各大IT公司校园招聘程序猿笔试、面试题集锦
百度一面
1、给定一个字符串比如“abcdef”,要求写个函数变成“defabc”,位数是可变的。
别人的方法:这个比较简单,我用的是strcpy和memcpy,然后他问有什么优化的办法,我就不知道了。
我的方法:
用两个指针*front,*rear分别指向字符串的第一个字符和最后一个字符。
以下是代码:
#include<stdio.h> #include<string.h> int main(void){ char s[] = "abcdefa";//如果是char *s ,则后面不能修改其指向的内容。原因是: //char指针指向文本字符串,可以认为char指针是指向const对象的指针;char数组名,可以认为是常量指针,不允许修改指向 char *front,*rear = s; while(*rear != NULL) rear ++; rear--; while(front != rear){ if(*front != *rear){ //如果两个字符相等,则不需要互换 char temp = *front; *front = *rear; *rear = temp; } front++; rear--; } printf("%s",&s); return 0; }
2、socket过程就是socket的server和client整个流程写下来,这个还是没啥问题的。
详见:http://blog.csdn.net/heyutao007/article/details/6588302
3、数据结构二叉树的遍历,给了个二叉树,前序、中序、后序写出来,这个没什么难度。
4、树的层次遍历,这个开始真忘了,想了半天才想起来用队列。然后他又让我详细写出入队出队的过程,总之还是搞定了。
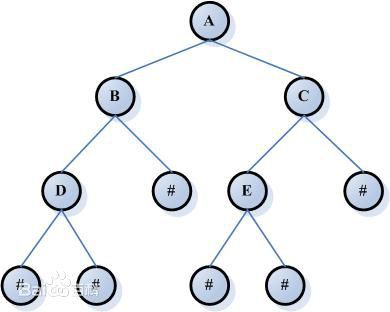
这颗二叉树的层次遍历的过程:假设一个队列Q,首先根节点A入队列,接着取对头元素,即A,将A的子节点B、C先后入队列,再次取对头元素,即B,然后将B的子节点D、#入队列。重复取出对头元素,将对头元素入队列的过程。直到队列中的数据为空,遍历结束。
5、两圆相切转圏问题——一个小圆半径是1厘米,一个大圆半径是5厘米,小圆沿着大圆转圈,请问要转几圈可以转完大圈?这个问题在行测题做过,就是公转自转的问题,不管大小圆半径是多少,外切转圏要转R/r+1圏,内切转圏转R/r-1圈。
百度二面
1、二叉树的前序遍历的递归和非递归的可执行程序。
递归容易实现。
非递归的实现需要借助栈来实现
//二叉树的遍历 //首先是递归实现: //先序遍历 #include <stdio.h> #include "malloc.h" //定义二叉树的节点 typedef struct BiTNode{ char data; struct BiTNode *lchild;//左子树 struct BiTNode *rchild;//右子树 }BiTNode,*BiTree; //先序建立二叉树 BiTree createBiTree(){ char ch; BiTree T; scanf("%c",&ch); if(ch=='#'){ T = NULL; printf("Null"); } else{ T = (BiTree)malloc(sizeof(BiTNode)); T->data = ch; T->lchild = createBiTree(); T->rchild = createBiTree(); } return T;//返回根节点 } //前序遍历(递归实现) void preOrder(BiTNode *root){ if(root != NULL){ printf("%c,",root->data); preOrder(root->lchild); preOrder(root->rchild); } } //前序遍历(非递归实现) void preOrder2(BiTNode *root){ //初始化栈 stack *s = (stack *)malloc(sizeof(stack)); initStack(s); BiTNode *p = root;//遍历指针 while(p || !isEmpty(s)){ if(p){ printf("%d ",p->data);//访问父节点信息 push(s,p);//将父节点入栈 p = p->lchild;//遍历左子树 }else{ BiTNode *father = pop(s);//出栈的是p结点父节点 p = father->rchild;//遍历右子树 } } } //定义栈 typedef struct stack{ BiTNode nodes[20]; int size; int top;//指向栈顶元素,初始值为-1 }stack; //初始化stack void initStack(stack *stack){ stack->size = 0; stack->top = -1; } //判断栈是否为空 bool isEmpty(stack *stack){ return stack->size==0?true:false; } //获取栈大小 int getSize(stack *stack){ return stack->size; } //入栈 void push(stack *stack,BiTNode *node){ if(stack->size<20){ stack->top++; stack->nodes[stack->top] = *node; } } //出栈 BiTNode* pop(stack *stack){ if(stack->top >= -1){ return &stack->nodes[stack->top]; } return NULL; } //中序遍历 void inOrder(BiTNode *root){ if(root != NULL){ inOrder(root->lchild); printf("%c,",root->data); inOrder(root->rchild); } } //后序遍历 void postOrder(BiTNode *root){ if(root != NULL){ postOrder(root->lchild); postOrder(root->rchild); printf("%c,",root->data); } }
2、写出快速排序的实现代码,一个是字符串拼接函数的实现strcat(),还有大数相乘,都是基本题。
2.1、快速排序:
void quick_sort1(int s[], int l, int r) { if (l < r) { int i = AdjustArray(s, l, r);//先成挖坑填数法调整s[] quick_sort1(s, l, i - 1); // 递归调用 quick_sort1(s, i + 1, r); } } int AdjustArray(int s[], int l, int r) //返回调整后基准数的位置 { int i = l, j = r; int x = s[l]; //s[l]即s[i]就是第一个坑 while (i < j) { // 从右向左找小于x的数来填s[i] while(i < j && s[j] >= x) j--; if(i < j) { s[i] = s[j]; //将s[j]填到s[i]中,s[j]就形成了一个新的坑 i++; } // 从左向右找大于或等于x的数来填s[j] while(i < j && s[i] < x) i++; if(i < j) { s[j] = s[i]; //将s[i]填到s[j]中,s[i]就形成了一个新的坑 j--; } } //退出时,i等于j。将x填到这个坑中。 s[i] = x; return i; }
3、归并排序的实现。
public void MergerSort(int[] v, int first, int last) { if (first + 1 < last) { int mid = (first + last) / 2; MergerSort(v, first, mid); MergerSort(v, mid, last); Merger(v, first, mid, last); } } public void Merger(int[] v, int first, int mid, int last) { Queue<int> tempV = new Queue<int>(); int indexA, indexB; //设置indexA,并扫描subArray1 [first,mid] //设置indexB,并扫描subArray2 [mid,last] indexA = first; indexB = mid; //在没有比较完两个子标的情况下,比较 v[indexA]和v[indexB] //将其中小的放到临时变量tempV中 while (indexA < mid && indexB < last) { if (v[indexA] < v[indexB]) { tempV.Enqueue(v[indexA]); indexA++; } else { tempV.Enqueue(v[indexB]); indexB++; } } //复制没有比较完子表中的元素 while (indexA < mid) { tempV.Enqueue(v[indexA]); indexA++; } while (indexB < last) { tempV.Enqueue(v[indexB]); indexB++; } int index = 0; while (tempV.Count > 0) { v[first+index] = tempV.Dequeue(); index++; } }
