NoSQL期末复习-MongoDB
一、MongoDB基础
概念
-
MongoDB是一款开源、跨平台、分布式,具有大数据处理能力的文档存储数据库。
-
MongoDB是由C++语言编写的非关系型数据库
-
MongoDB是一个面向集合的文档型数据库。
-
MongoDB的优势:易用性、高性能、高可用性、易扩展性、多种储存引擎
-
MongoDB的逻辑结构是体系结构的一种形式,它是一种层次结构,主要由文档(Document)、集合(Collection)、数据库(DataBase)这三部分组成。MongoDB的逻辑结构是面向用户的。
-
MongoDB默认提供admin、local、config以及test数据库四个数据库
-
集合就是MongoDB的一组文档,分为一般集合和上限集合。
-
文档中不能有重复的键,每个文档都有一个默认的_id键。
使用规范


二、MongoDB基本操作
1)数据库操作
//查看数据库
>show dbs/databases
//创建数据库
>use myDB //如果数据库不存在,则创建数据库,否则切换到指定数据库。
//统计数据库信息
>db.stats()
//删除数据库
>db.dropDatabase()2)集合操作
//创建集合
>db.createCollection("collectionName")
// 查看集合
>show collections
//查看集合详细信息
>db.getCollectionInfos() //查看当前集合
//重命名集合
>db.myCollection.renameCollection("myColl")
//删除集合
>db.myColl.drop()3)插入文档
//插入一条数据
>db.mydb.insert({"name":"lihua","age":19})
>db.students.insertOne(doc1)
//插入多条数据
db.students.insert([doc1,doc2,doc3,...])
db.students.insertMany([doc1,doc2,doc3,...])4)删除文档
db.集合名.deleteMany({}) //删除所有文档
db.集合名.remove({})
假设要删除user集合中所有“username”为”foo”的文档:db.user.remove({“username”:“foo”})5)更新文档
db.collection.update(
,
,
{
upsert: ,
multi: ,
writeConcern:
}
)
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
db.collection.save(object)
object代表需要更新的对象,如果集合内部已经存在一个和object相同的"_id"的记录,Mongodb会把object对象替换集合内已存在的记录,如果不存在,则会插入object对象。 6)更新文档——修改器
1)$inc (修改数值,做加法运算。可以将一个值增加和减少,只能针对数字类型)
> db.mycol.insert({title:"first",visites:107})
//修改参观次数增加1
> db.mycol.update({title:"first"},{$inc:{visites:1}})
//修改参观次数减少2
> db.mycol.update({title:"first"},{$inc:{visites:-2}})
2)$set (可以完成特定需求的修改,即修改某一值。如果指定的键不存在,则进行添加操作)
> db.author.update({"name":"foo"},{$set:{"intro":"teacher"}})
3)$push(可以完成数组的插入,在文档的最后插入,若键不存在,则自动在文档的后面追加数组类型的键值对)
使用$push插入数组:
>db.posts.update({title:"a blog"},{$push:{comments:{name:"leon",email:"leon.email.com",content:"leon replay"}}})
4)$addToSet(向数组中添加元素,如果存在则不添加)
向email数组中添加一个email信息:
>db.user.update({name:“foo”},{$addToSet:{Email:“[email protected]”}})
5)$mul(修改数值,做乘法运算。)
把x的值从2变为x:50:
>db.mycol.update({x:2},{$mul:{x:25}})
6)$rename(修改字段的键名。)
把第一个x:99的键名从x变为m:
>db.mycol.update({x:99},{$rename:{x:"m"}})
7)$unset(删除一个字段。)
>db.mycol.update({m:99},{$unset:{comment:[]}}) //comment是一个数组
