企业实践课——基于自然语言处理的期刊文本分类
基于多种机器学习算法的期刊文摘文本分类
摘要: 本文主要通过机器学习的常规算法模型来对期刊文摘数据进行分析预测,期刊文摘的每一条数据都是一个文本数据,可以当作特征值,文摘类别就是数据的标签。通过已有数据进行文本分析,形成一个有效的训练模型来预测期刊文摘的类别。再结合词频统计绘制词云来找出不同期刊文摘类别的特征文字。
首先本文对期刊文摘数据进行了初步的探索,统计了每一种类别期刊的数据条数,经济类期刊的数据数量最多,达到了1601条,通信类的期刊数据条数最少,仅有27条。接着我们对期刊文摘的文本数据进行jieba中文分词。将文本数据的特征提取出来转换成用数字表示的词频矩阵,然后再用TF-IDF算法计算每个词在文章中的重要程度。把处理好的数据放入不同的模型中进行训练,然后根据预测准确率来判断模型的好坏。我们依次使用了,Naive Bayesian Model、KNN、Logistic Regression、SVM、XGBoost算法模型。其中XGBoost的预测准确率高达为96.43%,是本文中使用的所有机器学习模型中预测准确率最高的,SVM模型的预测准确率有91.68%,Logistic Regression模型的预测准确率有90.92%,Naive Bayesian Model模型的预测准确率有,KNN的准确率有87.89%。
在完成了基本要求的几种算法模型之后,我们又探索了一些要求中未提到的机器学习算法,例如Decision Tree、Random Forest、Etra Trees、AdaBoost、LightGBM、GDBT,这些模型的准确率在17%~97%之间波动,其中效果最好的是LightGBM模型,其准确率为96%,逼近XGBoost模型的训练效果,其他的算法准确率基本都在85%,但AdaBoost模型的准确率却出奇的低,初步分析可能是受到样本数据分布不均衡影响。
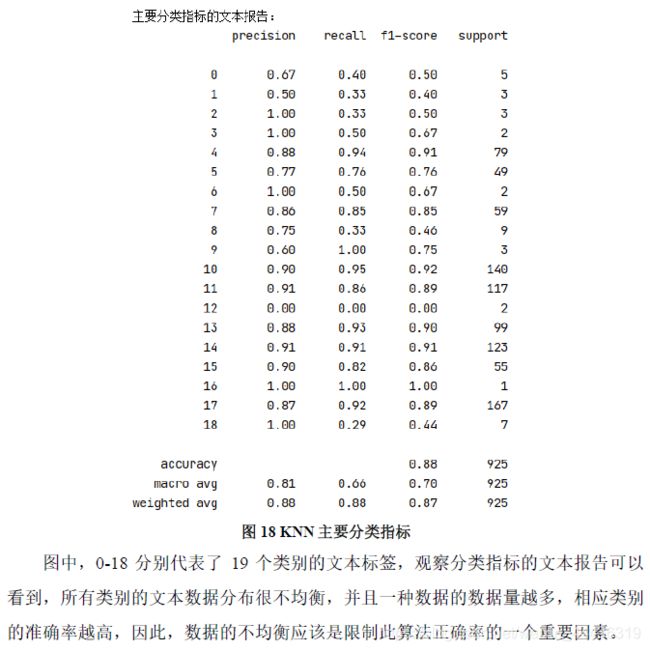
因为期刊文摘的不同类别数据分布很不均衡,导致了所有训练出来的分类器在预测经济、计算机等数据样本较多的期刊文摘类别时,预测准确率较高,普遍超过了90%,且有个别类别甚至接近100%,但是在预测交通、通信等样本数据偏少的类别时,预测的准确率十分低,严重的影响了整体的预测准确率。也正是如此我训练的所有模型的天花板就是在97%,只有在以后使用SMOTE过采样等解决数据样本不均衡的方法才有可能突破瓶颈,将整体的预测效果提高。
最后按照不同期刊文摘类别绘制出每个类别期刊的词云
关键词:中文分词,XGBoost,KNN,Logistic Regression,机器学习