4、文件按a~z编号,aa~az,ba~bz...za...zz...aaa...aaz,aba~abz...这样的方法进行编号。给定任意一个编号,输出文件是第几个文件。并写出测试方法。简单,把编号看成26进制,这题就是一个十进制和26进制的进制转换问题了。
5、编程:两个链表,按升序排序,合并后仍按升序,不准用递归,并求复杂度
百度电面:
1、谈谈你对数据库中索引的理解
解答:
索引就是加快检索表中数据的方法。数据库的索引类似于书籍的索引。在书籍中,索引允许用户不必翻阅完整个书就能迅速地找到所需要的信息。在数据库中,索引也允许数据库程序迅速地找到表中的数据,而不必扫描整个数据库。
2、现在普通关系数据库用得数据结构是什么类型的数据结构
关系模型(二维表)。
3、索引的优点和缺点
索引的优点 1.创建唯一性索引,保证数据库表中每一行数据的唯一性 2.大大加快数据的检索速度,这也是创建索引的最主要的原因 3.加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。 4.在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。 5.通过使用索引,可以在查询的过程中使用优化隐藏器,提高系统的性能。
索引的缺点 1.创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加 2.索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大 3.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度
4、session、cookie和cache的区别是什么
详见:http://blog.csdn.net/lonelyrains/article/details/7838074
5、如果有几千个session,怎么提高效率?
将session存储在数据库中
6、session是存储在什么地方,以什么形式存储的?
| 方式 | 优点 | 缺点 | 应用 | |
| 存储在本地机器内存中 | 速度读取快 | 容易丢失 | 小型网站 | |
| 存储在别的电脑中 | 不消耗本地资源 | 如果网络不通,则Session读取不到 | 大的网站 | |
| 存储在数据库中 | 存储量大 | 速度慢 | 用户很多的网站 |
新浪技术部笔试题
一、数据结构和算法 1、简述什么是hashtable,如何解决hash冲突 2、什么叫二叉树,满二叉树,完全二叉树
4、数组和链表有什么区别,分别用在什么场合
数组和链表都是线性表,但数组是一组元素有序地存储在连续的内存单元中,而链表的节点元素存储的内存单元并不是连续的。
由于存储性质,导致数组的查找可根据下标直接定位,而链表的查找需要遍历,因此查找的效率数组比链表要高,而插入和删除一个元素,数组需要平均移动二分之一的元素,而链表可以直接通过断链和指针实现插入和删除。
对于树的操作一般用到链表,对于图的操作一般用到数组。
数组应用场景:
1、注重存储密度;
2、经常做的运算是按序号访问数据元素;
3、数组更容易实现,任何高级语言都支持;
4、构建的线性表较稳定。
链表应用场景:
1、对线性表的长度或者规模难以估计;
2、频繁做插入删除操作;
3、构建动态性比较强的线性表。
二、操作系统
1、什么叫虚拟内存
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。
2、块设备和字符设备有什么区别
块设备:。块设备将信息存储在固定大小的块中,每个块都有自己的地址。数据块的大小通常在512字节到32768字节之间。块设备的基本特征是每个块都能独立于其它块而读写。磁盘是最常见的块设备。
字符设备:字符设备按照字符流的方式被有序访问,像串口和键盘就都属于字符设备。
1.字符设备只能以字节为最小单位访问,而块设备以块为单位访问,例如512字节,1024字节等
2.块设备可以随机访问,但是字符设备不可以
3.字符和块没有访问量大小的限制,块也可以以字节为单位来访问
3、进程和线程的区别
4、简述TCP网关连接交互细节
即TCP三次握手连接,四次握手断开。
三、Lunix
1、写出10个常用的linux命令和参数
1、返回上层目录:cd ..;2、打印当前目录:pwd;3、解压tar.gz:tar -xzvf file.tar.gz 解压tar:tar -xvf file.tar;4、强制删除某个文件:rm -rf file;5、重命名/移动文件:mv /dir/file1 /dir2/file1;
更多详见:http://os.51cto.com/art/201009/223806.htm
2、如何查看磁盘剩余空间
df -h1 3、如何查看端口是否被占用
4、如何查看某个进程所占用的内存
可分为动态查看和静态查看,详见:http://blog.csdn.net/sunlylorn/article/details/6215137
四、程序题(具体题目记不太清了)
1、用两个线程实现1-100的输出
public class Test1 { int num = 0; class addThread extends Thread { @Override public void run() { super.run(); while (true) { if (num < 100) addNum(); else break; } } } public synchronized void addNum() { System.out.println("num=" + num++); } public static void main(String[] args) { Test1 test = new Test1(); addThread t1 = test.new addThread(); addThread t2 = test.new addThread(); t1.start(); t2.start(); } }
2、把一个文件夹中所有01结尾的文件前十行内容输出
package sina;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.RandomAccessFile;
public class Test2 {
public static void main(String[] args) {
print("e:/test");
}
private static void print(String pwd) {
File dir = new File(pwd);
File[] files = dir.listFiles();
for(int i=0;i<files.length;i++){
//遍历每个文件
try {
RandomAccessFile rf = new RandomAccessFile(files[i], "r");
long len = rf.length();
long start = rf.getFilePointer();
long end = start+len;
rf.seek(end-2);
if(rf.read() == '0'){
rf.seek(end-1);
if(rf.read() == '1'){
//以01结尾的文件
readTop10Lines(files[i]);
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
/**
* 读取文件前10行
* @param f
* @throws IOException
*/
private static void readTop10Lines(File f) throws IOException{
BufferedReader br = new BufferedReader(new FileReader(f));
String temp;
StringBuffer sb = new StringBuffer();
temp = br.readLine();
int count = 1;
while(temp != null && count<=10){
sb.append(temp);
temp = br.readLine();
count++;
}
System.out.println(sb.toString());
}
}
关于文件操作:http://blog.sina.com.cn/s/blog_507e84890100ch8q.html
思科一面:
1、C++和Java最大的区别是什么?
http://blog.chinaunix.net/uid-12707183-id-2918815.html
2、static、extern、global的作用?(再一次出现了static,上镜率真高挖~)
http://blog.csdn.net/hackbuteer1/article/details/7487694
3、inline内联函数是否占用运行时间?
