大模型产业落地关键战打响!百度首发行业大模型,外加一口气十连发
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
1、2、3、4、5、6、7、8、9、10……
谁能想到,在现如今大模型当道的节点上,别家都是一次发布一个或几个。
百度呢?
一口气,10个!

如果把它们归拢归拢,打开方式是这样的,主要涵盖三大类:
基础大模型
任务大模型
行业大模型
值得一提的是,“行业大模型”是属于业界首发的那种。
然后百度还说了,“好马得配好鞍”啊。
于是乎,为了能让开发者使用大模型时用得舒服,顺便推出了一系列开发套件、大模型API、开放平台。
还为了让开发者们基于大模型迸发更多富有想象力的新事物,打造了一个新社区——旸谷大模型创意与探索社区。
而作为支撑大模型的底座,位居中国深度学习平台综合市场份额第一的飞桨,也迎来了六个方面的全新升级。
这就是在每年约定俗成的深度学习开发者盛会——WaveSummit 2022中,百度提交的最新“AI大作业”。
除此之外,纵观整场发布会,百度提及的两个关键词显得格外醒目:
一个是“AI越来越普惠”;另一个是“大模型产业落地关键年”。

△ 百度首席技术官,王海峰
通俗点来说,可以理解为把AI门槛降下去(降维),让强模型用起来(出击)。
那么百度真的让“用AI”这事,变得够easy了吗?
以“难用”著称的大模型,今年要在产业落地的解法又该是什么?

△ 百度集团副总裁,吴甜
我们不妨一同来看一看。
时隔半年,大模型要规模化“上岗”
说起搞大模型这事,早在去年12月份,飞桨便有过一次大动作。
当时发布的是全球第一个千亿级知识增强大模型——鹏城-百度·文心大模型(下文简称“文心大模型”),参数量达到了2600亿之多。
而此次时隔仅半年再发的10个大模型,正是基于此。

对比着来看,“基础通用大模型”和“任务大模型”有8个新的大模型上线:
例如:
NLP大模型
新增了ERNIE 3.0 Zeus,它是一个任务知识增强千亿级大模型。
可以使用统一的接口和方式同时处理各类应用任务,包括开放问答、信息抽取、情感分析、语义匹配等。

跨模态大模型
ERNIE-SAT,语音-语言跨模态大模型。在预训练过程中将中英双语对应的音素作为输入,让模型学习不同语言间音素的对齐以及语言与语音的对齐,同时对语言和语音做联合掩码学习。
ERNIE-GeoL,地理-语言跨模态大模型。有了它,像搜索“北京西火车站”这样不规范词语时,可以理想地对应到真实地理坐标上的“北京西站”(已经用在了百度地图)。

CV大模型
VIMER-UFO 2.0,参数规模170亿,是业界规模最大的多任务统一视觉大模型。
它的一大特点,是在训练的时候可以把多个任务放到一起来联合学习,例如可以同时完成机动车、非机动车、行人等特征的提取。

VIMER-UMS,可以通过融合编码来学习图像及其相应文字的统一表征(已经用到了商品搜索)。
VIMER-StrucTexT 2.0,可以融合学习“语义”和“结构”信息,支持文档图像理解的全场景任务。
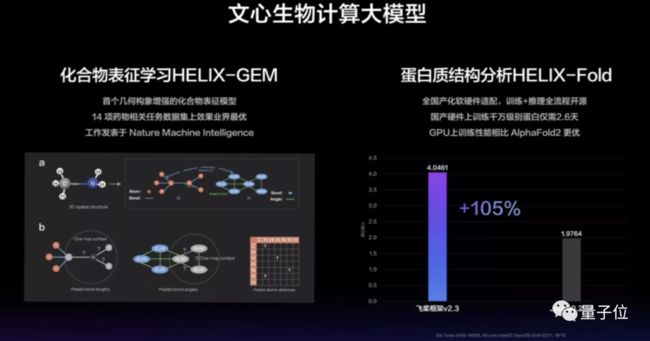
生物计算大模型
HELIX-GEM,是融合了几何级别的自监督学习策略,学习化合物键长、键角等空间结构知识,提升化合物性质预测的效果(例如提升药物筛选成功率)。
HELIX-Fold,是蛋白结构分析大模型,在国产DCU环境,可以将千万级别蛋白的训练时间从AlphaFold2的7天缩短到2.6天。
从上面的大模型不难看出,飞桨文心大模型一个非常明显的标签便是“知识增强”。
这就使得文心大模型不仅拥有解决基础问题的能力,在面对专有任务问题时,也能处理得游刃有余。
而除了8个扩充之外,文心大模型还多了2个“新增”——行业大模型。