>db.sushe.update({"name":"linqian"},{$unset:{height:{}}})
8)$min(给出的值与当前文档字段值进行比较,当给定值比较小时,则修改当前文档值为给定值。)
>db.mycol.update({m:99},{$min:{m:50}})
9)$max(给出的值与当前文档字段值进行比较,当给定值比较大时,则修改当前文档值为给定值。)
>db.mycol.update({m:50},{$max:{m:100}})7)查询文档
1)
>db.collection.find()
>db.collection.find().pretty() //格式化的方式来显示所有文档
>db.collection.findOne() //只返回一个文档
>db.students.count() //查询文档的条数
2)
>db.collection.find({k1:val1,k2:val2...........}) // find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
0表示不显示指定字段,1表显示指定字段。
>db.sushe.find({"name":"linqian"},{"_id":1,"age":0})
3)嵌套文档查询
>db.sushe.insert({ "peo_id" : "006", "name" : "linqian", "age" : 20, "weight" : 98, "hobby" : "read", "comments" : [ { "name" : "xiaolin", "email" : "qq.com" } ] })
> db.sushe.find({"comments.name":"xiaolin"})
(通过“.”连接comments和name,并以双引号方式来实现指定嵌套文档的查询)
4)数组查询
//等价某一数组
>db.sushe.find({"comments" : [ { "name" : "xiaolin", "email" : "qq.com" } ]})
//查询数组中的某一个值
//查询有n个元素的数组
>db.mycol.find({"tags":{$size:n}}).pretty()
5)查找null字段,查找指定无值字段
>db.col.insert([{_id:1,toy:null},{_id:2}])
//查找null值字段
>db.col.find({_id:1,toy:null})
//查找的值不存在
>db.col.find({_id:2,toy:{$exists:false}})
6)limit与skip
//返回第n条文档
>db.sushe.find().limit(n).pretty()
//显示第n条开始的文档
>db.sushe.find().skip(n).pretty()
7)sort()排序
//1 为升序排列,而-1是用于降序排列
//查询年级在2015和2017里面的学生信息,避免写多个and,同时按照他们的班级进行排序,升序
>db.students.find({
grade: {
$in: [2015, 2016, 2017]
}
}).sort({grade:-1});
8)包含($in)和不包含($nin)
//查询年级在2015和2017里面的学生信息,避免写多个and
db.students.find({
grade: {
$in: [2015, 2016, 2017]
}
});
//查询年级不在2015和2017里面的学生信息,避免写多个and
db.students.find({
grade: {
$nin: [2015, 2016, 2017]
}
9)通过查询操作符查找
//区间条件查找
>db.col.find({likes:{$gt:100,$lt:120}})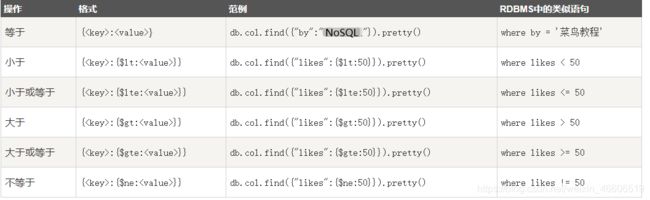
10)or查询
//查询身高大于175的或者低于160的学生信息
db.students.find({
$or: [{
height: {
$gt: 175
}
}, {
height: {
$lt: 160
}
}]
注意:$in用于不同文档指定同一个key进行或条件匹配,$or可以指定多个key或条件匹配。
11)正则表达式查询
语法格式:db.col.find({:{$regex:/pattern/}})
//查询值的固定后一部分
>db.col.find({title:{$regex:/dis$/}}).pretty()
//查询值的固定前一部分
>db.col.find({title:{$regex:/^Mon/}}).pretty()
//查询值的任意一部分
> db.col.find({title:{$regex:/ed/}}).pretty()
//正则表达式options选项
//选项1:i,不区分大小写字母
>db.col.find({title:{$regex:/d/i}}).pretty() 8)聚合操作
