JVM系列--虚拟机的内存管理
Java语言和其他语言在内存管理的区别
对比其他语言,例如C语言,在内存管理方面,Java要做得更加“智能”一些。主要是因为Java语言提供了相关的虚拟机进行内存管理。
通常在C语言里面,创建一个对象之后需要手动进行对象内存的delete,free处理。例如这段代码:
#include <iostream>
using namespace std;
int main() {
cout << "free begin " << endl;
void* p = malloc(1024 * 1024 * 10 * sizeof(int));
free(p);
cout << "free end ";
}
代码内部需要手动执行free函数。
而在Java程序中却没有这类操作对存在,关于内存对分配和释放对于开发人员来说是完全透明的,主要工作交给了Java虚拟机去完成。但是这样的设计也有弊端:一旦出现了内存泄漏排查也比较困难。
内存管理比对图

JVM的内存布局–程序计数器
在Java虚拟机里面(这里主要是讲解jdk1.8版本),主要分为了以下部分,如下图所示:
程序计数器其实就是当前程序所运行的字节码行号指令器。字节码指令在工作的时候通过程序计数器的值来获取下一条指令值,程序计数器的值相当于不同指令所在的内存地址。
下边我们通过一段代码来查看分析。
public class TestDemo {
private int addOne(int a){
return a+1;
}
public static void main(String[] args) {
TestDemo testDemo = new TestDemo();
int p = 1;
int j = 2;
int result = testDemo.addOne(p) + j;
System.out.println(result);
}
}
这样的一段代码,通过Javac 命令先进行编译为class文件,然后再通过Javap -c 查看字节码内容,就会得出这么一份内容:
public class org.idea.netty.framework.server.test.TestDemo {
public org.idea.netty.framework.server.test.TestDemo();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: return
public static void main(java.lang.String[]);
Code:
0: new #2 // class org/idea/netty/framework/server/test/TestDemo
3: dup
4: invokespecial #3 // Method "":()V
7: astore_1
8: iconst_1
9: istore_2
10: iconst_2
11: istore_3
12: aload_1
13: iload_2
14: invokespecial #4 // Method addOne:(I)I
17: iload_3
18: iadd
19: istore 4
21: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
24: iload 4
26: invokevirtual #6 // Method java/io/PrintStream.println:(I)V
29: return
}
看到最左边的字节码序列号,在14号的位置,执行了一次addOne操作,在该函数执行之后,需要重新回到之前的调用方位置,继续执行之前剩下的操作:
int result = testDemo.addOne(p) + j;
这个时候就需要提前使用程序计数器(PC)记录下后续需要返回的程序指令所在的内存地址。
为什么需要这一设计?
因为在操作系统中CPU是轮流切换不同的线程,所以当某个程序执行到一半,CPU去执行其他程序了,此时就需要有一个中间介质将之前执行的程序运行到的地址给记录下来,方便后续调用的时候直接提取使用。
为了最大化减少CPU来回切换过程中,对每个线程执行下一指令的影响,程序计数器被设计存放在了栈当中。
JVM的内存布局–栈
比较多的书籍里买呢,关于虚拟机栈总有不同的说法,这里我推荐以周志明老师的《深入理解Java虚拟机》一书中的说法为准。早期的虚拟机里面关于栈的说法主要有两大门派,分别是本地方法栈和虚拟机栈。
本地方法栈 当调用的是原生native方法的时候,需要寄存到本地方法栈当中
虚拟机栈 专门为调用jvm内部方法所提供的一个栈
但是在主流的Hotspot虚拟机中本地虚拟栈和虚拟机栈已经被融合成了一体,所以并没有过多的区别。
Java的栈是属于线程私有的一个模块,生命周期和线程一样。 每个栈里面都会存储一定的栈帧,栈帧包含了操作数栈,动态链接,局部变量表,方法出口。
操作数栈 执行指令的时候,需要将指令加入到操作数栈当中,而此时执行的每一条指令都需要压入到操作数栈里面。
动态链接 可以理解为将一些栈上边的信息和堆里面的数据做关联的一个操作。
局部变量表 每个函数的局部变量,参数列表。
方法出口 每个子方法执行完毕之后,都需要回到之前调用方的入口模块。
由于栈帧是属于线程私有的内存区域,所以有的时候如果在一个私有函数中包含了过多的临时变量,或者某些函数的递归层数过深都会导致栈帧空间不足,从而报出stackoverflowerror异常。
ps:注意hotspot的虚拟机是不允许栈空间不足继续扩容的,但是早期的classic虚拟机却允许。
JVM的内存布局–堆
在JVM中的堆区域,这是属于一个公共部分的区域,算是jvm里面的最大的一块内存区域了,几乎所有的对象都是存储在堆这个模块中,(也有特殊情况会将对象分配到栈上)堆设计的初衷其实就是为了给对象存储所使用的。
网上经常会有一些文章或者传言说,堆分为了年轻代,老年代,年轻代又分为eden区,survivor区域。其实这种说法是不严谨的描述,因为大部分程序员采用的jdk都是hotspot的相关产品,该类虚拟机在早期的时候主要是采用了分代回收的思路来进行内存管理,而如今虚拟机早已提供了更多优秀的垃圾收集技术,所以这种说法准确来讲应该换成:采用分代回收思路来进行收集的主流java虚拟机中,堆主要分为了年轻代,老年代…
关于对象存储的位置,其实只能说大部分存储在堆中,但是少数情况下,堆可以额外开辟一个空间用于给线程存储一些属于它们专有的buffer。这种技术叫做TLAB,属于栈上分配技术。
为什么要发明TLAB技术?