图 目 录
图 1 原始数据集结构示意图
图 2 不同类别的期刊文摘数目统计图
图 3全概率公式示意图
图 4随机森林示意图
图5逻辑回归分布函数
图6 Level-Wise生长策略示意图
图7 Leaf-Wise生长策略演示
图8 AdaBoost算法演示步骤一
图9 AdaBoost算法演示步骤二
图 10 SVM分类示意图
图 11支持向量机模型评估
图 12支持向量机主要分类指标
图 13 支持向量机准确率5折交叉验证
图 14 XGboost 模型评估
图 15 XGBoost主要分类指标
图 16 XGBoost 准确率5折交叉验证
图 17 KNN模型评估
图 18 KNN主要分类指标
图 19 KNN 准确率5折交叉验证
图 20 Logistic Regression 模型评估
图 21 Logistic Regression 主要分类指标
图 22 逻辑回归准确率5折交叉验证
图 23 朴素贝叶斯模型评估
图 24 朴素贝叶斯 主要分类指标
图 25 朴素贝叶斯准确率5折交叉验证
图 26 Decision Tree模型评估
图 27 Decision Tree 主要分类指标
图 28 决策树准确率5折交叉验证
图 29 Random Forest模型评估
图 30 Random Forest 主要分类指标
图 31 随机森林准确率5折交叉验证
图 32 ETrees 模型评估
图 33 ETrees 主要分类指标
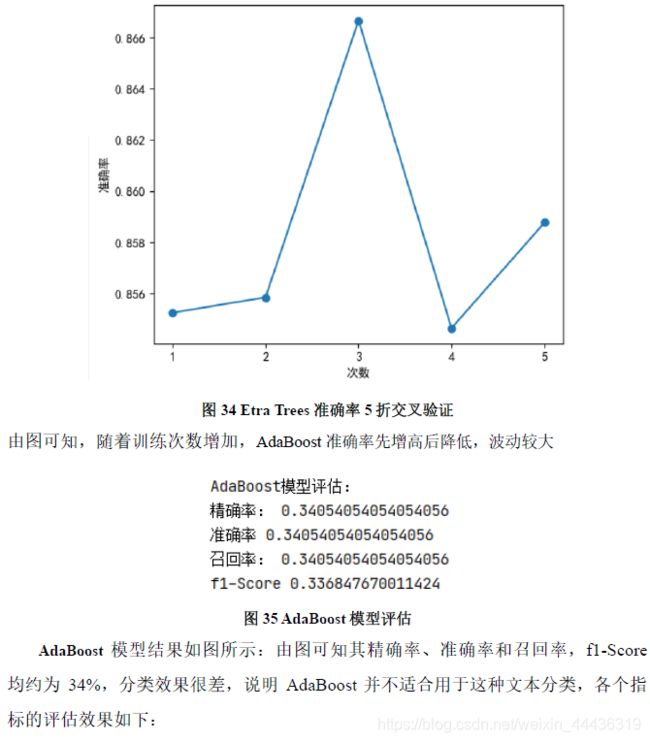
图 34 Etra Trees 准确率5折交叉验证
图 35 AdaBoost模型评估
图 36 AdaBoost 主要分类指标
图 37 AdaBoost 准确率5折交叉验证
图 38 LightGBM模型评估
图 39 LightGBM主要分类指标
图 40 LightGBM 准确率5折交叉验证
图 41 GDBT模型评估
图 42 GDBT主要分类指标
图 43 经济类期刊文摘词云
图 44 计算机类期刊文摘词云
图 45 法律类期刊文摘词云
图 46 环境类期刊文摘词云
图 47 交通类期刊文摘词云
图 48 教育类期刊文摘词云
图 49 空间类期刊文摘词云
图 50 矿藏类期刊文摘词云
图 51 历史类期刊文摘词云
图 52 能源类期刊文摘词云
图 53 农业类期刊文摘词云
图 54 时政类期刊文摘词云
图 55 体育类期刊文摘词云
图 56通信类期刊文摘词云
图 57 文学类期刊文摘词云
图 58 医疗类期刊文摘词云
图 59 艺术类期刊文摘词云
图 60 哲学类期刊文摘词云
问题介绍