不会占用运行时间。 在程序编译时,编译器将程序中出现的内联函数的调用表达式用内联函数的函数体来进行替换。由于在编译时将内联函数体中的代码替代到程序中,因此会增加目标程序代码量,进而增加空间开销,而在时间开销上不象函数调用时那么大,可见它是以目标代码的增加为代价来换取时间的节省。
详见:http://www.cnblogs.com/socrassi/archive/2009/09/09/1563002.html
关于C语言转换为机器语言的过度:http://blog.csdn.net/chengocean/article/details/6250779。
思科二面:
1、进程和线程有什么区别?
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
详见:http://jingyan.baidu.com/article/624e74598efcc834e9ba5a66.html
3、页面的替换算法都有哪些?
1、理想页面置换算法(OPT):这是一种理想的页面替换算法,在实际中不可能实现。该算法的思想是:发生缺页时,选择以后永不使用或在最长时间内不再被访问的内存页面予以淘汰。
2、先进先出页面置换算法(FIFO):选择最先进入内存的页面予以淘汰。
3、最近最久未使用算法(LRU):选择在最近一段时间内最久没有使用过的页,把它淘汰。
4、最少使用算法(LFU):选择到当前时间为止被访问次数最少的页转换。
补充:磁盘调度算法。
详见:http://blog.csdn.net/kennyrose/article/details/7532651
操作系统中常见的调度算法:http://blog.chinaunix.net/uid-25132162-id-361291.html
4、用户态和内核态的区别?
当一个任务(进程)执行系统调用而陷入内核代码中执行时,我们就称进程处于内核运行态(或简称为内核态)。此时处理器处于特权级最高的(0级)内核代码中执行。当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。每个进程都有自己的内核栈。当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。即此时处理器在特权级最低的(3级)用户代码中运行。当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态。因为中断处理程序将使用当前进程的内核栈。这与处于内核态的进程的状态有些类似。
5、平面上N个点 没两个点都确定一条直线 求出斜率最大 那条直线所通过 两个点 斜率不存在 情况不考虑 时间效率越高越好 解法:先把N个点按x排序。 斜率k最大值为max(斜率(point[i],point[i+1])) 0<=i<n-2。 复杂度Nlog(N)。 以3个点为例,按照x排序后为ABC,假如3点共线,则斜率一样,假如不共线,则可以证明在AB或BC中,一定有一个点的斜率大于AC,一个点的斜率小于AC。
腾讯一面
1、关系型数据库的特点
关系型数据库,是指采用了关系模型来组织数据的数据库。
关系模型是在1970年由IBM的研究员E.F.Codd博士首先提出的,在之后的几十年中,关系模型的概念得到了充分的发展并逐渐成为主流数据库结构的主流模型。
简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
关系模型中常用的概念:
- 关系:可以理解为一张二维表,每个关系都具有一个关系名,就是通常说的表名
- 元组:可以理解为二维表中的一行,在数据库中经常被称为记录
- 属性:可以理解为二维表中的一列,在数据库中经常被称为字段
- 域:属性的取值范围,也就是数据库中某一列的取值限制
- 关键字:一组可以唯一标识元组的属性,数据库中常称为主键,由一个或多个列组成
- 关系模式:指对关系的描述。其格式为:关系名(属性1,属性2, ... ... ,属性N),在数据库中成为表结构
关系型数据库的优点:
- 容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
- 使用方便:通用的SQL语言使得操作关系型数据库非常方便
- 易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率
http://blog.csdn.net/robinjwong/article/details/18502195
2、父类的析构函数为什么要定义为虚函数
不定义为虚函数的话,delete父类只释放了父类的内存空间,而子类的内存空间没有释放,造成了内存泄漏。而定义了虚函数则不会造成内存泄漏。
详见:http://blog.csdn.net/qiurisuixiang/article/details/6926313
3、把一个字符串的大写字母放到字符串的后面,各个字符的相对位置不变,不能申请额外的空间。 (比较难)
4、快排算法实现程序
http://blog.csdn.net/hackbuteer1/article/details/6568913
5、KMP算法实现程序
http://blog.csdn.net/hackbuteer1/article/details/7319115
6、override和overload的区别
java中,override:在继承时,子类方法覆盖父类方法;overload:同一个类中,方法名相同,但参数个数、顺序和类型至少其中一个不同,则被视为不同的方法。
详见http://www.cnblogs.com/whgw/archive/2011/10/01/2197083.html
7、编程并实现一个八皇后的解法
8、链表的归并排序
腾讯二面:
1、在数据库中如何创建一个表
CREATE TABLE table_name
(column_name data_type
{[NULL | NOT NULL]
[PRIMARY KEY | UNIQUE]}
2、创建后如何添加一个记录、删除一个记录
用sql语句:
添加一个记录:insert stu('id','name') with value(1,'he');
删除一个记录:delete from stu where id=1;
3、编写C++中的两个类 一个只能在栈中分配空间 一个只能在堆中分配。 (比较难)
4、请编写实现malloc()内存分配函数功能一样的代码。
5、请编写能直接实现strstr()函数功能的代码。
KMP算法
6、已知: 每个飞机只有一个油箱, 飞机之间可以相互加油(注意是相互,没有加油机) 一箱油可供一架飞机绕地球飞半圈, 问题:为使至少一架飞机绕地球一圈回到起飞时的飞机场,至少需要出动几架飞机?(所有飞机从同一机场起飞,而且必须安全返回机场,不允许中途降落,中间没有飞机场)
三架飞机足矣。。http://blog.sina.com.cn/s/blog_60c3c90f0100lkhs.html
7、static的作用——再一次出现~
http://blog.csdn.net/hackbuteer1/article/details/7487694
JAVA中的static 修饰符
1、static变量
按照是否静态的对类成员变量进行分类可分两种:一种是被static修饰的变量,叫静态变量或类变量;另一种是没有被static修饰的变量,叫实例变量。
两者的区别是:
对于静态变量在内存中只有一个拷贝(节省内存),JVM只为静态分配一次内存,在加载类的过程中完成静态变量的内存分配,可用类名直接访问(方便),当然也可以通过对象来访问(但是这是不推荐的)。
对于实例变量,没创建一个实例,就会为实例变量分配一次内存,实例变量可以在内存中有多个拷贝,互不影响(灵活)。
所以一般在需要实现以下两个功能时使用静态变量:
在对象之间共享值时
方便访问变量时
2、静态方法
静态方法可以直接通过类名调用,任何的实例也都可以调用,
因此静态方法中不能用this和super关键字,不能直接访问所属类的实例变量和实例方法(就是不带static的成员变量和成员成员方法),只能访问所属类的静态成员变量和成员方法。
因为实例成员与特定的对象关联!这个需要去理解,想明白其中的道理,不是记忆!!!
