Q&A | 如何使用clusterProfiler对MSigDB数据库进行富集分析
Q&A | 如何使用clusterProfiler对MSigDB数据库进行富集分析
Question
MSigDB
富集分析
富集分析
思考
参考
往期
Question
有朋友在后台提问:在使用clusterProfiler做富集分析时,想用MSigDB里的数据库进行注释,而不是常规的GO和KEGG,需要怎么操作。其实这个问题在clusterProfiler包的使用文档(Chapter 12 Universal enrichment analysis | Biomedical Knowledge Mining using GOSemSim and clusterProfiler (yulab-smu.top)里已经写的很清楚了,这里我就简单的翻译一下。
MSigDB
The Molecular Signatures Database (MSigDB) 一个用于GSEA软件的注释基因集的集合。MSigDB基因集分为9个主要集合:
H: hallmark gene sets(browse 50 gene sets)
该基因集概括和代表了特定的定义良好的生物状态或过程,并显示一致的表达。这些基因集是通过一种计算方法生成的,该方法基于识别其他MSigDB集合中基因集之间的重叠,并保留显示协调表达的基因。

C1: positional gene sets(browse 278 gene sets)
该类别包含人类每条染色体上的不同cytoband区域对应的基因集合。根据不同染色体编号进行二级分类。

C2: curated gene sets(browse 6290 gene sets)
共识基因集合,基于通路、文献等:这部分包括我们熟悉的KEGG信号通路等 。

C3: regulatory target gene sets(browse 3731 gene sets)
该类别包含了miRNA靶基因和转录因子结合区域等基因集合。

C4: computational gene sets(browse 858 gene sets)
该类别包含计算机软件预测出来的基因集合,主要是和癌症相关的基因,示意如下

C5: ontology gene sets(browse 14998 gene sets)
C5基因集分为两个子集,第一个来自于包含BP、CC和MF的Gene Ontology(GO),第二个来自于人类表型本体(HPO)。

C6: oncogenic signature gene sets(browse 189 gene sets)
代表细胞通路的基因集合,这些通路在癌症中通常是不受调节的。大多数特征直接来自NCBI GEO的微阵列数据,或者来自内部未发表的涉及已知癌症基因微扰的分析实验。

C7: immunologic signature gene sets(browse 5219 gene sets)
该类别包含了免疫系统功能相关的基因集合。

C8: cell type signature gene sets(browse 671 gene sets)
包含人类组织单细胞测序研究中确定的细胞类型的簇标记的基因集。