二、小组成员分工

思路分析




四、方法概述






4.3 Decision Tree



4.4 Random Forest





4.5 Extra Trees


4.6 XGBoost



4.7 KNN

4.8 Logistic Regression




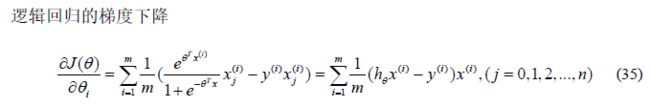

4.9 LightGBM

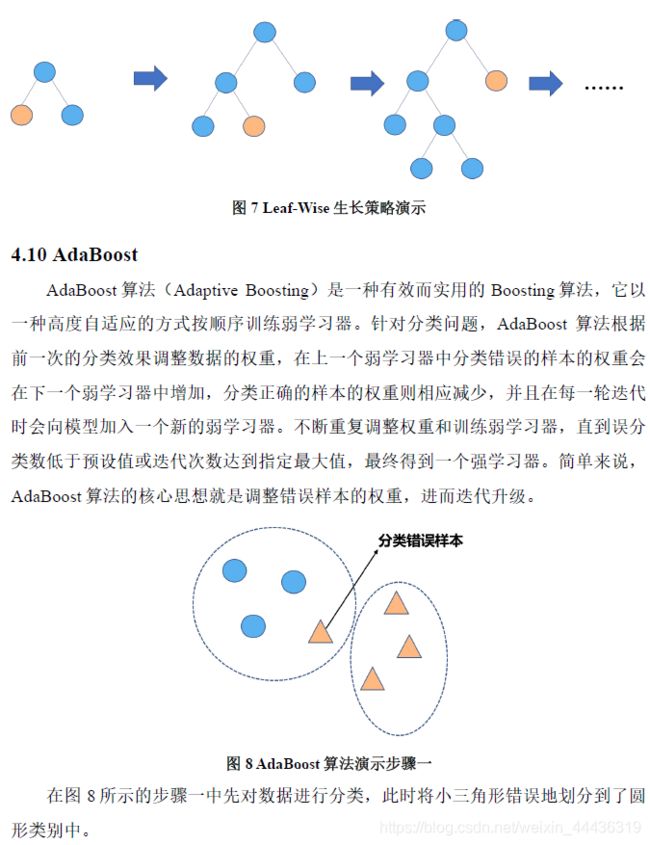



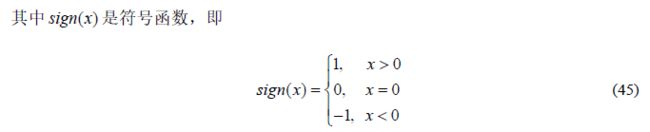
5. 3结果分析



5.4 不同模型训练评估结果截图



















5. 5 不同期刊文摘类别的词云图






六、总结
总结
本次项目是一个文本分类型数据分析项目,因为之前有做过类似的项目所以一上来真个流程都比较熟悉。
处理数据,分词这些环节都很顺畅,没有遇到什么问题,但是在去除停用词的时候却出现了问题。一开始是读取停用词的词库文件报错,当时我在停用词库文件里面大致浏览了一下,以为是个别符号的问题,就在百度里面找了一些其他来源的中文停用词库,比如百度的停用词库、哈工大的停用词库等,但是依然没能解决报错。后来在CSDN里面查到确实是因为停用词库里面的数据有个别的错误,需要在读取数据的时候设定相应的参数,让程序忽略读取文件时出现的个别错误。
解决了停用词库的问题以后,又接着卡在了去除停用词这个地方,换行符和空格无法完全去除干净。一直没有找到原因所在,后来进行特征提取的时候也并没有受到影响。
在特征提取环节我们试了两种不同的方法,第一种是TF-IDF算法,可以对全部数据使用,最后得到的模型训练效果较好。第二种方法词袋模型,如果使用全部数据就会出现内存溢出,即便是进行SVD降维也会出现内存溢出问题。而且词袋矩阵中有太多的无意义值,也就是0值,属于稀疏矩阵,有效存储并不大。所以后面的新算法探索阶段我们就直接放弃了词袋模型,直接使用TF-IDF算法进行特征提取。
在数据降维的时候一直出现报错,后来查了不少资料才得以解决。主要是因为调用降维函数的时候没有设定维度参数,所以引起了后面模型训练的错误。
在训练模型的时候,明显感觉到支持向量机的计算过程十分漫长,计算出来的准确率在91%上下波动,谈不上很好,但是也不算差。表现最好的就是XGBoost模型的训练效果,准确率巅峰值可以达到97%左右,而且计算的时间远少于支持向量机。
在项目要求的几种算法训练测试完成以后,我们还探索了一些新的算法。LightGBM、AdaBoost、GDBT、Extra Trees、Decision Tree、Random Forest等。这些算法模型基本都是基于树模型而建立的,除了Decision Tree,其他几种新的模型都算是树模型的集成学习模型。尽管他们的底层基础十分类似,中间的训练过程还是有较大的不同,分类的方法也不尽相同。最后训练出来的结果更是相差甚远。训练效果最好的是LightGBM模型,准确率最好情况下达到了96.32%,而效果最差的是AdaBoost模型,准确率仅有17%,这是一个十分差的结果。
不足
这次企业实践项目整体上完成度高,尝试了多种不同的算法,但是在前期的数据探索和处理环节还不够深入,有点浅尝辄止。一方面是后面是时间相对有点紧迫,另一方面是本次的重点在于模型建立和训练分类器。所以就没有花太多的时间去进行数据探索,相关的数据描述性统计和分析也比较匮乏。
其次是在特征提取环节,仅调用了sklearn中TF-IDF算法模型和词袋模型,没有再去尝试其他第三方库提供的特征提取模型,即便是相同的TF-IDF算法在不同的第三方库中,内部的实现机制也是有千差万别的。所以特征提取的方法难免显得单调。
在数据的分布处理上没有去解决样本分布不均衡问题,经济类,计算机等类别的期刊文摘数据条数较多,都有1500条以上,但是交通、通信等类别的期刊文摘仅有几十条数据,样本分布yanzho能够不均衡,这也导致训练出来的所有模型都只对经济、计算机等拥有样本数量偏多的类别预测精准,而对交通、通信等拥有样本较少的类别预测十分不准。
改进
虽然这次课程时间比较紧迫,内容丰富,部分算法很具有挑战性。但是未来我还有很多时间去深入探究这次课程的内容。
首先就是要把本次所有使用到的算法原理和过程弄明白,然后自己实现这些算法,而不仅仅是局限于调用已经封装好的第三方库。
然后就是在特征提取上,要尝试其他库中的特征提取方法。
最后就是在数据分布上尝试欠采样或者SMOTE过采样来平衡样本数据分布,让训练器对每一个类别的训练效果都可以得到显著的提升和综合性能均衡。
这次实践课程收获很多,接触了很多原来不熟悉的机器学习算法,对于自然语言处理的整个项目流程也有了更加深入的了解和认识,当然这个过程也充满了挑战和困难,但是老师的耐心指导和讲解帮我解决了实践过程中的困难。
附录
完整代码
'''
python3.7
-*- coding: UTF-8 -*-
@Project -> File :Code -> NLP
@IDE :PyCharm
@Author :YangShouWei
@USER: 296714435
@Date :2021/4/26 14:34:37
@LastEditor:
'''
import pandas as pd
import jieba
import csv
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import precision_score, classification_report, accuracy_score, recall_score
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from xgboost import XGBClassifier
import SVD
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
import warnings
from sklearn.ensemble import AdaBoostClassifier
from sklearn import decomposition