因为static方法独立于任何实例,因此static方法必须被实现,而不能是抽象的abstract。
例如为了方便方法的调用,Java API中的Math类中所有的方法都是静态的,而一般类内部的static方法也是方便其它类对该方法的调用。
静态方法是类内部的一类特殊方法,只有在需要时才将对应的方法声明成静态的,一个类内部的方法一般都是非静态的
3、static代码块
static代码块也叫静态代码块,是在类中独立于类成员的static语句块,可以有多个,位置可以随便放,它不在任何的方法体内,JVM加载类时会执行这些静态的代码块,如果static代码块有多个,JVM将按照它们在类中出现的先后顺序依次执行它们,每个代码块只会被执行一次。例如:
public class Test5 {
private static int a;
private int b;
static{
Test5.a=3;
System.out.println(a);
Test5 t=new Test5();
t.f();
t.b=1000;
System.out.println(t.b);
}
static{
Test5.a=4;
System.out.println(a);
}
public static void main(String[] args) {
// TODO 自动生成方法存根
}
static{
Test5.a=5;
System.out.println(a);
}
public void f(){
System.out.println("hhahhahah");
}
}
运行结果:
3
hhahhahah
1000
4
5
利用静态代码块可以对一些static变量进行赋值,最后再看一眼这些例子,都一个static的main方法,这样JVM在运行main方法的时候可以直接调用而不用创建实例。
8、写string类的构造,析构,拷贝函数——这题大约出现过4次左右,包括编程和程序填空,程序员面试宝典上有这题,也算是个经典笔试题,出现几率极大~
http://rsljdkt.iteye.com/blog/770072
微软面试题
微软面试题汇总 http://www.cnblogs.com/qlee/archive/2011/09/16/2178873.html 1、给你一个凸多边形,你怎么用一条线,把它分成面积相等的两部分 2、有一条数轴,上有一整数点s,点s两侧分别放了两个机器人,不知道两个机器人分别距离s的距离,两机器人不能相互通信。 现在,给你以下指令: R(往右一格) L(往左一格) IF(S)是否在S点 GOTO A,跳到A代码段。 设计一套指令给两个机器人,让两个器机可以最终在某一点相遇。
3、怎么判断两棵二叉树是否是同构的
4、按层次打印一个二叉树
5、给你一个数n(最大为10000),怎么求其阶乘
6、判断两个单链表是否有交叉
对于仅判断相交不相交的话:判断最后一个节点是否相同的办法并不慢,如果两个链表长度m,n 那么复杂度O(m+n),这是最优的复杂度
拓展:如何寻找交叉节点:
指针p、q分别遍历链表a、b,假设q先到达NULL(即 假设a 比 b 长),此时从a的头发出一个指针t,当p到达NULL时,从b的头发出s,当s==t的时候即交点.
58同城面试题
一面:
1、set(底层基于红黑树实现)的操作;
list,set,map的用法和区别:http://www.cnblogs.com/I-am-Betty/archive/2010/09/06/1819486.html
java中treemap和treeset实现(红黑树):http://www.cnblogs.com/liqizhou/archive/2012/09/27/java%E4%B8%ADtreemap%E5%92%8Ctreeset%E5%AE%9E%E7%8E%B0%E7%BA%A2%E9%BB%91%E6%A0%91.html
hashtable和hashmap的区别:
2、手写快排递归与非递归实现;
http://blog.csdn.net/hackbuteer1/article/details/6568913
3、KMP原理解释
http://blog.csdn.net/hackbuteer1/article/details/7319115
4、聚类分类协同过滤算法;
http://blog.csdn.net/wolenski/article/details/7982555
二面: 1、提示词实现Trie树+hash 2、最快速度求两个数组之交集; 3、文章最短摘要生成;
网易有道
1、试着用最小的比较次数去寻找数组中的最大值和最小值。 解法一: 扫描一次数组找出最大值;再扫描一次数组找出最小值。 比较次数2N-2
解法二: 将数组中相邻的两个数分在一组, 每次比较两个相邻的数,将较大值交换至这两个数的左边,较小值放于右边。 对大者组扫描一次找出最大值,对小者组扫描一次找出最小值。 比较1.5N-2次,但需要改变数组结构 解法三: 每次比较相邻两个数,较大者与MAX比较,较小者与MIN比较,找出最大值和最小值。
迅雷面试题
1、写一个字符串插入的函数 2、问了我关于虚函数底层的实现 http://blog.csdn.net/hackbuteer1/article/details/7883531 3、写了快排、堆排 http://blog.csdn.net/hackbuteer1/article/details/6568913 4、问我TCP、UDP的一些知识 http://blog.csdn.net/hackbuteer1/article/details/6845406 5、还问了我一些Linux的知识 6、让我实现红黑树的删除操作 http://blog.csdn.net/hackbuteer1/article/details/7760584
网新恒天一面
1、考察指针int (*p)[10]和int *p[10]的区别,用法
2、sizeof(),strlen()的区别和用法
2.1、sizeof()是操作符,strlen()是函数;
2.2、sizeof后面跟的是类型或者函数名,strlen的参数只能是char*;
2.3、sizeof返回的是字节大小,strlen返回的是字符个数。
3、堆、栈的区别和用法
3.1、
栈(stack):由编译器自动分配释放,存放函数的参数和局部变量的值。其操作方式类似于数据结构中的栈(先进后出)
堆(heap):一般用程序员通过malloc自动分配,也必须由程序员free释放所占用的内存。
3.2
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思
是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的
说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示
overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的
空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限
于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
4、多继承的优点与缺点
多重继承的优点是对象可以调用多个基类中的接口。
