索引的创建和设计原则
文章目录
- 1. 索引的声明与使用
-
- 1.1 索引的分类
- 1.2 创建索引
- 2. MySQL8.0索引新特性
-
- 2.1 支持降序索引
- 2.2 隐藏索引
- 3 哪些情况适合创建索引?
-
- 3.1 字段的数值有唯一性的限制
- 3.2 频繁作为 WHERE 查询条件的字段
- 3.3 经常 GROUP BY 和 ORDER BY 的列
- 3.4 UPDATE、DELETE 的 WHERE 条件列(删改操作的where条件)
- 3.5 DISTINCT 字段需要创建索引
- 3.6 多表 JOIN 连接操作时,创建索引注意事项
- 3.7 使用列的类型小的创建索引
- 3.8 使用字符串前缀创建索引
- 3.9 区分度高(散列性高)的列适合作为索引
- 3.10 使用最频繁的列放到联合索引的左侧
- 3.11 在多个字段都要创建索引的情况下,联合索引优于单值索引
- 4. 使用索引注意点
- 5. 哪些情况不适合创建索引
-
- 5.1 在where中使用不到的字段,不要设置索引
- 5.2 数据量小的表最好不要使用索引
- 5.3 有大量重复数据的列上不要建立索引
- 5.4 避免对经常更新的表创建过多的索引
- 5.5 不建议用无序的值作为索引
- 5.6 删除不再使用或者很少使用的索引
- 5.7 不要定义冗余或重复的索引
1. 索引的声明与使用
1.1 索引的分类
MySQL的索引包括:普通索引、唯一索引、主键索引、联合索引
1.2 创建索引
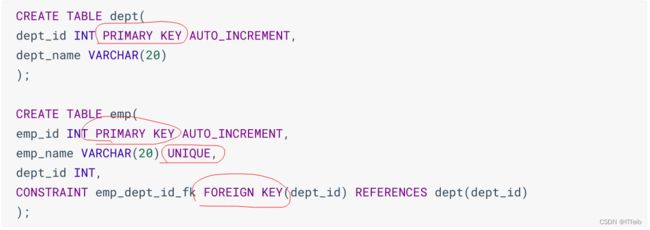
在已经存在的表上创建索引:

删除索引:
- 提示 删除表中的列时,如果要删除的列为索引的组成部分,则该列也会从索引中删除。如果组成索引的所有列都被删除,则整个索引将被删除。
2. MySQL8.0索引新特性
2.1 支持降序索引


- 降序索引对我们比如说orderby desc来说,按照降序组织的索引在roderby时候,所要查的这些记录都是在一块的(在附近的),一个页中的记录是按单链表组织的,那么这个局部性会提高查询效率。
2.2 隐藏索引
在MySQL 5.7版本及之前,只能通过显式的方式删除索引。此时,如果发现删除索引后出现错误,又只能通过显式创建索引的方式将删除的索引创建回来。如果数据表中的数据量非常大,或者数据表本身比较大,这种操作就会消耗系统过多的资源,操作成本非常高。
从MySQL 8.x开始支持 隐藏索引(invisible indexes) ,只需要将待删除的索引设置为隐藏索引,使查询优化器不再使用这个索引,确认将索引设置为隐藏索引后系统不受任何响应,就可以彻底删除索引。 这种通过先将索引设置为隐藏索引,再删除索引的方式就是软删除
创建表时直接创建:
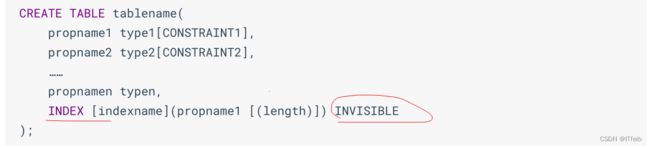
在已经存在的表上创建:

通过ALTER TABLE语句创建:

切换索引可见状态:已存在的索引可通过如下语句切换可见状态:

- 注意 当索引被隐藏时,它的内容
仍然是和正常索引一样实时更新的。如果一个索引需要长期被隐藏,那么可以将其删除,因为索引的存在会影响插入、更新和删除的性能。增删改
3 哪些情况适合创建索引?
3.1 字段的数值有唯一性的限制

3.2 频繁作为 WHERE 查询条件的字段
某个字段在SELECT语句的 WHERE 条件中经常被使用到,那么就需要给这个字段创建索引了。尤其是在数据量大的情况下,创建普通索引就可以大幅提升数据查询的效率。
3.3 经常 GROUP BY 和 ORDER BY 的列
索引就是让数据按照某种顺序进行存储或检索,因此当我们使用 GROUP BY 对数据进行分组查询,或者使用 ORDER BY 对数据进行排序的时候,就需要 对分组或者排序的字段进行索引 。如果待排序的列有多个,那么可以在这些列上建立 组合索引 。
结论:
- 如果单独用GROUP BY,就针对对应字段建立索引,若对多个字段进行GROUP BY,可以建立联合索引。
- 如果既有GROUP BY又有ORDER BY可以考虑联合索引,此联合索引中要把GROUP BY 的字段写在前面,ORDER BY的字段写在后面,且8.0中若是降序的话加上DESC后效果更好
3.4 UPDATE、DELETE 的 WHERE 条件列(删改操作的where条件)
对数据按照某个条件先进行查询后再进行 UPDATE 或 DELETE 的操作,如果对 WHERE 字段创建了索引,就能大幅提升效率。原理是因为我们需要先根据 WHERE 条件列检索出来这条记录,然后再对它进行更新或删除。如果进行更新的时候,更新的字段是非索引字段,提升的效率会更明显,这是因为非索引字段更新不需要对索引进行维护
3.5 DISTINCT 字段需要创建索引
![]()
对student_id字段加索引后,SQL 查询效率有了提升,同时显示出来的 student_id 还是按照 递增的顺序 进行展示的。这是因为索引会对数据按照某种顺序进行排序,所以在去重的时候也会快很多
3.6 多表 JOIN 连接操作时,创建索引注意事项

