Hibernate(7)- Hibernate映射文件详解(***.hbm.xml)
一.作用
Hibernate的持久化类和关系数据库之间的映射通常是用一个XML文档来定义的。该文档通过一系列XML元素的配置,来将持久化类与数据库表之间建立起一一映射。这意味着映射文档是按照持久化类的定义来创建的,而不是表的定义。
二.Hibernate映射文件主要内容
- 映射内容的定义:
Hibernate映射文件由节点定义映射内容并指定所对应的JavaBean的位置(也可以不在该节点中用package属性指定对应的JavaBean位置,而在该节点下的class节点中的name属性中指定) - 数据库和JavaBean的关联:
Hibernate映射文件中用节点下的 节点指定数据库表和JavaBean的关联。( 该节点的父节点中用package属性指定了JavaBean的包名时用)/全路径(该节点的父节点中没用package属性指定JavaBean的包名时用) - 主键映射:
在节点下用 节点映射对应的主键,该节点必须有且只有一个(因为主键只有一个),同时必须放在 节点前 - 普通字段映射:
在节点下用 节点映射普通字段,该节点可有多个(一个字段用一个该节点来映射)
示例:
This class contains the employee detail.
你需要以格式
- 映射文件是一个以
标签是一个可选元素,可以被用来修饰类。- 在 id 元素中的
三.Hibernate 映射类型
映射类型
当你准备一个 Hibernate 映射文件时,我们已经看到你把 Java 数据类型映射到了 RDBMS 数据格式。在映射文件中已经声明被使用的 types 不是 Java 数据类型;它们也不是 SQL 数据库类型。这种类型被称为 Hibernate 映射类型,可以从 Java 翻译成 SQL,反之亦然。
在这一章中列举出所有的基础,日期和时间,大型数据对象,和其它内嵌的映射数据类型。
原始类型
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| integer | int 或 java.lang.Integer | INTEGER |
| long | long 或 java.lang.Long | BIGINT |
| short | short 或 java.lang.Short | SMALLINT |
| float | float 或 java.lang.Float | FLOAT |
| double | double 或 java.lang.Double | DOUBLE |
| big_decimal | java.math.BigDecimal | NUMERIC |
| character | java.lang.String | CHAR(1) |
| string | java.lang.String | VARCHAR |
| byte | byte 或 java.lang.Byte | TINYINT |
| boolean | boolean 或 java.lang.Boolean | BIT |
| yes/no | boolean 或 java.lang.Boolean | CHAR(1) ('Y' or 'N') |
| true/false | boolean 或 java.lang.Boolean | CHAR(1) ('T' or 'F') |
日期和时间类型
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| date | java.util.Date 或 java.sql.Date | DATE |
| time | java.util.Date 或 java.sql.Time | TIME |
| timestamp | java.util.Date 或 java.sql.Timestamp | TIMESTAMP |
| calendar | java.util.Calendar | TIMESTAMP |
| calendar_date | java.util.Calendar | DATE |
二进制和大型数据对象
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| binary | byte[] | VARBINARY (or BLOB) |
| text | java.lang.String | CLOB |
| serializable | any Java class that implements java.io.Serializable | VARBINARY (or BLOB) |
| clob | java.sql.Clob | CLOB |
| blob | java.sql.Blob | BLOB |
JDK 相关类型
| 映射类型 | Java 类型 | ANSI SQL 类型 |
|---|---|---|
| class | java.lang.Class | VARCHAR |
| locale | java.util.Locale | VARCHAR |
| timezone | java.util.TimeZone | VARCHAR |
| currency | java.util.Currency | VARCHAR |
四.heibernate的主键映射方式:
在
- assigned:应用程序自身对id赋值。当设置
时,应用程序自身需要负责主键id的赋值,由外部程序负责生成(在session.save()之前为对象的主键设置值),无需Hibernate参与,一般应用在主键为自然主键时。例如XH为主键时,当添加一个学生信息时,就需要程序员自己设置学号的值,这时就需要应用该id生成器。 - native:由数据库对id赋值。当设置
