底层数据库之上实现了一个ORM(对象关系映射)层。ORM提供了API(应用程序接口)用于与数据交互。这种API提供了一个执行环境以及记录集的创建,供对象操作数据库中存储的数据。
本单讲解如何使用执行环境和记录集,通过所需要的工具实现业务处理。
本章主要讲解以下内容:
- 使用 shell 命令交互式地学习 ORM API
- 理解执行环境和上下文
- 使用记录集和作用域(domain)查询数据
- 访问记录集中的数据
- 在记录中写入
- 处理日期和时间
- 使用记录集
- 事务和底层 SQL
学完本章后,读者可以使用Odoo代码执行所有这些操作,还可使用这些工具来实现自己的业务处理。
开发准备
本章代码使用交互式 shell 命令行执行,无需使用前面章节的代码。相关代码参见 GitHub 仓库的ch07/ch07_recorsets_code.py文件。
使用 shell 命令行
Python带有命令行界面,是研究其语法一个很好的方式。Odoo 也有类似的功能,这就是 shell 命令行。可以交互式地执行命令了解其机制。
使用这种命令行,在启动Odoo时加上shell,以及通常启动Odoo所使用的那些选项:
在命令行中执行以下命令并指定数据库即可使用:
(env15) $ odoo shell -c library.conf此时在终端中可以看到正常的服务启动信息,但这时不是启动监听请求的HTTP服务,而是会进行一个等待输入的Python命令窗口。
这一交互式命令界面模拟了以OdooBot超级用户运行class方法内的环境。可以使用self变量,它被设置为OdooBot超级用户记录对象。
例如,使用如下命令查看self记录集:
>>> self
res.users(1,)
>>> self._name
'res.users'
>>> self.name
'OdooBot'
>>> self.login
'__system__'以下命令打印的内容如下:
- self变量含res.users记录集,仅包含一条 id 为1的记录
- 查看self._name获得记录集模型名res.users
- 记录的 name 字段值为OdooBot
- 记录的 login 字段值为
__system__
Odoo 12中的变化
ID号为1的超级用户由原来的 admin 变成内部用户__system__。现在 admin 的 ID 号为 2并且不是超级用户,但默认各标准应用会自动为其授予所有权限。主要原因是避免用户使用超级用户账号来执行日常操作。这样的风险是该用户会跳过权限规则并导致数据的不一致,比如跨公司关联。现在超级用户仅用于查找问题或具体的跨公司操作。
和 Python 一样,可通过 Ctrl + D退出该命令行。此时会结束服务并返回到系统shell 命令行。
现在我们学习了如何启动Odoo shell会话。这对于查看Odoo API功能非常重要。下面就进行一步学习其执行环境。
执行环境
Odoo记录集在环境上下文中进行操作,提供一个触发操作的上下文相关信息。例如使用了数据库游标、当前Odoo用户等等。
在模型方法中运行的Python代码可以访问self记录集变量,可通过self.env访问本地环境。服务端shell环境也提供了一个self指针,和方法中的用法类似。
本节中我们学习执行上下文中的那些属性以及如何使用它们。
环境属性
我们已经知道self是一个记录集。记录集携带环境信息,像浏览数据的用户以及其它上下文相关信息(如,使用的语言和时间)。
可使用记录集的env属性访问当前环境,如下例所示:
我们可通过如下代码查看当前环境:
>>> self.env
self.env 中的执行环境中有以下属性:
- env.cr是正在使用的数据库游标(cursor)
- env.user是当前用户的记录
- env.uid是会话用户 id,与env.user.id相同
- env.context是会话上下文数据中的不可变字典
- env.company是当前公司
- env.companies用户的许可公司
ODOO 13中的变化
Odoo 13中引入了env.company和env.companies。此前版本中这一信息通过使用env.user.company_id和env.user.company_ids在用户记录中读取。
环境还提供对带有所有已安装模型注册表的访问,如self.env['res.partner']返回partner 模型的指针。然后我们还可以对其使用search()或browse()方法来获取记录集:
>>> self.env["res.partner"].search([("display_name", "like", "Azure")])
res.partner(14, 26, 33, 27)上例中返回的res.partner模型记录集包含四条记录,id 分别为14、26、33和27。记录集并没有按 id 排序,因为使用了相应模型的默认排序。就 partner 模型而言,默认的_order为display_name。
环境上下文
环境上下文是一个带有会话数据的字典,可用于客户端用户界面以及服务端 ORM 和业务逻辑中。
在客户端中,它可以把信息从一个视图带到另一个视图中,比如在点击链接或按钮后,携带前一个视图中活跃的记录 id,它也可提供下一个视图中使用的默认值。
在服务端中,一些记录集的值会依赖于上下文提供的本地化设置。具体的例子有影响可翻译字段值的lang键。
上下文还可为服务端代码提供信号。比如active_test键在设为 False 时,会改变ORM中search()方法的行为,它会忽略记录中的active标记,inactive(假删除)的记录也会被返回。
客户端的初始上下文长这样:
>>> self.env.context
{'lang': 'en_US', 'tz': 'Europe/Brussels'}补充:还可使用self.context_get()进行获取
其中 lang 键为用户语言,tz 为时区信息。记录中的内容随当前的上下文可能会不同:
- 可翻译字段根据活跃的 lang 语言不同值也会不同
- 日期字段根据活跃的的 tz 时区不同显示时间会不同
在上一个视图中点击链接或按钮打开视图时,网页客户端会对上下文自动添加一些键,提供我们所浏览记录的信息:
- active_model为前一个模型名
- active_id为用户所位于的原始记录的ID
- active_ids为用户浏览列表视图时所选中的ID列表
向导助手经常使用这些键来查找所要操作的那些记录。
通过对键使用如下前缀上下文可用于设置配置值及对目标客户端视图启用默认过滤器:
- 对字段名添加default_前缀为该字段设置默认值。例如{'default_user_id': uid}将当前用户设置为默认值。
