Etcd 入门简介
1. 简介
Etcd 是 CoreOS 基于 Raft 开发的分布式 key-value 存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。
1.1 特性
- Go 语言实现的高可靠 KV 存储系统
- 支持HTTP协议的PUT/GET/DELETE操作
- 支持服务注册与发现,WATCH接口(通过 HTTP Long Polling 实现)
- 支持 KEY 持有 TTL 属性
- CAS (Compare and Swap) 操作
- 支持多key的事务操作
- 支持目录操作
1.2 使用场景
- 服务注册和发现
- 配置中心
- 分布式锁
- Leader选举
2. Raft 一致性
2.1 基本概念
-
角色
- Leader
- Follower
- Candidate
-
Term (任期)
- 在raft协议中,将时间分成一个个任期
-
复制状态机:保证数据的一致性
-
心跳(heartbeat) 和 超时机制(timeout)
在Raft算法中,有两个timeout机制来控制leader选举:
- 选举定时器(election timeout): follower等待成为candidate的等待时间,它被随机设定为150ms~300ms
- 心跳定时器(heartbeat timeout): 某节点成为leader后,它会发送Append Entries消息个其他节点,这些消息就是通过heartbeat timeout来传递,follower接收到leader的心跳包的同时也重置选举定时器
2.2 Leader 选举
-
触发条件:
- 正常情况下,follower收到leader的心跳后,会把定时器清零,不会触发选举
- follower的选举定时器超时(可能是leader故障),会变成candidate,触发leader选举
-
选举过程:
- 一开始,所有节点都是follower,同时启动选举定时器(150ms ~ 300ms,随机的,降低冲突概率)
- 定时器到期,变成candidate
- 当前任期加+1,并投自己一票
- 发起 RequestVote 的 RPC 请求,要求其他节点为自己投票
- 如果得到超过半数的节点同意,就成为了leader
- 如果选举超时,未产生leader,则进入下一个任期,重新选举
-
限制条件:
- 每个节点最多投一次票,采用先到先服务原则
- 如果没有投过票,则对比candidate的log与当前节点的log那个最新,谁的lastLog的term越大谁就越新,如果term相同,谁的index越大谁就越新。如果当前节点比candidate新,拒绝投票。
2.3 日志复制
当前 Leader 收到客户端的日志(事务请求)后先把该日志追加到本地的 Log 中,然后通过 heartbeat 把该 Entry 同步给其他 Follower,Follower 接收到日志后记录日志然后向 Leader 发送 ACK,当 Leader 收到大多数(n/2+1)Follower 的 ACK 信息后将该日志设置为已提交并追加到本地磁盘中,通知客户端并在下个 heartbeat 中 Leader 将通知所有的 Follower 将该日志存储在自己的本地磁盘中。
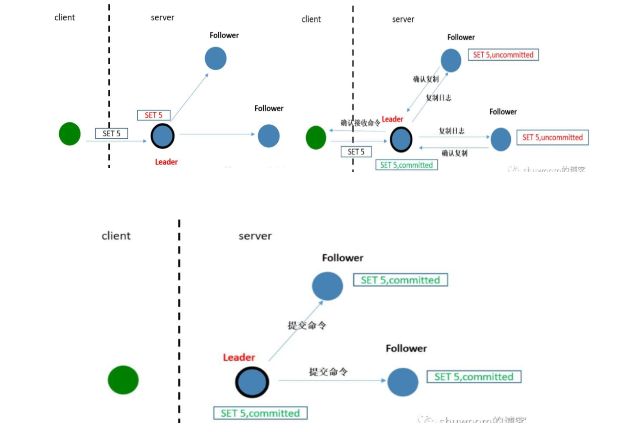
示例:
-
Client向Leader提交指令(如:SET 5),Leader收到命令后,将命令追加到本地日志中,该目录状态处于"uncommitted",复制状态机不会执行该命令
-
Leader将命令(SET 5)并发复制给其他节点,并等待其他节点将命令写入到日志中,如果此时有些节点失败或者慢,Leader节点会一直重试,直到半数以上节点将该命令写入到了日志中。之后Leader节点就提交命令,并返回给Client节点
-
