MySQL数据库复习(前三章)
文章目录
- 一二章手写笔记
- 关系型数据库标准语言SQL
-
- SQL体系结构
- 基本表的操作
- 对表的结构进行修改
- select 语句
-
- 常见的查询条件
- 使用集函数
- 排序
- 连接
- limit子句
- 嵌套循环
-
- 带有any和all的子查询
- 带有exists的子查询
- 除运算
- 数据更新
-
- 插入数据
- 修改数据
- 删除数据
- 数据控制
-
- 授权
- 回收
- 视图
一二章手写笔记

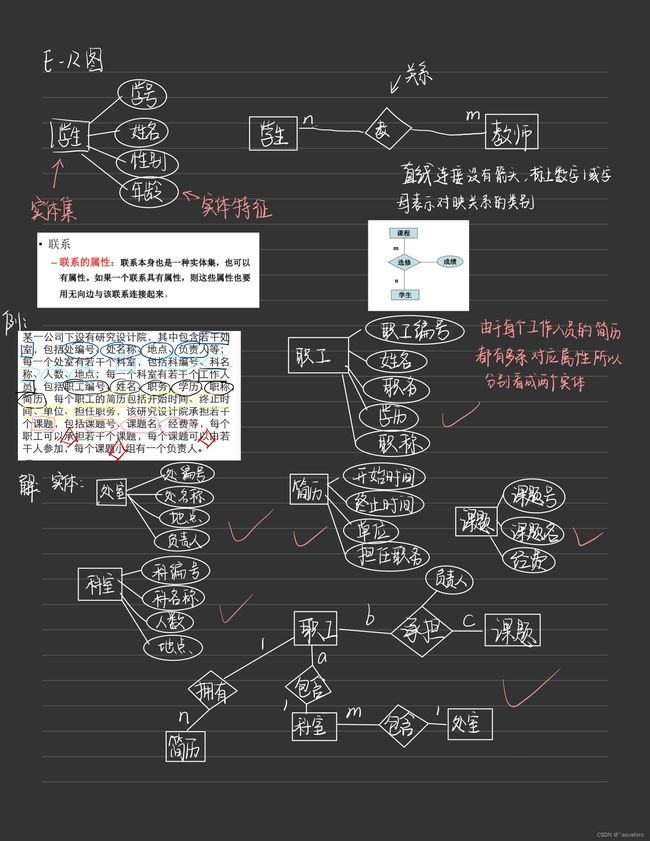






关系型数据库标准语言SQL
SQL体系结构
用户
视图:是从一个或几个基本表(或视图)导出的表,对应外模式
基本表:是数据库中实际存在的关系,对应模式
存储文件:基本表在存储介质上的物理存储文件
基本表的操作
| 操作对象 | 创建 | 删除 | 修改 |
|---|---|---|---|
| 表 | create table | drop table | alter table |
| 视图 | create view | drop view | |
| 索引 | create index | drop index |
常见的数据类型
- 定长和变长字符串 char(n) varchar(n)
- 定长和变长二进制串 binary(n) varbinary(n)
- 整型数 int 半长整型 smallint
- 浮点型 float double
- 日期型 date
- 时间型 time
- 时标
常用完整性约束
- 实体完整性
- 主码约束: primary key
- 参照完整型约束
- 外码约束:foreign key
- 用户自动定义完整性
- 唯一性约束:unique
- 非空值约束
注意:
主码primary key可以直接加在需要约束的属性的后面,也可以primary key(属性1,属性2)(多属性时)
外码直接在要约束的属性后加references(注意加s)表名(属性)
或者foreign key (属性) references 表名(属性)
例:
第一种:
use library;
create table Book
(
BookId int primary key,
Title char(20) not null,
PublisherName char(15) references publisher(name)
);
第二种:
create table author
(
bookid int,
author char(10),
PRIMARY KEY (bookid, author),
foreign key (bookid) references book(bookid)
);
基本表的删除就是
use 表(view);
drop table (view)表名
基本表的修改
| 动作 | 关键字 |
|---|---|
| 增加新列或完整性约束 | add |
| 删除列或完整性 | drop |
| 修改列名和数据结构 | modify |
例:
向表中插入数据
use library;
insert into book values (1, '数据库原理与应用', '清华出版社');
insert into book values (2, '计算机算法设计与分析','中国工信出版社');
insert into book values (3, '人工智能', '清华大学出版社');
增加一个表格
use library;
create table norelation
(
id int primary key,
present varchar(20)
);
对表的结构进行修改
增加一列
use library;
alter table norelation
add 姓名 varchar(4);
alter table norelation
add 年龄 int;
增加外码约束条件
alter table norelation
add foreign key (姓名) references publisher(name);
修改类型
alter table norelation
modify 年龄 smallint;
删除一列
alter table norelation
drop 年龄;
删除一个表
use norelation;
drop table norelation;
删除约束时,当一个表有多个同类型的约束
方法:
- 通过系统指定的名称
通过
show create table 学习;
这个操作可以将约束的名称显示,通过用约束的名来进行删除
- 给约束取名称
alter table 学习 add constraint sno_fkey
foreign key(学号) references 学生(学号);
删除操作
