【OpenCV实现图像:OpenCV进行OCR字符分割】
文章目录
-
- 概要
- 基本概念
- 读入图像
- 图像二值化
- 小结
概要
在处理OCR(Optical Character Recognition,光学字符识别)时,利用传统的图像处理方法进行字符切分仍然是一种有效的途径。即便当前计算机视觉领域主导的是卷积神经网络,但对于一些相对简单的实际应用场景,传统方法仍然表现出良好的效果。
在OCR任务中,字符切分是一个关键的步骤,它能够将整个文本图像分割成单个字符,为后续的处理任务提供基础。传统图像处理方法可以通过一系列技术来实现字符的准确切分。这些技术可能包括但不限于:
边缘检测: 使用算子(如Sobel、Canny)检测图像中字符的边缘,从而确定字符的边界。
连通区域分析: 通过标记和分析图像中的连通区域,可以识别字符的位置和形状。
投影法: 水平和垂直投影可以帮助检测字符之间的间隔,从而进行字符切分。
轮廓分析: 提取字符的轮廓信息,进而判断字符的位置和形状。
形态学操作: 使用腐蚀、膨胀等形态学操作来调整字符的形状,以便更好地进行切分。
虽然卷积神经网络在图像处理任务中表现出色,但在一些简单的场景中,传统方法的实用性仍然很大。例如,在文档扫描、数字识别等任务中,通过合理运用传统图像处理技术,可以快速、准确地完成字符切分,为后续的OCR处理奠定基础。这种混合使用传统方法和深度学习技术的方式,可以充分发挥各自的优势,实现更全面、高效的图像处理任务。
基本概念
OCR(Optical Character Recognition):全称光学字符识别,是一项技术,通过使用光学和图像处理技术,将图像中的文字转换为可编辑的文本。
Segmentation:在图像处理领域,分割是指将整个图像分解为多个子部分的过程,以便进行进一步的处理。
OCR Segmentation:是指在光学字符识别过程中,将包含文本的图像分解成多个小部分的操作。这旨在有效地识别图像中的文字,并将其从背景中分离出来,以便后续的OCR处理。通过分割,系统可以更准确地定位和识别每个字符,提高整体识别准确性。
读入图像
读入图像:
一旦获得了包含文本的数字图像,或者通过扫描仪将某些文档转换为数字图像进行存储,就可以迈入下一步,即预处理。在这个阶段,可以使用以下代码来读入图像,以便进行后续的处理。
import cv2
# 读入图像
myImage = cv2.imread('12.png')
# 显示图像
cv2.imshow('Text Image', myImage)
cv2.waitKey(0)
图像二值化
在开始分割文本图像之前,需要经过一系列预处理步骤,其中之一是图像的二值化。这个过程包括以下步骤:
灰度化: 首先,将输入图像转换为灰度图像。这一步的目的是简化图像,使系统能够更轻松地识别图像中的不同形状,同时去除颜色信息,从而减少处理的复杂性。这通常通过将图像中的每个像素的彩色信息转化为相应的灰度值来实现。
import cv2
# 读入图像
myImage = cv2.imread('12.png')
# 灰度化
grayImage = cv2.cvtColor(myImage, cv2.COLOR_BGR2GRAY)
# 二值化
_, binaryImage = cv2.threshold(grayImage, 128, 255, cv2.THRESH_BINARY)
# 显示图像
cv2.imshow('Binary Image', grayImage)
cv2.waitKey(0)

二值化: 一旦图像变为灰度图,接下来的关键步骤是将其二值化。这意味着将图像中的像素值转换为两个可能的值之一,通常是0和255。这样的二值图像使得文字与背景更为明显,为后续的字符切分和识别提供了更好的基础。
这个可以根据自己的修改,转换颜色。
_, binaryImage = cv2.threshold(grayImage, 128, 255, cv2.THRESH_BINARY)
import cv2
# 读入图像
myImage = cv2.imread('12.png')
# 灰度化
grayImage = cv2.cvtColor(myImage, cv2.COLOR_BGR2GRAY)
# 二值化
_, binaryImage = cv2.threshold(grayImage, 128, 255, cv2.THRESH_BINARY)
# 显示图像
cv2.imshow('Binary Image', binaryImage)
cv2.waitKey(0)

import cv2
# 读入图像
myImage = cv2.imread('12.png')
# 灰度化
grayImage = cv2.cvtColor(myImage, cv2.COLOR_BGR2GRAY)
# 二值化
ret, thresh = cv2.threshold(grayImage, 0, 255, cv2.THRESH_OTSU | cv2.THRESH_BINARY_INV)
# 形态学操作
horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (18, 18))
dilation = cv2.dilate(thresh, horizontal_kernel, iterations=1)
# 显示图像
cv2.imshow('Dilated Image', thresh)
cv2.waitKey(0)