Leader提交命令后,下一次的心跳包中会通知其他follower也来提交这条命令。收到Leader的消息后,就将命令应用到状态机中(State Machine),最终保证每个节点的数据一致。
2.4 安全性
安全性是用于保证每个节点都执行相同序列的安全机制,如当某个 Follower 在当前 Leader commit Log 时变得不可用了,稍后可能该 Follower 又会被选举为 Leader,这时新 Leader 可能会用新的 Log 覆盖先前已 committed 的 Log,这就是导致节点执行不同序列;Safety 就是用于保证选举出来的 Leader 一定包含先前 committed Log 的机制;
-
选举安全性(Election Safety):每个任期(Term)只能选举出一个 Leader
-
Leader 完整性(Leader Completeness):指 Leader 日志的完整性,当 Log 在任期 Term1 被 Commit 后,那么以后任期 Term2、Term3… 等的 Leader 必须包含该 Log;Raft 在选举阶段就使用 Term 的判断用于保证完整性:当请求投票的该 Candidate 的 Term 较大或 Term 相同 Index 更大则投票,否则拒绝该请求。
2.5 失效处理
-
Leader 失效:其他没有收到 heartbeat 的节点会发起新的选举,而当 Leader 恢复后由于步进数小会自动成为 follower(日志也会被新 leader 的日志覆盖)
-
follower 节点不可用:follower 节点不可用的情况相对容易解决。因为集群中的日志内容始终是从 leader 节点同步的,只要这一节点再次加入集群时重新从 leader 节点处复制日志即可。
-
多个 candidate:冲突后 candidate 将随机选择一个等待间隔(150ms ~ 300ms)再次发起投票,得到集群中半数以上 follower 接受的 candidate 将成为 leader
3. Wal 日志
3.1 简介
WAL:Write Ahead Log,预写式日志。它的最大作用是记录了整个数据变化的全部历程。在etcd中,所有数据的修改在提交前,都要先写入到WAL。
WAL 数据存储优势:
- 故障快速恢复:当数据遭到破坏时,可通过执行所有WAL中记录的修改操作,快速从最原始的数据恢复到数据损坏前的状态
- 数据回滚(undo)和重做(redo):因为所有的修改操作都被记录在WAL,需要回滚或重做,只需在日志找到相应的执行点即可。
3.2 日志格式
wal 日志是二进制的,解析出来后是以上数据结构 LogEntry,其构成:LogEntry: type|term|index|data
-
type: 有两种, 0 表示 Normal,1 表示 ConfChange(ConfChange 表示 Etcd 本身的配置变更同步,比如有新的节点加入等)
-
term:每个 term 代表一个主节点的任期,每次主节点变更 term 就会变化。
-
index:这个序号是严格有序递增的,代表变更序号
-
data:二进制格式,将 raft request 对象的 pb 结构整个保存下。Etcd 源码下有个 tools/etcd-dump-logs,可以将 wal 日志 dump 成文本查看,可以协助分析 raft 协议。
raft 协议本身不关心应用数据,也就是 data 中的部分,一致性都通过同步 wal 日志来实现,每个节点将从主节点收到的 data apply 到本地的存储,raft 只关心日志的同步状态,如果本地存储实现的有 bug,比如没有正确的将 data apply 到本地,也可能会导致数据不一致。
3.3 Wal & Snapshot
日志名称:
WAL: $seq-$index.wal
Snapshot: $term-$index.snap
cd /var/lib/etcd/default.etcd/member
tree
.
