【跟着labuladong刷力扣】力扣刷题-----数据结构之二叉树
前言
刷题学框架,刷题学思想.跟着labuladong从二叉树开始刷力扣.
labuladong链接:labuladong代码小抄
刷题插件链接(来源labuladong公众号):
链接:https://pan.baidu.com/s/1glrZjyFCG4bXual3gzTvvw
提取码:un2k
文章目录
- 前言
- 一、纲领篇
-
- 1. 解决二叉树问题的两种思维
- 2.理解二叉树的前中后序
- 3.力扣104题:二叉树的最大深度(简单)
- 4.力扣543题:二叉树的直径(简单)
- 5. 力扣144题:二叉树的前序遍历(简单)
- 二、思路篇
-
- 1.力扣226题:翻转二叉树(简单)
- 2.力扣114题:二叉树展开为链表(中等)
- 3.力扣116题:填充每个节点的下一个右侧节点指针(中等)
- 三、构造篇
-
- 1. 力扣654题:最大二叉树(中等)
- 2. 力扣105题:从前序与中序遍历序列构造二叉树(中等)
- 3. 力扣106题:从中序与后序遍历序列构造二叉树(中等)
- 4. 力扣889题:根据前序和后序遍历构造二叉树(中等)
- 四、序列篇
-
- 1. 力扣297题:二叉树的序列化与反序列化(困难)
- 五、后序篇
-
- 1. 力扣652题:寻找重复的子树(中等)
- 六、归并排序详解及应用
-
- 1. 力扣912题:排序数组
- 2. 力扣315题:计算右侧小于当前元素的个数(困难)
- 3. 力扣493题: 翻转对(困难)
- 4. 力扣327题: 区间和的个数(困难)
- 七、快速排序详解及应用
-
- 1. 力扣912题: 排序数组(中等)
- 2. 力扣215题:数组中的第K个最大元素(困难)
- 八、二叉搜索树特性篇
-
- 1. 力扣230题:二叉搜索树中第K小的元素(中等)
- 2. 力扣538/1038题:把二叉搜索树转换为累加树(中等)
- 九、二叉搜索树基操篇
-
- 1. 力扣700题:二叉搜索树中的搜索(简单)
- 2. 力扣450题:删除二叉搜索树中的节点(中等)
- 3. 力扣701题:二叉搜索树的插入操作(中等)
- 4. 力扣98题:验证二叉搜索树(中等)
- 十、二叉搜索树构造篇
-
- 1. 力扣96题:不同的二叉搜索树(中等)
- 2. 力扣95题:不同的二叉搜索树Ⅱ(中等)
- 十一、美团面试官:你对后序遍历一无所知
-
- 1. 力扣1373题:二叉搜索子树的最大键值和(困难)
- 十二、 Git原理之最近公共祖先
-
- 1. 力扣236题:二叉树的最近公共祖先(中等)
- 2. 力扣235题:二叉搜索树的最近公共祖先(简单)
- 十三、如何计算完全二叉树的节点数
-
- 1. 力扣222题:完全二叉树的节点个数(中等)
一、纲领篇
在刷题心得中,作者建议从二叉树开始建立思维,我也缺少递归思维,因此从二叉树开始刷题.
1. 解决二叉树问题的两种思维
- 是否可以通过遍历一遍二叉树得到答案? 如果可以,用一个traverse函数配合外部记录变量(如高度)来实现,这种是遍历的思维模式.
- 是否可以定义一个递归函数,每次递归都用子树的答案推导出原问题的答案? 如果可以,要给出递归函数的定义,并充分利用这个函数的返回值,这叫做分解问题的思维模式.
后面的刷题将从这两个思维模式进行分析,每到二叉树的题都会有1-2种解题思路.
2.理解二叉树的前中后序
抛开书本所讲,直接给出理解:前序位置就是刚进入一个节点的时候,后序位置就是即将离开一个节点的时候,中序位置就是左子树都遍历完,即将开始遍历右子树的时候,将代码写在不同位置,代码执行的时机就不同.
3.力扣104题:二叉树的最大深度(简单)
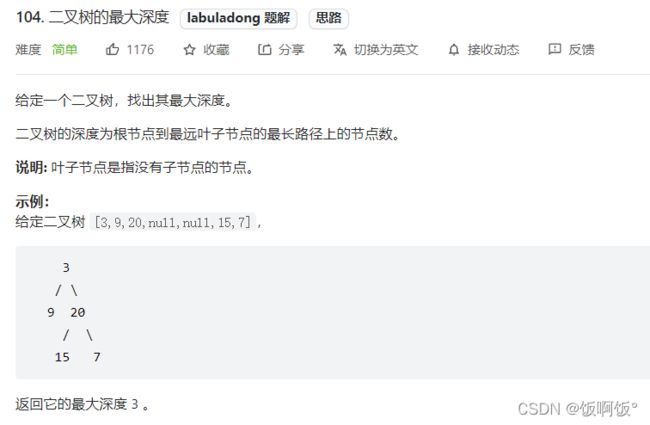
- 是否可以用遍历的思想解决: 可以!! 遍历每一个节点,并记录高度即可,最后返回最大高度.需要注意的是,力扣的提交系统处理全局存在一些规则:提交之后所用的测试用例共享全局变量和类变量,因此有些定义了全局变量的程序,在执行代码时是对的,但在提交时就有问题了.参考: https://leetcode-cn.com/circle/discuss/A2t74s/.回到本题,本题的代码如下:
var maxDepth = function(root) {
// 最大的高度
res = 0
//记录高度
depth = 0
// 遍历二叉树
traverse(root)
return res
};
var traverse = function(root){
// 遍历到叶子节点
if(root === null){
res = Math.max(res,depth)
return
}
// 进入节点时,高度加1
depth++
traverse(root.left)
traverse(root.right)
// 离开节点时,高度减1
depth--
}
关于为什么离开节点时,高度要减1的问题,我觉得这样解释比较好,因为遍历到右子树后左子树的高度就不能要了,因此要减1.
- 是否可以用分解问题的思想解决:**也可以!!**因为大树的高度是由子树的高度加起来的,代码比较简单
// maxDepth定义为计算一棵树的高度
var maxDepth = function(root){
if(root === null){
return 0
}
// 计算左子树高度
var leftDepth = maxDepth(root.left)
// 计算右子树高度
var rightDepth = maxDepth(root.right)
// 当前最大的高度为左右的最高加1
var res = Math.max(leftDepth,rightDepth) + 1
return res
}
4.力扣543题:二叉树的直径(简单)

