scrapy集成selenium分布式爬虫---01
文章目录
- 一. 创建一个scrapy项目
- 二. 在这个项目中创建一个爬虫文件
- 三.分析网页
- 四.selenium懒加载
- 五.数据解析
- 六.将数据持久化存储(以保存到mysql为例)
- 七.总结
一. 创建一个scrapy项目

二. 在这个项目中创建一个爬虫文件
首先要cd到创建的项目,再执行下面的代码创建爬虫文件


三.分析网页
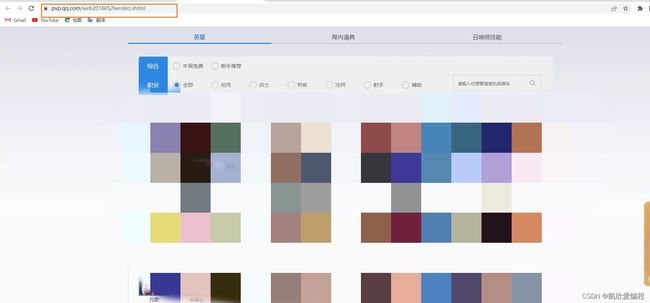
将地址放到爬虫文件的start_url中去

打印数据源码
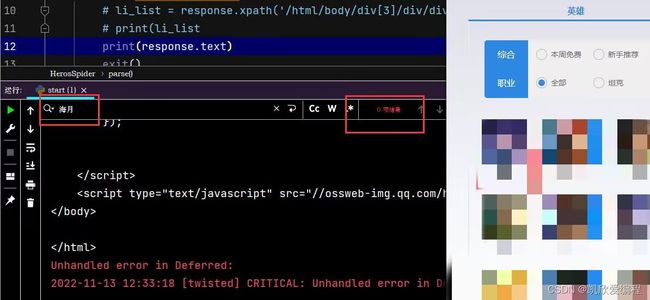
可以看到我们并没有抓取到里面所有英雄的数据,说明这个网页存在一个懒加载,所以我们需要做一个页面加载的操作(利用selenium)
四.selenium懒加载
首先需要导入selenium驱动的包,创建一个初始化方法去实例化一个driver驱动对象

在middlewares.py中间件文件中的requesr_response()方法里面实现懒加载
加载之前我们需要导入两个模块


request.url是我们发起请求的网页地址
spider.driver.execute_scrapt()是执行我们的js代码
sleep是为了等待一秒让网页数据通过selenium滚动后的数据加载出来
deta是获取的加载数据后的网页源码
HtmlResponse是将加载完后的网页响应对象返回给spider爬虫文件
spider.driver.current_url是数据加载后的网页地址
body 是加载数据后的网页数据源码
request是请求方式还是没有变的
encoding是我们网页的编码格式
在settings中开启我i们中间件的管道,使得响应对象传入到我们的spider文件中

可以看到我们的网页数据已经抓取到了
五.数据解析


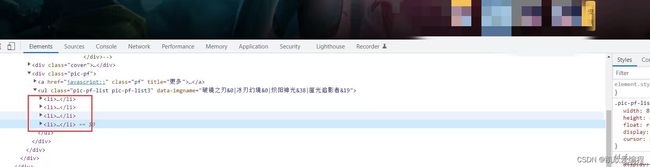
提取到每个小li下面的a标签的href属性值,可以看到这个href的链接缺少了一个请求头

提取到详细页面链接之后利用yield生成器再次对详细页面链接发起请求,callback就是解析详细也买你链接需要的回调函数
抓取详细页面的皮肤图片和昵称(每一张皮肤都在一个li标签中)


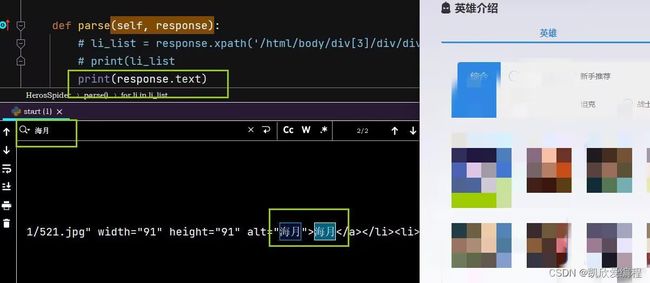
这里获取的英雄的全名,为什么有none(拿海月看到)

我们有些英雄的全名是直接嵌套在h3标签内,而我们上面的代码却是在h3标签下还嵌套了一个span,所以此处我们要做个if判断

抓取英雄的技能以及技能的详细伤害
.
这里做了一个异常捕获就是在爬取过程中会出现报错,如果某一个数据没有获取到而导致报错我们可以通过这个捕获快速找到原因
六.将数据持久化存储(以保存到mysql为例)
首先需要先在item.py文件中定义数据结构的字段

将item.py定义的数据结构类导入到我们的spider文件中,并且提交到pipelines管道
![]()

在settings.py中开启pipelines管道

可以在pipelines.py中输出一下item,如果看得到我们传书的数据说明数据通过管道传输过来了
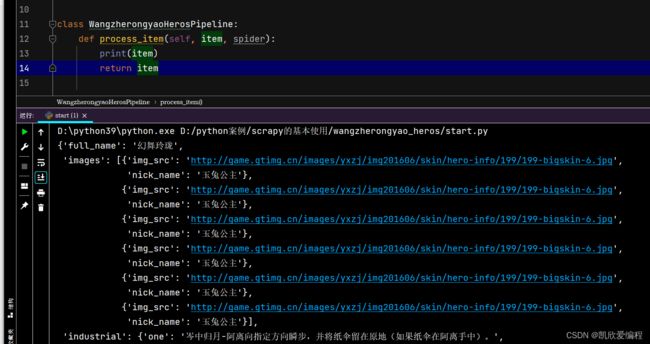
保存到mysql之前可以先在MySQL可视化工具中创建一个数据库和数据表

做数据持久化存储在pipelines.py中
import pymysql
class WangzherongyaoHerosPipeline:
def open_spider(self, spider):
self.coon = pymysql.connect(host='127.0.0.1', port=3306, user='****', mima='******', charset='utf8',
database='wangzhe_heros')
def process_item(self, item, spider):
self.cursor = self.coon.cursor() # 创建一个光标对象
sql = '''insert into heros(full_name,nick_name,images,industrial) values(%s,%s,%s,%s)'''
self.cursor.execute(sql,[item['full_name'],item['nick_name'],str(item['images']),str(item['industrial'])])
self.coon.commit()
return item
# print(item)
def close_spider(self,spider):
self.cursor.close()
self.coon.close()
这里的open_sipder()和close_spider()是我自己实例化的两个函数,因为,scrapy生成器是一条一条的提交过来的,然而我们连接数据库只需要连接一次,为了减少性能的耗费,我们只需要打开一次,可以在pipeline类中定义一个函数,close也是如此,其实你使用with open()的话就更能体现出实例这两个方法的必要性
运行scrapy项目,在mysql可视化工具中查看我们的数据

七.总结
本章集成了selenium和scrapy进行网页数据抓取,我们selenium的缺点是效率慢,中和scrapy的高效,会让我们抓取数据更快,也通过selenium解决了网页数据懒加载的问题,以及持久化存储(在scrapy中如何把数据保存到mysql中)