接着可以选择并使用多种算法从上述二值图像中提取信息,例如直方图均衡、傅立叶变换、形态学等。
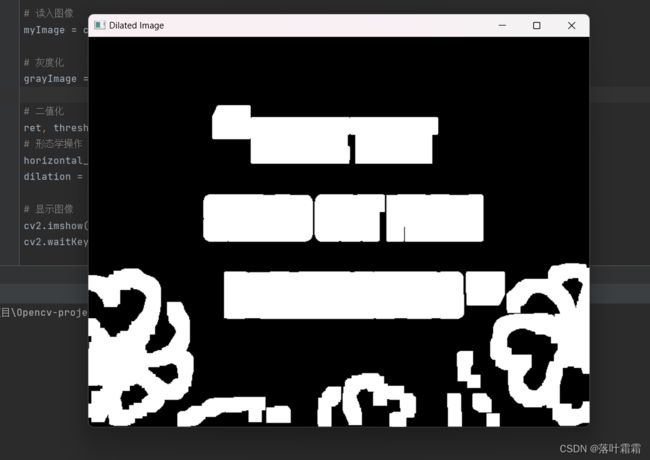
形态学操作
import cv2
# 读入图像
myImage = cv2.imread('12.png')
# 灰度化
grayImage = cv2.cvtColor(myImage, cv2.COLOR_BGR2GRAY)
# 二值化
ret, thresh = cv2.threshold(grayImage, 0, 255, cv2.THRESH_OTSU | cv2.THRESH_BINARY_INV)
# 形态学操作
horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (18, 18))
dilation = cv2.dilate(thresh, horizontal_kernel, iterations=1)
# 显示图像
cv2.imshow('Dilated Image', dilation)
cv2.waitKey(0)
查找轮廓
接着需要找到轮廓线,这样才能将图像与背景逐行分离。
为了清楚,换红色线条标注,可以修改这段代码更换颜色
rect = cv2.rectangle(myImage, (x, y), (x + w, y + h), (0, 0, 255), 1) # 红色矩形
import cv2
# 读入图像
myImage = cv2.imread('12.png')
# 灰度化
grayImage = cv2.cvtColor(myImage, cv2.COLOR_BGR2GRAY)
# 二值化
ret, thresh = cv2.threshold(grayImage, 0, 255, cv2.THRESH_OTSU | cv2.THRESH_BINARY_INV)
# 形态学操作
horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (18, 18))
dilation = cv2.dilate(thresh, horizontal_kernel, iterations=1)
# 查找轮廓
horizontal_contours, hierarchy = cv2.findContours(dilation, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# 在原始图像上绘制红色矩形
for cnt in horizontal_contours:
x, y, w, h = cv2.boundingRect(cnt)
rect = cv2.rectangle(myImage, (x, y), (x + w, y + h), (0, 0, 255), 1) # 红色矩形
# 显示图像
cv2.imshow('Image with Red Rectangles', myImage)
cv2.waitKey(0)

单词和字符分割
接着我们通过以下步骤对裁剪出的轮廓子图进行单词分割:
1-预处理(灰度、阈值)
2-形态学算法
3-找到边界并绘制它们
4-进入单个字符分割
进而我们将对输出图像中的每个单词再次重复相同的步骤进行单个字符的分割:
1-预处理(灰度、阈值)
2-形态学算法
3-找到边界并绘制它们
4-停止
最终我们得到的结果如下。
代码:
import cv2
# 读入图像
myImage = cv2.imread('12.png')
# 灰度化
grayImage = cv2.cvtColor(myImage, cv2.COLOR_BGR2GRAY)
# 二值化
ret, thresh = cv2.threshold(grayImage, 0, 255, cv2.THRESH_OTSU | cv2.THRESH_BINARY_INV)
# 形态学操作
horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (18, 18))
dilation = cv2.dilate(thresh, horizontal_kernel, iterations=1)
# 查找轮廓
horizontal_contours, hierarchy = cv2.findContours(dilation, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# 在原始图像上绘制红色矩形和进行字符分割
for cnt in horizontal_contours:
x, y, w, h = cv2.boundingRect(cnt)
# 绘制红色矩形
rect = cv2.rectangle(myImage, (x, y), (x + w, y + h), (0, 0, 255), 1)
# 在水平轮廓区域内进行字符分割
roi = thresh[y:y + h, x:x + w]
# 进行字符分割的额外步骤,例如形态学操作、查找字符轮廓等
char_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
char_dilation = cv2.dilate(roi, char_kernel, iterations=1)
char_contours, _ = cv2.findContours(char_dilation, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 在原始图像上绘制字符的边界
for char_cnt in char_contours:
char_x, char_y, char_w, char_h = cv2.boundingRect(char_cnt)
char_rect = cv2.rectangle(myImage, (x + char_x, y + char_y), (x + char_x + char_w, y + char_y + char_h),
(0, 255, 0), 1)
# 显示图像
cv2.imshow('Image with Red Rectangles and Character Boundaries', myImage)
cv2.waitKey(0)
`

小结
在传统图像处理中,如何利用常见的形态学方法进行字符轮廓查找,从而实现字符的切分。通过提供相应的代码实现,展示了在一些字符分布简单、字符间隔较大的场景下,该方法能够取得一定的效果。然而,由于采用传统方案,该方法的泛化性较为有限。在面对更复杂的场景时,可以考虑借助神经网络等先进技术,以实现更加鲁棒和适用于多种情况的字符切分算法。