多重继承的缺点是容易出现继承向上的二义性。
详见:http://blog.csdn.net/jandunlab/article/details/14110117
5、(1)IO2:30ms, CPU 20ms, IO1 20ms, CPU 30ms
(2) IO1 20ms, CPU 20ms, IO2 10ms
(3) CPU 30ms, IO1 20ms
求三种情况的CPU和IO占用率
网新恒天二面:
1、内联函数与宏的区别
1.1、内联函数在运行时可调试,而宏定义不可以;
1.2、编译器会对内联函数的参数类型做安全检查或自动类型转换(同普通函数),而宏定义则不会;
1.3、内联函数可以访问类的成员变量,宏定义则不能;
详情:http://blog.csdn.net/gao675597253/article/details/7397373
2、与信号量相关知识的考察,具体题目记不清了,反正知道基本概念就会做
详见:http://blog.csdn.net/sunlovefly2012/article/details/9396201
3、填空,考察页式虚拟内存的缺页情况,也是知道这部分知识点就会做的题
即页面替换算法。
1、理想页面置换算法(OPT):这是一种理想的页面替换算法,在实际中不可能实现。该算法的思想是:发生缺页时,选择以后永不使用或在最长时间内不再被访问的内存页面予以淘汰。
2、先进先出页面置换算法(FIFO):选择最先进入内存的页面予以淘汰。
3、最近最久未使用算法(LRU):选择在最近一段时间内最久没有使用过的页,把它淘汰。
4、最少使用算法(LFU):选择到当前时间为止被访问次数最少的页转换。
4、类的继承相关知识点的考察,是一道程序输出分析题
5、栈的类的成员函数的实现,程序填空题。
6、模板函数与函数模板的区别
7、函数模板与类模板的区别
百度笔试题
1、数组,链表的优缺点:这个问题比较简单不过我自己经常会忽略的一点是数组是固定空间,链表是可变空间
数组和链表都是线性表,但数组是一组元素有序地存储在连续的内存单元中,而链表的节点元素存储的内存单元并不是连续的。
由于存储性质,导致数组的查找可根据下标直接定位,而链表的查找需要遍历,因此查找的效率数组比链表要高,而插入和删除一个元素,数组需要平均移动二分之一的元素,而链表可以直接通过断链和指针实现插入和删除。
对于树的操作一般用到链表,对于图的操作一般用到数组。
数组应用场景:
1、注重存储密度;
2、经常做的运算是按序号访问数据元素;
3、数组更容易实现,任何高级语言都支持;
4、构建的线性表较稳定。
链表应用场景:
1、对线性表的长度或者规模难以估计;
2、频繁做插入删除操作;
3、构建动态性比较强的线性表。
2、a[N][20]输入N个长度不超过20的字符串,比较这些字符串中是否有完全相同的字母,且相同字母数是否相等。如何改进该算法,降低复杂度。
3、黑:A Q 4
红:J 8 4 2 7 3
梅:K Q 5 4 6
方:A 5
有以上16张扑克牌老板从中选择了一张,之后把这张牌的点数告诉了员工甲,把花色告诉了员工乙。之后按以上方式将16张牌平摊在桌面上。
————甲说:我不知道这张牌是什么。
————乙说:我知道你不知道。
————甲说:我现在知道了。
————乙说:我也知道了。
这张牌是什么?
应该是方5.
3.1、从甲的第一句话可以分析,这张牌不是J、8、2、7、3、K、6。
3.2、从乙的第一句话可以分析,这张牌不是红或者梅。
3.3、从甲的第二句话可以分析,这张牌不是A。其实甲在说谎,他还不确定是黑Q、4还是方5。
3.4、从乙的第二句话可以分析,这张牌就是方5,因为黑中有两个Q和4,而方只有一个5。
4、A:M*M矩阵,求字符串S是否存在A的连续对角线上。(这题应该有涉及到一个之字二维矩阵方面的知识) A若为内存装不下的大矩阵该如何处理?
5、系统接收数据包32字节,第1字节为优先级,其余为数据。设计一个调度算法 (1)优先级高的先处理 (2)同等条件下,请求次数多的先处理 (3)优先级高的一定比优先级低的先处理 写出所用的数据结构的定义,计算空间容量。
阿里巴巴B2B一面
1、各种排序算法的比较次数
2、static、auto未初始化的初始值 http://blog.csdn.net/hackbuteer1/article/details/7487694
3、x*=y+8,给出x,y的值,求该表达式计算后二者的值
x=1,y=2,x*=y+8后,y=2,x=10。
4、enum类型的default赋值规则
enum enumType {Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday};
枚举量Monday、Tuesday等的值默认分别为0-6,我们可以显式的设置枚举量的值:
enum enumType {Monday=1, Tuesday=2, Wednesday=3, Thursday=4, Friday=5, Saturday=6, Sunday=7};
指定的值必须是整数!
详情:http://jingyan.baidu.com/article/e75aca85526c1b142edac6d9.html
5、定义函数F(int x){return (x*x);} 求F(3+5)
F(3+5)=64
6、fgets(s,n,f)函数的功能
原型是char *fgets(char *s, int n, FILE *stream);
从流中读取n-1个字符,除非读完一行,参数s是来接收字符串,如果成功则返回s的指针,否则返回NULL。
形参注释:*string结果数据的首地址;n-1:一次读入数据块的长度,其默认值为1k,即1024;stream文件指针
说得简单一点就是从f这个文件输入流中读取n-1个字符,存到s中。
如果一行的字符数小于n-1,那么就是一行的字符数,所以应该理解为不超过n-1,如果一行的长度大于n-1,就是n-1个字符
7、定义*s="ab\0cdef",输出该字符可以看到什么结果
ab。因为priintf函数以\0为字符串结束标记。
8、还是static相关知识——在此说明一下static这个关键字相当重要,在笔试中出现率为100%,在面试中出现率为50%。
http://blog.csdn.net/hackbuteer1/article/details/7487694
JAVA中的static 修饰符
1、static变量
按照是否静态的对类成员变量进行分类可分两种:一种是被static修饰的变量,叫静态变量或类变量;另一种是没有被static修饰的变量,叫实例变量。
两者的区别是:
对于静态变量在内存中只有一个拷贝(节省内存),JVM只为静态分配一次内存,在加载类的过程中完成静态变量的内存分配,可用类名直接访问(方便),当然也可以通过对象来访问(但是这是不推荐的)。
对于实例变量,没创建一个实例,就会为实例变量分配一次内存,实例变量可以在内存中有多个拷贝,互不影响(灵活)。
所以一般在需要实现以下两个功能时使用静态变量:
在对象之间共享值时
方便访问变量时
2、静态方法
静态方法可以直接通过类名调用,任何的实例也都可以调用,
因此静态方法中不能用this和super关键字,不能直接访问所属类的实例变量和实例方法(就是不带static的成员变量和成员成员方法),只能访问所属类的静态成员变量和成员方法。
因为实例成员与特定的对象关联!这个需要去理解,想明白其中的道理,不是记忆!!!
