MATLAB中std函数用法
目录
语法
说明
示例
矩阵列的标准差
三维数组的标准差
指定标准差权重
矩阵行的标准差
数组页的标准差
排除缺失值的标准差
标准差和均值
标准差
std函数的功能是得到标准差。
语法
S = std(A)
S = std(A,w)
S = std(A,w,"all")
S = std(A,w,dim)
S = std(A,w,vecdim)
S = std(___,missingflag)
[S,M] = std(___)说明
S = std(A) 返回 A 沿大小大于 1 的第一个数组维度计算的元素的标准差。默认情况下,标准差按 N-1 实现归一化,其中 N 是观测值数量。
-
如果A是观测值的向量,则S是标量。
-
如果A是一个列为随机变量且行为观测值的矩阵,则S是一个包含与每列对应的标准差的行向量。
-
如果A是多维数组,则std(A)沿大小大于 1 的第一个数组维度计算,并将这些元素视为向量。此维度中S的大小变为1,而所有其他维度的大小仍与在A中相同。
-
如果A是标量,则S为0。
-
如果A是一个 0×0 的空数组,则 S 为 NaN。
-
如果 A 是表或时间表,则 std(A) 返回单行表,其中包含每个变量的标准差。 (自 R2023a 起)
S = std(A,w) 指定加权方案。当 w = 0(默认值)时,标准差按 N-1 实现归一化,其中 N 是观测值数量。当 w = 1 时,标准差按观测值数量进行归一化。w 也可以是包含非负元素的权重向量。在这种情况下,w 的长度必须等于 std 将作用于的维度的长度。
当 w 为 0 或 1 时,S = std(A,w,"all") 返回 A 的所有元素的标准差。
S = std(A,w,dim) 返回沿维度 dim 的标准差。要维持默认归一化并指定运算的维度,请在第二个参数中设置 w = 0。
当 w 为 0 或 1 时,S = std(A,w,vecdim) 返回向量 vecdim 中指定维度的标准差。例如,如果 A 是矩阵,则 std(A,0,[1 2]) 返回 A 中所有元素的标准差,因为矩阵的每个元素包含在由维度 1 和 2 定义的数组切片中。
S = std(___,missingflag) 在上述任一语法的基础上指定包含还是省略 A 中的缺失值。例如,std(A,"omitmissing") 在计算标准差时会忽略所有缺失值。默认情况下,std 包括缺失值。
[S,M] = std(___) 还返回 A 中用于计算标准差的元素的均值。如果 S 是加权标准差,则 M 是加权均值。
示例
矩阵列的标准差
创建一个矩阵,并计算每一列的标准差。
A = [4 -5 1; 2 3 5; -9 1 7];
S = std(A)
S = 1×3
7.0000 4.1633 3.0551三维数组的标准差
创建一个三维数组,并计算沿第一个维度的标准差。
A(:,:,1) = [2 4; -2 1];
A(:,:,2) = [9 13; -5 7];
A(:,:,3) = [4 4; 8 -3];
S = std(A)
S =
S(:,:,1) =
2.8284 2.1213
S(:,:,2) =
9.8995 4.2426
S(:,:,3) =
2.8284 4.9497指定标准差权重
创建一个矩阵,并根据权重向量w计算每一列的标准差。
A = [1 5; 3 7; -9 2];
w = [1 1 0.5];
S = std(A,w)
S = 1×2
4.4900 1.8330矩阵行的标准差
创建一个矩阵,并计算每一行的标准差。
A = [6 4 23 -3; 9 -10 4 11; 2 8 -5 1];
S = std(A,0,2)
S = 3×1
11.0303
9.4692
5.3229数组页的标准差
创建一个三维数组并计算每页数据(行和列)的标准差。
A(:,:,1) = [2 4; -2 1];
A(:,:,2) = [9 13; -5 7];
A(:,:,3) = [4 4; 8 -3];
S = std(A,0,[1 2])
S =
S(:,:,1) =
2.5000
S(:,:,2) =
7.7460
S(:,:,3) =
4.5735排除缺失值的标准差
创建一个包含 NaN 值的矩阵。
A = [1.77 -0.005 NaN -2.95; NaN 0.34 NaN 0.19]
A = 2×4
1.7700 -0.0050 NaN -2.9500
NaN 0.3400 NaN 0.1900计算矩阵的标准差,不包括缺失值。对于包含任一 NaN 值的矩阵列,std 使用非 NaN 元素进行计算。对于 A 中包含的所有值都是 NaN 的列,标准差为 NaN。
S = std(A,"omitmissing")
S = 1×4
0 0.2440 NaN 2.2203标准差和均值
创建一个矩阵,并计算每一列的标准差和均值。
A = [4 -5 1; 2 3 5; -9 1 7];
[S,M] = std(A)
S = 1×3
7.0000 4.1633 3.0551
M = 1×3
-1.0000 -0.3333 4.3333创建一个矩阵,根据权重向量 w 计算每列的加权标准差和加权均值。
A = [1 5; 3 7; -9 2];
w = [1 1 0.5];
[S,M] = std(A,w)
S = 1×2
4.4900 1.8330
M = 1×2
-0.2000 5.2000参数说明
A — 输入数组
输入数组,指定为向量、矩阵、多维数组、表或时间表。如果 A 是标量,则 std(A) 返回 0。如果 A 是一个 0×0 的空数组,则 std(A) 返回 NaN。
w — 粗细
权重,指定为下列值之一:
-
0 - 按 N-1 实现归一化,其中 N 是观测值的数量。如果只有一个观测值,则权重为 1。
-
1 - 按 N 实现归一化。
-
由非负标量权重构成的向量,这些权重对应于沿其计算方差的A 维度。
dim — 沿其运算的维度
沿其运算的维度,指定为正整数标量。如果不指定维度,则默认为第一个大于 1 的数组维度。
维度 dim 表示长度减至 1 的维度。size(S,dim) 为 1,而所有其他维度的大小保持不变。
以一个 m×n 输入矩阵 A 为例:
-
std(A,0,1) 计算 A 的每一列元素的标准差,并返回一个 1×n 行向量。