学习一门技术的过程中,弄清楚其发展的原因其实是非常重要的,不然很容易就变得知其然而不知其所以然,知道有这么一种技术,知道该怎么熟练运用,其背后的原理,但是却不了解为什么要这么设计。
首先我们来思考一下这么一个问题,当一个全新的对象需要分配内存的时候需要考虑哪些情况?
计算对象所需要的空间大小
寻找合适的内存区域
将对象分配到指定的内存区域
分配对象的过程主要包含了上述的这几个步骤,那么假设在多线程的环境下,情况就变得复杂了。分配对象的过程中还需要考虑加锁控制,内存空间中的一些指针碰撞问题等等问题,因此通过堆来分配内存其实还是一件非常繁琐的事情。在早期jdk1.5出来之后,java语言的市场日渐庞大,企业级的大型系统应用开始渐渐增多,于是在hotspot jvm 1.6 推出的时候,出现了tlab技术,专门用于优化这种堆频繁分配内存造成的性能损耗问题。
tlab全称为:ThreadLocalAllocBuffer 在下一篇文章中我会介绍到关于hotspot中使用tlab技术的一些细节点。
JVM的内存布局–方法区
在jvm里面,还有一个公共的内存区域被叫做为方法区,主要是用于存储一些常量池的数据信息和jvm初始化过程中加载的类文件信息。
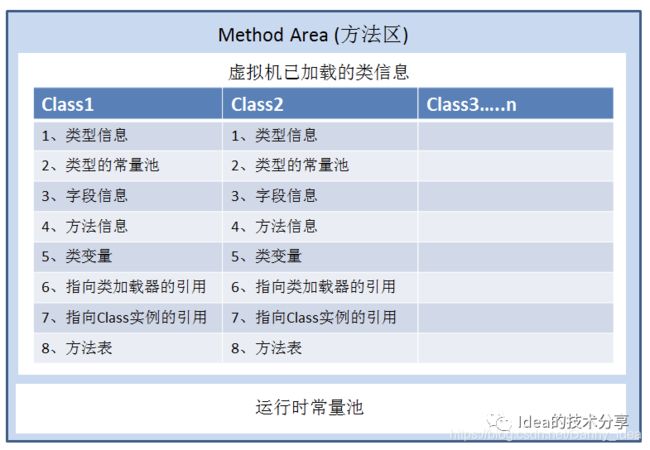
很多时候我们都容易产生一个知识误区,误以为永久代就是方法区,但是这种说法是不完善的,需要有所调整,因为大部分的时候我们都是使用了hotspot虚拟机,而其他的例如说j9,jrockit虚拟机,它们并没有永久代这么一个说法。
在早期的时候,hotspot虚拟机采用了分代收集的思路来进行垃圾回收,才会将方法区这个部分归拢为了永久代(full gc的时候是会回收的),但是当后续演进过程中,hotspot团队发现使用永久代在垃圾回收的时候并不高效率,甚至在jdk8的时候将其进行了废弃。
方法区是和堆属于两个不同的存储区域,永久代是属于hotspot系列专有的一种说法。
JVM的内存布局–直接内存
直接内存的这个模块其实并不是java虚拟机规范所定义的内存区域,但是在使用的时候,因为这块内存是使用了操作系统中的内存空间,所以如果使用中超过了机器限制的内存大小,也会有oom发生。

在jdk1.4的时候出现了nio技术,这里面引入了channel和buffer的概念,比较经典的代表就是使用directbytebuffer对象来作为直接内存引用的相关操作,从而避免了java堆和native堆的来回复制数据问题。