from sklearn.ensemble import ExtraTreesClassifier
from lightgbm import LGBMClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn import metrics
warnings.filterwarnings('ignore')
from sklearn.model_selection import cross_val_score
def description(s, y_predict, y_test):
print(s+"模型评估:")
# print("精确率:",precision_score(y_test, y_predict, average=None)) # 精确率
print("精确率:", precision_score(y_test, y_predict, average='micro')) # 微平均,精确率
print("准确率", accuracy_score(y_test, y_predict)) # 准确率
print("召回率:", recall_score(y_test, y_predict, average='micro'))
print("f1-Score", metrics.f1_score(y_test, y_predict, average="weighted"))
# print("roc:", metrics.roc_auc_score(y_test, y_predict, multi_class='ovo'))
# print(confusion_matrix(y_test, y_predict))
print("主要分类指标的文本报告:")
print(classification_report(y_test, y_predict))
def Logitic(x_train, y_train, x_test, y_test):
"""
逻辑回归模型
:param x_train:训练集特征值
:param y_train:训练集标签
:param x_test: 测试集特征值
:param y_test: 测试集标签
:return:None
"""
print("逻辑回归模型开始计算...")
# 用逻辑回归进行预测
lg = LogisticRegression(solver="sag")
#将数据集放入模型进行训练
lg.fit(x_train,y_train)
# print("逻辑回归的预测准确率:",lg.score(x_test,y_test))
# 模型评估
description("逻辑回归", lg.predict(x_test), y_test)
Cross_valid(lg, x_train, y_train, 5)
def naviebayes(x_train, y_train, x_test, y_test):
"""
朴素贝叶斯
:param x_train:训练集特征值
:param y_train:训练集
:param x_test:
:param y_test:
:return:
"""
print("朴素贝叶斯开始计算...")
# 进行朴素贝叶斯算法的预测
mlt = MultinomialNB(alpha=0.4)
#将训练集放入模型中开始训练
mlt.fit(x_train, y_train)
# 模型评估
description("朴素贝叶斯", mlt.predict(x_test), y_test)
Cross_valid(mlt, x_train, y_train, 5)
def svm_model(x_train, y_train, x_test, y_test):
"""
支持向量机
:param x_train:训练集特征值
:param y_train:训练集标签
:param x_test: 测试集特征值
:param y_test: 测试集标签
:return:None
"""
print("支持向量机开始计算...")
# 用支持向量机模型进行预测
svm_clf = SVC(kernel="linear", verbose=False)
# 将训练集数据放入模型进行训练
svm_clf.fit(x_train, y_train)
# 预测结果
# print("支持向量机的预测准确率:",svm_clf.score(x_test, y_test))
#模型评估
description("支持向量机",svm_clf.predict(x_test), y_test)
Cross_valid(svm_clf, x_train, y_train, 5)
def DecisionTree(x_train, y_train, x_test, y_test):
"""
决策树模型
:param x_train:训练集特征值
:param y_train:训练集标签
:param x_test: 测试集特征值
:param y_test: 测试集标签
:return:None
"""
print("决策树开始计算...")
# 用决策树进行预测
dec = DecisionTreeClassifier(max_depth=8) # 传入最大深度值
#将训练集放入模型开始训练
dec.fit(x_train, y_train)
print("决策树模型预测率:",dec.score(x_test,y_test))
# 模型评估
description("决策树", dec.predict(x_test), y_test)
Cross_valid(dec, x_train, y_train, 5)
def RandomForest(x_train, y_train,x_test,y_test):
"""
随机森林
:param x_train:训练集特征值
:param y_train:训练集标签
:param x_test: 测试集特征值
:param y_test: 测试集标签
:return:None
"""
print("随机森林算法模型开始计算...")
#用随机森林模型进行预测
rfc = RandomForestClassifier()
#将训练集放入模型进行训练
