目标检测||速览
元学习论文总结||小样本学习论文总结
2017-2019年计算机视觉顶会文章收录 AAAI2017-2019 CVPR2017-2019 ECCV2018 ICCV2017-2019 ICLR2017-2019 NIPS2017-2019
目录
一:基础概念
二:两种方法
2.1两阶段法
R-CNN
SPP Net
Fast R-CNN
PFN
Mask R-CNN
2.2 一阶段法
YOLO
SSD
DSSD
RetinaNet
总结
一:基础概念
目标检测问题
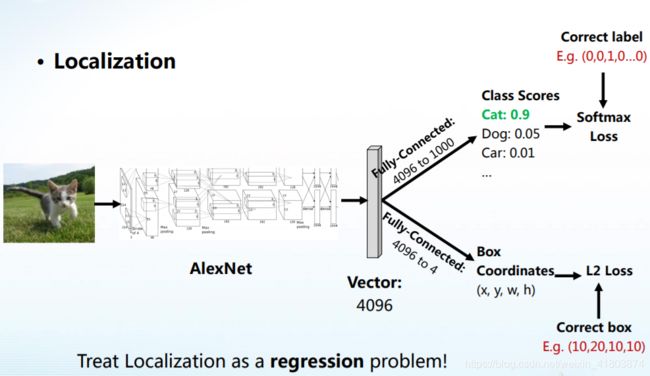
方法类别

首先预定义类别集合

任务分为单目标和多目标检测
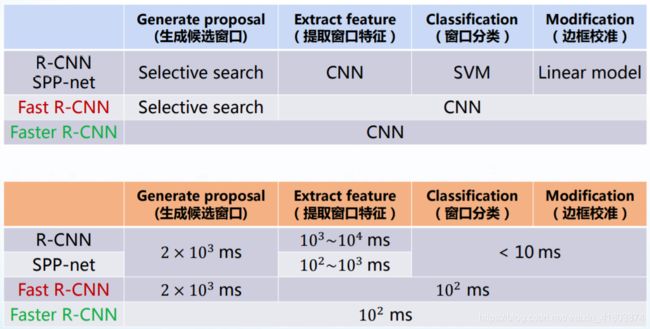
原始方法多为从图像中clip足够多的框,丢到cnn分类器中分类,区分目标和背景。缺点是:Need to apply CNN to huge number of locations and scales, very computationally expensive。
另一种方法,期望查找可能包含对象的图像区域,相比上一种方法加快了速度和效率

二:两种方法
两阶段法:1.生成候选框 2.分类调整候选框,得到最后的目标标定
一阶段法:直接得到最终的目标标定

2.1两阶段法
R-CNN
R-CNN法,注意将候选区域变形为(分类网络要求的输入尺寸)放到CNN中分类。每张图像生成2千个候选框。
Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation. In: CVPR, 2014

算法流程,Fast R-CNN

广义R-CNN框架
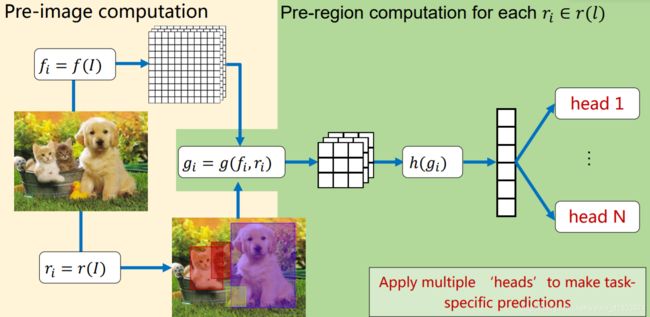
R-CNN的缺点,一个是太慢47秒/每张;一个因为要调整图像大小,可能带来特征的丢失

SPP Net
与R-CNN不用的是,不进行手动图像变形。而是使用卷积池化的功能变形图像到合适大小。SPP(金字塔形空间池化?)
He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition. In: PAMI, 2015.

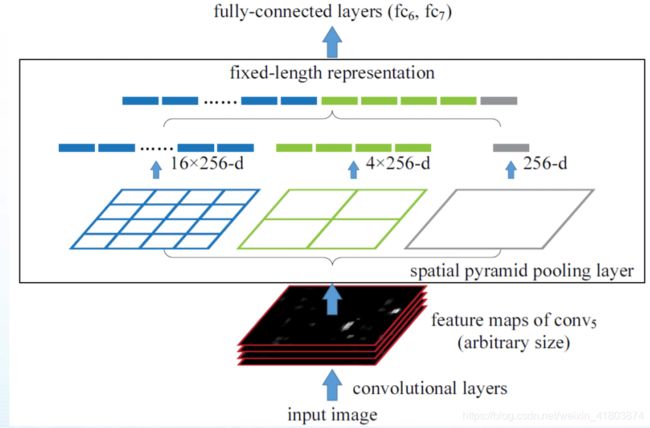
模型原理:卷积层的参数和输入大小无关,它仅仅是一个卷积核在图像上滑动,不管输入图像多大都没关系,只是对不同大小的图片卷积出不同大小的特征图。SPP-Net在最后一个卷积层后,接入了金字塔池化层,使用这种方式,可以让网络输入任意的图片,而且还会生成固定大小的输出。
从整体过程来看,就是如图二所示。黑色图片代表卷积之后的特征图,接着我们以不同大小的块来提取特征,分别是4*4,2*2,1*1,将这三张网格放到下面这张特征图上,就可以得到16+4+1=21种不同的块(Spatial bins),我们从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。这种以不同的大小格子的组合方式来池化的过程就是空间金字塔池化(SPP)。比如,要进行空间金字塔最大池化,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出单元,最终得到一个21维特征的输出。所以Conv5计算出的feature map也是任意大小的,经过SPP之后,就可以变成固定大小的输出了,以上图为例,一共可以输出(16+4+1)*256的特征。
与R-CNN对比,速度快了很多

SPP Net也要问题:1.将模型分成了多个步骤 2. 检测速度还是不够

Fast R-CNN
两个改进:1.简化了spp的流程 2. 将多目标检测只用一个模型来实现
Girshick R. Fast r-cnn. In: ICCV, 2015.
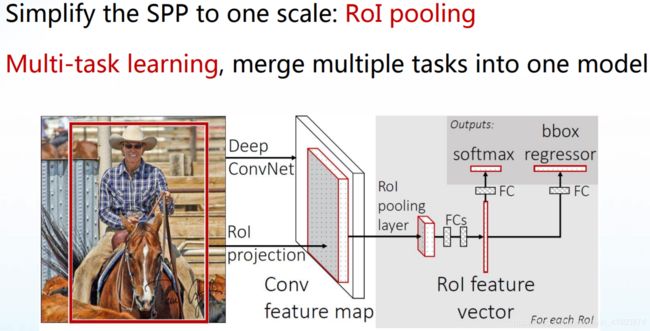
相比原始R-CNN不同的结构:FPN
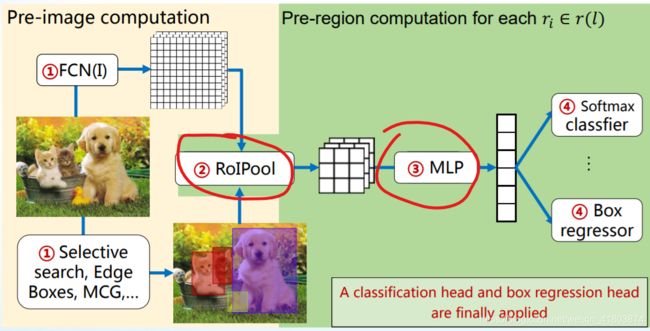
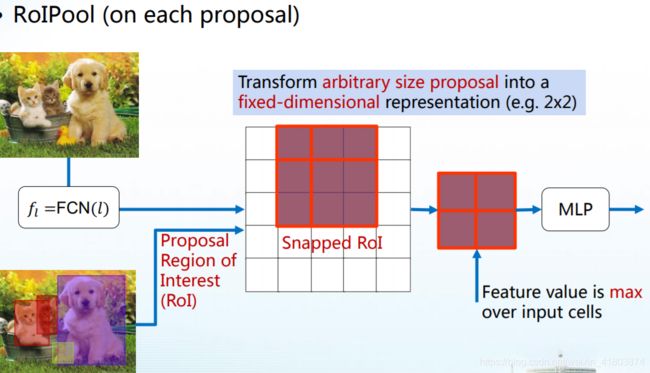
首先是ROIPooling(Region of Interest Pooling)
对结构的优化:

缺点:RoI的区域召回率很低?对VOC性能还行但是对COCO就表现不好。有时候RoI会很慢。
更多细节:Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks. In: NIPS, 2015.
RPN的改进
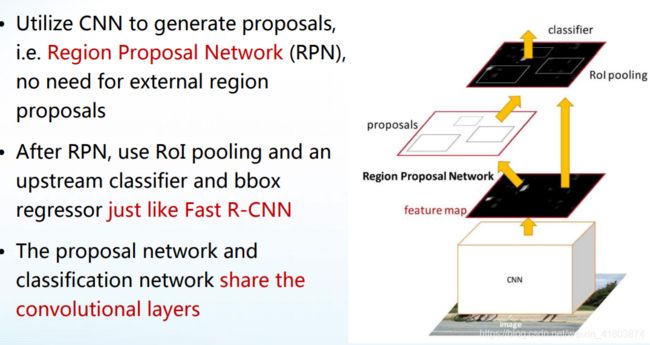
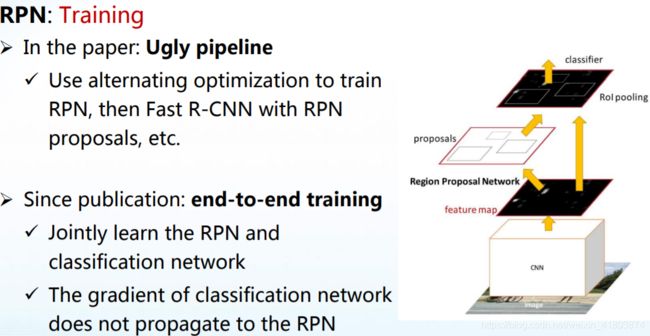
RPN的结构
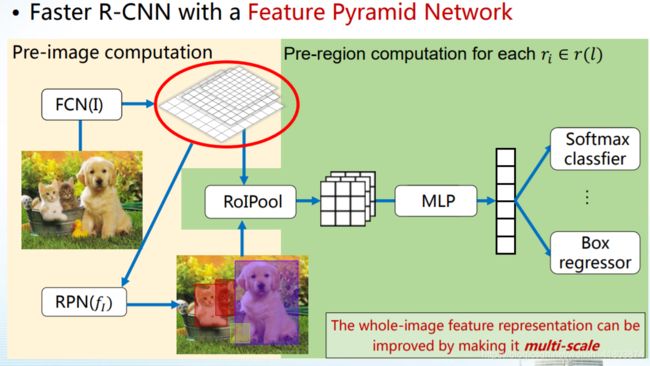
PFN
Feature Pyramid Network (FPN)
Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection. In: CVPR, 2017
检测器需要在大范围内对对象进行分类和定位,PFN提升了这个能力

通过对图像进行多尺度处理,可以改善图像的整体特征表示,对比
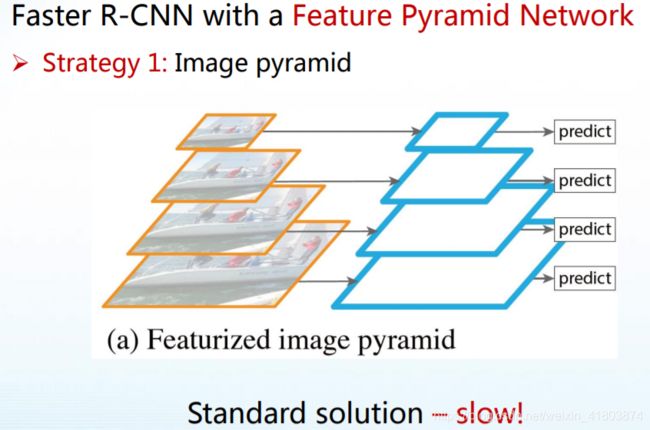
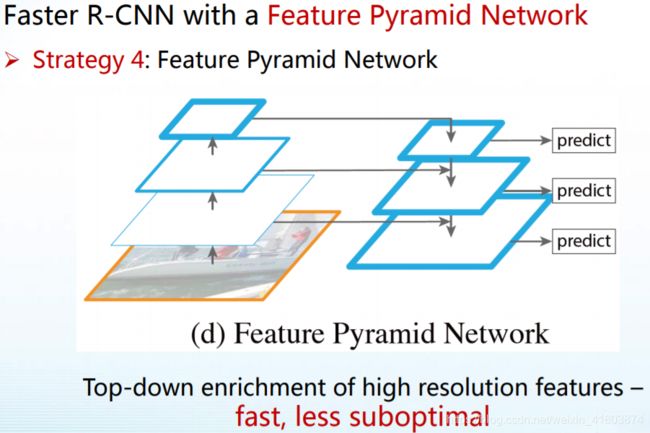
FPN的工作:



Mask R-CNN
替换RoIPooling
He K, Gkioxari G, Dollár P, et al. Mask r-cnn. In: ICCV, 2017.(Best Paper)
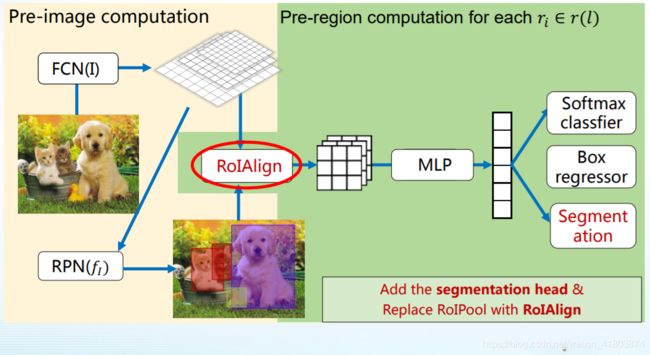
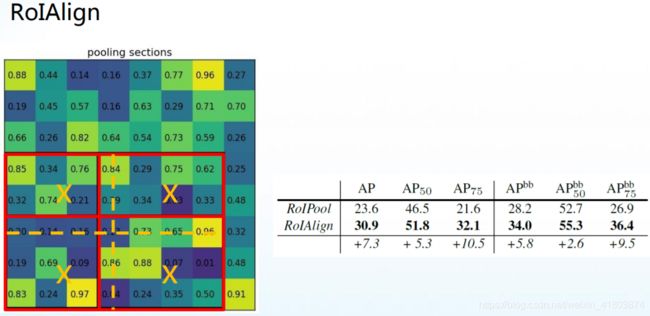
总结两阶段法

2.2 一阶段法
YOLO
YOLO: You Only Look Once
Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection. In: CVPR, 2016
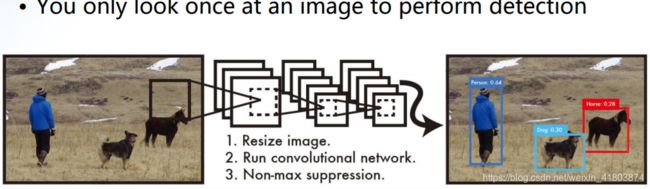
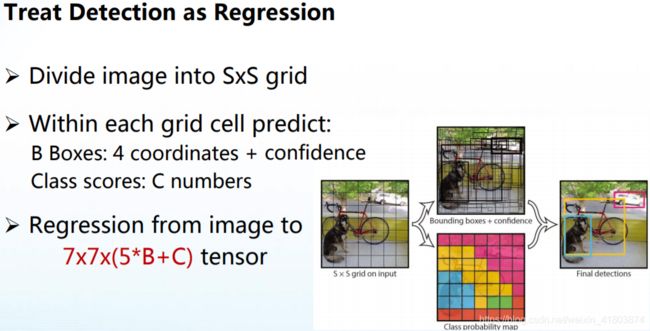
将检测视为回归问题

SSD
SSD: Single-Shot multibox Detector 单次多框检测
Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector. In: ECCV, 2016
由Fast R-CNN驱动,不同纵横比的默认框;多尺度:根据不同尺度的特征图进行预测
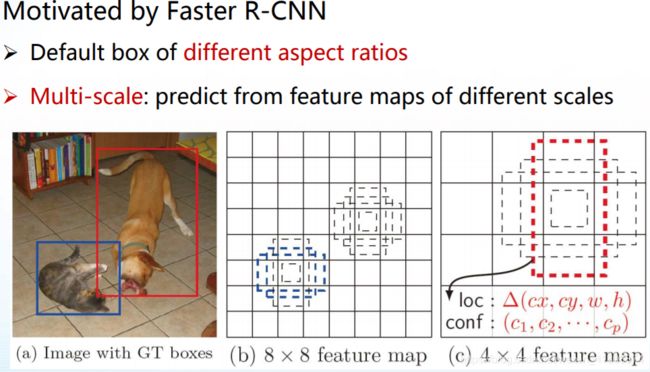
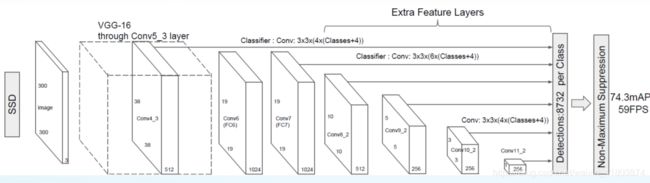

DSSD
Fu C Y, Liu W, Ranga A, et al. Dssd: Deconvolutional single shot detector
DSSD: Deconvolutional Single Shot Detector反卷积SSD(上采样,把特征图像变大)
动机:为小目标检测提供更多的上下文信息

RetinaNet
Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection. In: ICCV, 2017
单阶段检测器在精度上通常比两阶段检测器差,主要原因:样本不平衡。背景区域比对象区域要多得多;大部分的背景区域容易与物体区分,无法为学习提供足够的指导。


总结单阶段

总结