aggregate命令的语法:db.colName.aggregate( [ { }, { }, …] )
原数据没有影响。

1)$project 用于修改输入文档的结构//使用0表示结果集中排除字段,1表示结果集中包含字段//新建字段也是给新字段赋值即可,赋值时使用$符号引用原字段的值,如果是子文档中值,使用.符合连接。>db.sushe.aggregate([{$project{"_id":0,"name":1,"age":1,"height":1,"weight":1,"hobby":1,JavaCourse:"$course.Java"}}])
2)$match 用于过滤数据,只输出符合条件的文档
>db.sushe.aggregate([{$match:{"name":"linqian"}}])
3)$limit 用来限制MongoDB聚合管道返回的文档数
>db.sushe.aggregate([{$limit:1}])
4)$skip 跳过指定数量的文档,并返回剩下的文档
>db.sushe.aggregate([{$skip:2}])
5)$unwind 将文档中的某一个数组类型拆分成多条,每条包含数组中的一个值>db.sushe.aggregate([{$unwind:"$course"}])
6)$group 将集合中的文档分组,可用于统计结果,一般与管道表达式$sum等组合使用。>db.sushe.aggregate([{$group:{"_id":"$age"}}])
7)$sort 将文档排序后输出,1为按字段升序,-1表示降序
>db.sushe.aggregate([{$sort:{"age":-1}}])//1代表升序,-1表降序
8)管道表达式
db.sushe.aggregate([{$group:{"_id":"$hobby",age_sum:{$sum:"$age"}}}])//分组再相加
db.sushe.aggregate([{$group:{"_id":"$hobby",age_min:{$min:"$age"}}}])
db.sushe.aggregate([{$group:{"_id":"hobby",people:{$first:"$name"}}}])//分组文档并获取第一个文档
db.sushe.aggregate([{$group:{"_id":"hobby",people:{$last:"$name"}}}])
9)$push 数组添加
// 新建tags字段,分别将同类的产品名称作为tags字段值
>db.product.aggregate([
{$group:{_id:"$type",tags:{$push:"$name"}}}
])
10)$addToSet
11)复合使用例子
//使用aggregate做一个统计,age大于13的文档按age字段分组后统计每组数量。
>db.user.aggregate([
{$match:{age:{$gt:13}}},
{$group:{_id:"$age","amount":{$sum:1}}}
])
//选出age大于13的文档按age的升序排序,取前2个文档参与group,用age分组并统计人数。
>db.user.aggregate([
{$match:{age:{$gt:13}}},
{$sort:{age:1}},
{$limit:2},
{$group:{_id:"$age",amount:{$sum:1}}}
])
//选出age大于13的文档用age分组并统计人数,所得结果按_id的升序排序,取前两个文档作为结果返回。
>db.user.aggregate([
{$match:{age:{$gt:13}}},
{$group:{_id:"$age",amount:{$sum:1}}},
{$sort:{_id:1}},
{$limit:2}
])9)Map-Reduce
MapReduce基本语法:


例题:
测试数据:
{"quantity":2,price:5.0,pnumber:"p003"},{quantity:2,price:8.0,pnumber:"p002"}, {quantity:1,price:4.0,pnumber:"p002"}, {quantity:2,price:4.0,pnumber:"p001"}, {"quantity":4,price:10.0,pnumber:"p003"}, {quantity:10,price:20.0,pnumber:"p001"}, {quantity:10,price:20.0,pnumber:"p003"}, {quantity:5,price:10.0,pnumber:"p002"}
求取相同商品编号的商品总数量。
db.good.mapReduce(
function(){emit(this.pnumber,this.quantity)},
function(key,values){return Array.sum(values)}