rfc.fit(x_train, y_train)
print("随机森林模型准确率:",rfc.score(x_test, y_test))
# 模型评估
description("随机森林", rfc.predict(x_test), y_test)
Cross_valid(rfc, x_train, y_train, 5)
def KNeighbors(x_train, y_train, x_test, y_test):
"""
K近邻算法
:param x_train:训练集特征值
:param y_train:训练集标签
:param x_test: 测试集特征值
:param y_test: 测试集标签
:return:None
"""
print("K近邻算法开始计算...")
#进行K近邻算法的预测
knn = KNeighborsClassifier()
#将训练集放入模型中开始训练
knn.fit(x_train,y_train)
print("K近邻的预测准确率:",knn.score(x_test,y_test))
# 模型评估
description("K近邻", knn.predict(x_test), y_test)
Cross_valid(knn, x_train, y_train, 5)
import numpy as np
def XGBoost(x_train, y_train,x_test,y_test):
"""
XGBoost模型
:param x_train:
:param y_train:
:param x_test:
:param y_test:
:return:
"""
# print('XGBoost')
xgb = XGBClassifier(random_state=0)
xgb.fit(x_train, y_train)
print("XGB模型准确率:", xgb.score(x_test, y_test))
# 模型评估
description("XGBoost:", xgb.predict(x_test), y_test)
Cross_valid(xgb, x_train, y_train, 5)
def AdaBoost(x_train, y_train,x_test,y_test):
"""
AdaBoost算法
:param x_train:
:param y_train:
:param x_test:
:param y_test:
:return:
"""
ada = AdaBoostClassifier(random_state=0)
ada.fit(x_train,y_train)
description("AdaBoost", ada.predict(x_test), y_test)
Cross_valid(ada, x_train, y_train, 5)
def GDBT(x_train, y_train,x_test,y_test):
"""
GDBT算法
:param x_train:
:param y_train:
:param x_test:
:param y_test:
:return:
"""
gdbt = GradientBoostingClassifier(random_state=0)
gdbt.fit(x_train,y_train)
description("GDBT", gdbt.predict(x_test), y_test)
Cross_valid(gdbt, x_train, y_train, 5)
def LGBM(x_train, y_train,x_test,y_test):
"""
LightGBM算法
:param x_train:
:param y_train:
:param x_test:
:param y_test:
:return:
"""
lgbm = LGBMClassifier(random_state=0)
lgbm.fit(x_train, y_train)
description("LGBM", lgbm.predict(x_test), y_test)
Cross_valid(lgbm, x_train, y_train, 5)
def EtraTress(x_train, y_train,x_test,y_test):
"""
极度提升树算法
:param x_train:
:param y_train:
:param x_test:
:param y_test:
:return:
"""
et = ExtraTreesClassifier(random_state=0)
et.fit(x_train, y_train)
description("ETrees",et.predict(x_test), y_test)
Cross_valid(et, x_train, y_train, 5)
def Cross_valid(model, x_train, y_train, num):
"""
K折交叉验证
:param model: 训练模型
:param x_train: 训练集数据
:param y_train: 训练集标签
:param num: 交叉验证次数
:return:
"""
c = cross_val_score(model, x_train, y_train, cv=num)
print("K折交叉验证:", c)
plt.figure(figsize=(6, 5))
plt.plot(np.arange(1, 6), c, 'o-')
plt.xticks(np.arange(1,6,1))
plt.xlabel("次数")
plt.ylabel("准确率")
plt.show()
def DealData():
"""
数据预处理
:return:
"""
data = pd.read_excel("期刊文摘.xlsx") # 读取文本数据
quoting=csv.QUOTE_NONE
stop = pd.read_csv("stopwords.txt",error_bad_lines=False, quoting=csv.QUOTE_NONE,header=None) # 读取停用词表
# print(data.head())
print(data['分类'].unique())