- 对过滤器名添加default_search_前缀会自动启用该过滤器。例如{'default_search_filter_my_tasks': 1}会激活名为filter_my_books的过滤器。
这些前缀常用于窗口动作和视图的元素中。
修改记录集执行环境和上下文
记录集执行上下文可进行修改,来使用前面小节所述的功能或者是对记录集调用的方法添加信息。
环境和上下文可通过下述的一些方法进行修改。每个方法都返回新记录集,以及修改了环境的原始记录集拷贝:
.with_context( 方法使用字典中的内容替换上下文。) .with_context(key=value, ...) 方法修改上下文对其设置所提供的属性。.sudo([flag=True]) 方法启用或禁用可跳过权限规则的超级用户模式,上下文用户保持不变。.with_user( 方法将用户修改为所提供的用户,可以传用户记录或ID号。) .with_company( 方法将公司修改为所提供的公司,可以传公司记录或ID号。) .with_env( 方法将记录集的所有上下文修改为所传的上下文。)
ODOO 13中的变化
Odoo 13中引入了with_user()和with_company()方法。此前的版本中切换用户使用sudo([
]) 方法,可操作指定用户切换为超级用户上下文。此前版本中切换公司使用with_context(force=company=) ,设置一个在相关业务逻辑中选择的context键。
此外环境对象还提供了一个env.ref()函数,传入一个外部标识符字符串并返回相应记录,如下例所示:
>>> self.env.ref('base.user_root')
res.users(1,)如果外部标识符不存在,会抛出ValueError异常。
我们已更深入地学习了在Odoo服务端使用Python代码执行环境的知识。下一步要使用数据进行交互。这时首先要学习的是如何查询数据及创建数据集,在下一节中进行讨论。
使用记录集和作用域查询数据
Odoo业务逻辑需要从数据库中读取数据执行操作。这通过记录集实现,通过查询原始数据并将其暴露至我们可操作的Python对象。
Odoo中Python通常在类方法中运行,self表示要操作的记录集。有时,我们需要为其它模型创建记录集。这时应获取模型的指针,然后对其查询创建记录集。
环境对象通常可通过self.env访问,保存对所有可用模型的引用,它们可通过类字典的语法访问。例如,获取对partner模型的引用,使用self.env['res.partner']或self.env.get('res.partner')。它个模型指针之后可用于创建记录集,我们在下面的小节学习。
创建记录集
search()方法接收一个域表达式然后返回符合条件记录的记录集。例如,[('name', 'like', 'Azure')]会返回name字段包含Azure的所有记录。
如果模型有特殊字段 active,默认只有active=True的记录才在选择范围内。
还可以使用以下关键字参数:
- order关键字是数据库查询ORDER BY语句中使用的字符串。通常是一个逗号分隔的字段名列表。每个字段名都可接DESC关键字,用于表示倒序排列。
- limit关键字设置获取记录的最大条数。
- offset关键字忽略前 n 前记录,可配合limit使用来一次查询指定范围记录。
有时我们只要知道满足某一条件的记录条数。这时可使用search_count()来有效地返回记录条数而非记录集。
browse()方法接收一个 ID 列表或单个ID然后返回这些记录的记录集。在我们知道 ID 并想要获取记录时这就非常方便了。
例如,要获取显示名中包含Lumber的所有partner记录,使用如下的search()调用:
>>> self.env['res.partner'].search([('display_name', 'like', 'Lumber')])
res.partner(15, 34)知道所要查询的ID列表时,使用下例中的browse()调用:
>>> self.env['res.partner'].browse([15, 34])
res.partner(15, 34)大多数情况下都不知道这些ID,因而search()方法比browse()更常用。
为更好地使用search(),需要较好地掌握作用域过滤器的语法。因此,下一节中我们集中讨论。
作用域表达式
作用域(domain)用于过滤数据记录。它使用一种特殊语法来供 Odoo ORM解析,生成数据库查询中的 WHERE 表达式。作用域表达式是一组条件组成的列表,每个条件都是一个('字段名', '运算符', '值')组成的元组,例如,下面这个是就有效的作用域表达式,只有一个条件:[('is_done', '=', False)].。作用域表达式也可以不加条件。这会转换成空列表([]),查询的结果是返回所有记录。
在两种运行作用域上下文的方式:有客户端,如窗口动作和客户端视图,以及服务端,如权限记录规则和方法中的Python代码。字段名和值元素中可以使用的内容取决于运行上下文。
下面我们来学习每个作用域条件的详细解释:字段名、运算符和值。
作用域条件中的字段名元素
第一个条件元素是所需过滤字段的名称字符串。在服务端使用作用域表达式时,字段名元素可使用点号标记来访问关联模型的值。例如,我们可以使用'publisher_id.name',甚至是'publisher_id.country_id.name'。
客户端中不允许使用点号标记,仅能使用简单字段名。
小贴士:在客户端中需要使用关联记录时,因为无法使用点号标记,解决方案时通过related=属性添加关联记录至模型中。这样,就可以直接访问模型字段获取该值。
作用域条件中的运算符元素
第二条件元素为应用于所过滤条件的运算符。可以不用管的运算符如下:
[table id=89 /]
这些运算符应用于第一个元素中提供的字段,使用的是第三个元素是提供的值。如('shipping_address_id', 'child_of', partner_id)在运行上下文查看partner_id变量、读取其值。在数据库中查询shipping_address_id字段,选取地址是partner_id值中查找为其子级的记录。
作用域条件中的值元素
第三个元素以Python表达式运行。可使用字面值,如数字、布尔值、字符串或列表,可使用运行上下文中的值和标识符。
不接受记录对象。而应当使用相应记录的ID。例如,不能使用[('user_id', '=', user)] ,而应使用[('user_id', '=', user.id)]。
对于记录规则 ,运行上下文中有如下可使用的名称:
- user: 当前用户的记录(等价于self.env.user)。使用user.id获取对应的ID。
- company_id: 活跃公司记录的ID(等价于self.env.company.id)。
- company_ids: 所允许公司的ID列表(等价于self.env.companies.ids)。
- time: Python时间模块,提供日期和时间函数。请见官方手册。
ODOO 13中的变化
company_id和company_ids上下文值自Odoo 13可在记录规则运算中使用,此前的版本使用的user.company_id.id不推荐再使用。例如,此前常用的['|', ('company_id', '=', False), ('company_id', 'child_of', [user.company_id.id])] 现在应写为[('company_id', 'in', company_ids)]。
对多字段的搜索
在对对多字段进行搜索时,运算符作用于每个字段值,如果任意字段值匹配作用域条件的话运算的记录就会出现在结果中。
=和in运算符类似于包含运算符。都查看任一字段值是否匹配所搜索值列表中的任意值。对应地,!=和not in运算符查找字段值中不匹配搜索值列表中的任意值。
使用多个条件组合域表达式
域表达式是一个列表并且包含多个条件元组。默认这些条件使用AND逻辑运算符连接,也就是说它仅返回满足所有条件的记录。
也可以使用显式逻辑运算符 - '&'符号表示 AND 运算符(默认值),管道运算符'|'表示OR运算符。这两个运算符会作用于接下来的两项,递归执行。后面我们会一起来详细了解。
对于更为正式的定义,域表达式使用前缀标记法,也称波兰表达式(Polish notation):运算符放在运算项之前。AND和OR是二元运算符,而NOT是一元运算符。
感叹号'!'表示NOT运算符,可用于下一项的运算,因此要放在执行的否定项之前。例如['!', ('is_done','=',True)]会过滤出所有未完成的记录。
运算符,如!和|,可进行嵌套,允许AND/OR/NOT复杂条件的定义。我们通过一个示例进行讲解。
在服务端的记录规则中,我们可以看到类似下面这样的域表达式:
['|',
('message_follower_ids', 'in', [user.partner_id.id]),
'|',
('user_id', '=', user.id),
('user_id', '=', False)
]这个域过滤出所有这样的记录:
- 当前用记是一个关注者,或者
- 当前用户是记录的责任人(user_id),或者
- 记录没有责任用户
下图是上例域表达式的抽象语法树表示:
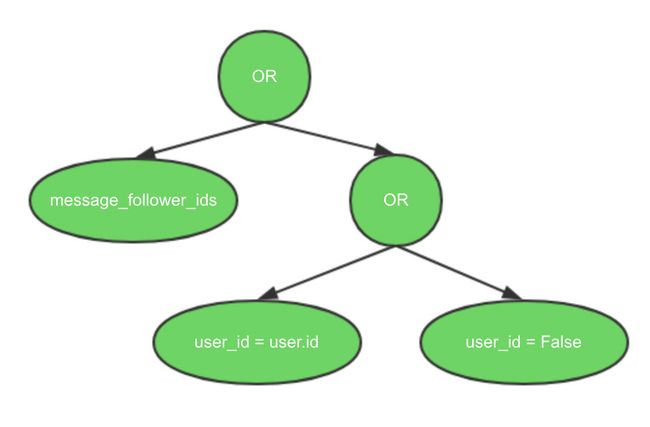
图7.1:描述组合作用域表达式的图
第一个| (OR)运算符作用于关注者的条件加下一个条件的结果。下一个条件又是另两个条件的并集:记录的用户ID设置为当前用户或者没有设置用户ID。
特殊作用域条件
在都想要恒真或恒假时还支持使用一些特殊的作用域条件。
(1, "=", 1)条件为一个恒真表达式。可以对记录规则使用它来为所有记录赋予一个更高的用户组权限。例如,使用User: All Documents 组重载原来受限的继承记录权限组User: Own Documents only。可在Odoo的源代码addons/sales_team/security/sales_team_security.xml中查看这一示例。
还支持(0, "=", 1) ,它表示一个恒假的表达式。
按字段分组以及聚合数据
有时我们需要按数据字段对记录分组。Odoo中可使用read_group()方法。该方法的参数如下:
- domain参数是过滤所获取记录的作用域表达式列表。
- fields是一个字段名列表,配合聚合函数使用的格式为field:aggr。聚合函数为PostgreSQL内置支持的那些,如sum, avg, min, max, count和count_distinct。例如:["subtotal:sum"]。
- groupby参数是一个所需分组的字段名列表。
- limit参数是可选的最大返回分组数。
- offset参数是可选的跳过的记录数。
- orderby参数是可选的结果所使用的order by语句字符串(和search()所支持的类似)。
- lazy参数,若设置为True,仅按第一个字段进行分组,将剩余的分组字段添加至
__context结果中。这个参数的默认值是True,在设置为False时会立即应用所有的分组字段。
以下是按国家对partner记录分组并对不同状态计数的示例:
>>> self.env["res.partner"].read_group([("display_name", "like", "Azure")], fields=["state_id:count_distinct",], groupby=["country_id"], lazy=False)
[{'__count': 4, 'state_id': 1, 'country_id': (233, ), '__domain': ['&', ('country_id', '=', 233), ('display_name', 'like', 'Azure')]}] 这会返回一个国家ID为233的单个分组结果列表。运行self.env["res.country"].browse(233).name,可以看到国家为美国。__count键显示国家ID为233的partner有4个,state_id对象显示去重聚合户数结果:这些用户为同一个1个国家。
现在我们学习了如何创建记录集。接下来,我们要从其中读取数据。大多数情况下这是一个小型的操作,但对某些字段类型,有一些细节需要我们注意。下一节会帮助我们理解。
在记录集中访问数据
一旦获取了数据集,就可以查看其中包含的数据了。下面的几个小节中我们就来探讨如何访问记录集中的数据。
我们可以获取单条记录的字段值,称为单例(singleton)。关联字段带有特殊属性,我们可通过点号标记来查看关联记录。最后我们一起思考处理日期和时间记录以及进行格式转换。
访问记录中数据
记录集中仅有一条记录时,称为单例。单例仍是记录集,在需要记录集的地方均可使用。
与多元素记录集不同,单例可使用点号标记访问它的字段,如:
>>> print(self.name)
OdooBot下个例子中我们看看同一个 self 单例和记录集相同的行为,我们可对其进行遍历。它只有一条记录,所以只会打印出一个名称:
>>> for rec in self: print(rec.name)
...