因为static方法独立于任何实例,因此static方法必须被实现,而不能是抽象的abstract。
例如为了方便方法的调用,Java API中的Math类中所有的方法都是静态的,而一般类内部的static方法也是方便其它类对该方法的调用。
静态方法是类内部的一类特殊方法,只有在需要时才将对应的方法声明成静态的,一个类内部的方法一般都是非静态的
3、static代码块
static代码块也叫静态代码块,是在类中独立于类成员的static语句块,可以有多个,位置可以随便放,它不在任何的方法体内,JVM加载类时会执行这些静态的代码块,如果static代码块有多个,JVM将按照它们在类中出现的先后顺序依次执行它们,每个代码块只会被执行一次。例如:
public class Test5 {
private static int a;
private int b;
static{
Test5.a=3;
System.out.println(a);
Test5 t=new Test5();
t.f();
t.b=1000;
System.out.println(t.b);
}
static{
Test5.a=4;
System.out.println(a);
}
public static void main(String[] args) {
// TODO 自动生成方法存根
}
static{
Test5.a=5;
System.out.println(a);
}
public void f(){
System.out.println("hhahhahah");
}
}
运行结果:
3
hhahhahah
1000
4
5
利用静态代码块可以对一些static变量进行赋值,最后再看一眼这些例子,都一个static的main方法,这样JVM在运行main方法的时候可以直接调用而不用创建实例。
9、数据库中索引,簇索引,非簇,唯一,复合,覆盖索引的区别
详解:http://sunct.iteye.com/blog/1933511
图文理解:http://www.jb51.net/article/29693.htm
补充视图的相关概念:http://www.cnblogs.com/GISDEV/archive/2008/02/13/1067817.html
10、SQL语句和范式是对数据库有要求的公司笔试必考点之一
SQL语句:sql内连接和外连接。内连接就是表结果集的交集,而外连接是表结果集的并集。
补充:JVM类加载机制-http://blog.csdn.net/a19881029/article/details/17068191
阿里巴巴B2B二面
1、通配符的含义
通配符是一种特殊语句,主要有星号(*)和问号(?),用来模糊搜索文件。
2、死锁的基本知识——死锁是各大笔试面试中出现率50%的知识点
产生死锁的原因主要是:
(1) 因为系统资源不足。
(2) 进程运行推进的顺序不合适。
(3) 资源分配不当等。
如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则
就会因争夺有限的资源而陷入死锁。其次,进程运行推进顺序与速度不同,也可能产生死锁。
产生死锁的四个必要条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之
一不满足,就不会发生死锁。
死锁的解除与预防:
理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和
解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确
定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态
的情况下占用资源。因此,对资源的分配要给予合理的规划。
3、信号量P、V原语的相关知识点
详见:http://blog.csdn.net/sunlovefly2012/article/details/9396201
4、有向图的邻接表表示
//有向图的邻接表表示法 #include <stdio.h> #include <malloc.h> #define MAX_VERTEX_NUM 50//定义图的最大顶点数 typedef char VertexData; typedef struct EdgeNode//边表结点 { int adjvex;//邻接点域 VertexData data; struct EdgeNode *next;//边结点所对应的下一个边结点 }EdgeNode; typedef struct VertexNode//定点表结点 { VertexData data; EdgeNode *firstedge;//头结点所对应的第一个边结点 }VertexNode; typedef struct AdjList { int VexNum,ArcNum;//定义图的顶点数和边数 VertexNode vertex[MAX_VERTEX_NUM];//定义头结点数组 }AdjList; void CreateGraph(AdjList *adj) { int e,s,d,n,i; char c; EdgeNode *q = NULL; printf("输入顶点数\n"); scanf("%d",&n); printf("输入边数\n"); scanf("%d",&e); adj->VexNum=n; adj->ArcNum = e; //初始化表头结点 for(i=1;i<=n;i++){ printf("输入第%d个顶点的顶点名称:\n",i); //输入流中还有残留的字符,getchar()会接受那个字符。可以在调用getchar()之前用fflush(stdin)刷新一下输入缓冲区。 fflush(stdin); c = getchar(); adj->vertex[i].data=c;//顶点名称,是一个字符 adj->vertex[i].firstedge = NULL; } for(i=1;i<=e;i++){ printf("输入第%d条边的起点和终点:\n",i); scanf("%d %d",&s,&d);//输入边的起始和终止 q=(EdgeNode *)malloc(sizeof(EdgeNode));//创建一个表结点 if(q==NULL) return; q->adjvex=d; q->next = adj->vertex[s].firstedge;//新加入的结点都是头结点之后, //原来在头结点之后的结点要后移 adj->vertex[s].firstedge = q; } } void DisplayGraph(AdjList *adj) { int n=adj->VexNum;//顶点个数,后面要遍历每一个点点 EdgeNode *q=NULL; int i; for(i=1;i<=n;i++) { q=adj->vertex[i].firstedge; if(q!=NULL) { printf("从结点%c出发的边有:",adj->vertex[i].data); while(q!=NULL) { printf("%c->%c",adj->vertex[i].data,adj->vertex[q->adjvex].data); q=q->next; } } } } void main() { AdjList *adj=(AdjList *)malloc(sizeof(AdjList)); CreateGraph(adj); DisplayGraph(adj); }
5、STL中迭代器的工作原理,迭代器与普通指针有什么区别?