kind = data["分类"].value_counts()
# 统计每一种类被的期刊文本数量
matplotlib.rcParams['axes.unicode_minus'] = False # 正常显示负号
plt.rcParams["font.sans-serif"] = "SimHei" # 设置图片中的字体为中文黑体
plt.figure(figsize=(8, 6))
sns.barplot(x=kind.index,y=kind.values,alpha=0.8)
# 在柱状图上面显示数字
for x, y in enumerate(kind.values):
plt.text(x, y + 10, '%s' % y, ha='center', va='bottom')
plt.title("各类别期刊文摘数量统计")
plt.xlabel("期刊类别")
plt.ylabel("数量")
plt.tight_layout()
# plt.show()
label = dict()
for index,i in enumerate(data["分类"].unique()):
label[i] = index
c = list(data["分类"])
t = []
for i in c:
t.append(label[i])
data['分类'] = t
word = [] # 存储分词结果
text = list(data["正文"])
stop.columns = ["停用词"]
stop = list(stop["停用词"])
# stop.append(' ')
# stop.append('\n')
# print(stop)
for i in text:
for q in range(10):
str(i).replace(str(q), '$$') # 将文本中0~9的数字替换成$$便于后续去除。
# seg_list = jieba.cut(str(i), cut_all=False) # 分词
seg_list = jieba.lcut(str(i))
seg_list = list(seg_list)
for j in seg_list: # 遍历列表中的词语,去除停用词
if j in stop:
seg_list.remove(j)
word.append(' '.join(seg_list))
# print(seg_list)
# print(word[-1])
# 划分数据集,训练集:测试集=9:1
x_train,x_test,y_train, y_test = train_test_split(word,t, test_size=0.1)
# 提取方法:TFIDF
x_train, x_test = TfidfModel(x_train, x_test)
# 提取方法:词袋模型
# x_train, x_test = Countvec(x_train, x_test)
return x_train, y_train, x_test, y_test
def TfidfModel(x_train, x_test):
"""
TFIDF模型提取特征
:param x_train: 训练集
:param x_test: 测试集
:return:
"""
tf = TfidfVectorizer()
x_tr = tf.fit_transform(x_train)
x_te = tf.transform(x_test)
return x_tr, x_te
def Countvec(x_train, x_test):
"""
词袋模型,提取特征
对文本进行特征值化
:return:None
"""
cv = CountVectorizer()
x_train = cv.fit_transform(x_train)
x_test = cv.transform(x_test)
# print(cv.get_feature_names())
# print(x_train.toarray()) # 转化成数组输出
x_train = x_train.toarray()
x_test = x_test.toarray()
return x_train.tolist(),x_test.tolist()
def SVD(train):
"""
SVD奇异值分解降维
:param train:
:return:
"""
svd = decomposition.TruncatedSVD(1000)
return svd.fit_transform(train)
if __name__ =="__main__":
x_train,y_train,x_test,y_test = DealData()
# 进行SVD降维
# x_train = SVD(x_train)
# 训练模型
LGBM(x_train, y_train, x_test, y_test)
GDBT(x_train, y_train, x_test, y_test)
XGBoost(x_train,y_train,x_test,y_test) # XGBoost
DecisionTree(x_train, y_train, x_test, y_test)
RandomForest(x_train,y_train,x_test,y_test)
naviebayes(x_train,y_train,x_test,y_test)
EtraTress(x_train, y_train, x_test, y_test)
KNeighbors(x_train,y_train,x_test,y_test)
Logitic(x_train,y_train,x_test,y_test)
AdaBoost(x_train,y_train,x_test,y_test)
svm_model(x_train, y_train, x_test, y_test) # 支持向量机
词云实现代码
pasg=pd.read_excel(r"C:\Users\acer\Desktop\数据挖掘\文本分类实践项目\期刊文摘.xlsx")
tanspatation = pasg.loc[pasg['分类']=='交通',:]