{out:"mymapreduce1"}
)
db.mymapreduce1.find()
10)索引
-
索引是一种特殊的数据结构,即采用B-Tree数据结构。
-
MongoDB的索引可以分为6种,即单字段索引、复合索引、多键索引、地理空间索引、文本索引以及哈希索引。
查看索引
>db.mycol.getIndexes()
查看索引大小
>db.mycol.totalIndexSize()
创建索引
>db.mycol.createIndex(keys,options)
//key用于指定索引键,value指定排序顺序,1为升序,-1为降序。
>db.user.createIndex({"myname":1}) //在user集合中创建单字段索引
>db.user.createIndex({age:-1,myname:1}) //在user集合中创建复合索引,在age、myName字段同时创建索引。
删除索引
>db.mycol.dropIndex(index) //参数index,其数据类型为字符串或文档,可用于指定要删除的索引。
>db.mycol.dropIndexes() //删除所有索引
>db.user.dropIndex({myname:1})三、Python操作MongoDB
使用python操作MongoDB需要使用一个第三方库PyMongo
1)连接MongoDB
import pymongo
client = pymongo.MongoClient(host='localhost', port=27017) //无密码连接
client = pymongo.MongoClient('mongodb://localhost:27017/')
client =pymongo.MongoClient("mongodb://admin:[email protected]:27017/") //有密码连接
2)查看MongoDB数据库
dbs=client.list_database_names() //获取MongoDB中所有的数据库;
for db in dbs:
print(db) // 通过一个高级for循环,遍历打印MongoDB中所有的数据库;
3)查看数据里的所有集合
db_user=client["user"]
collection=db_user.list_collection_names //用于查看数据库user中的集合,
4)创建集合
db_user.create_collection("mycol")
5)删除集合
db_user.drop_collection("mycol")
6)查看文档
mycol=db_user["mycol"]
documents=mycol.find()
for document in documents:
print(document)
7)插入文档
newDoc={"name":"qiu","age":19}
mycol.insert_one(newDoc)
8)更新文档
mycol.updateDoc({"name":"qiu"},{"$set":{"age":21}})
9)删除文档
mycol.delete_one({"name":"qiu"})四、MongoDB副本集、分片
-
MongoDB有三种集群部署模式,分别是主从复制(Master-Slaver)、副本集(Replica Set)和分片(Sharding)模式。
-
副本集中主要有三个角色:主节点、从节点(副本节点)、仲裁者。
-
副本节点与主节点同步副本是异步同步
-
MongoDB的副本集中,副本节点是通过 自动拉取 获得主节点数据
-
副本集的功能:冗余的数据、读写分离、自动故障转移
-
MongoDB分片是MongoDB支持的另一种集群形式
-
分片(Sharding)技术是开发人员用来提高 数据存储和数据读写吞吐量 常用的技术之一。
-
分片与副本集主要区别在于,分片是每个节点存储数据的不同片段,而副本集是每个节点存储数据的相同副本。
-
Shard(分片)。每个分片包含被分片数据集合的子集,即一个集合可以被分为若千个分片,每个分片可以部署为副本集。
-
Mongos(路由器)。 Mongos充当查询路由器,提供用户端应用程序和分片集群之间的接口。
-
Config Servers(配置服务)。配置服务存储集群的元数据(含数据块相关信息)和配置设置。配置服务必须部署为副本集。
-
分片键( Shard Key)与块( Chunk) Mongodb通过建立唯一性的分片键来把集合文档分片存储到各个分片服务器之中,也就是一个分片对应一个分片键,分片鍵旦建立就不能更改。 分片键存在于集合中每个文档的索引字段或素引复合字段。
-
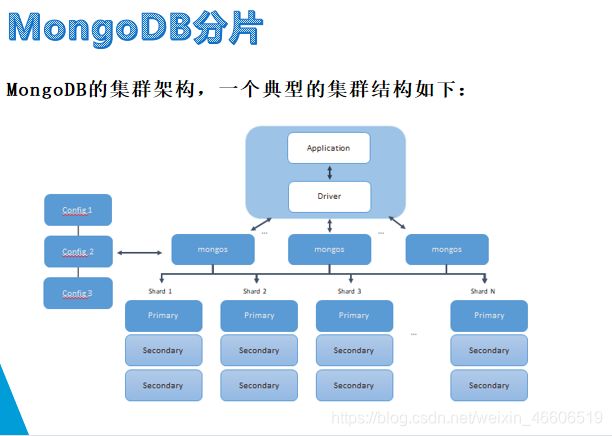
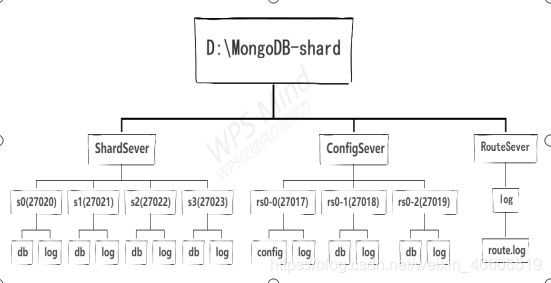
实例:
在单一服务器上建立分片集群模拟结构,要建立的清单如下:
Shard Server1:27020 //分片服务器1.端口号为27020