├── snap
│ ├── 0000000000000023-00000000000186a1.snap
│ └── db
└── wal
├── 0000000000000000-0000000000000000.wal
├── 0000000000000001-000000000001677b.wal
├── 0.tmp
└── 1.tmp
etcd-raft中的snapshot,其主要功能是为了回收日志占用的存储空间(包括内存和磁盘)。
etcd-raft中的snapshot代表了应用的状态数据,而执行snapshot的动作也就是将应用状态数据持久化存储,这样,在该snapshot之前的所有日志便成为无效数据,可以删除。。
4. MVVC 存储引擎
4.1 Etcd V3
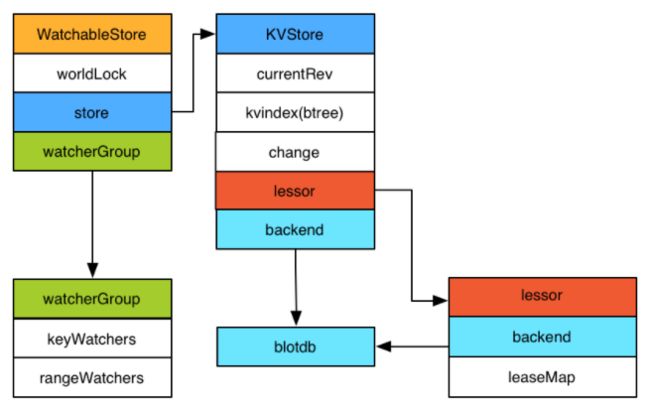
Etcd v3 store 分为两部分:
- kvindex:内存中的索引,基于 golang 的 btree 实现
- backend:后端存储。它可以对接多种存储,当前使用的 boltdb。boltdb 是一个单机的支持事务的 kv 存储,Etcd 的事务是基于 boltdb 的事务实现的。Etcd 在 boltdb 中存储的 key 是 revision,value 是 Etcd 自己的 key-value 组合,也就是说 Etcd 会在 boltdb 中把每个版本都保存下,从而实现了多版本机制。
多版本记录:
etcdctl txn <<<'
put key1 "v1"
put key2 "v2"
'
etcdctl txn <<<'
put key1 "v12"
put key2 "v22"
'
# boltdb
rev={3 0}, key=key1, value="v1"
rev={3 1}, key=key2, value="v2"
rev={4 0}, key=key1, value="v12"
rev={4 1}, key=key2, value="v22"
# revision 主要由两部分组成,第一部分 main rev,每次事务进行加一,第二部分 sub rev,同一个事务中的每次操作加一。
watcherGroup 状态:
- synced: 表示该 group 的 watcher 数据都已经同步完毕,在等待新的变更
- unsynced: 表示该 group 的 watcher 数据同步落后于当前最新变更,还在追赶
当 Etcd 收到客户端的 watch 请求,如果请求携带了 revision 参数,则比较请求的 revision 和 store 当前的 revision,如果大于当前 revision,则放入 synced 组中,否则放入 unsynced 组。同时 Etcd 会启动一个后台的 goroutine 持续同步 unsynced 的 watcher,然后将其迁移到 synced 组。
4.2 Etcd v2 & Etcd v3
-
接口通过 grpc 提供 rpc 接口,放弃了 v2 的 http 接口。优势是长连接效率提升明显,缺点是使用不如以前方便,尤其对不方便维护长连接的场景。
-
废弃了原来的目录结构,变成了纯粹的 kv,用户可以通过前缀匹配模式模拟目录。
-
内存中不再保存 value,同样的内存可以支持存储更多的 key。
-
watch 机制更稳定,基本上可以通过 watch 机制实现数据的完全同步。
-
提供了批量操作以及事务机制,用户可以通过批量事务请求来实现 Etcd v2 的 CAS 机制(批量事务支持 if 条件判断)。
5. 集群安装
5.1 docker
$ cat > docker-compose.yml <<EOF
version: "3"
networks:
etcd_net:
driver: bridge
volumes:
etcd1_data:
etcd2_data:
etcd3_data:
services:
etcd1:
image: "bitnami/etcd:3.5.1"
container_name: etcd1
restart: always
ports:
- "12380:2380"
- "12379:2379"
networks:
- etcd_net
environment:
- ALLOW_NONE_AUTHENTICATION=yes
- ETCD_NAME=etcd1
- ETCD_LISTEN_PEER_URLS=http://0.0.0.0:2380
- ETCD_LISTEN_CLIENT_URLS=http://0.0.0.0:2379
- ETCD_ADVERTISE_CLIENT_URLS=http://etcd1:2379
- ETCD_INITIAL_ADVERTISE_PEER_URLS=http://etcd1:2380
- ETCD_INITIAL_CLUSTER_TOKEN=etcd-cluster
- ETCD_INITIAL_CLUSTER=etcd1=http://etcd1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380
- ETCD_INITIAL_CLUSTER_STATE=new
volumes:
- etcd1_data:/bitnami/etcd
etcd2:
image: "bitnami/etcd:3.5.1"
container_name: etcd2
restart: always
ports:
- "22380:2380"
- "22379:2379"
networks:
- etcd_net
environment:
- ALLOW_NONE_AUTHENTICATION=yes
- ETCD_NAME=etcd2
- ETCD_LISTEN_PEER_URLS=http://0.0.0.0:2380
- ETCD_LISTEN_CLIENT_URLS=http://0.0.0.0:2379
- ETCD_ADVERTISE_CLIENT_URLS=http://etcd2:2379
- ETCD_INITIAL_ADVERTISE_PEER_URLS=http://etcd2:2380
- ETCD_INITIAL_CLUSTER_TOKEN=etcd-cluster
- ETCD_INITIAL_CLUSTER=etcd1=http://etcd1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380
- ETCD_INITIAL_CLUSTER_STATE=new
volumes:
- etcd2_data:/bitnami/etcd
etcd3:
image: "bitnami/etcd:3.5.1"
container_name: etcd3
restart: always
ports:
- "32380:2380"
- "32379:2379"
networks:
- etcd_net
environment:
- ALLOW_NONE_AUTHENTICATION=yes
- ETCD_NAME=etcd3
- ETCD_LISTEN_PEER_URLS=http://0.0.0.0:2380
- ETCD_LISTEN_CLIENT_URLS=http://0.0.0.0:2379
- ETCD_ADVERTISE_CLIENT_URLS=http://etcd3:2379
- ETCD_INITIAL_ADVERTISE_PEER_URLS=http://etcd3:2380
- ETCD_INITIAL_CLUSTER_TOKEN=etcd-cluster
- ETCD_INITIAL_CLUSTER=etcd1=http://etcd1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380
- ETCD_INITIAL_CLUSTER_STATE=new
volumes:
- etcd3_data:/bitnami/etcd
EOF
$ docker-compose up -d
$ docker exec -it eaf4ca35e233 /bin/sh
# etcdctl member list
ade526d28b1f92f7, started, etcd1, http://etcd1:2380, http://etcd1:2379, false
bd388e7810915853, started, etcd3, http://etcd3:2380, http://etcd3:2379, false