-
std(A,0,2) 计算 A 的每一行元素的标准差,并返回一个 m×1 列向量。

如果 dim 大于 ndims(A),则 std(A) 返回大小与 A 相同的由零组成的数组。
vecdim — 维度向量
维度向量,指定为正整数向量。每个元素代表输入数组的一个维度。指定的操作维度的输出长度为 1,而其他保持不变。
以 2×3×3 输入数组 A 为例。然后 std(A,0,[1 2]) 返回 1×1×3 数组,其元素是在 A 的每个页面上计算的标准差。

missingflag — 缺失值条件
缺失值条件,指定为下表中的值之一。
| 值 | 输入数据类型 | 描述 |
|---|---|---|
| "includemissing" | 所有支持的数据类型 | 在计算标准差时包括 A 和 w 中的缺失值。如果运算维度中的任一元素缺失,则 S 中的对应元素也会缺失。 |
| "includenan" | double, single, duration | |
| "includenat" | datetime | |
| "omitmissing" | 所有支持的数据类型 | 忽略 A 和 w 中的缺失值,并基于较少的点计算标准差。如果运算维度中的所有元素都缺失,则 S 中的对应元素也会缺失。 |
| "omitnan" | double, single, duration | |
| "omitnat" | datetime |
S — 标准差
标准差,以标量、向量、矩阵、多维数组或表形式返回
-
如果 A 是观测值的向量,则 S 是标量。
-
如果 A 是一个列为随机变量且行为观测值的矩阵,则 S 是一个包含与每列对应的标准差的行向量。
-
如果 A 是多维数组,则 std(A) 沿大小不大于 1 的第一个数组维度计算,并将这些元素视为向量。此维度中 S 的大小变为 1,而所有其他维度的大小仍与在 A 中相同。
-
如果 A 是标量,则 S 为 0。
-
如果 A 是一个 0×0 的空数组,则 S 为 NaN。
-
如果 A 是表或时间表,则 S 是单行表。 (自 R2023a 起)
M — 均值
均值,以标量、向量、矩阵、多维数组或表形式返回。
-
如果 A 是观测值的向量,则 M 是标量。
-
如果 A 是一个列为随机变量且行为观测值的矩阵,则 M 是一个包含与每列对应的均值的行向量。
-
如果 A 是多维数组,则 std(A) 沿大小大于 1 的第一个数组维度计算,并将这些元素视为向量。此维度中 M 的大小变为 1,而所有其他维度的大小仍与在 A 中相同。
-
如果 A 是标量,则 M 等于 A。
-
如果 A 是一个 0×0 的空数组,则 M 为 NaN。
-
如果 A 是表或时间表,则 M 是单行表。 (自 R2023a 起)
如果 S 是加权标准差,则 M 是加权均值。
标准差
对于由 N 个标量观测值组成的有限长向量 A,标准差定义为
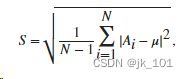
,其中 μ 是 A:

的均值。标准差是方差的平方根。
有些标准差的定义使用归一化因子 N 而非 N – 1。可以通过指定权重 1 来使用归一化因子 N,从而生成样本关于其均值的二阶矩的平方根。
无论标准差的归一化因子是什么,都假定均值具有归一化因子 N。
加权标准差
对于由 N 个标量观测值组成的有限长度向量 A 和加权方案 w,加权标准差定义为

,其中 μw 是 A 的加权均值。
加权均值
对于由 N 个标量观测值组成的随机变量向量 A 和加权方案 w,加权均值定义为