for line in tanspatation.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags1 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text1 = " ".join(tags1)
sport = pasg.loc[pasg['分类']=='体育',:]
for line in sport.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags2 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text2 = " ".join(tags2)
agri = pasg.loc[pasg['分类']=='农业',:]
for line in agri.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags3 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text3 = " ".join(tags3)
medi = pasg.loc[pasg['分类']=='医疗',:]
for line in medi.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags4 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text4 = " ".join(tags4)
his = pasg.loc[pasg['分类']=='历史',:]
for line in his.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags5 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text5 = " ".join(tags5)
philo = pasg.loc[pasg['分类']=='哲学',:]
for line in philo.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags6 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text6 = " ".join(tags6)
edu = pasg.loc[pasg['分类']=='教育',:]
for line in edu.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags7 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text7 = " ".join(tags7)
liter = pasg.loc[pasg['分类']=='文学',:]
for line in liter.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags8 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text8 = " ".join(tags8)
politic = pasg.loc[pasg['分类']=='时政',:]
for line in politic.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags9 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text9 = " ".join(tags9)
law = pasg.loc[pasg['分类']=='法律',:]
for line in law.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags10 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text10 = " ".join(tags10)
elec = pasg.loc[pasg['分类']=='电子',:]
for line in elec.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags11 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text11 = " ".join(tags11)
mine = pasg.loc[pasg['分类']=='矿藏',:]
for line in mine.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags12 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text12 = " ".join(tags12)
space = pasg.loc[pasg['分类']=='空间',:]
for line in space.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags13 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text13 = " ".join(tags13)
econo = pasg.loc[pasg['分类']=='经济',:]
for line in econo.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags14 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text14 = " ".join(tags14)
souce = pasg.loc[pasg['分类']=='能源',:]