所谓二叉树的直径,就是左右子树的最大深度之和,那么直接的想法是对每个节点计算左右子树的最大高度,得出每个节点的直径,从而得出最大的那个直径。(这个没搞清楚~~)
var diameterOfBinaryTree = function(root) {
// 最大直径
maxDiameter = 0
// 遍历树
maxDepth(root)
return maxDiameter
};
var maxDepth = function(root){
if(root === null){
return 0
}
// 遍历左右子树
var maxleft = maxDepth(root.left)
var maxright = maxDepth(root.right)
// 比较左右子树之和与目前最大高度的值
maxDiameter = Math.max(maxDiameter,maxleft+maxright)
return Math.max(maxleft,maxright) + 1
}
5. 力扣144题:二叉树的前序遍历(简单)

本题可以直接用遍历的思想解决,直接前序遍历
var preorderTraversal = function(root) {
arr = []
traverse (root)
return arr
};
var traverse = function(root){
if(root === null){
return
}
arr.push(root.val)
traverse (root.left)
traverse (root.right)
}
二、思路篇
1.力扣226题:翻转二叉树(简单)
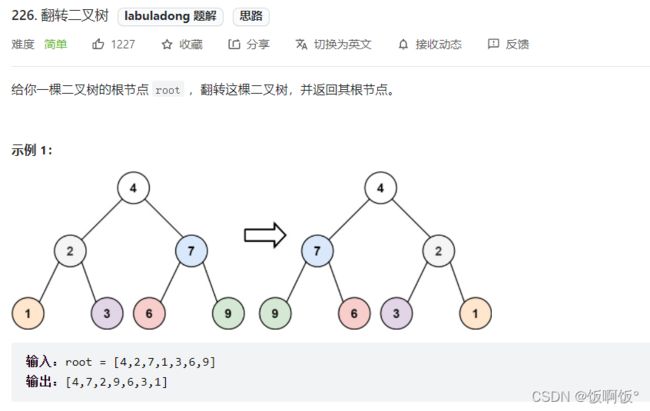
- 遍历思路:遍历每个节点,交换它的左右节点
var invertTree = function(root) {
reverse(root)
return root
};
var reverse = function(root){
if(root === null){
return
}
var temp = new TreeNode()
temp = root.left
root.left = root.right
root.right = temp
reverse(root.left)
reverse(root.right)
}
- 迭代思路:定义一个函数,它可以交换一个节点的左右子树.
// 功能定义:交换左右子树的位置
var invertTree = function(root) {
if(root === null){
return null
}
var Left,Right = new TreeNode()
// 对整颗树的操作,交换左右子树
Left = invertTree(root.left)
Right = invertTree(root.right)
// 对当前子树的操作左子树给右边,右子树给左边
root.left = Right
root.right = Left
return root
};
2.力扣114题:二叉树展开为链表(中等)

给函数输入一个节点root,以root为根的二叉树就会被扯平为一条链表,首先将左右子树拉平,然后把左子树放到右子树的位置上,右子树向下移.
// 定义:将以root为根的数拉平为链表
var flatten = function(root) {
if(root === null){
return
}
// 递归拉平左右子树
flatten(root.left)
flatten(root.right)
// 后序位置
// 左右子树已经被拉平成一条链表
let Left = root.left
let Right = root.right
// 将左子树作为右子树
root.left = null
root.right = Left
// 将右子树接在左子树后面
while(root.right!=null){
root = root.right
}
root.right = Right
return root
};
3.力扣116题:填充每个节点的下一个右侧节点指针(中等)

最初的思路一定是将左子树的right指向右子树,但是这样不能解决相邻的两个节点中,左边的右孩子要指向右边的左孩子的问题,两颗子树是分开的,因此labuladong大神给了一种思路,就是把二叉树的相邻节点抽象成一个三叉树节点,这样就把不是同一父节点的两个孩子关联起来了.(图片来源于labuladong)

var connect = function(root) {
if(root === null) return null
traverse(root.left,root.right)
return root
};
var traverse = function(node1,node2){
if(node1 === null || node2 === null){
return
}
node1.next = node2
traverse(node1.left,node1.right)
traverse(node2.left,node2.right)
traverse(node1.right,node2.left)
}
三、构造篇
1. 力扣654题:最大二叉树(中等)