OdooBot尝试访问有多条记录的记录集字段值会产生错误,所以在不确定操作的是否为单例数据集时就会是个问题。
小贴士:虽然无法使用点号标记访问多记录中的记录,但可以通过将值与记录集进行映射来批量访问。这借由mapped()实现。例如,rset.mapped("name")返回带有name值的列表。
对于设计为仅操作单例的方法,可在开头处使用self.ensure_one()。如果 self 不是单例时将抛出错误。
小贴士:在记录为空时ensure_one()函数也会抛出错误。查看rset是否有零条或一条记录时,可以使用rset or rset.ensure_one()。
空记录也是单例。这会很方便,因为在访问字段值时返回的是None而不是抛出错误。对于关联字段也是如此,使用点号标记访问关联记录也不会抛出错误。
因此在实际使用中,无需在访问字段值前检查是否为空记录集。例如,不需使用if record: print(record.name),我们可以无忧地写下更简单的 print(record.name)。还可以使用or条件提供空值的默认值:print(record.name or "None")。
访问关联字段
前面学习到模型可包含关联字段:多对一、一对多和多对多。这些字段类型的值为记录集。
对于多对一字段,其值可以是单例或空记录集。两种情况下都可以直接访问字段值。如下例中的命令是正确且安全的:
>>> self.company_id
res.company(1,)
>>> self.company_id.name
'YourCompany'
>>> self.company_id.currency_id
res.currency(1,)
>>> self.company_id.currency_id.name
'EUR'为避免麻烦,空记录可像单例一样操作,访问其字段值不会返回错误而是返回 False。所以我们可以使用点号标记来遍历字段,而无需担心因其值为空而报错,如:
>>> self.company_id.parent_id
res.company()
>>> self.company_id.parent_id.name
False访问时间和日期值
在记录集中,日期和日期时间值以原生 Python 对象展示,例如,在查询上次 admin 用户的登录日期时:
>>> self.browse(2).login_date
datetime.datetime(2022, 5, 6, 3, 26, 21, 714562)因为日期和日期时间是 Python 对象,它们可使用这些对象的所有功能。
Odoo 12中的变化
date和datetime字段值以 Python 对象表示,而此前 Odoo 版本中它们以文本字符串表示。这些字段类型值仍可像此前 Odoo 版本中那样使用文本表示。
日期和时间在数据库中以原生的世界标准时间(UTC) 格式存储,不受时区影响。 在记录集中看到的datetime值也是 UTC格式,在客户端中向用户展示时,datetime值会根据当前会话的时区设置来转换成用户的时区,这一设置存储在上下文的tz键中,如{'tz': 'Europe/Brussels'}。这一转换由客户端负责,而不是由服务端完成。
例如在布鲁塞尔(UTC+1)的用户输入11:00 AM数据库中会存储为10:00 AM UTC,而在纽约(UTC-4) 的用户查看时则为06:00 AM。Odoo服务端日志消息时间戳使用提UTC时间,而非本地服务器时间。
相反的转换,由会话时区转换为UTC,也需由客户端在将用户输入的datetime传回服务器时完成。
小贴士:记住数据库中存储的日期和时间数据,以及在服务端代码中处理时均使用UTC表示。即便是服务端日志消息的时间戳也使用UTC表示。
现在我们学习了访问记录数据的详细知识。然而我们应用会为业务处理提供一些自动化,免不了要向记录集中写入数据。在下一小节中进行学习。
在记录中写入
有两种写入记录的方式:使用对象形式的直接赋值或使用write()方法。write()方法是底层负责执行写操作的方法,在使用外部API或加载XML记录时还会直接使用。对象形式的赋值稍后会加入到ORM模型中。它实现活跃记录模式且可以在Python代码逻辑中使用。
ODOO 13中的变化
在Odoo 13中,ORM模型引入了一个新的数据库写入方式,称为内存内ORM。此前的Odoo版本中,每次写入会直接生成相应的数据库SQL命令,这是有性能代价的,尤其复杂的相互依赖所导致的同一记录重复更新。自Odoo 13开始,这些操作会存储在内存缓存中,在事务结束时,自动调用新的flush()方法一次性执行相应的数据库操作。
接下来我们学习这两种方法及其区别。
使用对象形式的赋值
记录集实现了活跃记录模式。意思是我们可对其赋值,然后这些值会在数据库中持久化存储。这是一种符合直接的操作数据的便利方式。
ODOO 13中的变化
Odoo 13中支持对一条以上记录的记录集赋值。截至Odoo 12,仅支持对单条记录写入值,写入多条记录时需要使用write() 方法。
示例如下:
>>> root = self.env["res.users"].browse(1)
>>> print(root.name)
OdooBot
>>> root.name = "Superuser"
>>> print(root.name)
Superuser在使用活跃记录模式时,可通过记录集赋值设置关联字段的值。
日期和时间字段可以通过Python原生对象或Odoo默认格式的字符串表示进行赋值:
>>> from datetime import date
>>> self.date = date(2020, 12, 1)
>>> self.date
datetime.date(2020, 12, 1)
>>> self.date = "2020-12-02"
>>> self.date
datetime.date(2020, 12, 2)二进制字段应使用base64编码的值进行赋值。例如,在从文件读取原始二进制数据时,在赋值给字段前必须使用base64.b64encode()进行转换:
>>> import base64
>>> blackdot_binary = b"\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x00\x01\x00\x00\x00\x01\x08\x04\x00\x00\x00\xb5\x1c\x0c\x02\x00\x00\x00\x0bIDATx\xdacd\xf8\x0f\x00\x01\x05\x01\x01'\x18\xe3f\x00\x00\x00\x00IEND\xaeB'\x82"