- 首先, 连接表的数量尽量不要超过
3 张,因为每增加一张表就相当于增加了一次嵌套的循环,数量级增长会非常快,严重影响查询的效率。 - 对 WHERE 条件创建索引 ,因为 WHERE 才是对数据条件的过滤。如果在数据量非常大的情况下,没有 WHERE 条件过滤是非常可怕的。
- 最后, 对用于连接的字段创建索引 ,并且该字段在多张表中的 类型必须一致 。比如 course_id 在student_info 表和 course 表中都为 int(11) 类型,而不能一个为 int 另一个为 varchar 类型。
3.7 使用列的类型小的创建索引
- 数据类型越小,在
查询时进行的比较操作越快 - 数据类型越小,索引占用的
存储空间就越少,在一个数据页内就可以放下更多的记录,从而减少磁盘I/O带来的性能损耗,也就意味着可以把更多的数据页缓存在内存中,从而加快读写效率
这个建议对于表的主键来说更加适用,因为不仅是聚簇索引中会存储主键值,其他所有的二级索引的节点处都会存储一份记录的主键值,如果主键使用更小的数据类型,也就意味着节省更多的存储空间和更高效的I/O
3.8 使用字符串前缀创建索引
假设字符串很长,那存储一个字符串就需要占用很大的存储空间。在需要为这个字符串列建立索引时,那就意味若在对应的B+树中有这么两个问题:
- B+树索引中的
记录需要把该列的完整字符串存储起来,更费时。而且字符串越长,在索引中占用的存储空间越大。 - 如果B+树索引中索引列存储的字符串很长,那在做
字符串比较时会占用更多的时间。
我们可以通过截取字段的前面一部分内容建立索引,这个就叫前缀索引。
这样在查找记录时虽然不能精确的定位到记录的位置,但是能定位到相应前缀所在的位置,然后根据前缀相同的记录的主键值回表查询完整的字符串值。既节约空间,又减少了字符串的比较时间,还大体能解决排序的问题。
问题是,截取多少呢?截取得多了,达不到节省索引存储空间的目的;截取得少了,重复内容太多

拓展:Alibaba《Java开发手册》
[强制]:在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。
说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为20的索引,区分度会 高达90% 以上 ,可以使用 count(distinct left(列名, 索引长度))/count(*)的区分度来确定。
3.9 区分度高(散列性高)的列适合作为索引
比如age字段就不适合做索引,男女比例1:1,建立索引有一半的数据重复
3.10 使用最频繁的列放到联合索引的左侧
这样也可以较少的建立一些索引。同时,由于"最左前缀原则",可以增加联合索引的使用率
3.11 在多个字段都要创建索引的情况下,联合索引优于单值索引
4. 使用索引注意点
要限制每张表上的索引数目,建议单张表索引数量不超过6个,原因:
- 每个索引都需要
占用磁盘空间,索引越多,需要的磁盘空间就人。 - 索引会影响
INSERT、DELETE、UPDATE等语句的性能(增删改),因为表中的数据更改的同时,索引也会进行调整和更新,会造成负担。 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,会增加MySQL优化器生成执行计划时间,降低查询性能。
5. 哪些情况不适合创建索引
5.1 在where中使用不到的字段,不要设置索引
WHERE条件(包括GROUP BY、ORDER BY)里用不到的字段不需要创建索引,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的
5.2 数据量小的表最好不要使用索引
如果表记录太少,比如少于1000个,那么是不需要创建索引的。表记录太少,是否创建索引对查询效率的影响并不大。甚至说,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果。
5.3 有大量重复数据的列上不要建立索引
比如在学生表的“性别”字段上只有“男”与"女"两个不同值,因此无须建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度。
5.4 避免对经常更新的表创建过多的索引
- 频繁更新的
字段不一定要创建索引。因为更新数据的时候,也需要更新索引,如果索引太多,在更新索引的时候也会造成负担,从而影响效率。 - 避免对经常更新的
表创建过多的索引,并且索引中的列尽可能少。此时,虽然提高了查询速度,同时却会降低更新表的速度。
5.5 不建议用无序的值作为索引
索引是无序的,插入时可能造成页分裂,因为插入位置是不固定的,如果是自增id的话基本都是在树右边插入,无序key的话,插入很可能在之前的位置,造成页分裂。
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
5.6 删除不再使用或者很少使用的索引
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响
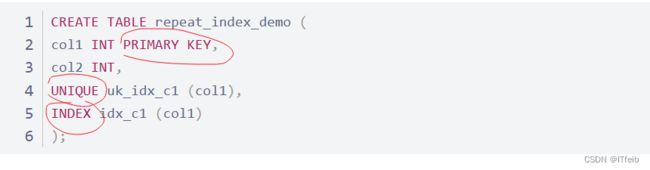
5.7 不要定义冗余或重复的索引
冗余索引:
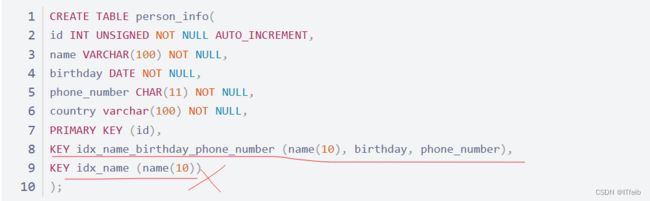
重复索引: