六、Sails中执行存储过程模拟Waterline的Create插入数据
文章目录
- 创建 baseCreate 存储过程
-
- 参数设置
- Prepared Statements
- LAST_INSERT_ID和@@IDENTITY
- 模拟Waterline
-
- sendNativeQuery
- 规划
- 密钥处理
- 转换字段名称和字段值
- 返回数据处理
-
- 修改控制器代码
- datetime bug
- mysql库中对数据库字段类型定义
- customToJSON
- postman自动化测试
清楚Waterline执行Query操作之后,我们已经具备足够知识来做一个可以模拟ORM的操作了。我们从数据库的增删改查之“增”开始,对应Waterline中Models的create 。
创建 baseCreate 存储过程
插入新数据是比较单纯而且简单的功能。在存储过程中可以通过拼接insert语句来实现。如果需要插入多条语句,insert后面的values可以增加有多个数据,这种操作的效率还是比较高的。
参数设置
拼接insert语句,我们需要tableName,字段名称,字段值以及插入后是否返回已经插入的数据的开关变量fetch,在代码和数据库之间传递值或是字段名称,可以通过上一篇博文里面说到的转义操作来实现对关键词的保护,代码在传递参数给数据库的过程中要传递的内容再加上“”(双引号)可以一定程度防止sql注入攻击。参数部分代码如下:
CREATE DEFINER=`root`@`localhost` PROCEDURE `baseCreate`(
IN `tableName` VARCHAR(200),
IN `cols` VARCHAR(1000),
IN `colValues` TEXT,
IN `fetch` BIT
)
为了统一管理本系统源代码(包含存储过程的源代码),在根目录下面创建sql子目录。把调试通过的存储过程代码以存储过程名称为文件名,.sql为扩展名保存在代码库。git上传的时候一并上传。
Prepared Statements
存储过程中建议使用预处理语句,mariaDB和mysql在预处理方面使用的是二进制,可以提高传输效率。并且和普通sql语句比较也有一定的性能优势。如果在预处理语句中使用参数,还可以防止注入式攻击。
LAST_INSERT_ID和@@IDENTITY
insert 语句常会遇到自增长id的问题。在mariaDB和mysql中都可以通过select last_insert_id()或select @@identity来获取最新插入的自增长id的值。这两做做法的选择需要更加深入的查询mysql官方文档,简单的说两个比较重要的知识点。
- 当使用INSERT语句插入多条记录的时候,使用LAST_INSERT_ID()返 回的仍是第一条的ID值,而@@IDENTITY返回最后一条。
- LAST_INSERT_ID()的值是由MySQL server来维护的,而且是为每条连接维护独立的值,也即某条连接调用last_insert_id()获取到的值是这条连接最近一次insert操作执行后的自增值,该值不会被其它连接的sql语句所影响。这个行为保证了不同的连接能正确地获取到它最近一次insert sql执行所插入的行的自增值,也就是说,last_insert_id()的值不需要通过加锁或事务机制来保证其在多连接场景下的正确性。
考虑到插入多条语句大多数情况下是不需要返回新id的,我的存储过程选择了LAST_INSERT_ID的做法。
存储过程具体代码可详见github上的源代码。如果需要copy写入数据库,可以考虑HeidiSQL里面的查询窗口输入并执行即可。
在HeidiSQL中执行存储过程创建语句的时候,应该下拉执行按钮并选择“一次性发送批处理”选项,否则容易出错。
模拟Waterline
sendNativeQuery
要执行存储过程,需要用到waterline的sendNativeQuery函数,示例如下:
var rawResult = await datastore.sendNativeQuery(sql, valuesToEscape);
Waterline 支持在第一个参数sql中使用$1, $2语法,把需要转义的变量写在valuesToEscape数组里面。可以根据情况选择自己转义或使用Waterline转义。
执行存储过程通过sendNaviteQuery发送call xxx 的Sql语句就可以实现。比如:
let INSERT_SQL = `CALL baseCreate("${sqlTableName}","${res.cols}", "(${res.values})", ${isFetch});`;
this.sa.sendNativeQuery(sql, valuesToEscape);//sa是sails全局变量,是sails.io.js 及sails 环境变量,数据模型等
在这个过程中,我们需要用到sails的waterline,我们的配置,加密的时候的密钥甚至是 lodash 工具库等等。为此我们需要一个规划,设计一个基础类集成需要用到的对象实例,其它类在基础类上面拓展。
规划
在根目录下的utils里面创建基础类:wlBase.ts。这个基础类实现对sendNativeQuery的操作分装,对前端传递过来的对象(req.body)进行解析,对sql语句进行转义,并对执行结果进行重组和封装。然后再创建其它的模拟类就可以以wlBase为父类,实现更多操作。其代码片段如下:
...
class wlBase {
/**
* sails的加密模块
*/
private EA: any;
private _: ToolsModule.Lodash;//lodash
/**
* sails 实例
*/
readonly sa: SailsData;
**
* config/models.js里面的默认字段属性配置
*/
readonly mConfig: AttributeCollection = ModelConfig.models.attributes;
....
}
...
密钥处理
在wlBase里面,我需要处理加密问题,config/models里面我们设置了多组密钥。并且这些密钥以年+季度号为key的,比如k20224表示是2022年第四季度,因此我们需要一个可以根据当前时间计算出应该使用什么密钥的程序,这个程序在wlBase里面用一个私有函数实现:
/**
* 获取config/models里面设置的加密密钥
* 可以在config里面配置多个密钥,比如每个季度一个密钥
* 根据当前日期所属季度计算key,如果有这个key就用新密钥,如果没有就用default
*/
private getEncryptKey(): void {
if (this.sa && this.sa.config.models.dataEncryptionKeys) {
let key = `k${dtHelper.currentYear()}${dtHelper.currentQuarter()}`;
if (this.sa.config.models.dataEncryptionKeys[key]) {
this.encryptKey = this.sa.config.models.dataEncryptionKeys[key];
} else {
this.encryptKey = this.sa.config.models.dataEncryptionKeys.default;
key = 'default';
}
this.EA = EncryptedAttributes(undefined, {
keys: this.sa.config.models.dataEncryptionKeys,
keyId: key
})
}
}
const EncryptedAttributes = require(‘encrypted-attr’); 就是引用前面说到的encrypted-att 库
转换字段名称和字段值
要实现插入数据,还需要把前端传过来的对象里面包含的字段名称和值根据models里面定义的字段属性转换成要添加到数据库里面的字段名称和值,如果是遇到需要加密的要进行加密,需要自动获取当前时间作为插入值的也需要在这个地方处理。这个程序在wlBase里面的可继承函数 colsAndValues 里面实现:
/**
* 根据字段信息转换成create操作的sql字段信息和值信息并做转义处理
*/
protected colsAndValues(attributes: Orm.AttributeCollection, data: any): SQL.colsAndValues {
//合并传递过来的属性和config/models里面设置的公共属性
let att = { ...attributes, ...this.mConfig };
let cols: Array<string> = new Array<string>();
let values: Array<string> = new Array<string>();
for (const key in att) {
let type: string = '';//字段类型
let autoIncrement: boolean = false;//是否自增长
let item: AttributeObject = <AttributeObject>att[key];//当前操作数据
if (item.autoMigrations) autoIncrement = item.autoMigrations.autoIncrement || false;
if (autoIncrement) continue;//自动增长类型的字段不需要插入
cols.push(SqlString.escapeId(key));//对字段名称执行转义(添加mysql的`转义符号)
if (item.autoMigrations) type = item.autoMigrations.columnType || item.type;
let valueItem = data[key] || '';
if (valueItem && item.encrypt) {
valueItem = this.encryptPassword(valueItem);
}
// 自动添加创建时间
if (item.autoCreatedAt) {
if (this.isDateType(type)) valueItem = dtHelper.parseDateTime(new Date());
else valueItem = new Date().getTime();
}
// 自动添加更新时间
if (item.autoUpdatedAt) {
if (this.isDateType(type)) valueItem = dtHelper.parseDateTime(new Date());
else valueItem = new Date().getTime();
}