具体来说,包括联合国家电网研发的知识增强的能源行业NLP大模型国网-百度·文心,以及联合浦发银行研发的知识增强的金融行业NLP大模型浦发-百度·文心。也正如刚才所述,这是业内史无前例的行业大模型。
行业大模型也是先基于文心大模型的通用能力,来挖掘相关行业中的知识;而后再结合实际行业特色的数据和知识,进行大规模无监督的联合训练。
而且在算法层面上,团队针对不同行业领域设计了具有特色的算法,这就让训练后的行业大模型能够更好的解决实际场景中的“疑难杂症”。
可以说,百度已经找到了大模型应用产业落地的关窍。
用吴甜的话来讲:
大模型如果能学习到行业特有数据和知识,会更接近于行业场景的需要,有利于大规模产业落地。
例如在保险行业这个真实场景中,一个老大难的问题便是合同数量庞大且重要。
但在行业大模型能力的加持之下,保险公司可以合同中的条款文本进行自动解析识别,关键信息的维度可以高达39个。
如此能力之下,业务的效率也是猛增,以前一份合同人工处理要花上30分钟的时间,而现在仅需1分钟!
这也更加印证了飞桨文心大模型“知识增强”标签之外的另一个特点——“产业级”。
除此之外,不难看出此次这10个新大模型具有一个共性,那便是都基于文心大模型的通用性。
颇有一种“一生二,二生三,三生万物”的感觉了。
但百度飞桨要做的可不只是打造大模型这么简单,他们还要让大模型用着方便。
就像我们刚才提到的“好马配好鞍”,在这方面,百度飞桨所提出的是一套工具平台:
大模型开发套件
大模型API服务
开发平台EasyDL和BML
据了解,开发平台EasyDL和BML能够涵盖30000多个任务,并且可以让数据标注量平均下降70%、效果平均提升10.7%。
这就让开发者在不挑算法能力的情况下,就可以“丝滑”地去用文心大模型。

值得一提的是,与飞桨虽“异曲”却“同工”的文心大模型,也是共享飞桨生态的升级,同步发布了一个生态系统——旸谷大模型创意与探索社区。
(旸谷在古书、神话中是指“日出的地方”。)
在这个社区里,开发者可以通过大模型的创意产品,擦碰出更多富有想象力的新事物。
……
而细品百度飞桨这一波操作之后,不难提炼出“量产”、“易用”这两个关键词。
由此,百度飞桨大模型“上岗”的路径也逐步明朗了起来——开始构建并走向规模化生产和产业级应用。
但要走好这条路,单是在文心大模型上发力还是不够的,还需要它背后关键的支撑点,飞桨。
飞桨:我最懂中国AI场景
百度飞桨作为一个深度学习平台,虽与文心大模型“异曲”,但从出发点和目标来看,却又有着“同工”之妙——加速AI的落地。
为此,在今年的Wave Summit峰会中,飞桨也由内到外地来了个六大全新发布。其中特别亮眼的,当属飞桨与硬件伙伴进一步深化合作、全面共创,推出了飞桨硬件生态共创计划。
同样也是“归拢归拢”着来看,飞桨全新发布可以分为三大类,分别是技术、场景和生态。
首先是飞桨框架升级到了2.3版本,在开发、训练、推理部署全面升级,提升深度定制开发和自动化能力。

