理论部分:K8S中Pod生命周期(包含探针哦)
1 缘起
同事参加定级答辩,被问到探针,
他是后台开发,对于探针的理解没有很深入,
只回答了一些,到这里,我根本不知道探针是啥?
我当时只了解K8S有哪些组件(Ingress、Service、Pod),
以及服务调用链路,还不知道Pod生命周期,
于是,开始针对性补习,查看官网文档https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/,
分享如下。
2 Pod
2.1 Pod lifecycle
Pod遵循定义的生命周期,开始Pod处于Pending阶段,
当至少有一个主容器正常启动时,Pod进入Running阶段,
最后,根据Pod中镜像的最终状态进入到Succeeded或者Failed阶段。
Pod运行的同时,kubelet可以重启容器去处理一些错误。
Pod中,Kubernets追踪不同容器的状态,决定采用何种措施是Pod重新恢复健康。
Kubernets的API中,Pod拥有规范且具体的状态。
Pod对象状态由一系列Pod conditions构成。Pod在其lifetime中只调度一次,
一旦Pod调度(分配)到某个节点,Pod开始运行,直到停止或者终止服务。
2.2 Pod lifetime
与单个应用容器类似,Pod被视为相对短暂(而不是持久)的实体。
Pod创建时分配唯一的ID(UID),调度到节点直到终止(依据重启策略)或者删除。如果节点“死亡”,Pod调度到“死亡”节点在超时后会调度删除。
Pod不会自愈。如果Pod安排到某个节点,然后失败,Pod会被删除;但是,当资源不足或者节点维护时Pod不会继续存活。Kubernates使用更高级别的抽象,称为Controller,用于处理一次性(用完即丢弃)的Pod实例。
一个给定的Pod(UID定义)不会重新调度到不同的节点,但是,Pod可以被新建、几乎相同的Pod代替,即使名称相同,但是UID不同。
当声明某些对象与某个Pod具有相同的lifetime时,如卷(Volume),意味着只要该特定Pod(具有确定的UID)存在,该对象就存在。如果Pod由于某些原因删除,即使替代的Pod已经创建,相关的对象(如卷)同样销毁并重新创建。
2.3 Pod conditions
每个Pod都有PodStatus,该状态有一系列PodConditions,表示Pod是否通过:
- PodScheduled:Pod已调度到某个节点
- ContainerReady:Pod中所有容器均已就绪
- Initialized:所有镜像全部初始化成功
- Ready:Pod可以提供服务,添加到匹配的服务负载均衡池中
Condition属性:
| 序号 | 值 | 描述 |
|---|---|---|
| 1 | type | Pod condition名称,PodScheduled、ContainerReady、Initialized、Ready |
| 2 | status | 表明condition是否可用,可能的值True、False或者Unknown |
| 3 | lastProbeTime | Pod condition探测的最后一次时间 |
| 4 | lastTransitionTime | Pod状态过渡的最后一次时间 |
| 5 | reason | 机器可读、大驼峰文本,表明状态过渡原因 |
| 6 | message | 人类可读信息,表明状态过渡原因 |
- 样例
kind: Pod
...
spec:
readinessGates:
- conditionType: "www.example.com/feature-1"
status:
conditions:
- type: Ready # a built in PodCondition
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
- type: "www.example.com/feature-1" # an extra PodCondition
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
containerStatuses:
- containerID: docker://abcd...
