本体调研
1.1本体概念
本体是用于描述一个领域的术语集合,其组织结构是层次结构化的,可以作为一个知识库的骨架和基础。
本体不等同于个体,它是相应领域内公认的概念集合。
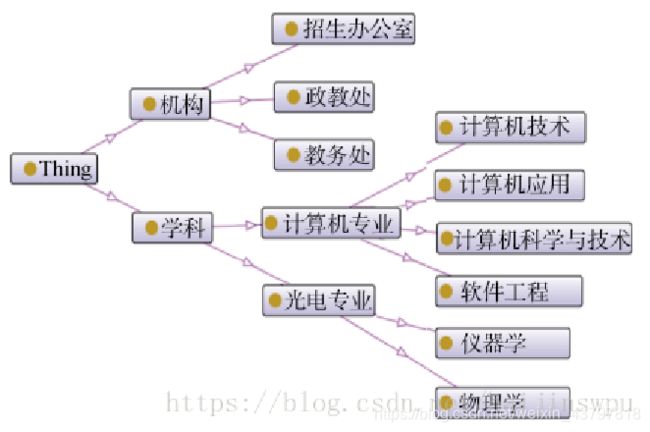
1.2 本体分类
依照领域依赖程度:
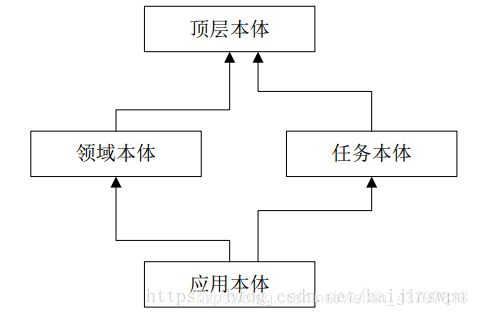
(1)顶层本体:研究通用概念以及概念之间的关系,如空间、时间、事件等,与具体应用无关,完全独立于限定领域,因此可以在较大范围内进行共享。
(2)领域本体:研究的是特定领域内概念及概念之间的关系。
(3)任务本体:定义一些通用任务或相关推理活动,用来表达具体任务内的概念及概念之间关系。
(4)应用本体:用来描述一些特定的应用,既可以引用领域本体中特定的概念,又可以引用任务本体中出现的概念。
根据本体表示的形式化程度不同:
- 完全非形式化,完全采用自然语言进行表示,结构松散,如术语列表。
- 结构非形式化,采用受限的或结构化的自然语言进行表示,能有效提高本体论的清晰度,减少二义性。如Enterprise Ontology的文本版本。
- 半形式化,采用一种人工定义的形式化语言进行表示,目前己有许多研究机构开发制定了这类形式化本体论表示语言,许多采用Ontolingua描述的本体都属于这一类。
- 完全形式化所有属性都具有形式化的语义,并能在某种程度上证明包括一致性和完整性等方面的属性。
根据本体应用主题:
-
本体在一个特定的领域中可重用,它们提供该领域特定的概念定义和概念之间的关系,提供该领域中发生的活动以及该领域的主要理论和基本原理等。对特定领域的本体研究和开发目前已涉及许多领域,其中包括企业本体、医学概念本体、酶催化生物学本体和陶瓷材料机械属性本体等。
-
通用或常识本体:关注于常识知识的使用。通用知识本体的研究包括著名Cyc的公司的OpenCyc本体,最新版的OpenCyc包括6000个概念和60000个关于这些概念的声明(包括概念间的关系、对概念的限制等,另外OpenCyc还包括一个基于本体论的常识推理机。
-
知识本体:它的研究重点是语言对知识的表达能力。典型的有斯坦福大学知识系统实验室提供的一种称为知识交换格式KIF(Knowledge Interchange Format)的知识描述语言,以及可以在线将各种知识转换为KIF的本体服务器Ontolingua。目前普遍认为,所有其它的知识表示形式都可以转换为KIF的形式。
-
语言学本体是指关于语言、词汇等的本体。典型的实例有GUM(Generalizeduppr model)即和普林斯顿大学研制的WordNet。
-
任务本体:也称为方法本体,任务本体是本体研究的另一个分支,主要研究可共享的问题求解方法,这里的推理方法与领域无关,任务本体主要涉及动态知识,而不是静态知识,任务本体中经常描述的要素包括任务目标、任务数据、执行状态等等。具体的研究主题包括通用任务、与任务相关的体系结构、任务方法结构、推理结构和任务结构等。
1.3 本体构成
构成:五元素(建模元语)
①类(Classes)或概念(Concepts);
② 关系(Relations);
③ 函数(Functions);
④ 公理(Axioms);
⑤ 实例(Instances)
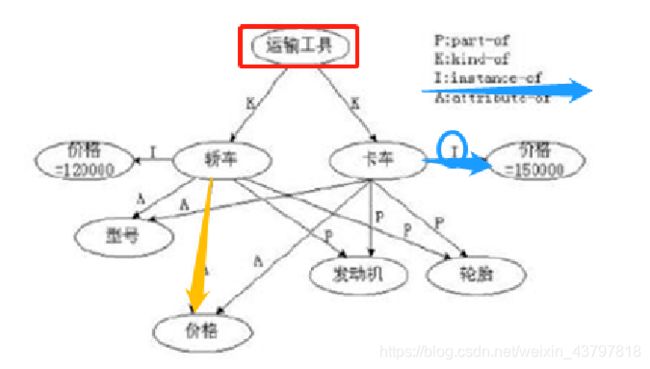

1.4 描述语言
本体的描述语言众多,W3C推荐的本体描述语言主要有RDF、RDFS和OWL。
1、RDF(资源描述框架),RDF用于描述web上的资源,是使用XML语言编写、计算机可读的,不是为了向用户展示。
2、RDFS(RDF Schem,RDF词汇描述语言),RDFS是在RDF基础上对其进行扩展而形成的本体语言,解决了RDF模型原有的缺点,定义了类、属性、属性值来描述客观世界,并且通过定义域和值域来约束资源,更加形象化表达了知识。