>>> self.image_1920 = base64.b64encode(blackdot_binary).decode("utf-8")在对多对一字段赋值时,所赋的值必须为单条记录(即单例记录集)。
对多字段也可使用记录集赋值,将关联记录列表替换为新的记录集。此处允许任意大小的记录集。
对关联字段设置空值时,可设置为None或False。
>>> self.child_ids = None
>>> self.child_ids
res.partner()在赋值列表中追加或删除记录使用记录操作运行。
例如,想旬公司记录还有一条用于存储地址详情的关联partner记录。假定我们想要添加当前用户为公司的子联系人。可通过如下命令实现:
>>> mycompany_partner = self.company_id.partner_id
>>> myaddress = self.partner_id
>>> mycompany_partner.child_ids = mycompany_partner.child_ids | myaddress此处使用了管道运算符(|)来拼接记录获取更大的记录集。
使用更简洁的追加赋值运算符(|=)也可以达到同样效果:
>>> mycompany_partner.child_ids |= myaddress更多有关记录操作运算符的知识请参见本章的构造记录集一节。
通过 write()方法写入
我们还可以使用write()方法来同时更新记录中的数据。它接收一个带有字段名和所赋值的字典。在很多场景中可以方便的使用,例如,在先准备好字典、稍后进行赋值时。对于老版本的Odoo(截至Odoo 12)无法直接赋值的场景也很有用。
write()方法接收字段及所赋值的字典,然后使用它们更新记录集:
>>> Partner = self.env['res.partner']
>>> recs = Partner.search( [('name', 'ilike', 'Azure')] )
>>> recs.write({'comment': 'Hello!'})
True日期和时间字段可以使用相应的Python对象或字符串文本形式进行赋值,和对象形式的赋值一样。
从Odoo 13开始,write()可以使用记录集来为对一和对多关联字段设置值,和对象形式的赋值一样。
ODOO 13中的变化
write()方法可使用记录集来对关联字段赋值。截至Odoo 12,多对一字段都使用ID值来进行设置,而对多字段通过特殊语法进行设置,如使用(4,
, _) 添加记录, (6, 0, []) 设置完整记录列表。这种语法在第五章 Odoo 15开发之导入、导出以及模块数据中进行过讨论。
例如,假设有两条Partner记录:address1和address2,我们希望将它们设置到self.child_ids字段上。
使用write() 方法,命令如下:
>>> self.write({ 'child_ids': address1 | address2})另一种(Odoo 13之前版本需要使用的)方式如下:
self.write({ 'child_ids': [(6, 0, [address1.id, address2.id])]})write()方法用于对已有记录写入数据。但我们还需要创建和删除记录,在下一节中进行讨论。
创建和删除记录
模型方法create()和 unlink()可分别用于创建记录和删除已有记录。
create()方法接收所需创建记录字段和值组成的字典,语法与 write()一致。没错,默认值会被自动应用,如下例所示:
>>> Partner = self.env['res.partner']
>>> new = Partner.create({'name': 'ACME', 'is_company': True})
>>> print(new)
res.partner(56,)unlink()方法会删除记录集中的记录,如下例所示:
>>> rec = Partner.search([('name', '=', 'ACME')])
>>> rec.unlink()
2022-06-05 01:53:09,906 43 INFO odoo-dev odoo.models.unlink: User #1 deleted mail.message records with IDs: [22]
2022-06-05 01:53:09,952 43 INFO odoo-dev odoo.models.unlink: User #1 deleted res.partner records with IDs: [56]
2022-06-05 01:53:09,961 43 INFO odoo-dev odoo.models.unlink: User #1 deleted mail.followers records with IDs: [6]
Trueunlink()方法返回了True。同时在进行删除时,触发日志消息告知我们关联记录的级联删除,如Chatter消息和关注者。
另一种创建记录的方法是复制已有记录。模型方法copy()可用于此。它接收一个可选字典参数,其中包含新建记录时要重写的值。
例如,通过demo用户新建用户的示例如下:
>>> demo = self.env.ref("base.user_demo")
>>> new = demo.copy({"name": "John", "login": "[email protected]"})带有copy=False属性的字段不会被自动拷贝。对多关联字段带有该标记时默认被禁用,因此也不可拷贝。
在前面的小节中,我们学习了如何访问记录集中的数据以及写入记录集。但我们需要关注某些字段类型。在下一节中我们讨论操作日期和时间的具体技巧。
处理日期和时间
在在记录集中访问数据一节中,我们学习了如何从记录中读取日期和时间值。执行日期计算及在原生格式和字符串表示之间进行转换都很常见。以及这们就来学习这类运算。
Odoo为新建日期和时间对象提供了一些有用的函数。
odoo.fields.Date对象提供了这些辅助函数:
- fields.Date.today()返回服务端所需格式的当前日期字符串,它使用UTC作为参照。这足以计算默认值。这种情况可通过default=fields.Date.today直接在日期字段定义中使用。