ready: true
2.4 Pod phase
Pods的状态属性是一个PodStatus对象,该对象有phase属性。
Pod阶段是Pod生命周期简单、高级的概括。阶段不是为了全面汇总容器或者Pod状态观测结果,也不是为了成为一个全面的状态机。
Pod阶段可能的值有:Pending、Running、Failed、Succeed、Unknown,
值含义如下所示,
Pod从启动到结束的阶段过程如下图所示。
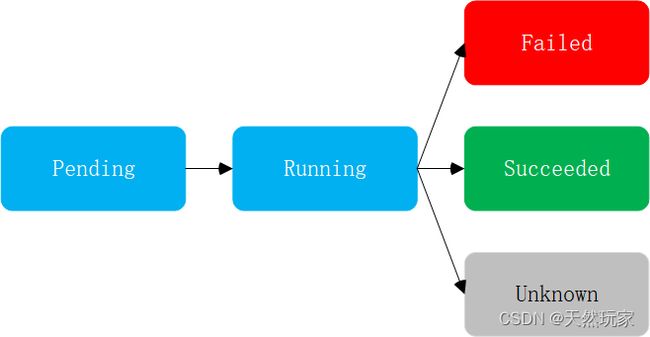
| 序号 | 值 | 描述 |
|---|---|---|
| 1 | Pending | Kubernetes集群已经接受Pod,但是一个或多个容器尚未配置及准备运行。包括通过网络下载镜像消耗的时间、Pod等待调度的时间。 |
| 2 | Running | Pod已经绑定到节点,所有容器已经创建。至少一个容器持续运行或者正在启动或者重启。 |
| 3 | Succeeded | Pod中所有容器成功运行,并且没有重启的。 |
| 4 | Failed | Pod中所有容器都已经终止,至少一个容器终止失败,即容器退出状态非0或者被系统终止 |
| 5 | Unknown | 由于某些原因不能获取Pod状态,这个阶段一般由于Pod与节点通信失败。 |
3 Container
3.1 重启策略
每个的Pod都有重启策略属性,可能的取值为:Always、OnFailure、或者Never,默认为Always。restartPolicy应用到Pod中所有容器,restartPolicy仅指kubelet在同一节点上重新启动容器。Pod中容器退出后,kubelet以指数后退延迟重启(10秒,20秒40秒,…),上限为5分钟。容器执行10分钟没有任何问题后,kubelet重置该容器的重启回退计时器。
3.2 状态
整个Pod阶段,Kubernetes追踪Pod中每个container状态。
某个容器的生命周期中可以使用容器生命周期钩子触发事件执行。
一旦调度器给Pod分配了节点,kubelet开始使用容器运行时为Pod创建容器,
容器状态有三种:Waiting、Running和Terminated,过程如下图所示,
状态解析如下表所示。

| 序号 | 值 | 描述 |
|---|---|---|
| 1 | Waiting | 如果容器状态既不是Running又不是Terminated,则是Waiting状态。容器处于Waiting状态表明容器仍在运行,只是需要时间启动,比如从容器镜像注册中心拉取镜像或者应用Secret数据。当使用kubectl查Pod镜像处于Waiting状态是,需要查看为什么Container处于这个状态。 |
| 2 | Running | 处于Running状态的容器表明容器执行正常没有问题。如果配置postStart钩子,则该钩子已经执行并结束。当使用kubectl查询Pod中镜像状态时,结果为Running。 |
| 3 | Terminated | 处于Terminated状态的容器开始执行,之后运行完成或者由于一些原因失败。当使用kubectl查询Pod中容器处于Terminated状态,可以通过容器退出编码以及容器执行开始和结束时间查看原因。如果为容器配置preStop钩子,这个钩子在容器进入Terminated状态前会执行钩子。 |
3.3 探针
探针是kubelet在容器上定期执行的诊断程序。
探针执行诊断有两种方式:kubelet在容器内执行代码或者发送网络请求执行诊断。
使用探针检测容器有四种不同方式,每个探针必须使用如下四种机制定义:
| 序号 | 值 | 描述 |
|---|---|---|
| 1 | exec | 在容器内执行具体的命令。诊断成功标志:命令执行退出状态码为0 |
| 2 | grpc | 使用gRPC执行远程程序。诊断成功标志:服务响应为SERVING,gRPC探针是实验功能,只有启动GRPCContainerProbe才可使用 |
| 3 | httpGet | 通过Pod的IP地址和指定的port和path执行HTTP GET请求。诊断成功标志:响应编码范围:[200, 400) |
| 4 | tcpSocket | 通过Pod的IP和指定的port指定TCP检测。诊断成功标志:端口是开放的 |
3.3.1 探针outcome
每个探针都有结果,结果有三种,如下表所示:
| 序号 | 值 | 描述 |
|---|---|---|
| 1 | Success | 容器诊断通过 |
| 2 | Failure | 容器诊断失败 |
| 3 | Unknown | 诊断失败,并且没有进一步动作,需要进一步检查 |