迭代器和指针相同的地方: 1、指针和iterator都支持与整数进行+,-运算,而且其含义都是从当前位置向前或者向后移动n个位置 2、指针和iterator都支持减法运算,指针-指针得到的是两个指针之间的距离,迭代器-迭代器得到的是两个迭代器之间的距离 3、通过指针或者iterator都能够修改其指向的元素 通过上面这几点看,两者真的很像,但是两者也有着下面的几个不同地方 1、out操作符可以直接输出指针的值,但是对迭代器进行在操作的时候会报错。通过看报错信息和头文件知道,迭代器返回的是对象引用而不是对象的值,所以cout只能输出迭代器使用*取值后的值而不能直接输出其自身。 2、指针能指向函数而迭代器不行,迭代器只能指向容器 这就说明了迭代器和指针其实是完全不一样的概念来的。指针是一种特殊的变量,它专门用来存放另一变量的地址,而迭代器只是参考了指针的特性进行设计的一种STL接口。 笔者曾在网上看到这样一种说法:迭代器是广义指针,而指针满足所有迭代器要求。迭代器是STL算法的接口,而指针是迭代器,因此STL算法可以使用指针来对基于指针的非STL容器进行操作。 笔者觉得上面说法也有几分道理,但是到底正不正确就留给看官自己判断了。但是有一点希望大家注意的是:千万不要把指针和迭代器搞混了。也许某些编译器使用指针来实现迭代器以至于有些人会误以为指针和迭代器是一个概念来的。
6、什么是友元? 7、delete、new的用法 8、typename的用法
9、编程判断一个数是否为2的幂
思路:2,4,8,16,32....都是2的n次幂
转换为二进制分别为:
10 100 1000 10000 100000
这些数减1后与自身进行按位与,如果结果为0,表示这个数是2的n次幂
01 011 0111 01111 011111
10&01 = 0 100&011 = 0 1000&0111 = 0 10000&01111 = 0 100000&011111 = 0
#include <stdio.h> /* 判断一个整数是否为2的次方幂 */ bool fun(int v) { bool flag = 0; if((v>0)&&(v&(v-1))==0) flag = 1; return flag; } int main(void) { int a; printf("请输入1个32位的整数:"); scanf("%d",&a); if(fun(a)) printf("这个数是2次方幂\n"); else printf("这个数不是2次方幂\n"); return 0; }
10、你怎样重新改进和设计一个ATM银行自动取款机?
10.1、用指纹识别、人脸识别来替代密码输入;
10.2、语音交互来代替传统按键式的人机交互方式。
12、10000Mbps万兆交换机怎么实现?
13、操作符重载的相关知识点,大题,具体记不清了
人民搜索的笔试题
1、打印汉诺塔移动步骤,并且计算复杂度
2、计算两个字符串的是否相似(字符的种类,和出现次数相同)
编程之美中的一道经典的动态规划题目——计算两个字符串的相似度
public class StringSimilar {
public int fun(String source,String target){
int i,j;
int[][] d = new int[source.length()+1][target.length()+1];
for(i=1;i<source.length()+1;i++){/*初始化临界值*/
d[i][0]=i;
}
for(j=1;j<target.length()+1;j++){/*初始化临界值*/
d[0][j]=j;
}
for(i=1;i<source.length()+1;i++){/*动态规划填表*/
for(j=1;j<target.length()+1;j++){
if(source.substring(i-1, i).equals(target.substring(j-1, j))){
d[i][j]=d[i-1][j-1];/*source的第i个和target的第j个相同时*/
}else{/*不同的时候则取三种操作最小的一个*/
d[i][j]=min(d[i][j-1]+1,d[i-1][j]+1,d[i-1][j-1]+1);
}
}
}
return d[source.length()][target.length()];
}
private int min(int i, int j, int k) {
int min = i<j?i:j;
min = min<k?min:k;
return min;
}
public static void main(String[] args) {
StringSimilar ss = new StringSimilar();
System.out.println(ss.fun("SNOWY", "SUNNY"));//3
System.out.println(ss.fun("a", "b"));//1
System.out.println(ss.fun("abdd", "aebdd"));//1
System.out.println(ss.fun("travelling", "traveling"));//1
}
}
3、定义二叉树,节点值为int,计算二叉树中的值在[a,b]区间的节点的个数
4、动态规划题:一条路有k可坑,每次能跳平方数步长(1 4 9 16。。),不能跳到坑里,从a跳到b最少几步?
5、给一个整数数组,求数组中重复出现次数大于数组总个数一半的数。
1、对以孩子兄弟链接的树进行遍历,不能用递归,也不能借助任何辅助空间
2、假设数组B是升序Int数组A循环移若干得到的位,实现对数组B进行查找的高效算法
step1:从数组的末尾向前遍历,比较B[i]<B[i-1],如果是,则B[i]就是A[0],记录下标j=i;
step2:判读查找数据data,data>B[0],则在B[0]~B[j-1]范围内通过二分查找查找该data;如果data<B[i],则在B[j]~B[B.length-1]范围内通过二分查找查找该data;
step3:输出该data在数组B中的下标
时间复杂度:假设数组长度为n,查找下标j的时间复杂度为O(n),查找data的时间复杂为:O(log2(n)),总的时间复杂度为O(n+log2(n))=O(n)。
3、只有整数和+-*/四种运算组成的算术表达书,实现其求值
考察的是后缀表达式,运用到栈的知识点。
package stack; public class MyStack { private int maxSize; private int[] stackArray; private int top; public MyStack(int s) { maxSize = s; stackArray = new int[maxSize]; top = -1; } public void push(int c) { stackArray[++top] = c; } public int pop() { return stackArray[top--]; } public int peek() { return stackArray[top]; } public boolean isEmpty() { return (top == -1); } public boolean isFull() { return (top == maxSize - 1); } public static void main(String[] args) { MyStack theStack = new MyStack(10); // theStack.push(10); // theStack.push(20); // theStack.push(30); // theStack.push(40); // theStack.push(50); while (!theStack.isEmpty()) { long value = theStack.pop(); System.out.print(value); System.out.print(" "); } System.out.println(""); } }
package peopleseach; import java.util.Scanner; import stack.MyStack; /** * 后缀表达式 * * @author he * */ public class SuffixExpression { /** * 输入后缀表达式 * * @param expression * 后缀表达式 */ private static String InputExpression(MyStack stack) { Scanner scanner = new Scanner(System.in); String signStr="";//符号字符串 String str = null; do { System.out.println("请输入整数或者计算符----输入q即为退出"); str = scanner.nextLine(); if (!str.isEmpty() && !"q".equals(str)) { char c = str.charAt(0); //如果是计算符号,则拼接成符号字符串 if(c=='+'||c=='-'||c=='*'||c=='/') signStr+=c; else //如果是整数,则入栈 stack.push(Integer.parseInt(str)); } } while (!"q".equals(str)); return signStr; } /** * 计算后缀表达式 * * @param signStr * 计算符号字符串 */ private static void calculate(MyStack stack, String signStr) { int result=0; for (int i = 0; i < signStr.length(); i++) { char c = signStr.charAt(i); int b = stack.pop(); int a = stack.pop(); switch (c) { case '+': result = a + b; break; case '-': result = a - b; break; case '*': result = a * b; break; case '/': result = a / b; break; } stack.push(result); } System.out.println("计算结果为:"+result); } /** * @param args */ public static void main(String[] args) { MyStack stack = new MyStack(10); String signStr = InputExpression(stack); calculate(stack, signStr); } }