时,数据库负责主键id的赋值,最常见的是int型的自增型主键。例如,在SQLServer中建立表的id字段为identity,配置了该生成器,程序员就不用为该主键设置值,它会自动设置。 - identity:采用数据库提供的主键生成机制,为long/short/int型列生成唯一标识如SQL Server、MySQL中的自增主键生成机制。
- hilo:通过hi/lo算法实现的主键生成机制,需要额外的数据库表保存主键生成历史状态。
- seqhilo:与hi/lo类似,通过hi/lo算法实现的主键生成机制,只是主键历史状态保存在sequence中,适用于支持sequence的数据库,如Oracle。
- increment:主键按数值顺序递增。此方式的实现机制为在当前应用实例中维持一个变量,以保存当前的最大值,之后每次需要生成主键的时候将此值加1作为主键。这种方式可能产生的问题是:如果当前有多个实例访问同一个数据库,由于各个实例各自维护主键状态,不同实例可能生成同样的主键,从而造成主键重复异常。因此,如果同一个数据库有多个实例访问,这种方式应该避免使用
- sequence:采用数据库提供的sequence机制生成主键,用于用序列方式产生主键的数据库(如:Oracle、DB2等的Sequence),用于为long/short/int型列生成唯一标识,如:
序列名 如Oracle sequence。 - uuid.hex:由Hibernate基于128位唯一值产生算法,根据当前设备IP、时间、JVM启动时间、内部自增量等4个参数生成十六进制数值(编码后长度为32位的字符串表示)作为主键。即使是在多实例并发运行的情况下,这种算法在最大程度上保证了产生id的唯一性。当然,重复的概率在理论上依然存在,只是概率比较小。一般而言,利用uuid.hex方式生成主键将提供最好的数据插入性能和数据平台适应性。
- uuid.string:与uuid.hex类似,只是对生成的主键进行编码(长度为16位)。在某些数据库中可能出现问题。
- foreign:使用外部表的字段作为主键。该主键一般应用在表与表之间的关系上,会在后面的表对应关系上进一步讲解。
- select:Hibernate 3新引入的主键生成机制,主要针对遗留系统的改造工程。
由于常用的数据库,如SQLServer、MySQL等,都提供了易用的主键生成机制(如auto-increase字段),可以在数据库提供的主键生成机制上,采用native生成器来配置主键生成方式。
五.映射文件的元素结构和属性
This class contains the employee detail.
- 根元素:
定义类 ,每一个hbm.xml文件都有唯一的一个根元素,包含一些可选的属性
(1).package: 指定当前映射文件对应的持久类的完整包名(如:package="entity.dao")
(2).schema: 指定当前映射文件对应的数据库表的schema名
(3).catalog: 指定当前映射文件对应的数据库表的catalog名
(4).default-cascade: 设置默认的级联方式(默认值为none)
(5).default-access: 设置默认的属性访问方式(默认值为property)
(6).default-lazy: 设置对没有指定延迟加载的映射类和集合设定为延迟加载(默认值为true)
(7).auto-import: 设置当前映射文件中是否可以在HQL中使用非完整的类名(默认值为true) - hibernate-mapping节点的子节点:
(1).class: 为当前映射文件指定对应的持久类名和对应的数据库表名
(2).subclass: 指定多态持久化操作时当前映射文件对应的持久类的子类
(3).meta: 设置类或属性的元数据属性
(4).typedef: 设置新的Hibernate数据类型
(5).joined-subclass: 指定当前联结的子类
(6).union-subclass: 指定当前联结的子类
(7).query: 定义一个HQL查询
(8).sql-query: 定义一个SQL查询
(9).filter-def: 指定过滤器 定义类 :根元素的子元素,用以定义一个持久化类与数据表的映射关系,如下是该元素包含的一些可选的属性
(1).name: 为当前映射文件指定对应的持久类名
(2).table: 为当前映射文件指定对应的数据库表名
(3).schema: 设置当前指定的持久类对应的数据库表的schema名
(4).catalog: 设置当前指定的持久类对应的数据库表的catalog名
(5).lazy: 设置是否使用延迟加载
(6).batch-size: 设置批量操作记录的数目(默认值为1)
(7).check: 指定一个SQL语句用于Schema前的条件检查
(8).where: 指定一个附加的SQL语句的where条件
(9).rowid: 指定是否支持ROWID
(10).entity-name:实体名称 默认值为类名
(11).subselect: 将不可变的只读实体映射到数据库的子查询中
(12).dynamic-update: 指定用于update的SQL语句是否动态生成 默认值为false
(13).dynamic-insert: 指定用于insert的SQL语句是否动态生成 默认值为false
(14).insert-before-update: 设定在Hibernate执行update之前是否通过select语句来确定对象是否确实被修改了,如果该对象的值没有改变,update语句将不会被执行(默认值为false)
(15).abstract: 用于在联合子类中标识抽象的超类(默认值为false)
(16).emutable: 表明该类的实例是否是可变的 默认值为fals
(17).proxy: 指定延迟加载代理类