alter table 学习 drop foreign key sno_fkey;
索引的建立与删除
索引: 索引是根据关系表中某些字段的值按照一定结构存放的文件。
简单来说,就是将表中的一行只拿出主码出来,使用另外一张表将主码和这个主码对应的行的地址存成一行,这样找原来的一行时就用主码现在索引表中找,通过地址直接直捣黄龙。

索引的分类:
- 聚集索引
- 表中的记录按照搜索码指定的顺序排列,而搜索码对应的索引称为聚集索引。
- 每个表
只能有一个聚集索引
- 非聚集索引
- 搜索码指定的顺序与表中记录的物理顺序不同
- 每个表可以有多个非聚集索引
索引原理
索引语句的格式
create [unique][cluster] index<索引名> on <表名>
(<列名><次序>,[<列名><次序>])
- 用表名指定要建立索引的基本表的名字
- 所以可以建立在一列或者多列上
- <次序>是索引值得排列顺序
- unique表明索引每一个索引值只能对应唯一的数据记录
- cluster表明要建立的是聚集索引
例:
create unique index scno on 学习
(学号 asc, 课程号 desc)
唯一值索引:对已经有重复的属性列不能在建unique索引
建立unique索引后dbms会检查后面的插入的数据是否会重复
聚集索引:建立聚集索引后,表中的数据会按照指定属性值升序或降序存放
技巧:
- 小型表建立索引对性能没有提高
- 大型字段和经常修改的字段不要建立索引
select 语句
select 指定要显示的属性列
from 指定查询对象
where 查询条件
group by 对查询结果按指定列的值分组,该属性列相等的元组为一个组
having 筛选只有满足条件的组
order by <列名> [asc | desc]对查询结果按指定列值的升序或降序排序
在实际的上用数据库产品中: 不删除重复元祖
在select子句中使用distinct 短语可以去除重复元组
常见的查询条件
| 查询条件 | 谓词 |
|---|---|
| 确定范围 | between and , not between and |
| 字符串匹配 | like, not like |
| 空值 | is null, not null |
- 确定范围
例: 查询出生年份在1996到1998年之间(包含)的学生姓名、性别、学院和出生年份
select 姓名,性别,学院,出生年份
from 学生
where 出生年份 between 1996 and 1998;
not between and 不包含1996和1998
- 字符串匹配
like '<匹配串>' [escape '<转义字符>']
<匹配串>:指定匹配模板
%代表任意长度
_代表任意单个字符
escape短语
当用户要查的字符串本身就含有%或者_时,要用’'转移字符或者用escape定义转义字符
例如:
查询课程名为 漫画鉴赏_推子 的课程
select 课程号,课程名
from 课程
where 课程名 like '漫画鉴赏*_%推%子' escap'*';
3.判断空值
‘is null’ 不能用‘=null’代替
使用集函数
5类主要集函数
计数
count([distinct | all] * | <列名>)
计算总和
sum([distinct | all] <列名>)
计算平均值
avg([distinct | all] <列名>)
求最大值
max([distinct | all] <列名>)
求最小值
min([distinct | all] <列名>)
distinct:计算时不计入重复值
all:不取消重复值(缺省值)
集函数的作用对象:
- 未对查询结果分组,集函数将作用于整个查询结果
- 对查询结果分组后,集函数将分别作用于每个组
having子句
这有满足having短语指定条件的组才输出
having短语与where子句的区别:作用对象不同
- where子句作用于基表或视图,从中选择则满足条件的元组
- having短语作用于组,从中选择满足条件的组
例:查询选课人数超过5人的课程的课程号及课程名;(课程号, 课程名)
select 课程.课程号, 课程名
from 课程
inner join 学习 on 课程.课程号 = 学习.课程号
group by 课程.课程号, 课程名
having count(学习.课程号) > 5;
排序
使用order by子句
- 可以按一个或多个属性排序
- 升序:asc;降序:desc;缺省值为升序
- asc:排列为空值的元祖最先显示,desc相反
例:
查询选修课程"经济学"的学生姓名和所在院系,结果按个院系排列,同时成绩从高到低排列(姓名,学院名称,成绩)
select 姓名, 学院名称, 成绩
from 学生
inner join 学院 on 学生.学院代码 = 学院.学院代码
inner join 学习 on 学生.学号 = 学习.学号