values.push(SqlString.escape(valueItem));//根据值进行转义
}
return {
cols: cols.join(','),
values: values.join(',')
}
}
返回数据处理
wlBas设计好之后,在utils文件夹里面添加wlSimulate.ts 这是一个以wlBase为父类的waterline 模拟类,这个类的设计目标是进行参数处理和执行存储过程以及决定怎么处理返回数据。
/**
* 使用存储过程的方法模拟waterline(orm)操作
*/
class wlSimulate extends wlBase {
/**
* 调用baseCreate存储过程插入数据
* @param tableName 表名称
* @param attributes 表属性
* @param data 要插入的数据
* @param fetch 是否返回插入记录
* @returns 插入记录或自增长Id
*/
async create(tableName: string, attributes: Orm.AttributeCollection, data: any, fetch: boolean): Promise<any> {
try {
let sqlTableName = this.sqlEscapeId(tableName);
let res = this.colsAndValues(attributes, data);
let isFetch = fetch ? 1 : 0;//对boolean类型进行转换
// 本代码插入单个数据,如果需要插入多个数据,可以组织多组values的值,每组用()包围并用,分割
let INSERT_SQL = `CALL baseCreate("${sqlTableName}","${res.cols}", "(${res.values})", ${isFetch});`;
let result = await this.sendQuery(INSERT_SQL);//获取存储过程的执行结果
return result;
}
catch (error) {
throw error;//这个地方要抛出错误给控制器
}
}
修改控制器代码
万事俱备了,现在我们可以修改我们的控制器代码了,找到api/controllers/UserController.ts 里面的create函数,修改代码如下:
// api/controllers/UserController.ts
....
/**
* 增加
* @param req api请求
* @param res api响应
* @param next 回调函数
*/
export async function create(req: Api.SailsRequest, res: Api.Response, next: Function): Promise<any> {
try {
let wl = new wlSimulate(req._sails);//我们创建的模拟类
let result = await wl.create('user', UserAttributes.attributes, req.body, true);//调用模拟类里面的ctreate函数,调用存储过程
res.status(200).send(result);
} catch (error) {
res.serverError(error);
}
};
....
如果都顺利,因为我们baseCreate存储过程可以返回插入的最后一条数据,所有将会得到以下结果:
{
"rows": [
[
{
"createdAt": "2022-12-04T03:27:21.410Z",
"updatedAt": 1670124441410,
"id": 3,
"email": "[email protected]",
"password": "YWVzLTI1Ni1nY20kJGsyMDIyNA==$upt6s+3rY/fknAFF$ag2nwVfr$XHDjkV6sbHSd1hAHyJHfyg",
"nickname": "Q8FDQ"
}
],
{
"fieldCount": 0,
"affectedRows": 1,
"insertId": 0,
"serverStatus": 2,
"warningCount": 0,
"message": "",
"protocol41": true,
"changedRows": 0
}
],
"fields": [
[
{
"catalog": "def",
"db": "admindata",
"table": "user",
"orgTable": "user",
"name": "createdAt",
"orgName": "createdAt",
"charsetNr": 63,
"length": 23,
"type": 12,
"flags": 128,
"decimals": 3,
"zeroFill": false,
"protocol41": true
},
{
"catalog": "def",
"db": "admindata",
"table": "user",
"orgTable": "user",
"name": "updatedAt",
"orgName": "updatedAt",
"charsetNr": 63,
"length": 20,
"type": 8,
"flags": 0,
"decimals": 0,
"zeroFill": false,
"protocol41": true
},
...