每一个二叉树节点都可以认为是一棵树的根节点,因此可以用分解的思路解决:选择最大的数作为根节点,然后将数组从最大数进行分界,递归构造左右子树.
var constructMaximumBinaryTree = function(nums) {
return build(nums , 0 , nums.length - 1)
};
// 函数定义:用最大的数作根节点,左右两边成为左右子树
var build = function(nums,left,right){
if(left > right){
return null
}
var index = -1
var maxVal = -Infinity
// 最找最大值及其索引
for(var i=left;i<=right;i++){
if(maxVal < nums[i]){
maxVal = nums[i]
index = i
}
}
// 构造根节点
var root = new TreeNode(maxVal)
// 构造左右子树
root.left = build(nums,left,index-1)
root.right = build(nums,index+1,right)
return root
}
2. 力扣105题:从前序与中序遍历序列构造二叉树(中等)
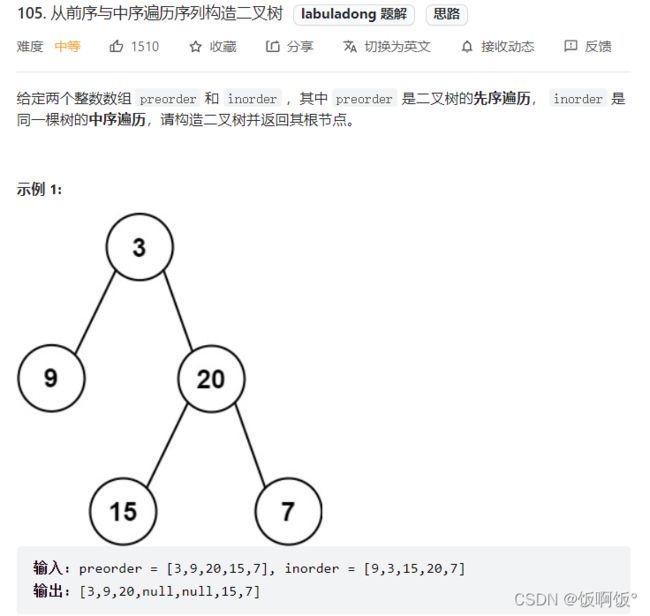
二叉树的前序和中序遍历结果的特点如下:(图片来源:labuladong算法小抄)
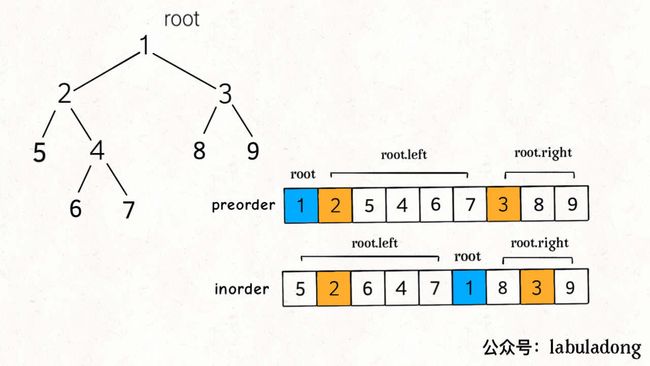
首先可以确定的是前序遍历的第一位就是整个树的根节点,在中序遍历中找到这个根节点,就可以把中序遍历分成左子树和右子树,再重新对左右子树做找根节点,拆分中序的做法,就可以得到整个二叉树.
var buildTree = function(preorder, inorder) {
return build(preorder,0,preorder.length-1,inorder,0,inorder.length-1)
};
// 函数定义,给出前序遍历,以及起始边界,中序遍历,以及起始边界,得到一棵二叉树
var build = function(preorder,preStart,preEnd,inorder,inStart,inEnd){
if(preStart > preEnd || inStart > inEnd){
return null
}
// 取前序的第一个节点做根节点
var root = new TreeNode(preorder[preStart])
// 在中序中寻找根节点索引,就可以把中序分成左右两半了
var index = inorder.indexOf(preorder[preStart])
// 计算左子树大小,方便确定边界值
var leftsize = index - inStart
// 遍历生成左右子树
root.left = build(preorder,preStart+1,preStart+leftsize,inorder,inStart,index-1)
root.right = build(preorder,preStart+leftsize+1,preEnd,inorder,index+1,inEnd)
return root
}
-
左子树参数解释
------preorder:前序遍历数据
------preStart+1:由于当前的第一位已经做了根节点,因此下一个根节点应该是preStart+1
------preStart+leftsize:此处应该是左子树数组结束的地方,就是左子树开始+左子树大小
------inorder:中序遍历数据
-----inStart:中序遍历最左边就是左子树的开始
-----index-1:左子树截至在根节点之前一位 -
右子树参数解释
------preorder:前序遍历数据
------preStart+leftsize+1:右子树第一位应该是左子树最后一位的下一位
------preEnd:右子树的最后一位就是数组的最后一位
------inorder:中序遍历数据
------index+1:中序遍历右子树就是根节点索引值的下一位
------inEnd:右子树截至在数组的最后一位
3. 力扣106题:从中序与后序遍历序列构造二叉树(中等)