d282ac2ce600c1ce, started, etcd2, http://etcd2:2380, http://etcd2:2379, false
5.2 二进制
# 1. 安装
wget https://github.com/etcd-io/etcd/releases/download/v3.5.1/etcd-v3.5.1-linux-arm64.tar.gz
tar zxvf etcd-v3.5.1-linux-arm64.tar.gz
mv etcd-v3.5.1-linux-arm64/etcd* /usr/local/bin/
mkdir -p /etc/etcd
# 2. 配置
cat > /etc/etcd/etcd.conf.yml <<EOF
name: 'etcd-1'
data-dir: /var/lib/etcd/default.etcd
wal-dir: ''
snapshot-count: 10000
heartbeat-interval: 100
election-timeout: 1000
quota-backend-bytes: 0
listen-peer-urls: 'http://192.168.3.191:2380'
listen-client-urls: 'http://localhost:2379,http://192.168.3.191:2379'
max-snapshots: 5
max-wals: 5
cors: ''
initial-advertise-peer-urls: 'http://192.168.3.191:2380'
advertise-client-urls: 'http://localhost:2379,http://192.168.3.191:2379'
discovery: ''
discovery-fallback: 'proxy'
discovery-proxy: ''
discovery-srv: ''
initial-cluster: 'etcd-1=http://192.168.3.191:2380,etcd-2=http://192.168.3.192:2380,etcd-3=http://192.168.3.193:2380'
initial-cluster-token: 'etcd-cluster'
initial-cluster-state: 'new'
strict-reconfig-check: false
enable-v2: true
enable-pprof: false
proxy: 'off'
proxy-failure-wait: 5000
proxy-refresh-interval: 30000
proxy-dial-timeout: 1000
proxy-write-timeout: 5000
proxy-read-timeout: 0
client-transport-security:
cert-file: ''
key-file: ''
client-cert-auth: false
trusted-ca-file: ''
auto-tls: false
peer-transport-security:
cert-file: ''
key-file: ''
client-cert-auth: false
trusted-ca-file: ''
auto-tls: false
self-signed-cert-validity: 1
log-level: info
logger: zap
log-outputs: [stderr]
force-new-cluster: false
auto-compaction-mode: periodic
auto-compaction-retention: "1"
EOF
# 3. 启动
cat > /lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
ExecStart=/usr/local/bin/etcd --config-file=/etc/etcd/etcd.conf.yml
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start etcd
systemctl status etcd
5.3 集群信息
$ etcdctl member list -w table
+------------------+---------+--------+---------------------------+-------------------------------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------+---------------------------+-------------------------------------------------+------------+
| 12971f2c752331ba | started | etcd-3 | http://192.168.3.193:2380 | http://192.168.3.193:2379,http://localhost:2379 | false |
| 7fe4b7b1994a2a9f | started | etcd-1 | http://192.168.3.191:2380 | http://192.168.3.191:2379,http://localhost:2379 | false |
| 96c03e6d8f6451f3 | started | etcd-2 | http://192.168.3.192:2380 | http://192.168.3.192:2379,http://localhost:2379 | false |
+------------------+---------+--------+---------------------------+-------------------------------------------------+------------+
$ etcdctl endpoint status --write-out=table
+----------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| 127.0.0.1:2379 | 7fe4b7b1994a2a9f | 3.5.1 | 20 kB | true | false | 2 | 9 | 9 | |
+----------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
$ etcdctl endpoint health --write-out=table
+----------------+--------+------------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+----------------+--------+------------+-------+
| 127.0.0.1:2379 | true | 5.796647ms | |
+----------------+--------+------------+-------+
6. 启动参数
--quota-backend-bytes: 当后端数据空间大小超过配额时发出告警,集群进入维护模式,只支持读取和删除。在释放足够空间后,告警解除,集群恢复正常
--auto-compaction-mode=revision --auto-compaction-retention=1000 automatically Compact on "latest revision" - 1000 every 5-minute (when latest revision is 30000, compact on revision 29000)
--auto-compaction-mode=periodic --auto-compaction-retention=10h automatically Compact with 10-hour retention windown for every 1-hour. Now, Compact happens, for every 1-hour but still with 10-hour retention window.