inner join 课程 on 学习.课程号 = 课程.课程号
where 课程名 = '经济学'
order by 学院.学院名称 asc, 成绩 desc;
连接
使用
<表名>
inner join <表名> on 条件
带有分组的查询语句中,select 子句后面只能出现两类信息:
1)用于分组的属性列
2)集函数
所以想要在select出后面的group by时要将需要投影的属性加上
自连接通过使用别名的形式实现即可,但是起了别名之后就不能用它原本的名字了
外连接以指定表作为连接主题,将主题表中大的所有元组输出
左外连接:left outer join … on
右外连接:right outer join … on
outer 可以省略
例:查询所有学生的姓名以及他们选修课程的课程号和成绩
select 姓名, 学习.课程号,成绩
from 学生
left join 学习 on 学生.学号 = 学习.学号;
limit子句
limit [offset,] count
offset参数指定要返回的第一行的偏移量;count指定返回记录行的最大数量
注意:第一行的偏移量为0,而不是1
例如:
select * from table limit 5,10;
# 返回第6-15行数据
嵌套循环
讲一个查询块嵌套在另一个查询块的where子句或having短语条件中的查询称为嵌套查询
- 不相关子查询
- 子查询结果用于建立父查询的查找条件
- 相关子查询
- 最内层查询需要用到上层父查询的某些属性值,因此最内层的子查询不能独立于父查询先完成
求解方法:
总原则:有里到外层层处理
- 不相关子查询
- 先从内层开始,每层执行完,然后上一层开始执行,直到最外层执行完
- 相关子查询
- 上层每取一条记录,子查询执行一遍,重复这个过程,直到上层表里全部访问完
带有any和all的子查询



带有exists的子查询
一定是相关子查询(类似于多层嵌套的for循环)
- exists谓词
- 带有exists谓词的子查询不返回任何数据,只产生逻辑真值’true’或逻辑假值’false’
- 如果内层查询结果非空,则返回真值
- 如果内层查询结果为空,则返回假值
除运算
使用除运算需要有集合包含集合的概念
待求列,象集 / 小集合被包含列
但是在用SQL语句实现时
思路:
大集合:A
小集合:B
¬ ( B − A ) : N O T E X I S T S ( 小集合 N O T E X I S T S 大集合 \neg(B - A): NOT\ EXISTS (小集合 NOT \ EXISTS 大集合 ¬(B−A):NOT EXISTS(小集合NOT EXISTS大集合
例:求至少选修了与学号"T06"同学选修的课程相同的学生学号;(学号)
小集合:T06同学选修的课程
大集合:某同学选修的全部课程
select distinct 学号
from 学习 as sc1
where not exists
(
select *
from 学习 as sc2
where 学号 = 'T06'
and not exists
(
select 课程号
from 学习
where sc1.学号 = 学习.学号
and sc2.课程号 = 学习.课程号
)
);
例:求选修了全部课程的学生姓名
小集合:全部课程
大集合:同学选的课程
select 姓名
from 学生 as s1
where not exists
(
select *
from 课程 as c
where not exists
(
select *
from 学习
where s1.学号 = 学号
and c.课程号 = 课程号
)
);
数据更新
插入数据
- 插入单个元组
insert into book values (4, '最优化理论与算法', '清华大学出版社');
insert into book values (5, '机器学习', '清华大学出版社');
- 插入子查询结果
insert into <表名> [属性列]
子查询
例:统计每门课的平均分,并把结果存入数据库
insert into 课程平均分(课程号,课程名,平均分)
(
select 课程号, 课程名, avg(成绩)
from 课程
inner join 学习 on 课程.课程号 = 学习.课程号
group by 课程号, 课程名
);
修改数据
update <表名>
set <列名> = <表达式>[, <列名> = <表达式>]
[where <条件>];
功能:修改指定表中满足where子句条件的元组
set语句后面跟的是将对应的列改成的表达式
例:将选修了180101号课程的学生成绩增加一分
update 学习
set 成绩 = 成绩 + 1
where 课程号 = '180101';
将计算机学院的学生的成绩清零
update 学习
set 成绩 = 0
where exists
(
select *
from 学生