3、OWL(Web Ontology Language,Web本体语言),用来对本体进行语义描述。OWL保持了原有RDF、RDFS的兼容性,有较好的语义表达能力,根据表达能力的增强顺序OWL分为三种子语言:OWL-Lite、OWL-DL和OWL-Full。
1.5 应用领域
应用于知识工程、自然语言处理、系统建模、信息处理、数字图书馆、信息检索和语义Web、软件复用、面向对象技术等领域。
典型应用案例:
(l)基于语义的信息检索,特别是网络搜索引擎和数字化图书馆。
(2)基于本体的数据集成、机器学习等。
(3)领域本体的应用。比如,在生物信息学中已建成的GeneOntology,尽管只包括了part-of等简单的关系,但是对生物信息学界已经有巨大的影响。
(4)语义Web服务。
(5)在线元数据管理和自动信息发布。
1.6 研究现状
国外:
国外对本体建模作了大量研究并运用于知识工程领域。主要代表为:
① 万维网联盟W3C的研究;
② 德国卡尔斯鲁厄大学基于本体的知识门户和语义门户的研究;
③ 美国斯坦福大学的知识系统实验室对本体建模工具和本体应用层面的研究。
国内:
国内进行本体研究的主要有三支科研力量。
1)中国科学院计算所、数学所、自动化所的若干实验室,代表人物是陆汝铃院士等人。
2)哈尔滨工业大学计算机系,代表人物是王念滨博士。
3)浙江大学人工智能研究所,代表人物是博士生导师高济教授。
2.1 构建方法
-
手工建立本体:需要大量领域专家的参与
最具有代表性的项目有:①Princeton 大学的 Miller 等人构建的 WordNet,为自然语言的多个术语提供解释;②董振东历经多年搭建的知网(HowNet),是一个通用知识库,包含了大量中英文概念、概念间的关系以及属性间的关系。 -
半自动构建本体(复用已有本体):主要采用人工参与和计算机辅助的方式,目前大多借助本体构建工具和本体描述语言。利用已有输入、输出窗口,可以方便用户进行编辑、生成和维护本体。但只是用于建立本体的结构形式,并不支持本体内容的构建。计算机辅助在概念获取、概念关系抽取等过程均有涉猎,但仍离不开人为干预,在本体信息筛选阶段表现得愈加明显。
-
自动构建本体:是彻底由机器通过自然语言处理、机器学习以及人工智能等方法从大量自由文本、机器可识别的词典、叙词表、数据库等数据源中获取概念及其概念间的关系。通过此方法不仅可以从已有数据源中发现已有知识,并且还可以挖掘出潜在的知识,应用前景十分可观。但是此种方法严重依赖算法库质量的好坏,因此,如何填补此研究领域的空白,是当今研究的一大热点。
2.2 构建难点
- 现状大多手工建立本体费时费力,特定领域需专家参与。
- 通用的大规模本体少,大多本体只针对某个具体应用领域构造的
- 在实际应用中,不同本体之间映射、扩充与合并处理等操作复杂。
- 现实的知识体系变化时,先前构造的本体必须作相应的演化保持一致性。
2.3 领域本体构建工程思想
IDEF-5方法:通过使用图表语言和细化说明语言,获取关于客观存在的概念、属性和关系,并将它们形式化成本体。
骨架法,又称Enterprise法,专门用来创建企业本体。
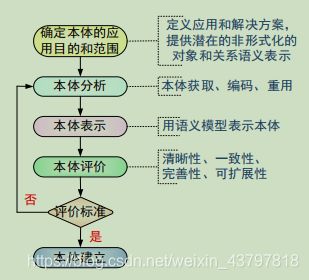
TOVE企业建模法,通过本体建立指定知识的逻辑模型。
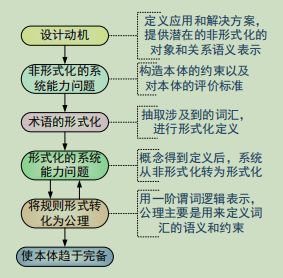
Methontology方法,是在结合了骨架法和GOMEZ-PEREZ方法后提出的一种更通用的方法。专用于创建化学本体(有关化学元素周期表的本体),该方法已被马德里大学理工分校人工智能图书馆采用。
循环获取法,是一种环状的结构。流程如下:(1)资源选取(2)概念学习(3)领域集中(4)关系学习(5)评价
七步法:由斯坦福大学医学院开发,主要用于领域本体的构建。

