目录
- spark 数据倾斜优化
- 数据倾斜产生的原因
- 数据倾斜七种解决方案
- 使用Hive ETL预处理数据
- 过滤少数导致倾斜的key
- 提高shuffle操作的并行度
- 双重聚合
- 将reduce join转为map join
- 采样倾斜key并分拆join操作
- 使用随机前缀和扩容RDD进行join
spark 数据倾斜优化
数据倾斜产生的原因
1、数据分布不均,有的key很多,有的key很少
2、有shuffle的过程
这两个原因也是解决数据倾斜的两个入手的方面
数据倾斜七种解决方案
其中 3、4、5、6 最重要
3和4 -- 聚合
5和6 -- 关联
1、使用Hive ETL预处理数据
2、过滤少数导致倾斜的key
3、提高shuffle操作的并行度
4、双重聚合
5、将reduce join转为map join
6、采样倾斜key并分拆join操作
7、使用随机前缀和扩容RDD进行join
使用Hive ETL预处理数据
相当于将数据倾斜提前到Hive中,Hive底层是MapReduce,运行稳定不容易失败。而spark如果出现数据倾斜,很容易报错
过滤少数导致倾斜的key
比如数据中有很多null的数据,对业务没有影响,可以在shuffle之前过滤掉
package com.shujia.opt
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object FilterKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("app")
val sc: SparkContext = new SparkContext(conf)
val lines: RDD[String] = sc.textFile("data/word")
println("第一个RDD分区数量:" + lines.getNumPartitions)
val countRDD: RDD[(String, Int)] = lines
.flatMap(_.split(","))
.map((_, 1))
.groupByKey()
.map(x => (x._1, x._2.toList.sum))
println("聚合之后RDD分区的数量" + countRDD.getNumPartitions)
countRDD.foreach(println)
/**
* 采样key ,g过滤掉导致数据倾斜并且对业务影响不大的key
*
*/
val wordRDD: RDD[(String, Int)] = lines
.flatMap(_.split(","))
.map((_, 1))
/* val top1: Array[(String, Int)] = wordRDD
.sample(true, 0.1)
.reduceByKey(_ + _)
.sortBy(-_._2)
.take(1)
//导致数据倾斜额key
val key: String = top1(0)._1 */
//过滤导致倾斜的key
wordRDD
.filter(t => !"null".equals(t._1))
.groupByKey()
.map(x => (x._1, x._2.toList.sum))
.foreach(println)
while (true) {
}
}
}提高shuffle操作的并行度
例如:groupByKey(100)
提高并行度,相当于增加了reduce task 的数量,每一个 reduce task 中分区的数据量会减少,可以缓解数据倾斜
双重聚合
增加随机的前缀聚合一次,再去掉前缀聚合一次。只适合聚合的情况,不适合太复杂的逻辑
package com.shujia.opt
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.Random
object DoubleReduce {
/**
* 双重聚合
* 一般适用于 业务不复杂的情况
*
*/
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("app")
val sc: SparkContext = new SparkContext(conf)
val lines: RDD[String] = sc.textFile("data/word")
val wordRDD: RDD[String] = lines
.flatMap(_.split(","))
.filter(!_.equals(""))
// 对每一个key打上随机5以内的前缀
wordRDD.map(word => {
val pix: Int = Random.nextInt(5)
(pix + "-" + word, 1)
})
.groupByKey() //第一次聚合
.map(t => (t._1, t._2.toList.sum))
.map(t => {
//去掉随机前缀
(t._1.split("-")(1), t._2)
})
.groupByKey() //第二次聚合
.map(t => (t._1, t._2.toList.sum))
.foreach(println)
while (true) {
}
}
}将reduce join转为map join
如果在join的时候产生了数据倾斜
在map端进行join,避免了shuffle,没有shuffle就不会产生数据倾斜
只适用于大表关联小表(小表不能超过1G)
package com.shujia.opt
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkSqlMapJoin {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName("join")
.config("spark.sql.shuffle.partitions", "2")
.getOrCreate()
import spark.implicits._
val student: DataFrame = spark.read
.format("csv")
.schema("id STRING , name STRING ,age INT ,gender STRING ,clazz STRING")
.load("data/students.txt")
val score: DataFrame = spark.read
.format("csv")
.schema("sid STRING ,cId STRING , sco INT")
.load("data/score.txt")
/**
* .hint("broadcast") : 广播小表实现map join
