在Hadoop中进行简单的词频统计
在Hadoop中进行简单的词频统计
1.建立WCMapper
代码如下:
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WCMapper extends Mapper {
@Override
protected void map(LongWritable k1 , Text v1,Context context)
throws IOException,InterruptedException{
//1.进行行偏移量内容反序列化
String line=v1.toString();
//2.通过空格分隔每行单词
String[] words = line.split(" ");
//3.通过遍历数组将k1,v1,变成k2,v2
for (String w : words) {
context.write(new Text(w), new LongWritable(1));
}
}
}
说明:
k1,v1转变成k2,v2,通过的是进行数组遍历,将每一行的单词分开并统计,由于没有合并,故new LongWritable(1),即每个单词一个并序列化写入。
Context:
用来传递数据以及其他运行状态信息,map中的k1,v1写入context,让它传递给Reducer进行reduce(k3,v3),而reduce进行处理之后数据继续写入context,继续交给Hadoop写入hdfs系统。
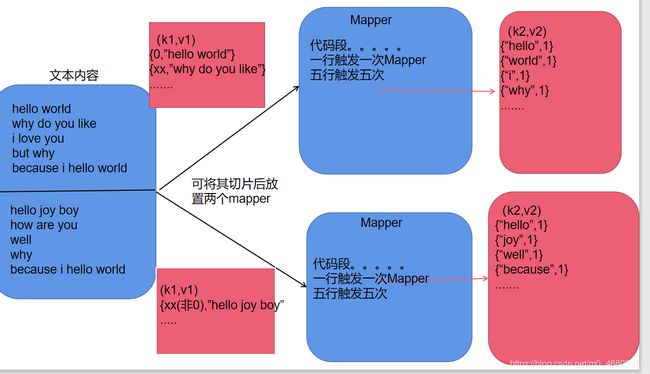
以下图可简单说明(为我个人理解):
2.建立WCReducer
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WCReducer extends Reducer {
@Override
protected void reduce(Text k3, Iterable v3s,
Context context) throws IOException, InterruptedException {
// 1.通过k3获取单词
String word = k3.toString();
//2.遍历v3对数值累加
int sum = 0 ;
for(LongWritable n:v3s) {
sum+=n.get();
}
//3.输出k4,v4
context.write(new Text(word),new LongWritable(sum));
}
}
k3不是k2,k3是k2经过哈希运算后(k2.hashcode()%reducernums)得出得结果,这有一个误区:将内容切分后,可能两个切段相同单词会不会被分配到不同reducer呢?当然不会。通过字符串运算出来得哈希值,相同单词出现相同结果,也就是会分配到同一个reducer机器中,不会说{“hello”,3},{“hello”,5"}这样得情况,只会出现{“hallo”,8}。
这里做一个简单的理解图(个人理解):

3.建立WCRunner
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WCRunner {
public static void main(String[] args)throws Exception {
//1.创建job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.指定程序入口,jar包
job.setJarByClass(WCRunner.class);
//3.设定map
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//4.设定reduce
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//5.设定输入和输出
//path中为你输入的文件,也就是你想统计的文件的路径。**这是一定要存在的**
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop:9000/WordCount"));
// path路径为输出目的地,也就是统计结果放在哪里,**这个文件夹一定不能存在,否则错误**
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop:9000/WordCount/result"));
//此段代码为是否显示处理过程,true为是
job.waitForCompletion(true);
}
}
此段代码,个人理解不是很深,因为初学Hadoop。所以不加多说明。
4.运行
当前三步都完成后,将三者所在的包进行export成jar包。
步骤是:右键点击三者所在的包,选择“export”,在"JAVA"中选择“JAR file",并分配好路径。
将这个jar包分在Linux系统中进行运行,因为本人Hadoop装在Linux上。
运行代码段:
hadoop jar WordCount.jar WordCount.WCRunner
其中"WordCount.WCRunner"为所在包路径,可在eclipse中查看:
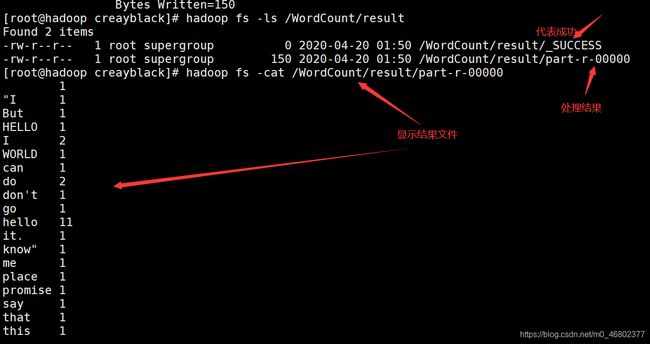
运行后可在输出文件路径寻找最终结果:
文件夹错误:Output directory hdfs://hadoop:9000/WordCount/result already exists
如果在WCRunner中,将输出目的地创建,则会显示如下图,此时应该删除输出目的地文件夹后可恢复正常。