3.3.2 探针类型
探针有三种类型,livenessProbe(活性探针)、readinessProbe(就绪探针)和startupProbe(启动探针)。
如下表所示。
| 序号 | 值 | 描述 |
|---|---|---|
| 1 | livenessProbe | 表明容器是否正在运行(Running)。如果活性探针失败,kubelet“杀掉”容器,容器会进入自己的重启策略,如果容器没有提供活性探针,默认状态是Success。 |
| 2 | readinessProbe | 表明容器是否可以响应请求(Ready)。如果就绪探针失败,终端控制器将从所有终端服务中移除匹配的Pod IP地址。初始延迟前就绪的默认状态为Failure,如果容器没有提供就绪探针,默认状态为Success。 |
| 3 | startupProbe | 表明应用的容器是否已经启动(Started)。如果提供启动探针,其他类型的探针在启动探针成功前都是不可用的。如果启动探针失败,kubelet将会“杀掉”容器,容器将执行重启策略,如果容器没有提供启动探针,默认状态为Success。 |
3.3.2.1 何时使用liveness探针(活性探针)
- 不使用活性探针
如果容器进程在遇到问题或者变为不健康时可以自行崩溃,不一定需要活性探针,kubelet会自动执行对应的重启策略。 - 使用活性探针
如果期望当容器重启失败或者被“杀掉”,使用具体的活性探针和具体的重启策略:Always或OnFailure。
3.3.2.2 何时使用readiness探针(就绪探针)
- 使用就绪探针
如果期望只有探针成功时才向Pod发送流量,请使用就绪探针。这里,就绪探针或许与活性探针一样,但是,就绪探针存在的意义是控制流量进入Pod,只有当探针成功启动后才会将流量放入Pod。 - 使用就绪探针
如果期望容器可以自由下线维护,可以使用就绪探针,这就是不同于活性探针的地方,下线过程中不会有流量计进入Pod。 - 使用活性探针和就绪探针
如果应用强依赖后端服务,可以同时使用活性探针和就绪探针。活性探针用于检测服务是否运行,就绪探针检测服务是否可用(获取正常响应),避免流量直接进入Pod,只能获取错误响应。 - 使用就绪探针
如果容器需要载入大尺寸数据、配置文件或者在启动过程中迁移,可以使用启动探针。然而,如果期望检测应用失败和应用继续处理启动数据的差别时,建议使用就绪探针。
3.3.2.3 何时使用startup探针(启动探针)
- 使用启动探针
对于启动时间长的容器可以使用启动探针,不是设置较长的活性间隔,容器启动时可以为容器探测分配独立的配置,允许比活性间隔更长。 - 使用启动探针
如果容器启动时间经常大于initialDelaySeconds+failtureThreshold*periodSeconds,建议使用启动探针,检测终端时具有活性探针的功能。默认的periodSeconds为10秒,设置的failureThreshold应足够大保证容器启动,不需要配置活性探针的默认值,避免死锁,当应用启动后,活性探针才工作。
4 终止Pods服务
因为Pods是运行在集群的节点中,所以,Pods的优雅终止也是非常重要的(当不需要Pod提供服务时,不是强制使用KILL停止服务并且不进行相关清理)。
这个设计是为了相关人员可以请求删除,并且知道何时终止进程,确保完全删除。当请求删除Pod时,集群记录并追踪Pod允许强制删除前的预期宽限期。有了这种强有力的停机跟踪,kubelet尝试优雅地关闭Pod。
通常,容器运行时发送TERM信号到每个容器的主进程。部分容器运行时按照容器镜像定义的STOPSINGAL值替代TERM发送到容器主进程。一旦宽限期过期,KILL信号发送到任意持续运行的进程,之后从API服务删除Pod。如果kubelet或者容器运行时的管理服务等待进程终止时重启,集群会从一开始就重试,包括完整的原始宽限期重试。
5 失败Pod的垃圾回收
对于失败的Pods,API对象在人工处理或者控制器处理移除前会一直存在于集群的。
当Pods的数量超过配置的阈值时,控制面清除终止的Pods(处于Succeeded或Failed阶段),这样操作可以在Pods创建和终止超时避免资源泄露。
6 小结
核心:
(1)Pod阶段可能的值有:Pending、Running、Failed、Succeed、Unkown;
(2)容器状态有三种:Waiting、Running和Terminated;
(3)容器探针有三种类型,livenessProbe(活性探针)、readinessProbe(就绪探针)和startupProbe(启动探针);
(4)使用探针检测容器有四种不同方式:exec、grpc、httpGet和tcpSocket。