4、还有一个是考贪心算法的,你让他们看算法导论那本书,关于fractional knapsack problem的那一段,就是0-1背包的一种变形;
5、链表相邻元素翻转,如a->b->c->d->e->f-g,翻转后变为:b->a->d->c->f->e->g
6、求正整数n所有可能的和式的组合(如;4=1+1+1+1、1+1+2、1+3、2+1+1、2+2)
1、实现一个atoi函数==>'注意正负号的判定'
/* * name:xif * coder:xifan@[email protected] * time:08.20.2012 * file_name:my_atoi.c * function:int my_atoi(char* pstr) */ int my_atoi(char* pstr) { int Ret_Integer = 0; int Integer_sign = 1; /* * 判断指针是否为空 */ if(pstr == NULL) { printf("Pointer is NULL\n"); return 0; } /* * 跳过前面的空格字符 */ while(isspace(*pstr) == 0) { pstr++; } /* * 判断正负号 * 如果是正号,指针指向下一个字符 * 如果是符号,把符号标记为Integer_sign置-1,然后再把指针指向下一个字符 */ if(*pstr == '-') { Integer_sign = -1; } if(*pstr == '-' || *pstr == '+') { pstr++; } /* * 把数字字符串逐个转换成整数,并把最后转换好的整数赋给Ret_Integer */ while(*pstr >= '0' && *pstr <= '9') { Ret_Integer = Ret_Integer * 10 + *pstr - '0'; pstr++; } Ret_Integer = Integer_sign * Ret_Integer; return Ret_Integer; }
2、翻转一个句子,其中单词是正序的
算法:
1、将字符串str[0]和str[str.length-1]互换元素,str[1]和str[str.length-2]互换元素····直到将str翻转;时间复杂度:O(n/2)
2、再将单词翻转。时间复杂度:O(nlog2(n))
package peopleseach; /** * 翻转一个句子,其中单词是正序的 * * @author he * */ public class OverturnSentence { private static String overturn(String ss) { char[] sentence = ss.toCharArray(); //将字符串str[0]和str[str.length-1]互换元素,str[1]和str[str.length-2]互换元素····直到将str翻转;时间复杂度:O(n/2) for(int i=0;i<sentence.length/2;i++){ char temp = sentence[i]; sentence[i] = sentence[sentence.length-1-i]; sentence[sentence.length-1-i] = temp; } System.out.println(new String(sentence)); int start = 0; for(int i=0;i<sentence.length;i++){ if(!((sentence[i] >= 'a'&&sentence[i]<='z') ||(sentence[i] >= 'A'&&sentence[i]<='Z'))){ //如果不是英文字符,说明一个字符完结,即str[start]-str[i-1]组成一个单词。接着就对该单词翻转 for(int j=0;j<(i-start)/2;j++){ char temp = sentence[start+j]; sentence[start+j] = sentence[i-1-j]; sentence[i-1-j] = temp; } start = i+1; } } return new String(sentence); } /** * @param args */ public static void main(String[] args) { System.out.println(overturn("I am a good boy!")); } }
3、二叉树两个结点中的最小公共子结点==>求长度,长度之差,远的先走,再一起走
4、三角阵中从第一行到最后一行(给出搜索方向的限制)找一个连续的最大和。
package peopleseach; /** * @author he * 题目:输入一个整形数组,数组里有正数也有负数。数组中连续的一个或多个整数组成一个子数组,每个子数组都有一个和。 * 求所有子数组的和的最大值。要求时间复杂度为O(n)。 浙大数据结构课本上有 思路: * 求连续数字之和,当和为负值,抛弃.当和为正值,比较其与最大值,如大于,则替换之 */ public class ContinuationMax { /** * 连续的最大和 * @param array 上三角矩阵的压缩存储数组 */ public static void findMax(int[] array) { int curMax = 0,max = 0; for(int i=0;i<array.length;i++){ curMax += array[i]; if(curMax < 0) curMax = 0; else if(curMax > max) max = curMax; } //if all data is negative if(max == 0){ max = array[0]; //find the max negative for(int i=1;i<array.length;i++) if(array[i]>max) max = array[i]; } System.out.println("The ContinuationMax is "+max); } /** * @param args */ public static void main(String[] args) { int[][] tarray = new int[][]{ {1, -2, 3, 10},{Integer.MAX_VALUE,-2, -3, 5},{Integer.MAX_VALUE,Integer.MAX_VALUE,6,-7},{Integer.MAX_VALUE,Integer.MAX_VALUE,Integer.MAX_VALUE,11}}; int n=(1+tarray.length)*tarray.length/2; int[] array = new int[n]; int m = 0; for(int i=0;i<tarray.length;i++) for(int j=i;j<tarray.length;j++){ array[m++] = tarray[i][j]; System.out.println(tarray[i][j]); } findMax(array); } }
5、实现一个STL中的vector中的尽量多的方法。
6、字符串移动(字符串为*号和26个字母的任意组合,把*号都移动到最左侧,把字母移到最右侧并保持相对顺序不变),要求时间和空间复杂度最小。
/** ** author :hackbuteer ** 时间复杂度 :O(n);空间复杂度:O(1)
** 注意:从str数组末尾向前遍历要优于从前向后遍历 **/ void Arrange(char *str , int n) { int i , k = n-1; for(i = n - 1 ; i >= 0 ; --i) { if(str[i] != '*') { if(str[k] == '*') { str[k] = str[i]; str[i] = '*'; } --k; } } }
7、说说outer join、inner join、left join、right join的区别是什么?
SQL语句:sql内连接和外连接。(inner join)内连接就是表结果集的交集,外连接(outer join)是表结果集的并集。 外连接又分为左连接(left join)和右连接(right join)。