],
null
]
}
这个返回结果是machinepack-mysql库返回的原始结果,有对mysql库的返回结果进行简单封装处理,返回结果里面有两部分:
- rows:返回查询的结果行,不论查询结果是否单行,rows第一个元素都是数组,第二个是sql语句的影响行数和改变行数等信息,这些信息可以根据需要处理
- fields:这个返回结果是对返回rows结果集的描述,包含数据库,表等名称信息已经字段类型 type
datetime bug
前面我们已经知道,如果数据库的类型设置为datetime并且我们程序对象是string类型,那么mysql或mariaDB库会把日期时间类型转换成带Z的零时区字符串(UTC),比如:“2022-12-04T03:27:21.410Z”, 这个数据直接插入数据库是不能通过的,必须把数据库的sql_model里面的严格模式关闭掉。而关闭严格模式的情况下,数据库会简单的把带Z的零时区数据去掉“Z”之后保存起来,由于datetime类型是不记录时区的,所以存入数据库的数据就变成“2022-12-04 03:27:21.410”(差8小时) 下次取出来再次转换成UTC(带“Z”零时区)数据就会再次减掉8小时(针对东8区)变成“2022-12-03T19:27:21.410” 依次循环,每存和取一次,时间就会少掉8个小时。这个是做ORM映射的时候选择string 对 datetime 的 Bug。
这种情况,返回数据的fields里面记录的数据类型就有用了,我们可以根据fileds里面的Type判断,如果是日期类型我们需要把它转换的零时区数据变成本地时间。
mysql库中对数据库字段类型定义
观察返回数据可见,Type的值是number类型,这个类型我们需要追溯到最初的源代码才能看到它的类型定义。在mysql库的protocol中有一个types.js ,我们可以看到这些类型的定义。比如我们的返回数据fields里面的createAt对应的type值是12(见下图),比对types.js代码可发现这个对应的数据类型就是datetime (mysql库里面的代码是:exports.DATETIME = 12;)

我们要做的也简单,在根目录下的typing子文件夹中添加SqlTypes.ts,把sql库中的类型定义复制进来,做成枚举类型,代码片段如下:
export enum SqlTypes {
DECIMAL = 0,
TINY = 1,
SHORT = 2,
LONG = 3,
FLOAT = 4,
DOUBLE = 5,
NULL = 6,
TIMESTAMP = 7,
....
}
做成枚举类型的好处是在typescript中可以非常清晰的引用,并且光标在某个枚举类型的时候,按F12(或Ctrl+单击)可以追踪到定义处。
有了这个类型定义之后,我们可以对返回数据进行简单的转换,代码片段如下(具体可见源代码rebuildRowsData函数):
switch (type) {
case SqlTypes.DATE: case SqlTypes.DATETIME: case SqlTypes.DATETIME2:
case SqlTypes.TIME: case SqlTypes.TIME2: case SqlTypes.TIMESTAMP: case SqlTypes.TIMESTAMP2:
it = dtHelper.parseDateTime(it);//把UTC时间转成本地时间
break;
}
经过处理之后,返回数据如下:

customToJSON
直到目前都还不错,但是返回数据里面把密码这种敏感信息泄露出来了,尽管已经有加密过,但是能不返回密码才是更安全的。实际上我们再model的user数据模型里面是有处理过的,我们当时有设计了另一个customToJson函数把password这个敏感信息剔除掉的,当时的代码是这样的:
//api/models/User.ts
import UserModel from "typing/UserModel";
declare var _: any;//获取lodash这个操作库
let User: UserModel.UserDefs = {
attributes: {
email: { type: 'string', unique: true,required:true },
password: { type: 'string', encrypt: true },
nickname:{type:'string'}
},
customToJSON:function():any {
return _.omit(this, ['password']);//每个数据模型都可以自定义toJSON函数,在该函数决定给前端看什么样的数据
}
}
在waterline的model模块里面,waterline会自动合并用户定义的customToJSON到每个对象的toJSON()函数里面,在控制器发送数据给前端的时候不论我们的代码里面是否执行toJSON(),waterline都会强制执行该函数。这样做的目的是为了方便我们再每个数据模型里面通过自定义函数决定给前端看什么样的数据,从而确保敏感信息的安全。