*
*/
student.hint("broadcast").join(score, $"sId" === $"id").show(10000000)
student.createOrReplaceTempView("student")
score.createOrReplaceTempView("score")
spark.sql(
"""
|
|select /*+broadcast(a) */ * from score as a join student as b on a.sId=b.id
|
""".stripMargin).show(1000000)
while (true) {
}
}
}package com.shujia.opt
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object MapJoin {
/**
* map join
*
* 将小表广播,大表使用map算子
*
* 1、小表不能太大, 不能超过2G
* 2、如果driver内存不足,需要手动设置 如果广播变量大小超过了driver内存大小,会出现oom
*
*/
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("app")
val sc: SparkContext = new SparkContext(conf)
//RDD 不能广播
val studentRDD: RDD[String] = sc.textFile("data/students.txt")
//将数据拉去到driver端,变成一个map集合
val stuMap: Map[String, String] = studentRDD
.collect() //将rdd的数据拉取Driver端变成一个数组
.map(s => (s.split(",")(0), s))
.toMap
//广播map集合
val broStu: Broadcast[Map[String, String]] = sc.broadcast(stuMap)
val scoreRDD: RDD[String] = sc.textFile("data/score.txt")
//循环大表,通过key获取小表信息
scoreRDD.map(s => {
val sId: String = s.split(",")(0)
//重广播变量里面获取数据
val stuInfo: String = broStu.value.getOrElse(sId, "")
stuInfo + "," + s
}).foreach(println)
while (true) {
}
}
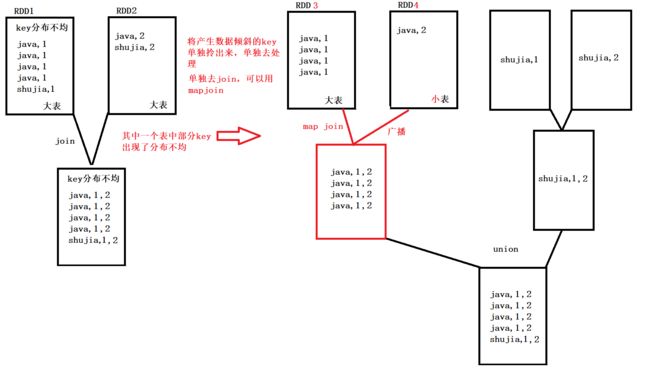
}采样倾斜key并分拆join操作
适用于大表关联大表,其中一个表的数据分布不均
1、将导致倾斜的数据单独抽取出来使用map join,剩下没有倾斜的数据正常join,最后将两次join的数据union在一起
package com.shujia.opt
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DoubleJoin {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("app").setMaster("local")
val sc = new SparkContext(conf)
val dataList1 = List(
("java", 1),
("shujia", 2),
("shujia", 3),
("shujia", 1),
("shujia", 1))
val dataList2 = List(
("java", 100),
("java", 99),
("shujia", 88),
("shujia", 66))
val RDD1: RDD[(String, Int)] = sc.parallelize(dataList1)
val RDD2: RDD[(String, Int)] = sc.parallelize(dataList2)
//采样倾斜的key
val sampleRDD: RDD[(String, Int)] = RDD1.sample(false, 1.0)
//skewedKey 导致数据倾斜的key shujia
val skewedKey: String = sampleRDD.map(x => (x._1, 1))
.reduceByKey(_ + _)
.map(x => (x._2, x._1))
.sortByKey(ascending = false)
.take(1)(0)._2
//导致数据倾斜key的RDD
val skewedRDD1: RDD[(String, Int)] = RDD1.filter(tuple => {
tuple._1.equals(skewedKey)
})
//没有倾斜的key
val commonRDD1: RDD[(String, Int)] = RDD1.filter(tuple => {
!tuple._1.equals(skewedKey)
})
val skewedRDD2: RDD[(String, Int)] = RDD2.filter(tuple => {
tuple._1.equals(skewedKey)
})
val commonRDD2: RDD[(String, Int)] = RDD2.filter(tuple => {
!tuple._1.equals(skewedKey)
})
val n = 2
//对产生数据倾斜的key 使用mapjoin
val skewedMap: Map[String, Int] = skewedRDD2.collect().toMap
val bro: Broadcast[Map[String, Int]] = sc.broadcast(skewedMap)
val resultRDD1: RDD[(String, (Int, Int))] = skewedRDD1.map(kv => {
val word: String = kv._1
val i: Int = bro.value.getOrElse(word, 0)
(word, (kv._2, i))
})
//没有数据倾斜的RDD 正常join
val resultRDD2: RDD[(String, (Int, Int))] = commonRDD1.join(commonRDD2)
//将两个结果拼接
resultRDD1.union(resultRDD2)
.foreach(println)
}
}使用随机前缀和扩容RDD进行join
很少使用,会导致RDD数据膨胀