【人工智能实验室】训练中超参数
注:下述内容学习自这篇博客 (98条消息) 深度学习超参数介绍及调参_xu_fu_yong的专栏-CSDN博客_深度学习超参数
---------------------------------------------------------------------------------------------------------------------------
(1)超参数介绍
① 通常是手工设定,不断试错调整;
②超参数是在开始学习过程之前或者训练中设置值的参数,需要为它根据已有或现有的经验指定“正确”的值,也就是人为为它设定一个值,它不是通过系统学习得到的;
③模型参数通常是有数据来驱动调整,超参数则不需要数据来驱动。
(2)深度学习中包含哪些参数
通常可以将超参数分为三类:网络参数、优化参数、正则化参数。
网络参数:可指网络层与层之间的交互方式(相加、相乘或者串接等)、卷积核数量和卷积核尺寸、网络层数(也称深度)和激活函数等。
优化参数:一般指学习率(learning rate)、批样本数量(batch size)、不同优化器的参数以及部分损失函数的可调参数。
正则化:权重衰减系数,丢弃法比率(dropout)。
(3)为什么要参数调优
①平衡模型优化寻找最优解和正则项之间的关系(正则项的引入是为了解决过拟合问题),模型优化希望最小化经验风险,而容易陷入过拟合,正则项用来约束模型复杂度;
②网络模型优化调整的目的是为了寻找到全局最优解(或者相比更好的局部最优解),而正则项又希望模型尽量拟合到最优;
③如何平衡两者之间的关系,得到最优或者较优的解就是超参数调整优化的目的。
(4)超参数的重要性顺序
① !!学习率!!:直接控制着训练中网络梯度更新的量级,也可以称作步长,按照我的理解是更新参数的限度,比如权重由5更新到1比权重由5更新到4的学习率限度更大,也即权重更新的范围更大。
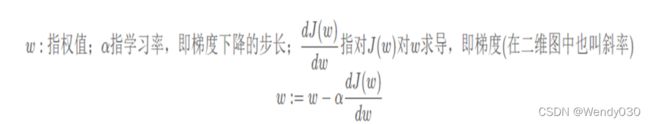
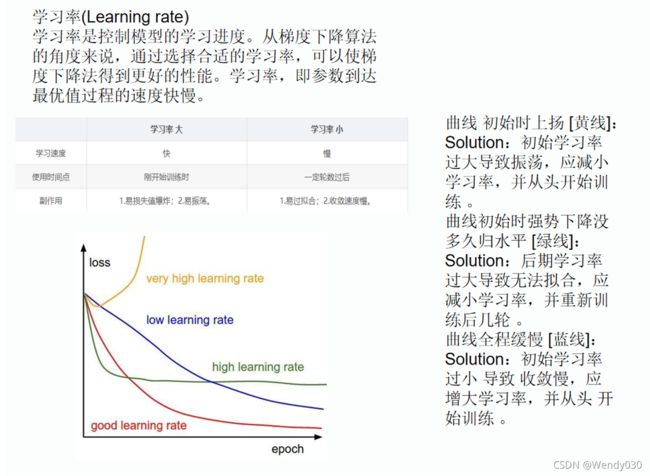
通常情况下,一个或者一组优秀的学习率既能加速模型的训练,又能得到一个较优甚至最优的精度。过大或者过小的学习率会直接影响到模型的收敛。
损失函数上的可调参数:需要结合实际的损失函数来调整,大部分情况下这些参数也能很直接的影响到模型的的有效容限能力。可分为如下三类:
第一类,辅助损失结合常见的损失函数:起到辅助优化特征表达的作用。例如度量学习中的Center loss,通常结合交叉熵损失伴随一个权重完成一些特定的任务。这种情况下一般建议辅助损失值不高于或者不低于交叉熵损失值的两个数量级;
第二类,多任务模型的多个损失函数:每个损失函数之间或独立或相关,用于各自任务,这种情况取决于任务之间本身的相关性;
第三类,独立损失函数:这类损失通常会在特定的任务有显著性的效果。例如RetinaNet中的focal loss,其中的参数γ,α,对最终的效果会产生较大的影响。这类损失通常论文中会给出特定的建议值。
②批样本数量:定了数量梯度下降的方向。过小的批数量,极端情况下,如batch size为1,即每个样本都去修正一次梯度方向,样本之间的差异越大越难以收敛。若网络中存在BN,batch size过小则更难以收敛,甚至垮掉,这是因为数据样本越少,统计量越不具有代表性,噪声也相应的增加。而过大的batch size,会使得梯度方向基本稳定,容易陷入局部最优解,降低精度。一般参考范围会取在[1:1024]之间,当然这个不是绝对的,需要结合具体场景和样本情况。
Batch Size定义:一次训练所选取的样本数。
Batch Size的大小影响模型的优化程度和速度。同时其直接影响到GPU内存的使用情况,假如你GPU内存不大,该数值最好设置小一点。
动量优化器的动量参数β:计算梯度的指数加权平均数,并利用该值来更新参数,设置为 0.9 是一个常见且效果不错的选择。
③Adam优化器的超参数:Adam优化器中的β1,β2,ϵ,常设为 0.9、0.999、10−8就会有不错的表现。
权重衰减系数:通常会有个建议值,例如0.0005 ,使用建议值即可,不必过多尝试。
丢弃法比率(dropout):通常会在全连接层之间使用防止过拟合,建议比率控制在[0.2,0.5]之间。使用dropout时需要特别注意两点:一、在RNN中,如果直接放在memory cell中,循环会放大噪声,扰乱学习,一般会建议放在输入和输出层;二、不建议dropout后直接跟上batchnorm,dropout很可能影响batchnorm计算统计量,导致方差偏移,这种情况下会使得推理阶段出现模型完全垮掉的极端情况。
网络参数:通常情况下增加网络层数能增加模型的容限能力,但模型真正有效的容限能力还和样本数量和质量、层之间的关系等有关,所以一般情况下会选择先固定网络层数,调优到一定阶段或者有大量的硬件资源支持可以在网络深度上进行进一步调整。
(第③部分不建议实践中过多尝试,下图为转载内容)