富集分析
你可以从 Broad Institute 下载 GMT files 然后使用 read.gmt() 读取文件并作为enricher() and GSEA()的参数。
当然。也有一个R包msigdbr,已经将MSigDB基因集打包成整齐的数据格式,可以直接与clusterProfiler一起使用。
我们使用 C6, oncogenic gene sets 为例。
# BiocManager::install("msigdbr")
library(msigdbr)
# 提取C6库
m_t2g <- msigdbr(species = "Homo sapiens", category = "C6") %>%
dplyr::select(gs_name, entrez_gene)
head(m_t2g)> head(m_t2g)
# A tibble: 6 x 2
gs_name entrez_gene
1 AKT_UP.V1_DN 57007
2 AKT_UP.V1_DN 22859
3 AKT_UP.V1_DN 22859
4 AKT_UP.V1_DN 137872
5 AKT_UP.V1_DN 249
6 AKT_UP.V1_DN 271 富集分析
# 导入示例基因
data(geneList, package="DOSE")
head(geneList)
gene <- names(geneList)[abs(geneList) > 2]
head(gene)em <- enricher(gene, TERM2GENE=m_t2g)
head(em)> head(em)
ID Description
RPS14_DN.V1_DN RPS14_DN.V1_DN RPS14_DN.V1_DN
GCNP_SHH_UP_LATE.V1_UP GCNP_SHH_UP_LATE.V1_UP GCNP_SHH_UP_LATE.V1_UP
PRC2_EZH2_UP.V1_DN PRC2_EZH2_UP.V1_DN PRC2_EZH2_UP.V1_DN
VEGF_A_UP.V1_DN VEGF_A_UP.V1_DN VEGF_A_UP.V1_DN
RB_P107_DN.V1_UP RB_P107_DN.V1_UP RB_P107_DN.V1_UP
E2F1_UP.V1_UP E2F1_UP.V1_UP E2F1_UP.V1_UP
GeneRatio BgRatio pvalue p.adjust
RPS14_DN.V1_DN 22/183 186/10915 4.716365e-13 7.970657e-11
GCNP_SHH_UP_LATE.V1_UP 16/183 181/10915 5.815455e-08 4.914059e-06
PRC2_EZH2_UP.V1_DN 15/183 192/10915 7.635020e-07 3.446929e-05
VEGF_A_UP.V1_DN 15/183 193/10915 8.158412e-07 3.446929e-05
RB_P107_DN.V1_UP 10/183 130/10915 6.428560e-05 2.024672e-03
E2F1_UP.V1_UP 12/183 188/10915 7.522623e-05 2.024672e-03
qvalue
RPS14_DN.V1_DN 6.503619e-11
GCNP_SHH_UP_LATE.V1_UP 4.009603e-06
PRC2_EZH2_UP.V1_DN 2.812505e-05
VEGF_A_UP.V1_DN 2.812505e-05
RB_P107_DN.V1_UP 1.652021e-03
E2F1_UP.V1_UP 1.652021e-03
geneID
RPS14_DN.V1_DN 10874/55388/991/9493/1062/4605/9133/23397/79733/9787/55872/83461/54821/51659/9319/9055/10112/4174/5105/2532/7021/79901
GCNP_SHH_UP_LATE.V1_UP 55388/7153/79733/6241/9787/51203/983/9212/1111/9319/9055/3833/6790/4174/3169/1580
PRC2_EZH2_UP.V1_DN 8318/55388/4605/23397/9787/55355/10460/6362/81620/2146/7272/9212/11182/3887/24137
VEGF_A_UP.V1_DN 8318/9493/1062/9133/10403/6241/9787/4085/332/3832/7272/891/23362/2167/10234
RB_P107_DN.V1_UP 8318/23397/79733/6241/4085/8208/9055/24137/4174/1307
E2F1_UP.V1_UP 55388/7153/23397/79733/9787/2146/2842/9212/8208/1111/9055/3833
Count
RPS14_DN.V1_DN 22
GCNP_SHH_UP_LATE.V1_UP 16
PRC2_EZH2_UP.V1_DN 15
VEGF_A_UP.V1_DN 15
RB_P107_DN.V1_UP 10
E2F1_UP.V1_UP 12dotplot(em)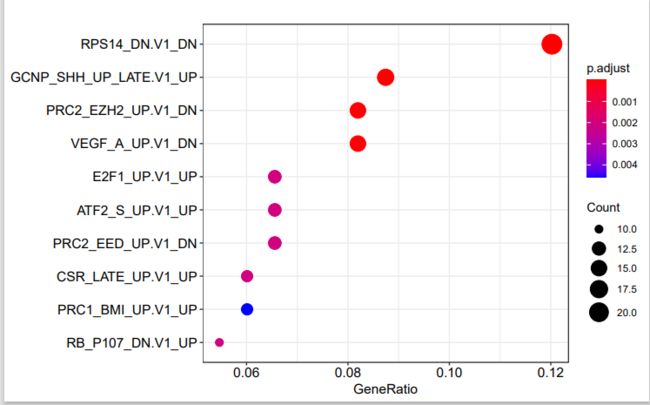
思考
之前R 实战 | 使用clusterProfiler进行多组基因富集分析我们讲过如何使用clusterProfiler进行多组基因富集分析,但是compareCluster的fun参数只有groupGO, enrichGO, enrichKEGG, enrichMKEGG, enrichWP ,enricher ,enrichPathway, enrichDO, enrichNCG, enrichDGN , enrichMeSH.如何使用compareCluster对MSigDB数据库进行多组富集分析呢?大家可以思考一下。
参考
Introduction | Biomedical Knowledge Mining using GOSemSim and clusterProfiler (yulab-smu.top)
往期
跟着Nature学作图 | 配对哑铃图+分组拟合曲线+分类变量热图
(免费教程+代码领取)|跟着Cell学作图系列合集
跟着Nat Commun学作图 | 1.批量箱线图+散点+差异分析
跟着Nat Commun学作图 | 2.时间线图
跟着Nat Commun学作图 | 3.物种丰度堆积柱状图
跟着Nat Commun学作图 | 4.配对箱线图+差异分析