所以customToJSON 这个函数很重要,我们用存储过程插入或查询数据的时候,由于不是调用waterline的model模块,所以没有执行该函数。因此我们必须把waterline的model模块里面的自定义函数合并到我们的返回数据对象上,这样res.send的时候就可以调用我们在api/models的所有数据模型里面设计好的customToJSON函数了,代码如下:
/**
* 复制自定义数据模型的toJson函数
* @param returnData 需要返回的记录数据
* @param tbName sails的model里面定义的模型名称(一般和表名称一致,如果不一致请传递model名称)
*/
protected copyCustomToJson(returnData: any, tbName: string) {
if (this.sa.models[tbName] && this.sa.models[tbName].customToJSON) {
Object.defineProperty(returnData, 'toJSON', {
writable: true,
value: this.sa.models[tbName].customToJSON
});
}
}
现在,返回的数据没有敏感信息,我们原来在User模型里面定义的customToJSON()函数起作用了:

添加了几条测试数据之后,每次重启sails的时候,由于我们打开了query调试功能,auto-migrating 过程可以看清楚sql的执行情况了。
postman自动化测试
完成用存储过程模拟waterline的create之后,直到现在一切都OK。然而内心还是会有一些惶恐:不知道这样的处理之后,代码的执行效率如何,稍微多一些的数据插入会不会导致什么未知的问题。
事实上,前面博文有提过我在写这个博客的时候就发现我加密后的数据有一小部分会导致auto-migrating 因为不能顺利解密而出错,我正是通过插入1000条数据来测试并找到这个bug的。
我们需要更多的测试数据,然而这个有点不容易。因为我们如果通过postman一条一条的添加,工作量巨大,并且不能批量执行,我们也测不出我们控制器的性能如何,我们需要自动化测试。幸运的是,我们习惯使用的Postman就有这样的能力。
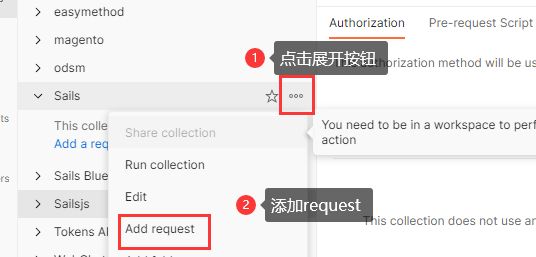
打开Postman(本文的Postman版本是v10.5.2) ,点击Collections,添加新Collection,输入Sails:
- 新增一个 Collection

- 新增一个Request
- Pre-request:由于我们的email是设置为不可重复的,我需要postman每次提交的email都不一样,这个用手动处理太麻烦,我们可以简单的用一个时间变量来做email的用户名,这样可以确保我们任何时候提交的email都和数据库里面的不一样。要实现这个,需要postman里面的Pre-request 。
postman的Pre-request 支持全局变量(环境变量)和用JavaScript 生成全局变量,具体函数是pm.environment.set。以下一行代码实现用时间戳做email,并设置到环境变量"emal"里面
pm.environment.set('email',new Date().getTime()+'@gmail.com');
- 昵称是可以不用处理的,但是为了测试效果,我们可以做一个自动生成随机昵称的,代码如下:
//生成随机字符串
function randomString(len) {
len = len || 32;
var $chars = 'ABCDEFGHJKMNPQRSTWXYZabcdefhijkmnprstwxyz2345678';
var maxPos = $chars.length;
var pwd = '';
for (var i = 0; i < len; i++) {
pwd += $chars.charAt(Math.floor(Math.random() * maxPos));
}
return pwd;
}
pm.environment.set('nickName',randomString(5));
合并上述两点,执行界面如下图:

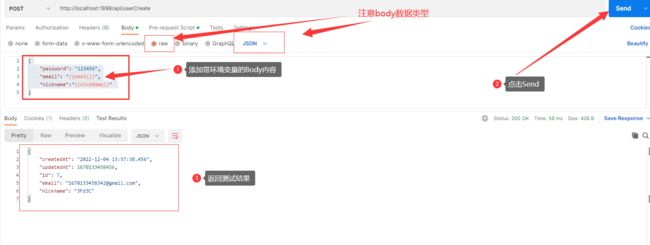
- Request Body:却换到Body标签,在Body里面使用环境变量(全局变量)提交,其中环境变量用{{ }}包裹,代码如下:
{
"password": "123456",
"email": "{{email}}",
"nickname":"{{nickName}}"
}
- 提交测试:保存本次请求并点击Send 按钮,如下图:
- 批量运行Run :在Postman界面上,点击我们创建的Collection 后右边有一个Run按钮,如下图:

- 设置运行迭代次数为1000,让Postman发送1000次请求,如下:

运行1000次提交之后,我们可以导出测试结果:可以看到本次提交次数和总用时(单位:毫秒)
"count": 1000,
"totalTime": 19680,
并且我们可以看到数据库里面新增了1000条记录。