教程:使用 Keras 优化神经网络

一、介绍
在 我 之前的文章中,我讨论了使用 TensorFlow 实现神经网络。继续有关神经网络库的系列文章,我决定重点介绍 Keras——据说是迄今为止最好的深度学习库。
我 从事深度学习已经有一段时间了,据我所知,处理神经网络时最困难的事情是无休止的参数调整范围。随着神经网络深度的增加,处理所有参数变得越来越困难。大多数情况下,人们依靠直觉和经验来调整它。事实上,关于这个话题的研究仍然很猖獗。
值得庆幸的是,我们有 Keras,它可以处理大量艰苦的工作并提供更简单的界面!
在 这篇文章中,我将分享我在深度学习方面的工作经验。我们将首先概述 Keras、其功能以及与其他库的区别。然后,我们将了解 Keras 中神经网络的简单实现。然后,我将带您进行神经网络参数调整的实践练习。
、目录
- Keras:概述
- Keras:优点
- Keras:限制
- 使用神经网络解决问题的一般方法
- 从“识别数字”的简单 Keras 实现开始
- 神经网络中需要注意的超参数
- 亲自动手(参数调整)
- 从这往哪儿走?
- 其他资源
二、Keras:概述
keras 是一个高级库,专门用于构建神经网络模型。它是用 Python 编写的,并且与 Python – 2.7 和 3.5 兼容。Keras 专为快速执行想法而开发。它具有简单且高度模块化的界面,使得创建复杂的神经网络模型变得更加容易。该库抽象了低级库,即 Theano 和 TensorFlow,以便用户不受这些库的“实现细节”的影响。
Keras 的主要特点是:
- 模块化: 构建神经网络所需的模块包含在一个简单的界面中,以便 Keras 更易于最终用户使用。
- 简约: 实现简短而简洁。
- 可扩展性: 为 Keras 编写新模块非常容易,并使其适合高级研究。
2.1 Keras:优点
作为一个高级库和更简单的界面,Keras 无疑是最好的深度学习库之一。与其他库相比,Keras 的几个突出特点是:
- 与 Theano 和 TensorFlow 相比,它吸收了这两个库的所有优点,并试图提供更好的“用户体验”。
- 由于 Keras 是一个 Python 库,由于 Python 作为编程语言固有的简单性,它更容易被公众使用。
- 与 Keras 相比,类似的库是 Lasagne,但使用过这两个库后,我可以说 Keras 更容易使用。
考虑到上述原因,Keras 作为深度学习库越来越受欢迎也就不足为奇了。
2.2 Keras:局限性
- 我认为对 Theano / TensorFlow 等低级库的依赖是一把双刃剑。这是因为 Keras 无法“走出这些库的领域”。例如,Theano 和 TensorFlow 都不支持 Nvidia 以外的 GPU(目前)。因此,Keras 也没有相应的支持。
- 与 Lasagne 不同的是,Keras 完全抽象了低级语言。因此,在构建自定义操作时灵活性较差。
- 我要说的最后一点是 Keras 相对较新。第一个版本于 2015 年初发布,此后经历了许多更改。虽然 Keras 已经在生产中使用,但在为生产部署 keras 模型之前应该三思而后行。
三、神经网络解决问题的一般方法
神经网络是一种特殊类型的机器学习 (ML) 算法。因此,与每个 ML 算法一样,它遵循数据预处理、模型构建和模型评估的常见 ML 工作流程。为了简洁起见,我列出了如何解决神经网络问题的 To-D0 列表。
- 检查这是否是神经网络比传统算法带来提升的问题(请参阅上一节中的清单)
- 调查哪种神经网络架构最适合所需的问题
- 通过您选择的语言/库定义神经网络架构。
- 将数据转换为正确的格式并将其分批
- 根据您的需要对数据进行预处理
- 增强数据以增加规模并制作更好的训练模型
- 将批次馈送到神经网络
- 训练并监控训练和验证数据集的变化
- 测试您的模型并保存以供将来使用
四、从“识别数字”的简单 Keras 实现开始
在 开始此实验之前,请确保您的系统中安装了 Keras。参考官方安装指南。我们将使用 Tensorflow 作为后端,因此请确保您已在配置文件中完成此操作。如果没有,请按照此处给出的步骤操作。
在 这里,我们解决了深度学习实践问题—— 识别数字。让我们看一下我们的问题陈述:
我 们的问题是图像识别问题,从给定的 28 x 28 图像中识别数字。我们有一部分图像用于训练,其余图像用于测试我们的模型。首先,下载训练和测试文件。数据集包含所有图像的压缩文件,train.csv 和 test.csv 都有相应的训练和测试图像的名称。数据集中不提供任何附加功能,仅以“.png”格式提供原始图像。
开始吧:
第 0 步:准备
a) 导入所有必要的库
%pylab inline
import os
import numpy as np
import pandas as pd
from scipy.misc import imread
from sklearn.metrics import accuracy_score
import tensorflow as tf
import keras
b) 让我们设置一个种子值,以便我们可以控制模型的随机性
# To stop potential randomness
seed = 128
rng = np.random.RandomState(seed)c) 第一步是设置目录路径,以确保安全!
root_dir = os.path.abspath('../..')