思路与上题基本一直,只需修改递归的参数即可,不多余解释了,直接上代码
var buildTree = function(inorder, postorder) {
return build(inorder,0,inorder.length-1,postorder,0,postorder.length-1)
};
var build = function(inorder,inStart,inEnd,postorder,posStart,posEnd){
if(inStart > inEnd || posStart > posEnd){
return null
}
var root = new TreeNode(postorder[posEnd])
var index = inorder.indexOf(postorder[posEnd])
var rightsize = inEnd - index
root.left = build(inorder,inStart,index-1,postorder,posStart,posEnd-rightsize-1)
root.right = build(inorder,index+1,inEnd,postorder,posEnd-rightsize,posEnd-1)
return root
}
4. 力扣889题:根据前序和后序遍历构造二叉树(中等)
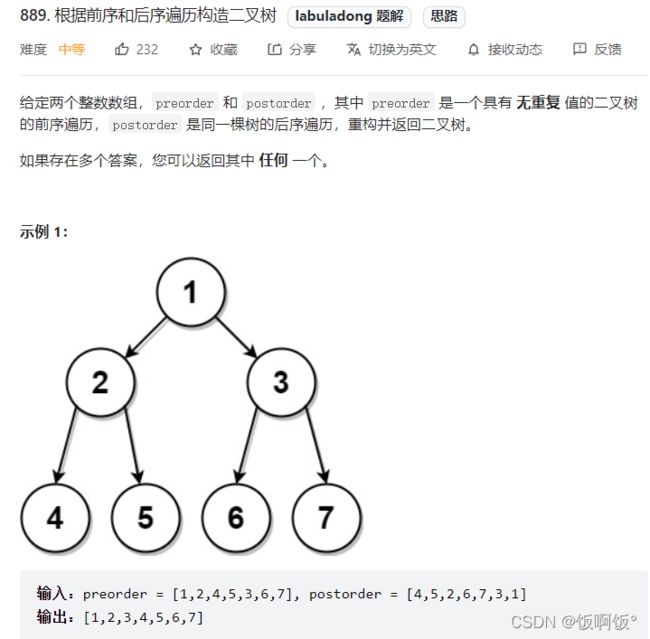
这里没有中序遍历了,因此就缺少了划分左右子树的标志,前序遍历是无法划分的,但是后序遍历可以通过前序的下一个值来划分左右子树,如图所示,(图片来源:labuladong算法小抄)(膜拜大神,写的实在是太好啦!!!)
由于使用到了当前节点的下一节点,因此在判断条件那里也要加上一条如果perStart == preEnd,就应该创建节点,不用再遍历左右子树了.代码如下:
var constructFromPrePost = function(preorder, postorder) {
return build(preorder,0,preorder.length-1,postorder,0,postorder.length-1)
};
var build = function(preorder,preStart,preEnd,postorder,postStart,postEnd){
if(preStart > preEnd || postStart > postEnd){
return null
}
if(preStart == preEnd){
return new TreeNode(preorder[preStart])
}
var root = new TreeNode(preorder[preStart])
var index = postorder.indexOf(preorder[preStart+1])
var leftSize = index - postStart +1
root.left = build(preorder,preStart+1,preStart+leftSize,postorder,postStart,index)
root.right = build(preorder,preStart+leftSize+1,preEnd,postorder,index+1,postEnd-1)
return root
}
四、序列篇
1. 力扣297题:二叉树的序列化与反序列化(困难)
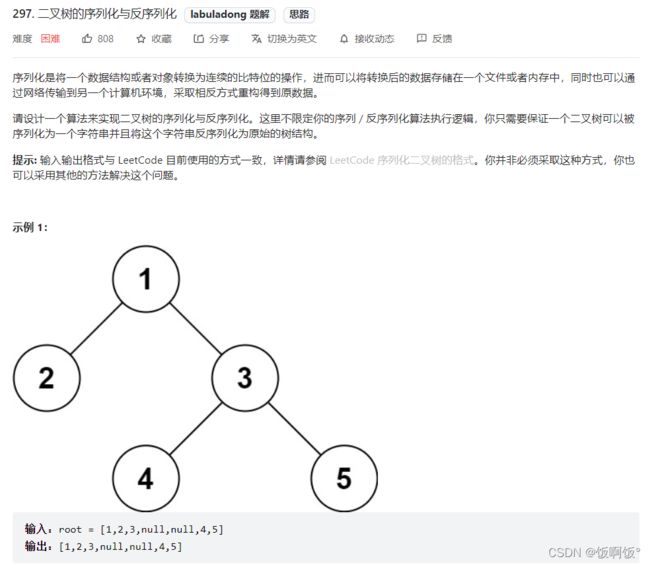
序列化:
var serialize = function(root) {
res = ''
rserialize(root)
return res
};
var rserialize = function(root){
if(root == null){
res += 'None,'
return
}
res += root.val + ','
rserialize(root.left)
rserialize(root.right)
}
反序列化:
var deserialize = function(data) {
var arr = data.split(",")
var root = rdeserialize(arr)
return root
};
var rdeserialize = function(arr){
if(arr[0] === 'None' && arr.length > 0){
arr.shift()
return null
}
var root = new TreeNode(arr[0])
arr.shift()
root.left = rdeserialize(arr)
root.right = rdeserialize(arr)
return root
}
五、后序篇
如何判断题目应该使用后序的方法:一旦发现题目和子树有关,大概率要给函数设置合理的定义和返回值,在后序位置写代码.
1. 力扣652题:寻找重复的子树(中等)
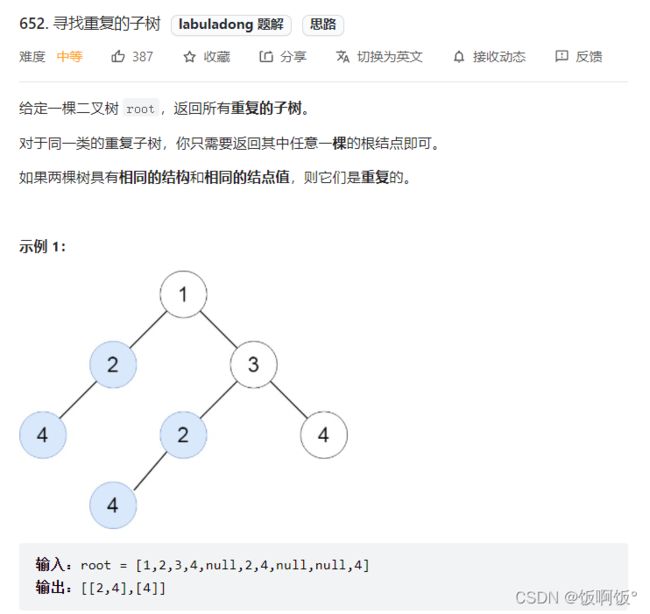
- 此题需要存储子树的个数,因此要使用到Map对象,下面介绍一下Map对象的使用(来自菜鸟教程).
let nameSiteMapping = new Map();
// 设置 Map 对象
nameSiteMapping.set("Google", 1);
nameSiteMapping.set("Runoob", 2);
nameSiteMapping.set("Taobao", 3);
// 获取键对应的值
console.log(nameSiteMapping.get("Runoob")); // 2
// 判断 Map 中是否包含键对应的值
console.log(nameSiteMapping.has("Taobao")); // true
