Python数据分析之数据预处理
mport pandas as pd
import numpy as np
import random as rnd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inlineimport warnings
warnings.filterwarnings(‘ignore’)
import matplotlib.pyplot as plt
plt.rcParams[‘font.sans-serif’] = [u’SimHei’]
plt.rcParams[‘axes.unicode_minus’] = False
在数据挖掘中,海量的原始数据中存在着大量不完整(有缺失值)、不–致、有异常的数据,严重影响到数据挖掘建模的执行效率,甚至可能导致挖掘结果的偏差,所以进行数据清洗就显得尤为重要,数据清洗完成后接着进行或者同时进行数据集成、转换、规约等–系列的处理,该过程就是数据预处理。
数据预处理的目的:
- 提高数据的质量
- 让数据更好地适应特定的挖掘技术或工具。
数据预处理的主要内容包括数据清洗、数据集成、数据变换和数据规约。
数据清洗
数据清洗主要是删除原始数据集中的无关数据、重复数据,平滑噪声数据,筛选掉与挖掘主题无关的数据,处理缺失值、异常值等。
缺失值处理
对缺失值的处理主要包括三类方法:删除缺失记录、数据插补、不处理。
常用的插补方法
- 均值/中位数/众数插补:根据属性类型,取该属性的均值/中位数/众数进行插补。
- 固定值插补:将缺失的属性值用一-个常量替换。如广州一个工厂普通外来务工人员的“基本工资”属性的空缺值可以用广州市普通外来务工人员工资标准1895元/月。
- 最近邻插补:在记录中找到与缺失样本最接近的样本的该属性值插补。
- 回归方法:对带有缺失值的属性使用已有数据进行回归预测,使用模型预测值来插补缺失值。
- 插值法:利用样本点建立插值函数 f ( x ) f(x) f(x),未知值由对应的 f ( x ) f(x) f(x)给出。
拉格朗日插值法
由泰勒定理,任意函数可用足够高阶的多项式和近似,即f(x)=\sum_{i=0}^n a_ix^if(x)=i=0∑naixi
插值法就是使用某一自变量(通常是index或者序数)计算另一属性的缺失值y_j=f(x_j)yj=f(xj)
因此,需要求解插值函数 f ( x ) f(x) f(x)的表达式,即求解 a _ i , i = 0 , 1 , . . . , n a\_i,i=0,1,...,n a_i,i=0,1,...,n,这需要 n + 1 n+1 n+1个样本点 ( x _ j , y _ j ) , j = 1 , 2 , . . . , n + 1 (x\_j,y\_j),j=1,2,...,n+1 (x_j,y_j),j=1,2,...,n+1,将样本点代入上述方程a_0+a_1x_1+a_2x_12+…+a_nx_1n=y_1a0+a1x1+a2x12+…+anx1n=y1a_0+a_1x_2+a_2x_22+…+a_nx_2n=y_2a0+a1x2+a2x22+…+anx2n=y2…a_0+a_1x_{n+1}+a_2x_{n+1}2+…+a_nx_{n+1}n=y_{n+1}a0+a1xn+1+a2xn+12+…+anxn+1n=yn+1
显然以上线性方程组的系数矩阵为范德蒙矩阵,因此,有唯一解,即有唯一 f ( x ) f(x) f(x),在实际计算中,直接求解上述矩阵比较复杂。拉格朗日插值法应运而生,拉格朗日插值法实际上是一种求 f ( x ) f(x) f(x)的计算方法:f(x)=\sum_{i=1}^{n+1} y_i\prod_{j\neq i}\frac{(x-x_j)}{(x_i-x_j)}f(x)=i=1∑n+1yij=i∏(xi−xj)(x−xj)
观察上式可以发现,这是一个x的n阶多项式,且过点所有 ( x _ m , y _ m ) (x\_m,y\_m) (x_m,y_m),即上式即为所求。
插值实例
df = pd.read\_excel('Python数据分析与挖掘实战/chapter3/demo/data/catering\_sale.xls')
df.head(3)
| 日期 | 销量 | |
|---|---|---|
| 0 | 2015-03-01 | 51.0 |
| 1 | 2015-02-28 | 2618.2 |
| 2 | 2015-02-27 | 2608.4 |
df.isnull().sum()
日期 0
销量 1
dtype: int64
可以看出,销量存在缺失值,使用拉格朗日法对缺失值进行插补,首先将异常值过滤为缺失值,然后对每一列的缺失值进行插值,插值的自变量为缺失值的前后k个数据的index。
from scipy.interpolate import lagrange
df[‘销量’][(df[‘销量’] < 400) | (df[‘销量’] > 5000)] = None # 过滤异常值,将其变为空值
def lagrange_(s,n,k=4):
“”"
s:需要插值的列
n:缺失值的index
k:插值使用前后k个数据
“”"
l = list(range(n-k,n)) + list(range(n+1,n+1+k))
y = s[[i for i in l if i >=0]] #取出前后k项数据的值
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(j)#对整个datafram进行插值
for i in df.columns:
for j in range(len(df)):
if df[i].isnull()[j]:
df[i][j]=lagrange_(df[i],j)
df.to_excel(‘outputfile.xlsx’)
异常值处理
| 异常值处理方法 | 方法描述 |
|---|---|
| 删除含有异常值的记录 | 直接将含有异常值的记录删除 |
| 视为缺失值 | 将异常值视为缺失值,利用缺失值处理的方法进行处理 |
| 平均值修正 | 可用前后两个观测值的平均值修正该异常值 |
| 不处理 | 直接在具有异常值的数据集.上进行挖掘建模 |
数据集成
- 数据集成:将多个数据源合并存放在一个一致的数据存储(如数据仓库)中的过程。
数据挖掘需要的数据往往分布在不同的数据源中,这时需要进行数据集成。在数据集成时,来自多个数据源的现实世界实体的表达形式是不一样的,有可能不匹配,要考虑实体识别问题和属性冗余问题,从而将源数据在最低层上加以转换、提炼和集成。
实体识别
-
实体识别:从不同数据源识别出现实世界的实体,它的任务是统一不同源数据的矛盾之处,常见形式如下:
- 同名异义:数据源A中的属性ID和数据源B中的属性ID分别描述的是菜品编号和订单编号,即描述的是不同的实体。
- 异名同义:数据源A中的sales__dt和数据源B中的sales_date都是描述销售日期的,即A.sales__dt=B.sales_date。
- 单位不统一:描述同一个实体分别用的是国际单位和中国传统的计量单位。
检测和解决这些冲突就是实体识别的任务。
冗余属性识别
数据集成往往导致数据冗余,例如:
- 同一属性多次出现;
- 同–属性命名不一致导致重复。
仔细整合不同源数据能减少甚至避免数据冗余与不一致,从而提高数据挖掘的速度和质量。对于冗余属性要先分析,检测到后再将其删除。
有些冗余属性可以用相关分析检测。给定两个数值型的属性A和B,根据其属性值,用相关系数度量一个属性在多大程度上蕴含另一一个属性。
数据变换
数据变换主要是对数据进行规范化处理,将数据转换成“适当的”形式,以适用于挖掘任务及算法的需要。
简单函数变换
简单函数变换是对原始数据进行某些数学函数变换,常用的变换包括平方、开方、取对数、差分运算等,即:
x’=x^2x′=x2x’=\sqrt xx′=xx’=log xx′=logxx’=f(x_{k+1})-f(x_{k})x′=f(xk+1)−f(xk)
规范化
- 数据规范化(归一化):对数据进行标准化处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析。
归一化处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲,数值间的差别可能很大,不进行处理可能会影响到数据分析的结果。为了消除指标之间的量纲和取值范围差异的影响,需要进行归一化。如将工资收入属性值映射到[-1,1]或者[0,1]内。数据规范化对于基于距离的挖掘算法尤为重要。
- 最小-最大规范化(MinMaxScaler)
x’=\frac{x-x_{min}}{x_{max}-x_{min}}x′=xmax−xminx−xmin
from sklearn.preprocessing import MinMaxScaler
data = pd.read_excel(‘Python数据分析与挖掘实战/chapter4/demo/data/normalization_data.xls’,header=None)
data
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 78 | 521 | 602 | 2863 |
| 1 | 144 | -600 | -521 | 2245 |
| 2 | 95 | -457 | 468 | -1283 |
| 3 | 69 | 596 | 695 | 1054 |
| 4 | 190 | 527 | 691 | 2051 |
| 5 | 101 | 403 | 470 | 2487 |
| 6 | 146 | 413 | 435 | 2571 |
scaler = MinMaxScaler().fit(data)
pd.DataFrame(scaler.transform(data))
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0.074380 | 0.937291 | 0.923520 | 1.000000 |
| 1 | 0.619835 | 0.000000 | 0.000000 | 0.850941 |
| 2 | 0.214876 | 0.119565 | 0.813322 | 0.000000 |
| 3 | 0.000000 | 1.000000 | 1.000000 | 0.563676 |
| 4 | 1.000000 | 0.942308 | 0.996711 | 0.804149 |
| 5 | 0.264463 | 0.838629 | 0.814967 | 0.909310 |
| 6 | 0.636364 | 0.846990 | 0.786184 | 0.929571 |
- 零均值规范化(StandardScaler)
x’=\frac{x-\mu}{\sigma}x′=σx−μ
依然使用上述数据:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(data)
pd.DataFrame(scaler.transform(data))
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | -0.977926 | 0.686811 | 0.501751 | 0.862099 |
| 1 | 0.653127 | -1.714885 | -2.368891 | 0.398987 |
| 2 | -0.557806 | -1.408513 | 0.159216 | -2.244798 |
| 3 | -1.200342 | 0.847495 | 0.739480 | -0.493515 |
| 4 | 1.789922 | 0.699666 | 0.729255 | 0.253609 |
| 5 | -0.409529 | 0.434001 | 0.164329 | 0.580335 |
| 6 | 0.702553 | 0.455425 | 0.074861 | 0.643283 |
连续变量离散化
一些数据挖掘算法,特别是某些分类算法( 如ID3算法、Apriori 算法等),要求数据是分类属性形式。这样,常常需要将连续变量变换成分类变量,即连续变量离散化。
离散化的基本方法
离散化的基本方法就是将连续变量的值区间划分为若干个区间,用不同符号代表不同区间中的值。
常用离散化的方法
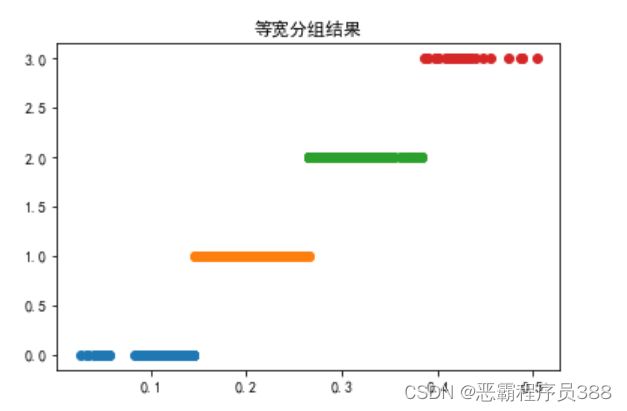
- 等宽分组:将值域划分为宽度相等的区间,区间个数由用户指定,类似于制作频率分布表。
下面将“肝气郁结证型系数”数据划分为4个不同的类。
data = pd.read_excel(‘Python数据分析与挖掘实战/chapter4/demo/data/discretization_data.xls’)
data.head(3)
| 肝气郁结证型系数 | |
|---|---|
| 0 | 0.056 |
| 1 | 0.488 |
| 2 | 0.107 |
k=4
r = pd.cut(data\['肝气郁结证型系数'\],k,labels=range(k))
for i in range(4):
plt.plot(data\[r==i\],\[i\]\*(data\[r==i\].count()\['肝气郁结证型系数'\]),'o')
p = plt.title('等宽分组结果')
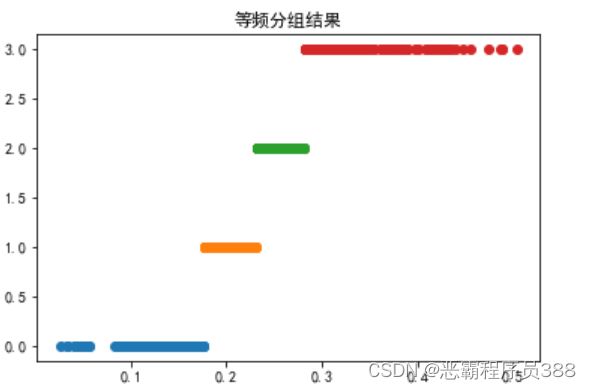
- 等频分组:分组后每个区间数据量相同。
r = pd.qcut(data[‘肝气郁结证型系数’],k,labels=range(k))
for i in range(k):
plt.plot(data[ri],[i]*(data[ri].count()[‘肝气郁结证型系数’]),‘o’)
p = plt.title(‘等频分组结果’)
- 聚类分组:使用聚类算法进行分组。
from sklearn.cluster import KMeans
KM = KMeans(n\_clusters=k).fit(data\['肝气郁结证型系数'\].values.reshape(len(data\['肝气郁结证型系数'\].values),1))
r = KM.labels\_
for i in range(k):
plt.plot(data\[r==i\],\[i\]\*(data\[r==i\].count()\['肝气郁结证型系数'\]),'o')
p = plt.title('等频分组结果')
属性构造
在数据挖掘的过程中,为了提取更有用的信息,挖掘更深层次的模式,提高挖掘结果的精度,我们需要利用已有的属性集构造出新的属性,并加入到现有的属性集合中。比如,进行防窃漏电诊断建模时,已有的属性包括供入电量、供出电量(线路上各大用户用电量之和)。理论上供入电量和供出电量应该是相等的,但是由于在传输过程中存在电能损耗,使得供入电量略大于供出电量,如果该条线路上的一个或多个大用户存在窃漏电行为,会使得供入电量明显大于供出电量。
为了判断是否有大用户存在窃漏电行为,可以构造出一个新的指标——线损率,该过程就是构造属性。新构造的属性线损率按如下公式计算。线损率=\frac{供入电量-供出电量}{供入电量}\times100\%线损率=供入电量供入电量−供出电量×100%线损率的正常范围一般在3%~15%,如果远远超过该范围,就可以认为该条线路的大用户很可能存在窃漏电等用电异常行为。
数据规约
在大数据集上进行复杂的数据分析和挖掘需要很长的时间,数据规约产生更小但保持原数据完整性的新数据集。在规约后的数据集上进行分析和挖掘将更有效率。数据规约的意义在于:
- 降低无效、错误数据对建模的影响,提高建模的准确性;
- 少量且具代表性的数据将大幅缩减数据挖掘所需的时间;
- 降低储存数据的成本。
特征规约
特征规约通过特征合并来创建新特征,或者直接通过删除不相关的特征(维)来减少数据维数,从而提高数据挖掘的效率、降低计算成本。特征规约的目标是寻找出最小的特征子集并确保新数据子集的概率分布尽可能地接近原来数据集的概率分布。特征规约有合并特征、向前选择、向后删除、主成分分析等方法。
简单来说,特征规约就是减少数据列数。
- 主成分分析的python实现
逐步向前选择、逐步向后删除和决策树归纳是属于直接删除不相关属性(维)方法。主成分分析是一种用于连续属性的数据降维方法,它构造了原始数据的-一个正交变换,新空间的基底去除了原始空间基底下数据的相关性,只需使用少数新变量就能够解释原始数据中的大部分变异。在应用中,通常是选出比原始变量个数少,能解释大部分数据中的变量的几个新变量,即所谓主成分,来代替原始变量进行建模。
data = pd.read_excel(‘Python数据分析与挖掘实战/chapter4/demo/data/principal_component.xls’,header=None)
data.head(3)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 40.4 | 24.7 | 7.2 | 6.1 | 8.3 | 8.7 | 2.442 | 20.0 |
| 1 | 25.0 | 12.7 | 11.2 | 11.0 | 12.9 | 20.2 | 3.542 | 9.1 |
| 2 | 13.2 | 3.3 | 3.9 | 4.3 | 4.4 | 5.5 | 0.578 | 3.6 |
data.shape
(14, 8)
from sklearn.decomposition import PCA
pca = PCA(n_components=3).fit(data)
data_pca = pca.transform(data)
data_pca,pca.explained_variance_ratio_.sum()
(array([[ 8.19133694, 16.90402785, 3.90991029],
[ 0.28527403, -6.48074989, -4.62870368],
[-23.70739074, -2.85245701, -0.4965231 ],
[-14.43202637, 2.29917325, -1.50272151],
[ 5.4304568 , 10.00704077, 9.52086923],
[ 24.15955898, -9.36428589, 0.72657857],
[ -3.66134607, -7.60198615, -2.36439873],
[ 13.96761214, 13.89123979, -6.44917778],
[ 40.88093588, -13.25685287, 4.16539368],
[ -1.74887665, -4.23112299, -0.58980995],
[-21.94321959, -2.36645883, 1.33203832],
[-36.70868069, -6.00536554, 3.97183515],
[ 3.28750663, 4.86380886, 1.00424688],
[ 5.99885871, 4.19398863, -8.59953736]]),
0.9737201283709646)
可以看出原始数据从8维降到3维,并包含了原数据97%的信息。
数值规约
数值规约指通过选择替代的、较小的数据来减少数据量,包括有参数方法和无参数方法两类。有参数方法是使用一个模型来评估数据,只需存放参数,而不需要存放实际数据,例如回归(线性回归和多元回归)和对数线性模型(近似离散属性集中的多维概率分布)。无参数方法就需要存放实际数据,例如直方图、聚类、抽样(采样)。
例如,抽样、分箱等都属于数值规约方法。``
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等习教程。带你从零基础系统性的学好Python!
一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、入门学习视频

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、python副业兼职与全职路线

上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码 即可领取↓↓↓
[[CSDN大礼包:《python兼职资源&全套学习资料》免费分享]](安全链接,放心点击)