2.4 现有的领域本体构建方法
1、构建领域本体的知识工程方法
主要特点:强调构建本体时要按照一定的规范和标准。相对于一般的系统,本体更强调共享、重用,可以为不同系统提供一种统一的语言,因此本体构建的工程性更为明显。
方法:目前本体工程中比较有名的方法包括TOVE 法、Methontology方法、骨架法、IDEF-5法和七步法等。(大多是手工构建领域本体)
现状: 由于本体工程到目前为止仍处于相对不成熟的阶段,领域本体的建设还处于探索期,因此构建过程中还存在着很多问题。
方法成熟度: 常用方法的成熟度依次为:七步法、Methontology方法、IDEF-5法、TOVE法、骨架法。
2、基于叙词表的领域本体构建
叙词表是一种语义词典,由术语及术语之间的各种关系组成。叙词表包含丰富的领域概念和语义关系,在表达知识结构上与本体有着天然联系,因此国内外很多学术团体都在尝试基于叙词表构建本体,研究重点在于叙词表向本体转换的方法。
现状:
国外:比较成熟的是通过本体表示语言对叙词表的词语和关系进行转换,有以下几种:用XML Schema构建叙词标记语言、用RDF Schema关系表示叙词内容、用RDF Schema表示叙词关系、用DAML + OIL关系表示叙词关系。
国内:对叙词表转化的研究,正处于热点阶段,主要有《国防科学技术叙词表》和《中国农业科学叙词表》的一部分。中国农业科学院科的常春博士基于《中国农业科学叙词表》的"作物大类",构建了一个有关食物安全的本体原型。中国国防科技信息中心的唐爱民等结合Enterprise方法、Methontology方法与"瀑布模型",基于《国防科学技术叙词表》成功构建了军用飞机领域本体的原型。
3、基于顶层本体构建领域本体的构建方法
本体构建的理论探讨已经比较成熟,但当将构建完的本体与实际应用联系起来的时候,就会存在的一些问题:
① 领域本体构建与应用脱节;
②领域本体难以复用和集成;
③ 由叙词表难以转化成真正的本体;
④ 本体构建的概念体系不够规范。
针对这些问题,提出了基于顶层本体开发领域本体的指导方法。
该方法从本体工程方法论的成熟度和领域本体构建的特点出发,借鉴了骨架法和七步法,并融合了叙词表和顶层本体资源,对概念体系的规范化校验和本体的标准化处理提出了具体的方法和步骤。

2.5 本体构建工具
目前常用的本体构建工具主要分为两类:可视化手工构建工具和半自动化构建工具。
- 可视化手工构建工具,主要有protégé、Apollo、WebOnto、WebODE和OntoEdit等,这类工具通常为用户提供可视化界面,用户可以通过简单的操作完成本体的构建。
① Protégé具有图形化的用户界面,操作简单,支持模块化设计,支持DAML+OIL和OWL语言,可利用RDF、RDFS和OWL等语言对本体进行编辑。但protégé不能批量导入数据,构建大规模本体费时费力,手工输入效率较低。
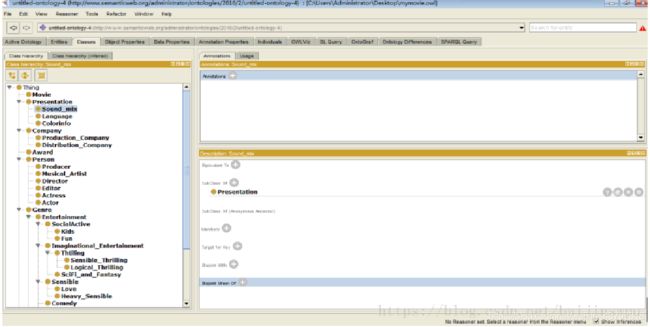
现在常用的本体构建工具中,只有protégé支持中文输入,
可以构建中文本体,但在中文推理机制方面却表现不佳,而其他构建工具基本上都不支持中文。
② OntoEdit 提供多种图形视窗来支持本体建模,并在其官网上公布了输入、输出
插件,同时支持字符数据型(String List)、布尔数据型(Boolean Data)、概念列表型
(Concept List)等多种数据类型的插件;提供了图形规划(Graph Layout)、实例编
辑器(Instance Editor)、概念关系拆分(Concept Relation Split)等多种工具插件;提
供可视化显示插件,具有多种可变样式。
- 半自动化构建工具。基于Java语言的Jena大大提高了构建本体的效率,但还没有实现完全意义上的自动化本体构建,仍需进一步研究。