console.log(nameSiteMapping.has("Zhihu")); // false
// 返回 Map 对象键/值对的数量
console.log(nameSiteMapping.size); // 3
// 删除 Runoob
console.log(nameSiteMapping.delete("Runoob")); // true
// 移除 Map 对象的所有键/值对
nameSiteMapping.clear(); // 清除 Map
- 寻找重复二叉树的过程中,要先找到根节点的子树,由下至上一层一层判断.
var findDuplicateSubtrees = function(root) {
myMap = new Map()
res = []
traverse(root)
return res
};
var traverse = function(root){
if(root === null){
return
}
var left = traverse(root.left)
var right = traverse(root.right)
var subTree = left + ',' + right + ',' + root.val
let flag = myMap.get(subTree) || 0
if(flag == 1){
res.push(root)
}
myMap.set(subTree,flag+1)
return subTree
}
六、归并排序详解及应用
1. 力扣912题:排序数组
- 排序数组的方法有很多,比如冒泡法,全排,归并等方法,其中归并排序的方法可以使用树的递归来完成.
- 复习归并排序思路:先把数组分成左右两个部分,分别对左右两部分排序,再合并两部分.其中,分别对左右两部分排序可以使用递归,合并的部分需要单独解释(主要是我不会).
var merge = function(nums,left,mid,right){
for(var i=left;i<=right;i++){
//不能原地合并,需要复制到辅助数组
temp[i] = nums[i]
}
// 标记左右两部分的位置
var i = left,j = mid+1
for(var p=left;p<=right;p++){
if(i == mid+1){
//要先判断左右是否都归并完成,因此要先判断,后排序,
// 如果左边到边界,只把右边加到数组中
nums[p] = temp[j++]
}else if(j == right+1){
// 如果右边到边界,只把左边加到数组中
nums[p] = temp[i++]
}else if(temp[i]<temp[j]){
//如果左边小于右边,把左边加到数组中,并左边++
nums[p] = temp[i++]
}else{
//还有等于的情况,所以不能直接写temp[i]>temp[j]
nums[p] = temp[j++]
}
}
}
- 递归操作
var sortArray = function(nums) {
temp = []
Sort(nums,0,nums.length-1)
return nums
};
var Sort = function(nums,left,right){
if(left == right){
return
}
var mid = left + parseInt((right - left)/2)
Sort(nums,left,mid)
Sort(nums,mid+1,right)
merge(nums,left,mid,right)
}
2. 力扣315题:计算右侧小于当前元素的个数(困难)
3. 力扣493题: 翻转对(困难)
4. 力扣327题: 区间和的个数(困难)
七、快速排序详解及应用
1. 力扣912题: 排序数组(中等)
2. 力扣215题:数组中的第K个最大元素(困难)
(以上五道题没看懂,等二叉树都学完再来看)
八、二叉搜索树特性篇
二叉搜索树(BST)的特性是,对于每个节点,左子树的值都比其值小,右子树值都比其值大;且左右子树也都是BST.
二叉搜索树的中序遍历结果是有序的(从小到大)
1. 力扣230题:二叉搜索树中第K小的元素(中等)
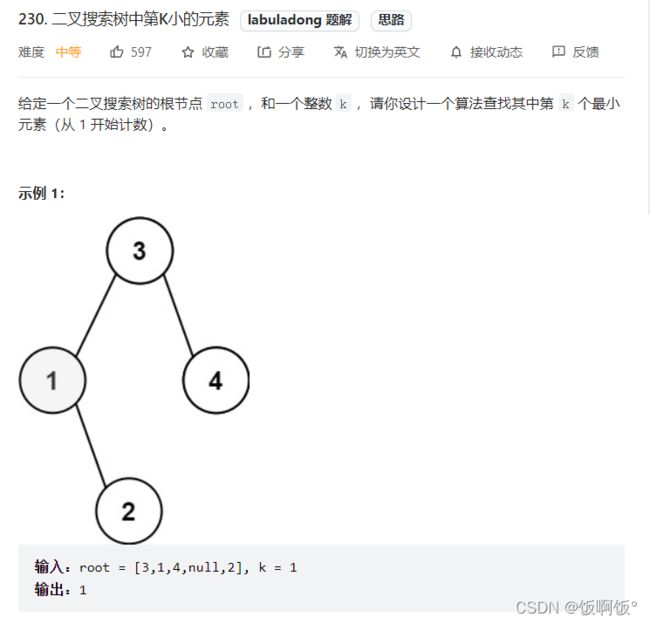
解题思路是先中序遍历输出节点,再找到第K个数,其实并不用全部输出,只要输出到第K个就可以return了.
var kthSmallest = function(root, k) {
res = 0
count = 0
traverse(root,k)
return res
};
var traverse = function(root,k){
if(root === null){
return;
}
traverse(root.left,k)
count++
if(count == k){
res = root.val
return
}
traverse(root.right,k)
}
2. 力扣538/1038题:把二叉搜索树转换为累加树(中等)
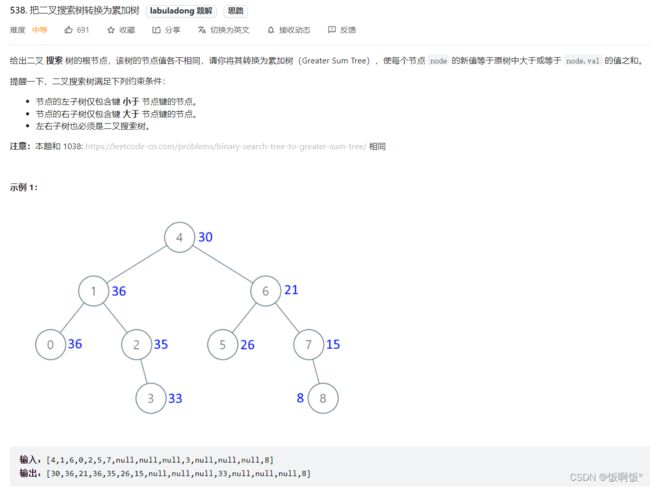
- 二叉搜索数的中序遍历(左中右)是升序的数组,如果按照右中左的顺序来遍历就是降序的,也是本题需要的,因为本题中右边的数最小,应该是最先更改的.
- 代码
var convertBST = function(root) {
count = 0
traverse(root)
return root
};
var traverse = function(root){
if(root === null){
return;
}
traverse(root.right)
count += root.val
root.val = count
traverse(root.left)
}
九、二叉搜索树基操篇
1. 力扣700题:二叉搜索树中的搜索(简单)