data_dir = os.path.join(root_dir, 'data')
sub_dir = os.path.join(root_dir, 'sub')
# check for existence
os.path.exists(root_dir)
os.path.exists(data_dir)
os.path.exists(sub_dir)第 1 步:数据加载和预处理
a) 现在让我们读取数据集。这些文件采用 .csv 格式,并具有文件名和相应的标签
train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv'))
test = pd.read_csv(os.path.join(data_dir, 'Test.csv'))
sample_submission = pd.read_csv(os.path.join(data_dir, 'Sample_Submission.csv'))
train.head()t
| 文件名 | 标签 | |
|---|---|---|
| 0 | 0.png | 4 |
| 1 | 1.png | 9 |
| 2 | 2.png | 1 |
| 3 | 3.png | 7 |
| 4 | 4.png | 3 |
b) 让我们看看我们的数据是什么样的!我们读取图像并显示它。
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(filepath, flatten=True)
pylab.imshow(img, cmap='gray')
pylab.axis('off')
pylab.show()i
c) 将上图表示为numpy数组,如下所示

d) 为了更轻松地进行数据操作,我们将所有图像存储为 numpy 数组
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
train_x = np.stack(temp)
train_x /= 255.0
train_x = train_x.reshape(-1, 784).astype('float32')
temp = []
for img_name in test.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'test', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
test_x = np.stack(temp)
test_x /= 255.0
test_x = test_x.reshape(-1, 784).astype('float32')
train_y = keras.utils.np_utils.to_categorical(train.label.values)于 这是一个典型的机器学习问题,为了测试模型的正常运行,我们创建了一个验证集。我们将训练集与验证集的分割大小设为 70:30
split_size = int(train_x.shape[0]*0.7)
train_x, val_x = train_x[:split_size], train_x[split_size:]
train_y, val_y = train_y[:split_size], train_y[split_size:]
train.label.ix[split_size:]
第 2 步:模型构建
a) 现在是主要部分了!让我们定义我们的神经网络架构。我们定义一个具有 3 层输入、隐藏层和输出的神经网络。输入和输出中的神经元数量是固定的,因为输入是我们的 28 x 28 图像,输出是表示类别的 10 x 1 向量。我们在隐藏层中有 50 个神经元。在这里,我们使用Adam作为优化算法,它是梯度下降算法的有效变体。keras 中还有许多其他可用的优化器(请参阅此处)。如果您不理解这些术语,请查看有关神经网络基础知识的文章,以更深入地了解其工作原理。
# define vars
input_num_units = 784
hidden_num_units = 50
output_num_units = 10
epochs = 5
batch_size = 128
# import keras modules
from keras.models import Sequential
from keras.layers import Dense
# create model
model = Sequential([
Dense(output_dim=hidden_num_units, input_dim=input_num_units, activation='relu'),
Dense(output_dim=output_num_units, input_dim=hidden_num_units, activation='softmax'),
])
# compile the model with necessary attributes
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
b) It’s time to train our model
trained_model = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y))#
第 3 步:模型评估
a)为了用我们自己的眼睛测试我们的模型,让我们可视化它的预测