(18).polymorphism: 指定使用多态查询的方式 默认值为implicit
(19).persister: 指定一个Persister类
(20).discriminator-value: 子类识别标识 默认值为类名
(21).optimistic-lock: 指定乐观锁定的策略 默认值为vesion- class节点的子节点:
(1).id: 定义当前映射文件对应的持久类的主键属性和数据表中主键字段的相关信息
(2).property: 定义当前映射文件对应的持久类的属性和数据表中字段的相关信息
(3).sql-insert: 使用定制的SQL语句执行insert操作
(4).sql-delete: 使用定制的SQL语句执行delete操作
(5).sql-update: 使用定制的SQL语句执行update操作
(6).subselect: 定义一个子查询
(7).comment: 定义表的注释
(8).composite-id: 持久类与数据库表对应的联合主键
(9).many-to-one: 定义对象间的多对一的关联关系
(10).one-to-one: 定义对象间的一对一的关联关系
(11).any: 定义any映射类型
(12).map: map类型的集合映射
(13).set: set类型的集合映射
(14).list: list类型的集合映射
(15).array: array类型的集合映射
(16).bag: bag类型的集合映射
(17).primitive-array: primitive-array类型的集合映射
(18).query: 定义装载实体的HQL语句
(19).sql-query: 定义装载实体的SQL语句
(20).synchronize: 定义持久化类所需要的同步资源
(21).query-list: 映射由查询返回的集合
(22).natural-id: 声明一个唯一的业务主键
(23).join: 将一个类的属性映射到多张表中
(24).sub-class: 声明多态映射中的子类
(25).joined-subclass: 生命多态映射中的来连接子类
(26).union-subclass: 声明多态映射中的联合子类
(27).loader: 定义持久化对象的加载器
(28).filter: 定义Hibernate使用的过滤器
(29).component: 定义组件映射
(30).dynamic-component: 定义动态组件映射
(31).properties: 定义一个包含多个属性的逻辑分组
(32).cache: 定义缓存的策略
(33).discriminator: 定义一个鉴别器
(34).meta: 设置类或属性的元数据属性
(35).timestamp: 指定表中包含时间戳的数据
(36).vesion: 指定表所包含的附带版本信息的数据 定义主键:
Hibernate使用OID(对象标识符)来标识对象的唯一性,OID是关系数据库中主键在Java对象模型中的等价物,在运行时,Hibernate根据OID来维持Java对象和数据库表中记录的对应关系
id节点的属性:
(1).name: 指定当前映射对应的持久类的主键名
(2).column: 指定当前映射对应的数据库表中的主键名(默认值为对应持久类的主键/属性名)
(3).type: 指定当前映射对应的数据库表中的主键的数据类型
(4).unsaved-value: 判断此对象是否进行了保存
(5).daccess: Hibernate访问主键属性的策略(默认值为property)- generator节点的属性:
(1).class: 指定主键生成器 - property节点的属性:
用于持久化类的属性与数据库表字段之间的映射,包含如下属性:
(1)name:持久化类的属性名,以小写字母开头
(2)column:数据库表的字段名
(3)type:Hibernate映射类型的名字
(4).formula: 设置当前节点对应的持久类中的属性的值由指定的SQL从数据库获取
注:指定的SQL必须用()括起来,指定SQL中使用列时必须用表的别名加.加列名的方式访问,但如果指定SQL中要使用当前映射对应的列时不能用表的别名加.加列名的方式访问,而是直接访问即可
如:formula="(select tn.columnName from tableName tn where tn.columnName=当前映射中的属性名)"
(5).unique: 设置该字段的值是否唯一(默认值为false)
(6).not-null: 设置该字段的值是否可以为null(默认值为false)
(7).not-found: 设置当当前节点对应的数据库字段为外键时引用的数据不存在时如何让处理(默认值为exception:产生异常,可选值为ignore:对不存在的应用关联到null)
(8).property-ref: 设置关联类的属性名,此属性和本类的关联相对应 默认值为关联类的主键
(9).entity-name: 被关联类的实体名
(10).lazy: 指定是否采用延迟加载及加载策略(默认值为proxy:通过代理进行关联,可选值为true:此对象采用延迟加载并在变量第一次被访问时抓取、false:此关联对象不采用延迟加载)
(11).access: Hibernate访问这个属性的策略(默认值为property)
(12).optimistic-lock: 指定此属性做更新操作时是否需要乐观锁定(默认值为true) - one-to-one节点的属性:
(1).name: 映射类属性的名字
(2).class: 关联类的名字
(3).formula: 绝大多数一对一关联都指向其实体的主键。在某些情况下会指向一个或多个字段或是一个表达式,此时可用一个SQL公式来表示
(4).cascade: 设置级联操作时的级联类型