- fields.Date.context_today(record, timestamp=None)在会话上下文中返回带有当前日期的字符串。时区从记录上下文中获取。可选项timestamp参数是一个datetime对象,如果传入则不使用当前时间,使用传入的值。
odoo.fields.Datetime对象提供了如下日期时间创建函数:
- fields.Datetime.now() 函数返回服务端所需格式的当前日期时间,它使用UTC作为参照。这足以计算默认值。可通过default=fields.Datetime.now直接在日期时间字段定义中使用。
- fields.Datetime.context_timestamp(record, timestamp)函数将原生的日期时间值(无时区)转换为具体时区的日期时间。时区从记录上下文中提取,因此使用了前述函数名。
时间的加减
日期对象可进行比较和相减来获取两个日期的时间差,时间差是一个timedelta对象。timedelta可通过日期运算对date和datetime对象进行加减。
这些对象由 Python 标准库datetime模块提供。以下是使用它进行的基本运算示例:
>>> from datetime import date
>>> date.today()
datetime.date(2022, 6, 5)
>>> from datetime import timedelta
>>> date(2022, 6, 5) + timedelta(days=7)
datetime.date(2022, 6, 12)对于date, datetime和timedelta数据类型的完整参考请见Python 官方文档。
timedelta对象支持周、天、小时、秒等等。但不支持年或月。
要对月或年进行日期运算,应当使用relativedelta对象。以下是加一年又一月的示例:
>>> from dateutil.relativedelta import relativedelta
>>> date(2022, 6, 5) + relativedelta(years=1, months=1)
datetime.date(2023, 7, 5)relativedelta对象对质高级日期运算,包含闰年和复活节的计算。官方文档位于https://dateutil.readthedocs.io。
Odoo 还在odoo.tools.date_utils模块中提供了一些额外的函数:
- start_of(value, granularity)是某个特定刻度时间区间的开始时间,这些刻度有year, quarter, month, week, day或hour。
- end_of(value, granularity)是某个特定刻度时间区间的结束时间。
- add(value, **kwargs)为指定值加上一个时间间隔。**kwargs参数由一个relativedelta对象来定义时间间隔。这些参数可以是years, months, weeks, days, hours, minutes等等
- subtract(value, **kwargs)为指定值减去一个时间间隔
这些工具函数在odoo.fields.Date和odoo.fields.Datetime对象中也可使用。
上述函数的使用示例如下:
>>> from odoo.tools import date_utils
>>> from datetime import datetime
>>> now = datetime(2022, 6, 5, 0, 0, 0)
>>> date_utils.start_of(now, 'week')
datetime.datetime(2022, 5, 30, 0, 0)
>>> date_utils.end_of(now, 'week')
datetime.datetime(2022, 6, 5, 23, 59, 59, 999999)
>>> today = date(2022, 6, 5)
>>> date_utils.add(today, months=2)
datetime.date(2022, 8, 5)
>>> date_utils.subtract(today, months=2)
datetime.date(2022, 4, 5)日期和时间对象转换为文本形式
有时需要将Python的date对象转换为文本形式。你不能吃在准备用户消息或格式化数据发送到其它系统时可能会用到。
Odoo字段对象提供了一些帮助函数用于将原生Python对象转化为字符串:
- fields.Date.to_string(value)函数将date对象转化为Odoo服务端所需的字符串格式。
- fields.Datetime.to_string(value)函数将datetime对象转化为Odoo服务端所需的字符串格式。
它们使用了Odoo服务端的预定义默认值,即如下的常量定义:
- odoo.tools.DEFAULT_SERVER_DATE_FORMAT
- odoo.tools.DEFAULT_SERVER_DATETIME_FORMAT
它们分别映射为%Y-%m-%d和%Y-%m-%d %H:%M:%S。
date.strftime和datetime.strftime函数接收一个格式字符串参数,用于将其它的转化为文本。
例如下面的示例:
>>> date(2022, 6, 5).strftime("%d/%m/%Y")
'05/06/2022'有关格式化代码的详情请参见官方文档。
转化文本表示的日期和时间
有时字符串格式的日期需要转化为Python的date或datetime对象。在Odoo 11及之前经常需要使用,其中的日期是以文本进行读取的。有一些工具可辅助文本和原生日期类型之间的相互转换。
为有助于格式间的转换,fields.Date和fields.Datetime对象提供了这些方法:
- fields.Date.to_date方法将字符串转换为date对象。
- fields.Datetime.to_datetime(value)方法将字符串转换为datetime对象。
使用to_datetime的示例如下:
>>> from odoo import fields
>>> fields.Datetime.to_datetime("2020-11-21 23:11:55")
datetime.datetime(2020, 11, 21, 23, 11, 55)上例中使用了Odoo内置的日期格式解析字符串,然后转化为Python的datetime对象。
对于其它的日期和时间格式,可使用date和datetime对象中的strptime方法:
>>> from datetime import datetime
>>> datetime.strptime("03/11/2020", "%d/%m/%Y")
datetime.datetime(2020, 11, 3, 0, 0)大多数情况下,文本形式的时间不是Odoo服务端所需的UTC时间。需要在存储到Odoo数据库之前转换为UTC时间。
例如,布鲁塞尔时区(UTC +1:00小时)的用户时间2020-12-01 00:30:00在数据库中应存储为UTC时间2020-11-30 23:30:00。代码如下:
>>> from datetime import datetime
>>> import pytz
>>> naive_date = datetime(2020, 12, 1, 0, 30, 0)
>>> client_tz = self.env.context["tz"]
>>> client_date = pytz.timezone(client_tz).localize(naive_date)
>>> utc_date = client_date.astimezone(pytz.utc)
>>> print(utc_date)
2020-11-30 23:30:00+00:00这段代码通过上下文获取用户时间区,然后使用它将原生日期转化为时间相关的日期。最后一步是使用astimezone(pytz.utc)将客户端时区的日期转换为UTC日期。
至此我们学习了Odoo中处理日期和时间的技巧。还有一些处理记录集和关联字段中存储值的具体技巧,我们在下一节中讨论。
使用记录集
记录集是一个记录集合,Python的业务逻辑中经常使用它。对记录集可执行一些运算,如映射和过滤。可以通过添加或删除记录来编写新的记录集。其它的运算有查看记录集的内容来是否包含具体的记录。
ODOO 10中的变化
从Odoo 10开始,记录集运算保留了排序。此前的 Odoo 版本中,记录集运算不一定会保留排序,但加运算和切片是保留排序的。
记录集运算
记录集包含一些函数,可以对其执行一些操作,如排序或过滤记录。
所支持的函数和属性有:
- recordset.ids 属性返回记录集元素的ID列表
- recordset.ensure_one()函数检查是否为单条记录(单例);若不是,则抛出ValueError异常
- The recordset.filtered(
) 函数返回一个过滤了的记录集,函数为过滤记录的测试函数。参数也可为包含所需运算的点号分隔字段序列字符串。会选取运算为真值的记录。 - recordset.mapped(
) 函数返回一个值列表,函数为每条记录返回一个值。参数也可为包含所需运算给返回字段的点号分隔字段序列字符串。在字段序列中使用对多字段是安全的。 - recordset.sorted(
) 返回一个排好序的记录集。函数为每条记录返回一个值。参数也可为待排序字段名称的字符串。注意不允许使用字段的点号标记序列。有一个可选参数reverse=True。
这些函数的使用示例如下:
>>> rs0 = self.env["res.partner"].search([("display_name", "like", "Azure")])
>>> len(rs0) # 几条记录
4
>>> rs0.filtered(lambda r: r.name.startswith("Nicole"))
res.partner(27,)
>>> rs0.filtered("is_company")
res.partner(14,)
>>> rs0.mapped("name")
['Azure Interior', 'Brandon Freeman', 'Colleen Diaz', 'Nicole Ford']
>>> rs0.sorted("name", reverse=True).mapped("name")
['Nicole Ford', 'Colleen Diaz', 'Brandon Freeman', 'Azure Interior']
>>> rs0.mapped(lambda r: (r.id, r.name))
[(14, 'Azure Interior'), (26, 'Brandon Freeman'), (33, 'Colleen Diaz'), (27, 'Nicole Ford')]构造记录集
记录集是不可变的,也就是说无法直接修改其值。但我们可以根据已有记录集构造一个新记录集。切片标记法常用于Python列表中,可用于记录集来提取记录的子集。举一些例子:
- rs[0]和rs[-1]分别返回第一个和最后一个元素
- rs[1:]返回除第一元素外的记录集拷贝
- rs[:1]返回记录集的第一个元素
小贴士:从记录集中提供取第一个元素的安全方式是rs[:1]而非rs[0]。后者在rs为空时结果出错,而前者则仅返回一个空记录集。另一个选择是odoo.fields模块中的first()方法:fields.first(rs)。
记录集还支持如下的集合运算:
- rs1 | rs2是一个集合的并运算,会生成一个包含两个记录集所有元素的记录集。这是一个类似set的运算,不会产生重复元素。
- 例如self.env.user | self.env.user返回单条记录,比如res.users(1,)。
- rs1 & rs2是集合的交集运算,会生成一个仅在两个记录集中同时出现元素组成的数据集。
- rs1 - rs2是集合的差集运算,会生成在rs1中有但rs2中没有的元素组成的数据集。
我们可以直接使用如下更简短标记的运算进行赋值:
- self.author_ids |= author1:如果记录集中不存在author1,会将author1加入记录集。
- self.author_ids &= author1运算仅保留author1记录集中也存在的记录。
- self.author_ids -= author1:如果author1存在于记录集中,进行删除
记录集追加
有时我们希望遍历一些逻辑,将每次循环的结果记录累加起来。ORM中追加的方式是先使用空记录集,然后不断添加记录。要获取空记录集,创建一个模型的指针。例如下面的命令:
>>> Partner = self.env['res.partner']
>>> recs = self.env['res.partner']
>>> for i in range(3):
... rec = Partner.create({"name": "Partner %s" % i})
... recs |= rec
...