Shard Server2:27021 //分片服务器1.端口号为27021
Shard Server3:27022 //分片服务器1.端口号为27022
Shard Server4:27023 //分片服务器1.端口号为27023
Config Server:27017--20019 //配置服务器.端口号为27017--27019
Route Process:40000 //路由服务器.端口号为40000
一、大概思路(目录)
1.配置分片服务
>mongod --port 27020 --dbpath d:\MongoDB-shard\ShardServer\s0\db --logpath d:\MongoDB-shard\ShardServer\s0\log\s0.log --logappend --shardsvr
>mongod --port 27021 --dbpath d:\MongoDB-shard\ShardServer\s1\db --logpath d:\MongoDB-shard\ShardServer\s1\log\s1.log --logappend --shardsvr
2.启动Config Server
>mongod --port 27017 --configsvr --dbpath d:\MongoDB-shard\ConfigServer\rs0-0\config --logpath d:\MongoDB-shard\ConfigServer\rs0-0\log\config.log --logappend --replSet rs0
>mongod --port 27018 --configsvr --dbpath d:\MongoDB-shard\ConfigServer\rs0-1\db --logpath d:\MongoDB-shard\ConfigServer\rs0-1\log\mongdb.log --logappend --replSet rs0
>mongod --port 27019 --configsvr --dbpath d:\MongoDB-shard\ConfigServer\rs0-2\db --logpath d:\MongoDB-shard\ConfigServer\rs0-2\log\mongdb.log --logappend --replSet rs0
3.搭建副本集
1、>mongo --port 27017
2、>rsconf = {
_id: "rs0",
members: [
{
_id: 0,
host: "127.0.0.1:27017"
},
{
_id: 1,
host: "127.0.0.1:27018"
},
{
_id: 2,
host: "127.0.0.1:27019"
}
]
}
3、>rs.initiate(rsconf) 初始化副本集
4、>rs.status() 查看副本集状态
5、>db.isMaster 判断主节点和辅助节点
6、use admin
7、向主节点添加一条数据,查看辅助接点是否也有此条数据
8、新开一个dos窗口 登录到辅助节点 查看辅助节点是否有主节点插入的数据
9、在步骤7中查询数据会报错 解决方法如下:
>db.getMongo().setSlaveOk()
>db.getMongo().setSecondaryOk() 
4.启动Route Process
>mongos --port 40000 --configdb "rs0/localhost:27017,localhost:27018,localhost:27019" --logpath d:\MongoDB-shard\RouteServer\rs0-0\log\route.log
5.配置sharding,添加分片节点
- >mongo --port 40000
- >use admin
- >db.runCommand({addShard:"localhost:27020"})
- >db.runCommand({addShard:"localhost:27021"})
- >db.runCommand({addShard:"localhost:27022"})
- >db.runCommand({addShard:"localhost:27023"})
- > db.runCommand({listshards:1}) 查看分片服务器的配置信息
- >db.runCommand({enablesharding:"testdb"}) 设置分片存储的数据库
- >db.runCommand({shardcollection:"testdb.log",key:{id:1}}
6.测试数据操作(紧接步骤五)
- > use testdb
- > for(var i=0;i<15000;i++){db.log.save({id:i,"test1":"testvall"});}
- > sh.status() 查看分片数据库信息