代码比较简单,直接利用BST的特性即可写出.
var searchBST = function(root, val) {
if(root == null){
return null
}
if(root.val === val){
return root
}else if(root.val > val){
return searchBST(root.left,val)
}else if(root.val < val){
return searchBST(root.right,val)
}
};
2. 力扣450题:删除二叉搜索树中的节点(中等)
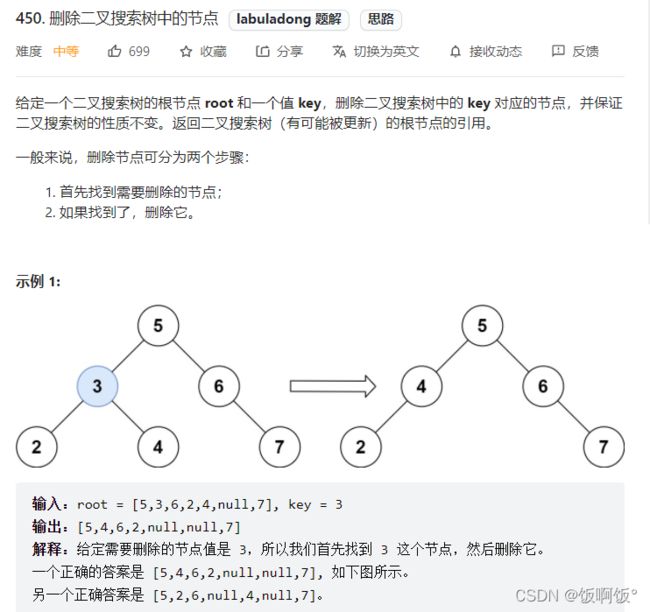
删除二叉搜索树中的节点主要有三种情况:
- 要删除的是根节点,那么直接删除就可以了
- 要删除的节点只有左或右节点,这样可以直接删除节点,然后存在的节点补上
- 要删除的节点左右节点都有,那么要先删除右子树中最小的节点,并把这个节点移动在要删除的节点位置上
需要单独定义一个函数来寻找右子树的最小节点,其实就是寻找右子树的最左节点.
var deleteNode = function(root, key) {
if(root === null){
return null;
}
if(root.val === key){
if(root.left === null) return root.right
if(root.right === null) return root.left
var minNode = new TreeNode()
minNode = getMinNode(root.right)
root.right = deleteNode(root.right,minNode.val)
minNode.left = root.left
minNode.right = root.right
root = minNode
}else if(root.val > key){
root.left = deleteNode(root.left,key)
}else if(root.val < key){
root.right = deleteNode(root.right,key)
}
return root
};
var getMinNode = function(node){
while(node.left != null) node = node.left
return node
}
3. 力扣701题:二叉搜索树的插入操作(中等)
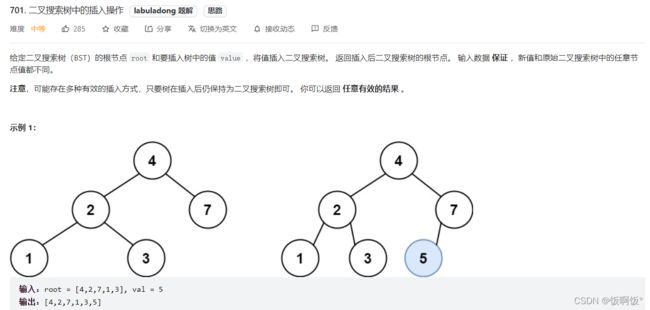
通过左右的数值判断来寻找插入的位置,最简单的方法就是作为叶子节点插入,插入的操作在递归到root为空的时候插入.
var insertIntoBST = function(root, val) {
if(root === null){
var newNode = new TreeNode(val)
return newNode
}
if(root.val > val){
root.left = insertIntoBST(root.left,val)
}else if(root.val < val){
root.right = insertIntoBST(root.right,val)
}
return root
};
4. 力扣98题:验证二叉搜索树(中等)
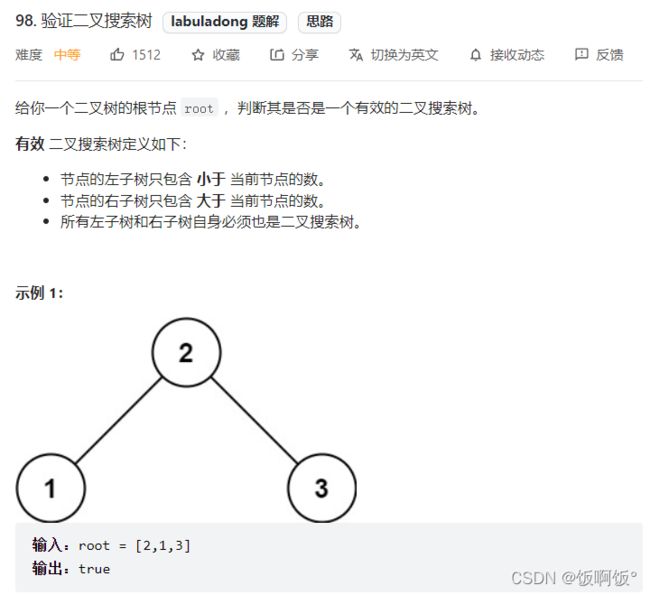
虽然二叉搜索树的特性是左节点<根节点<右节点,但如果只凭借这一条判断二叉搜索树的话是不够的,比如labuladong中就给出以下情况