>>> print(recs)res.partner(58, 59, 60)以上的代码循环了3次,每次循环都新建了一条partner记录,然后追加至recs记录集中。因其是记录集,recs变量可用于记录集能使用的地方,如向对多字段赋值。
但追加记录集时间效率不高,应避免在循环中进行。原因是Odoo的记录集是不可变对象,对记录集的任何运算都需要通过拷贝来获取变更后的版本。在向记录集追加记录时,原始记录集并未发生变化。而是拷贝了一份追加记录。拷贝运算是耗时的,记录集越大,耗时越久。
因而,需要考虑替代方案。以前例来说,我们可以在Python列表中汇集记录数据字典,然后通过单条create()调用创建所有这些记录。可以这么做是因为create()方法可接收字典列表。
所以可以把循环变成这样:
values = []
for i in range(3):
value = {"name": "Partner %s" % i}
values.append(value)
recs = self.env["res.partner"].create(values)但这一方案并不适用所有场景。另一种选择是使用Python列表汇集记录。Python列表是可变对象,追加元素的运算是高效的。因Python列表并不是记录集,这种方案无法用在记录集的场景中,比如向对多字段赋值。
以下是在Python列表中汇集记录的示例:
Partner = self.env["res.partner"]
recs = []
for i in range(3):
rec = Partner.create({"name": "Partner %s" % i})
recs.append(new_rec)以上这些例子描述了使用循环通过单独元素构建记录集的一些技巧。但有些场景并不一定要循环,像mapped()和filtered()这样的运算可提高效的实现方式。
记录集比较
某些场景中我们需要比较记录集的内容,来决定是否做进一步操作。记录集支持常规的比较运算。
查看
in not in
也可对记录做比较看一个记录集是否包含另一个记录集。比较两个记录集set1和set2:
- 如果set1中的所有元素也位于set2中,set1 <= set2及set1 < set2返回True。在两个记录集元素相同时<运算符返回False。
- 如果set2中的所有元素也位于set1中,set1 >= set2及set1 > set2返回True。在两个记录集元素相同时>运算符返回False。
数据库事务和底层SQL
通过客户端调用的ORM方法在事务中运行。事务保障了并发写入或出错时数据的正确性。在事务中,数据记录会上锁,保护其不受其它并发事务的影响,并保障不会有计划外的修改。在出错时,所有事务所做的修改会回滚,回到初始状态。
PostgreSQL提供了对事务的支持。在通过客户端调用ORM方法时,会初始化一个新的事务。如果在方法执行过程中发生错误,所有的修改都会撤销。如果方法执行完成且未报错,就会提交修改,让修改对其它事务有效、可见。
这些会自动进行处理,我们一般不太需要有任何担心。但在一些高级用例中,对当前事务加以控制可能会比较好。
ODOO 13中的变化
自Odoo 13起,数据库的写操作不是在方法运行时完成。而是汇聚在内存缓存中,实际的数据库写入会延迟至方法执行结束之时,由自动触发的flush()调用执行。
控制数据库事务
有些场景下控制事务会有利,可使用数据库游标self.env.cr加以实现。举个例子,遍历记录对每条记录执行运算,希望跳过运算错误的那些且不影响其它的记录。
为此,对象提供了如下方法:
- self.env.cr.commit()提交事务缓冲的写运算,使其在数据库中生效。
- self.env.cr.rollback()取消上次提交之后的写运算,如果尚未提交,则回滚所有操作。
小贴士:Odoo的shell会话模拟方法执行上下文。直到调用self.env.cr.commit()时才会执行数据库写操作。
执行原生SQL
The values parameter can be a tuple or a dict. When using a tuple, the parameters are replaced with %s, and when using a dict, they are replaced with %(
通过游标的execute()方法,我们可以直接在数据库中运行SQL语句。它接收一个要运行的SQL语句字符串,以及第二个可选参数:一个用作 SQL 参数值。
这一参数值可以是元组或列表。在使用元组时,参数使用%s替换,使用字典时,通过%(
>>> self.env.cr.execute("SELECT id, login FROM res_users WHERE login=%s OR id=%s", ("demo", 1))
>>> self.env.cr.execute("SELECT id, login FROM res_users WHERE login=%(login)s OR id=%(id)s", {"login": "demo", "id": 1})以上运行SQL的指令,需要替换参数及准备待抓取的结果游标。更多详情可参见psycopg2的官方文档。
注意:
在cr.execute() 中我们不应直接编写拼接参数的SQL查询。众所周知这样做会带来SQL注入攻击的安全风险。保持使用%s占位符并通过第二个参数来传值。
使用fetchall()函数获取结果,返回数据行的元组:
>>> self.env.cr.fetchall()
[(1, '__system__'), (6, 'demo')]也可使用dictfetchall()函数来以字典获取记录:
>>> self.env.cr.dictfetchall()
[{'id': 1, 'login': '__system__'}, {'id': 6, 'login': 'demo'}]小贴士:self.env.cr数据库游标对象是Odoo对PostgreSQL库psycopg2的封装。也就是说psycopg2的官方文档对助于我们对使用该对象的全面理解。
还可以使用数据操纵语言(DML) 来运行指令,如UPDATE和INSERT。Odoo环境依赖于数据缓存 ,这可能导致执行DML与数据库中的实际数据不一致。出于这个原因,在使用原生DML后,应使用self.env.cache.invalidate(fnames=None, ids=None).清除缓存。
fnames是清除和刷新的字段名列表。如未提供,则会清除所有字段。
ids是清除和刷新的记录ID列表。如未提供,则会清除所有字段。
注意:
直接在数据库中执行SQL语句可能会跳过ORM验证和依赖进而导致数据不一致,请仅在确定时进行该操作。
总结
在本章中,我们学习了如何操作模型数据执行 CRUD 运算:即创建、读取、更新和删除数据,还有处理和操作数据库所需的所有技巧。这是实现我们的业务逻辑和自动化代码的基石。
对于ORM API的测试,我们使用了Odoo交互式 shell 命令行。我们通过self.env环境运行了命令,该环境类似于模型方法中的环境,因此对于探索Odoo API功能很有用。
该环境让我们可以查看任意Odoo模型中的数据并生成记录集。我们学习了创建记录集的不同方式以及如何读取所提供的数据,包含一些特殊数据类型,如日期、二进制值和关联字段。
Odoo的另一个基本能力是回写数据。本章中,我们学习了如何新建记录,对现有记录写入以及删除记录。
我们还学习是日期和时间值的处理,使用了Python内置的工具以及Odoo框架所包含的一些帮助函数。
可操作记录集来添加元素、过滤记录、重新排序或追加值,以及比较记录集或查看具体记录的包含关系。这实现业务逻辑时可能会需要这些运算,本意中讲解了它们的基本技巧。
最后,我们可能需要跳过ORM模型的使用,使用底层SQL运算直接访问数据库或更精准地控制事务。这样可应对那些ORM模型对任务不理想的场景。
学习了这么多工具,我们可以进入下一章了,其中会学习模型的业务逻辑层以及实现使用ORM API自动操作的模型方法。
扩展知识
有关记录集的Odoo官方文档。