for line in souce.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags15 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text15 = " ".join(tags15)
art = pasg.loc[pasg['分类']=='艺术',:]
for line in art.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags16 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text16 = " ".join(tags16)
compu = pasg.loc[pasg['分类']=='计算机',:]
for line in tanspatation.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags17 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text17 = " ".join(tags17)
communi = pasg.loc[pasg['分类']=='通信',:]
for line in communi.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags18 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text18 = " ".join(tags18)
environment = pasg.loc[pasg['分类']=='环境',:]
for line in tanspatation.itertuples(): #使用a.itertuples()遍历DataFrame的每一行
linE = getattr(line, '正文') # 获得每一行
tags19 = jieba.analyse.extract_tags(linE, topK=100, withWeight=False) # 关键词提取 topK=100 提取TF-IDF权重最大的前100个关键词
text19 = " ".join(tags19)
#词云图
font=r"C:\Windows\Fonts\msyh.ttc"
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text1)
wordcloud.to_file('交通.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text2)
wordcloud.to_file('体育.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text3)
wordcloud.to_file('农业.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text4)
wordcloud.to_file('医疗.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text5)
wordcloud.to_file('历史.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text6)
wordcloud.to_file('哲学.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text7)
wordcloud.to_file('教育.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text8)
wordcloud.to_file('文学.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text9)
wordcloud.to_file('时政.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text10)
wordcloud.to_file('法律.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text11)
wordcloud.to_file('电子.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text12)
wordcloud.to_file('矿藏.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text13)
wordcloud.to_file('空间.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text14)
wordcloud.to_file('经济.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text15)
wordcloud.to_file('能源.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text16)
wordcloud.to_file('艺术.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text17)
wordcloud.to_file('计算机.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text18)
wordcloud.to_file('通信.png')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white') #width=1600,height=1200, mode='RGBA'
wordcloud.generate(text19)
wordcloud.to_file('环境.png')