出现的问题在于:对于每个节点root,代码检查了它的左右孩子节点是否符合左小右大的原则,但是BST的整个左子树都要小于根节点,整个右子树都要大于根节点.由此写出代码
var isValidBST = function(root) {
return validBST(root,null,null)
};
var validBST = function(root,min,max){
if(root === null) return true
if(min != null && root.val <= min) return false
if(max != null && root.val >= max) return false
return validBST(root.left,min,root.val) && validBST(root.right,root.val,max)
}
十、二叉搜索树构造篇
1. 力扣96题:不同的二叉搜索树(中等)

如果单纯的问,以1-5为根节点的二叉搜索树有多少个,答案是5个,原因是每一个节点都可以作为搜索树的根节点,如果根节点是3了,左子树是1,2;右子树是4,5;那么以3位根节点的情况就是2*2,因此可以类推出所有情况。
var numTrees = function(n) {
memo = new Array(); //用来记录相同情况的备忘录
for(var i=0;i<n+1;i++){ //一维长度为n+1
memo[i] = new Array();
for(var j=0;j<n+1;j++){ //二维长度为n+1
memo[i][j] = 0;
}
}
return count(1,n)
};
var count = function(lo,hi){
if(lo>hi){
return 1
}
if(memo[lo][hi] != 0){
return memo[lo][hi]
}
var res = 0
for(var i=lo;i<=hi;i++){
var left = count(lo,i-1)
var right = count(i+1,hi)
res += left*right
}
memo[lo][hi] = res
console.log(memo)
return res
}
2. 力扣95题:不同的二叉搜索树Ⅱ(中等)

要把上一题计算个数的步骤改成穷举情况,因此用到的for还有点多。
var generateTrees = function(n) {
if(n ==0) return []
return build(1,n)
};
var build = function(lo,hi){
var arr = []
if(lo>hi){
arr.push(null)
return arr
}
//穷举 root节点的所有可能
for(var i=lo;i<=hi;i++){
//递归构造出左右子树的所有合法BST
var leftTree = build(lo,i-1)
var rightTree = build(i+1,hi)
//给root节点穷举所有子树的组合
for(let left of leftTree){
for(let right of rightTree){
var root = new TreeNode(i,left,right)
arr.push(root)
}
}
}
return arr
}
十一、美团面试官:你对后序遍历一无所知
1. 力扣1373题:二叉搜索子树的最大键值和(困难)