(5).constrained: 表明当前类对应的表与被关联的表之间是否存在着外键约束 默认值为false
(6).fetch: 设置抓取数据的策略 可选值为 join外连接抓取、select序列选择抓取
(7).property-ref: 设置关联类的属性名,此属性和本类的主键相对应 默认值为关联类的主键
(8).access: Hibernate访问这个属性的策略(默认值为property)
(9).lazy: 指定是否采用延迟加载及加载策略 默认值为proxy通过代理进行关联 可选值为 true此对象采用延迟加载并在变量第一次被访问时抓取、false此关联对象不采用延迟加载
(10).entity-name: 被关联类的实体名 - many-to-one 元素:
(1).name: 映射类属性的名字
(2).class: 关联类的名字
(3).formula: 绝大多数一对一关联都指向其实体的主键。在某些情况下会指向一个或多个字段或是一个表达式,此时可用一个SQL公式来表示
(4).column: 中间关联表映射到目标关联表的关联字段
(5).cascade: 设置级联操作时的级联类型
(6).fetch: 设置抓取数据的策略 默认值为select序列选择抓取 可选值为join外连接抓取
(7).lazy: 指定是否采用延迟加载及加载策略 默认值为proxy通过代理进行关联 可选值为 true此对象采用延迟加载并在变量第一次被访问时抓取、false此关联对象不采用延迟加载
(8).update: 进行update操作时是否包含此字段
(9).insert: 进行insert操作时是否包含此字段
(10).not-found: 指定外键引用的数据不存在时如何让处理 默认值为exception产生异常 可选值为ignore对不存在的应用关联到null - many-to-many 元素
- set 元素
(1).name: 映射类属性的名字
(2).table: 关联的目标数据库表
(3).schema: 目标数据库表的schema名字
(4).catalog: 目标数据库表的catalog名字
(5).subselect: 定义一个子查询
(6).sort: 设置排序的类型 默认值为 unsorted不排序 可选值为 natural自然排序、comparatorClass实现接口类作为排序算法 避免与order-by同时使用
(7).lazy: 是否采用延迟加载
(8).inverse: 用于标识双向关联中被动的一方 默认值为false
(9).cascade: 设置级联操作时的级联类型
(10).mutable: 标识被关联对象是否可以改变 默认值为true
(11).order-by: 设置排序规则
(12).where: 增加筛选条件
(13).batch-size: 延迟加载时,一次读取数据的数量 默认值为1
(14).fetch: 设置抓取数据的策略 可选值为 join外连接抓取、select序列选择抓取 - .list 元素
- map 元素
六.hibernate 大对象类型的hibernate映射
1.说明
- 在 Java 中, java.lang.String 可用于表示长字符串(长度超过 255), 字节数组 byte[] 可用于存放图片或文件的二进制数据. 此外, 在 JDBC API 中还提供了 java.sql.Clob 和 java.sql.Blob 类型, 它们分别和标准 SQL 中的 CLOB 和 BLOB 类型对应. CLOB 表示字符串大对象(Character Large Object), BLOB表示二进制对象(Binary Large Object)
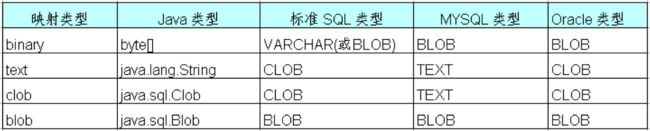
- Mysql 不支持标准 SQL 的 CLOB 类型, 在 Mysql 中, 用 TEXT, MEDIUMTEXT 及 LONGTEXT 类型来表示长度操作 255 的长文本数据
- 在持久化类中, 二进制大对象可以声明为 byte[] 或 java.sql.Blob 类型; 字符串可以声明为 java.lang.String 或 java.sql.Clob
- 实际上在 Java 应用程序中处理长度超过 255 的字符串, 使用 java.lang.String 比 java.sql.Clob 更方便
2.操作
- 如何映射?
若希望精确映射sql类型,可以使用sql-type属性,例如: - 保存二进制blob:
@Test public void testBlob() throws Exception{ News news = new News(); news.setAuthor("cc"); news.setContent("CONTENT"); news.setDate(new Date()); news.setDesc("DESC"); news.setTitle("CC"); InputStream stream = new FileInputStream("Hydrangeas.jpg"); Blob image = Hibernate.getLobCreator(session) .createBlob(stream, stream.available()); news.setImage(image); session.save(news); } - 读取二进制blob:
@Test public void testBlob() throws Exception{ News news = (News) session.get(News.class, 1); Blob image = news.getImage(); InputStream in = image.getBinaryStream(); System.out.println(in.available()); }