这是在技术层面上的能力提升,也是飞桨每年在WaveSummit上必秀的一块肌肉。
而与往年有所不同之处的是,它在场景层面上还喊出了“最懂中国AI场景”的口号。
为此,百度飞桨先是发布了一张训推一体导航图。
这张导航图是基于去年发布的推理部署导航图升级而来,目的就是为AI 产业应用落地提供从开发、训练到推理部署的全流程智能导航。
其次,百度飞桨推出了一个产业模型选型工具。有了它,就有一种“妈妈再也不用担心我选模型了”的感觉。
因为产业模型选择工具,是飞桨长期在产业长期“打拼”所总结的经验心得,还手把手教你的那种。
紧接着,飞桨还把产业级模型库做了开源。
这个模型库包含超过500个开源算法,而且以产业场景出发,能够在性能和精度做到平衡的特色模型,也从原先的13个增添到了23个。
在更聚焦的赛道上,飞桨在已有的量桨(量子机器学习)、螺旋桨(生物计算)基础上,还再添了一位新成员——PaddleScience赛桨。
赛桨是飞桨在面向AI for Science领域的全新发布,具备支持多领域多场景算例、算法和开发接口、端到端核心框架功能支持、广泛适配异构硬件四大优势。
而它的作用,依旧是为了加速加速前沿技术在产业中的应用落地。
为了让上述模型能够更方便地开发、部署和迭代,飞桨又推出了移动工作站。
只需预装飞桨EasyDL桌面版和智能边缘控制台,便可实现本地化开发和边端部署。
而在技术、场景之后,飞桨最后的一大升级,便是来自生态。
具体而言,包括三大“共创”计划,均是基于飞桨大航海计划2.0而来:
飞桨产业实践范例库共创计划:联合更多伙伴打造深度学习行业应用标杆,共享生态收益。
飞桨AI for Science共创计划:协同产学研合作伙伴打造AI for Science开源生态,推动科研创新与产业赋能。
飞桨硬件生态共创计划:从共聚、共研到共创,携手合作伙伴,软硬融合创新,共建繁荣硬件生态。
以上便是百度飞桨在Wave Summit 2022中的核心发布内容。
但随之而来的一个问题便是:
为什么非要把AI门槛降下去?
落地,落地,还是落地。
这也是从此次发布会中,能够感受到的最强信号。
但若是回溯到2019年那个最初的起点,将这三年的Wave Summit铺开来看,个中原因就会一目了然。
在第一届峰会中,百度CTO王海峰便提及:
深度学习正在推动人工智能进入工业大生产阶段。
王海峰当时认为,正因深度学习具备通用性,以及深度学习平台在不断发展,所以它们正在推动AI步入一种新的模式。
这种模式可以归结为“三化”,即标准化、自动化和规模化,这也就意味着人工智能在进入工业大生产阶段。
到了2020年,“企业版平台”被纳入到了飞桨的全景图之中,并且还发布了预训练模型的开发模式。
这也就迈出了通过预训练大模型来降低AI门槛的重要一步。
而在去年,吴甜在峰会中则是提出企业AI应用三阶段:AI先行者探路、AI工作坊应用、AI工业大生产。
并且针对每一个阶段分别阐述了企业将面临的困难和挑战,以及相应的解决方案。
与此同时,在同年的12月份,文心大模型也随之正式亮相。
……
从百度走了三年的这条路来看,一个大的BGM便是“AI工业大生产”,而主旋律可以说是“降低AI门槛、应用落地”。
而能够嫁接二者的“桥梁”,便是具备通用性质的人工智能技术。
正如历史中每一次的工业大革命,都是有通用技术的普及一样,例如机械技术、电气技术和信息技术。
而在人工智能时代的当下,这种信号也是越发的强烈:
深度学习技术:通用性越来越强
深度学习技术平台:标准化、自动化和模块化越来越显著
深度学习应用:产业智能化越来越广泛和深入
正如飞桨三年的观察那般,AI工业大生产已然如火如荼开展起来。
以文心大模型为例,目前已经在诸如保险、银行、农业、生物医药、工业、搜索,甚至是智能音箱等领域和场景中有所涉足,在提高垂直业务效率的道路上各显神通。
平台方面,据IDC的报告,飞桨已经取得了国内深度学习平台综合市场份额第一的成绩。
而且开发者社区已经凝聚477万开发者、服务18万个企业,并且已经创建56万个模型。
基于此,接下来的一步,就是要让人工智能技术更广泛地走进千行百业。
但以大模型为代表的人工智能通用技术,因为规模过大、算力需求过强等原因,长久以来一直成为开发者诟病之处。
那么这一局,又该如何破解?
吴甜在此次峰会中说“今年是大模型产业落地的关键年”,与此同时她也给出了一种“解法”:
要做好落地,需要解决的关键问题是,前沿的大模型技术如何与真实场景的方方面面要求相匹配。
而刚才我们提到的10个新大模型、1个配套工具平台和1个生态系统,正是此“解法”的具体内容:
首先,是建设更适配应用场景的模型体系,包含学习了足够多数据与知识的基础大模型,面向常见AI任务专门学习的任务大模型,以及引入行业特色数据和知识的行业大模型。
其次,是要有更有效的工具和方法论来让大模型发挥作用,充分考虑落地应用的全流程问题。
最后,是要有开放的生态,以生态促创新。
若是归结为一句话,或许可以是“框架打出去,模型用起来”。
以上便是百度飞桨为什么要致力于不断降低AI门槛的原因了。
值得一提的是,虽然此次百度飞桨“前无古人后无来者”地提出了行业大模型,但它并不是否定其它大模型厂商的分类模式。
这更像是站在传统大模型的基础上,为了让它更好地能被产业用起来,而提出的一种新范式。
……
那么最后,百度飞桨已经在大模型该如何“上岗”、人工智能在工业大生产阶段发展路径等问题上,交出了一份“AI大作业”。
你觉得值得参考吗?