where 学院 = '计算机'
and 学习.学号 = 学生.学号
);
删除数据
delete
from <表名>
[where <条件>];
功能 :删除指定表中满足where子句条件的元组
where子句:
- 指定要删除的元组
- 缺省表示要修改表中的所有元组
例:删除计算机学院所有学生的选课记录
delete
from 学习
where exists
(
select *
from 学生
where 学习.学号 = 学生.学号
and 学院 = '计算机'
);
数据控制
通过规定不同用户对于不同数据对象所允许执行的操作,从而限制用户智能存取他有权存取的数据。
存取控制是保证数据安全性的主要措施。
包括:grant和revoke
授权
grant <权限>[,<权限2>]
[on <对象类型> <对象名>]
TO <用户>[,< 用户二>]
[with grant option];
grant功能:将对指定操作对象的指定操作权限授予指定的用户
对于 加上WITH GRANT OPTION子句
过得某种权限的用户可以把这种权限再授权别的用户,反之没有权限
操作权限
| 对象 | 对象类型 | 操作权限 |
|---|---|---|
| 属性列 | TABLE | select, insert ,update,delete,all privileges |
| 视图 | TABLE | select,insert,update,delete, all privileges |
| 基本表 | TABLE | select, insert,update, delete, alter, index,allprivileges |
| 数据库 | DATABASE | create |
例:dba把在数据库smd中建立表的权限授予用户user3
grant create
on database smd
to user3;
把学习表的查询权限授权给全部用户public。
grant select
on table 学习
to public;
把学生表的insert权限授予user6用户,并允许他再将此权限授予其他用户
grant insert
on table 学生
to user6
with grant option;
注意:不允许循环授权
循环授权将影响数据库的安全性
回收
revoke <权限>[,<权限>]
[on <对象类型> <对象名> ]
from <用户> [, <用户>];
功能:从指定用户哪里守护对指定对象的指定权限
例:把用户user2修改成绩的权限收回(这修改这个属性列上的权限)
revoke update(成绩)
on table 学习
to user2;
权限的级联收回,使用with grant option授权的权限,当父节点权限被收回的话,那么它的子节点的权限也将被收回。
视图
视图是从一个或几个基本表(或视图)导出的表。虚表或虚关系。外模式。
视图的定义方法:
create view<视图名> [<列名> [, <列名>]]
as
(
子查询
);
[with check option];
dbms执行create view语句时只是把视图的定义存入数据字典,并不会执行其中的子查询语句。
使用with check option时是透过视图进行数据更新时,不得破坏视图定义中子查询的条件。
例:建立计算机学院学生的视图,并要求透过该视图进行的更新操作只涉及计算机学院的学生。
create view CS_stu
as
(
select 学号, 姓名, 籍贯
from 学生
where 学院 = '计算机'
)
with check option;
在对CS_stu视图进行更新时:
- 修改操作:dbms自动加上学院='计算机’的条件
- 删除操作:dbms自动加上学院='计算机’的条件
- 插入操作:dbms自动检查学院属性值是否为’计算机’
- 如果不是,则拒绝该插入操作
- 如果没有提供学院值,则学院列自动填充’计算机’
例:建立多个基表的视图
建立计算机学院选修了《数据库原理》课程的学生成绩视图。
create view CS_DB(学号, 姓名, 成绩)
as
(
select 学生.学号, 姓名, 成绩
from 学生
inner join 学习 on 学生.学号 = 学习.学号
inner join 课程 on 学习.课程号 = 课程.课程号
where 课程名 = '数据库原理'
);
建立一个反映学生年龄的视图
create view Stu_Age(学号, 姓名, 年龄)
as
(
select 学号, 姓名, year(now()) - 出生年份
from 学生
);
计算后的值或者统计值(入上面的年龄),被称为虚拟列,带有虚拟列的视图,定义时要给出组成视图的各个属性列的名称;
由于视图中的数据是虚的,所以可以将计算和统计的值放到视图中,减少实表的冗余。
删除视图和删除表一样
drop view <视图名>;