0Hr (rev = 1)
1hr (rev = 10)
...
8hr (rev = 80)
9hr (rev = 90)
10hr (rev = 100, Compact(1))
11hr (rev = 110, Compact(10))
...
Whether compaction succeeds or not, this process repeats for every 1/10 of given compaction period. If compaction succeeds, it just removes compacted revision from historical revision records
7. 数据持久化
Etcd 的数据目录:
-
snap:存放快照,Etcd 为防止 WAL 文件过多会创建快照。
-
wal:存放预写式日志,其最大的作用是记录整个数据变化的全部历程。在 Etcd 中,所有数据的修改在提交前,都要先写入 WAL 中。使用 WAL 进行数据的存储使得 Etcd 拥有故障快速回复和数据回滚这两个重要功能。
-
故障快速恢复:如果你的数据遭到破坏,就可以通过执行所有 WAL 中记录的修改操作,快速从最原始的数据恢复到数据损坏之前的状态。
-
数据回滚(undo)/ 重做(redo):因为所有的修改操作都被记录在 WAL 中,所以进行回滚或重做时,只需要反向或正向执行日志中的操作即可。
-
既然有了 WAL 实时存储所有的变更,那么为什么还需要做快照呢?
- 因为随着使用量的增加,WAL 存储的数据会暴增,为了防止磁盘很快就爆满,Etcd 默认每 10000 条记录做一次快照,做过快照之后的 WAL 文件就可以删除。而通过 API 可以查询的历史 Etcd 操作默认为 1000 条。
首次启动时,Etcd 会把启动的配置信息存储到 data-dir 参数指定的数据目录中。配置信息包括本地节点的 ID、集群 ID 和初始时集群信息。用户需要避免从一个过期的数据目录中重新启动 Etcd,因为使用过期的数据目录启动的节点会与集群的其他节点产生不一致(例如,重启之后又向 Leader 节点申请这个信息)的问题。所以,为了最大化保障集群的安全性,一旦有任何数据存在损坏或丢失的可能性,就应该包这个节点从集群中移除,任何加入一个不带数据目录的新节点。
8. MVCC
悲观锁和乐观锁:
-
“悲观锁”:Pessimistic Concurrency Control(PCC)它可以阻止一个事务影响其他用户来修改数据。如果一个事务执行的操作对某行数据应用了锁,那么只有在这个事务将锁释放之后,其他事务才能够执行与该锁冲突的操作。悲观并发控制主要用于数据争用激烈的环境,以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本的环境中。
-
“乐观锁”:它假设多用户并发的事务在处理时彼此之间不会互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务都会先检查在该事物读取数据之后,在没有其他事务又修改了该数据。如果其他事务有更新的话,那么正在提交的事务会进行回滚。
MVCC: 多版本并发控制(Multiversion Concurrency Control)它能够与两者很好地结合以增加事务的并发量。MVCC 的每一个写操作都会创建一个新的版本的数据,读操作会从有限多个版本的数据中挑选一个 “最适合”(要么是最新版本,要么是指定版本)的结果直接返回。通过这种方式,读写操作之间的冲突就不再需要收到关注。因此,如何管理和高效地选取数据的版本就成了 MVCC 需要解决的主要问题。