解决这个问题有三个要考虑的问题:
(1)左右子树是不是BST,可以用一个标志位来表示
(2)左右子树加上根节点后还是不是BST,判断方式就是,root.val > left.max && root.val < right.min
(3)记录节点和,随时替换成最大的。
var maxSumBST = function(root) {
maxSum = 0
sumBST(root)
return maxSum
};
var sumBST = function(root){
if(root == null){
var res = [1,Infinity,-Infinity,0]
return res
}
var left = sumBST(root.left)
var right = sumBST(root.right)
var res = []
if(left[0] == 1 && right[0] == 1 && root.val > left[2] && root.val < right[1]){
res[0] = 1
res[1] = Math.min(root.val,left[1])
res[2] = Math.max(root.val,right[2])
res[3] = left[3]+right[3]+root.val
maxSum = Math.max(maxSum,res[3])
}else{
res[0] = 0
}
return res
}
注意:var res = [1,Infinity,-Infinity,0]这里不能使用Number,MAX_VALUE和Number,MIN_VALUE,没有包括负数的情况.
十二、 Git原理之最近公共祖先
Git原理:其实这个题和git的内部原理没啥关系,只是借鉴了git 如何合并两条分支并检测冲突的过程,最先的一步就是找到这两条分支的最近公共祖先LCA。
1. 力扣236题:二叉树的最近公共祖先(中等)
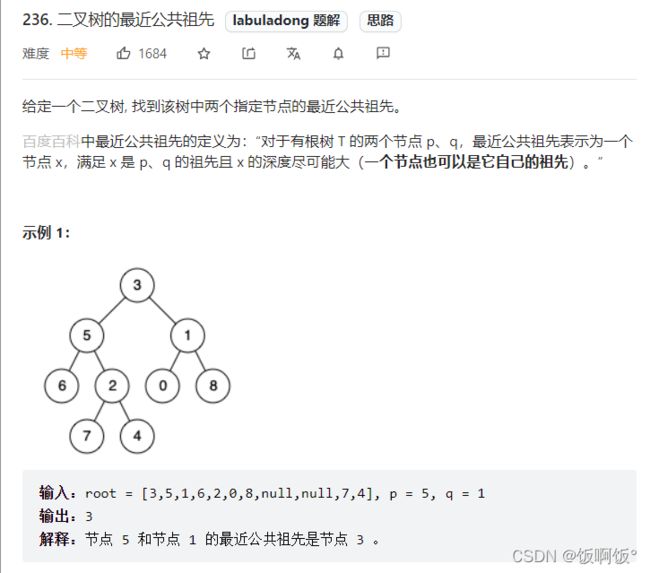
- 首先我们先不管查找两个数字,我们先考虑只找一个数,
var find = function(root,x){
if(root == null) return null
// 前序位置: 查看当前节点是不是要找的
if(root.val == x) return root
// 去左子树找
var left = find(root.left,x)
if(left != null) return left
// 中序位置:去右子树找
var right = find(root.right,x)
if(right != null) return right
// 实在找不到
return null
}
如果把return的位置改成后序呢
var find = function(root,x){
if(root == null) return null
// 前序位置: 查看当前节点是不是要找的
if(root.val == x) return root
// 去左子树找
var left = find(root.left,x)
var right = find(root.right,x)
//看看哪边找到了
return left !=null?left:right
}
- 本题的区别除了要查找两个数以外,返回的值也不是本身,而是它的root。
var lowestCommonAncestor = function(root, p, q) {
if(root == null){
return null
}
if(root == p || root == q){
return root
}
var left = lowestCommonAncestor(root.left,p,q)
var right = lowestCommonAncestor(root.right,p,q)
if(left != null && right != null){
return root
}
return left==null?right:left
};
2. 力扣235题:二叉搜索树的最近公共祖先(简单)
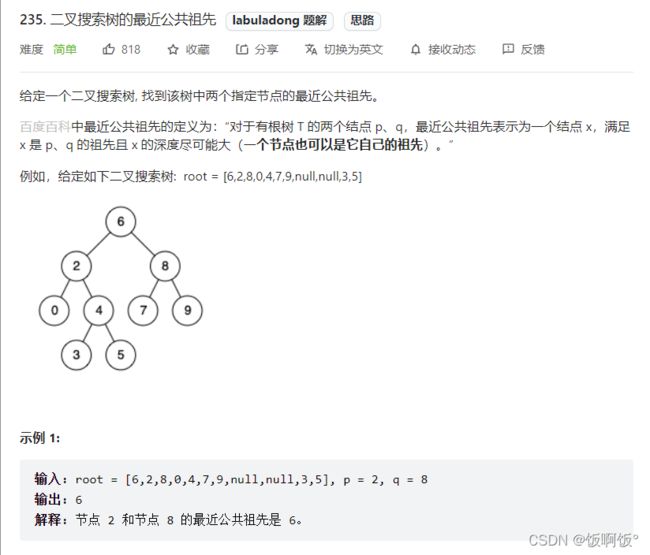
和上题同理,代码也相同。
var lowestCommonAncestor = function(root, p, q) {
if(root == null) return null
if(root == p || root == q) return root
var left = lowestCommonAncestor(root.left,p,q)
var right = lowestCommonAncestor(root.right,p,q)
if(left != null && right != null) return root
return left!=null?left:right
};
十三、如何计算完全二叉树的节点数
首先要区分完全二叉树和满二叉树,为了方便,直接引用[labuladong]的图片解释:
完全二叉树如下图,每一层都是紧凑靠左排列的:

满二叉树如下图,是一种特殊的完全二叉树,每层都是是满的,像一个稳定的三角形:

1. 力扣222题:完全二叉树的节点个数(中等)

- 普通的二叉树计算节点数的方法是
var countNodes = function(root){
if(root == null) return 0
return 1+countNodes(root.left)+countNodes(root.right)
}
- 满二叉树计算节点数的方法是
var countNodes = function(root)
var h = 0;
while(root != null){
root = root.left
h++
}
return Math.map(2,h)-1
}
- 本题可以先判断完全二叉树是不是满二叉树,如果是,就用公式算,如果不是,就用递归算
var countNodes = function(root) {
var l = root,r = root
let lh = 0,rh = 0
while(l!=null){
l = l.left
lh++
}
while(r!=null){
r = r.right
rh++
}
if(lh == rh){
return Math.pow(2,lh)-1
}
else{
return 1+countNodes(root.left)+countNodes(root.right)
}
}