033、微调
之——高级炼丹术
目录
之——高级炼丹术
杂谈
正文
1.标注数据集是很贵的
2.微调的思想
3.尝试
小结
杂谈
微调(Fine-tuning)是深度学习中的一种常见策略,它通常用于预训练模型在特定任务上的性能提升。微调的过程涉及在一个已经在大规模数据上进行了预训练的模型的基础上,通过使用目标任务的相关数据集进行进一步训练。
一般的微调步骤如下:
-
预训练阶段: 在大规模的数据集上,使用一个深度学习模型进行预训练。这个数据集通常是非常庞大的,例如ImageNet包含数百万张图像。
-
微调阶段: 将预训练的模型应用于特定的任务,使用与该任务相关的小型数据集进行微调。这个小型数据集可能是与任务密切相关的领域或者任务本身的数据。
-
模型调整: 在微调阶段,可以调整模型的一些超参数,如学习率、优化器等,以适应特定任务的要求。
微调的一个常见应用是使用在大规模图像分类任务上预训练的模型,然后在较小的数据集上微调以进行特定任务,比如医学图像分类或自定义的图像分类任务。应用迁移学习(transfer learning)将从源数据集学到的知识迁移到目标数据集。
正文
1.标注数据集是很贵的
大的公开数据集花销很大,而且强调泛化性,并不强调特定任务,而自己实际情况下的任务需求一般来说没有这么大的数据集,所以我们一般使用在公开数据集上预训练的模型拓展到我们自己的任务需求上。
2.微调的思想
-
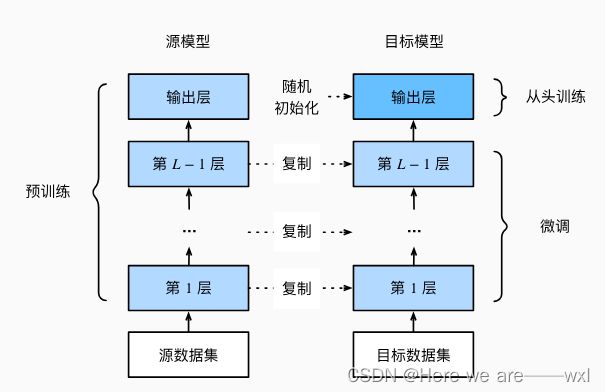
在源数据集(例如ImageNet数据集)上预训练神经网络模型,即源模型。
-
创建一个新的神经网络模型,即目标模型。这将复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。我们还假设源模型的输出层与源数据集的标签密切相关;因此不在目标模型中使用该层。
-
向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
-
在目标数据集(如椅子数据集)上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。
训练:

一些技巧:
神经网络越接近度量层输出层越是与数据集相关,而底层的则更加通用,固定底层的一些细节去优化语义是更有效率的选择,因为底层的通用特征是通过大数据集预训练出来的,是有很高质量的。

3.尝试
下载数据集并查看:
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
#下载hotdog数据集
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip',
'fba480ffa8aa7e0febbb511d181409f899b9baa5')
data_dir = d2l.download_extract('hotdog')
#%%
#读入数据集
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
#展示
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4)数据增广:
#数据增广
# 使用RGB通道的均值和标准差,以标准化每个通道
# imagenet做了这个事情,所以等搬过来,参数来自imagenet
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomVerticalFlip(),
torchvision.transforms.ToTensor(),
normalize])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize([256, 256]),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])
导入预训练数据集,修改输出层:
#%%
#查看预训练好的模型
pretrained_net = torchvision.models.resnet18(pretrained=True)
pretrained_net.fc
#%%
#由于我们的类别不一样,所以我们考虑copy预训练但改变最后的输出层
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight)
finetune_net.fc
训练:
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
#别的层不变,最后一层10倍学习率
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
#%%
#较小的学习率,通过微调预训练获得的模型参数
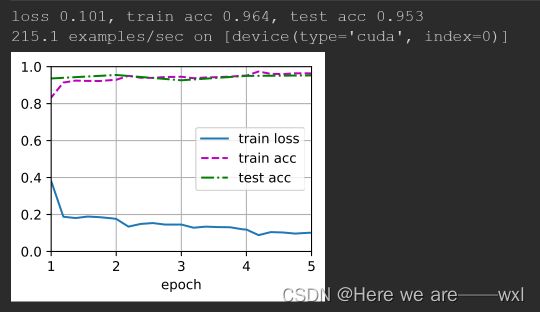
train_fine_tuning(finetune_net, 5e-5)结果:
有预训练的5个epoch:
没有预训练的:
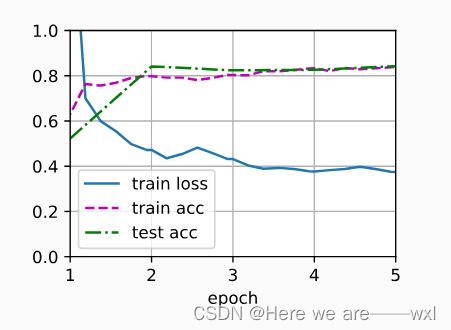
可见明显差别。
小结
-
迁移学习将从源数据集中学到的知识迁移到目标数据集,微调是迁移学习的常见技巧。
-
除输出层外,目标模型从源模型中复制所有模型设计及其参数,并根据目标数据集对这些参数进行微调。但是,目标模型的输出层需要从头开始训练。
-
通常,微调参数使用较小的学习率,而从头开始训练输出层可以使用更大的学习率。