pred = model.predict_classes(test_x)
img_name = rng.choice(test.filename)
filepath = os.path.join(data_dir, 'Train', 'Images', 'test', img_name)
img = imread(filepath, flatten=True)
test_index = int(img_name.split('.')[0]) - train.shape[0]
print "Prediction is: ", pred[test_index]
pylab.imshow(img, cmap='gray')
pylab.axis('off')
pylab.show()
p
预测为:8

b)我们看到我们的模型即使非常简单也表现良好。现在我们用我们的模型创建一个提交
sample_submission.filename = test.filename; sample_submission.label = pred
sample_submission.to_csv(os.path.join(sub_dir, 'sub02.csv'), index=False)
五、神经网络中需要注意的超参数
我觉得,与任何其他机器学习算法相比,超参数调整是神经网络中最难的。如果应用网格搜索,你会觉得很疯狂,因为在调整神经网络时有很多参数。
注意:我在下面的文章《使用 TensorFlow 实现神经网络简介》中讨论了有关何时应用神经网络的更多细节
优化神经网络时需要注意的一些重要参数是:
- 建筑类型
- 层数
- 一层中神经元的数量
- 正则化参数
- 学习率
- 使用的优化/反向传播技术的类型
- 辍学率
- 重量共享
此外,根据架构类型,可能还有更多的超参数。例如,如果您使用卷积神经网络,则必须查看超参数,例如卷积滤波器大小、池化值等。
选择好的参数的最佳方法是了解您的问题领域。研究以前对数据应用的技术,最重要的是向有经验的人询问对问题的见解。这是确保获得“足够好”的神经网络模型的唯一方法。
以下是一些有关训练神经网络的提示和技巧的资源。(资源 1、资源 2、资源 3)
六、亲自动手
让我们利用超参数的知识开始调整我们的神经网络模型。
- 正如我们之前所做的那样,我们重做所有先决条件。让我们导入模块
import os
import numpy as np
import pandas as pd
from scipy.misc import imread
from sklearn.metrics import accuracy_score
import tensorflow as tf
import keras
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, Convolution2D, Flatten, MaxPooling2D, Reshape, InputLayer- %和以前一样,设置种子值
# To stop potential randomness
seed = 128
rng = np.random.RandomState(seed)- 设置路径以供进一步使用
root_dir = os.path.abspath('../..')
data_dir = os.path.join(root_dir, 'data')
sub_dir = os.path.join(root_dir, 'sub')
# check for existence
os.path.exists(root_dir)
os.path.exists(data_dir)
os.path.exists(sub_dir)- r读取数据集并将其转换为可用的形式
train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv'))
test = pd.read_csv(os.path.join(data_dir, 'Test.csv'))
sample_submission = pd.read_csv(os.path.join(data_dir, 'Sample_Submission.csv'))
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
train_x = np.stack(temp)
train_x /= 255.0
train_x = train_x.reshape(-1, 784).astype('float32')
temp = []
for img_name in test.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'test', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
test_x = np.stack(temp)
test_x /= 255.0
test_x = test_x.reshape(-1, 784).astype('float32')
train_y = keras.utils.np_utils.to_categorical(train.label.values)- 将我们的训练数据分为训练和验证
split_size = int(train_x.shape[0]*0.7)
train_x, val_x = train_x[:split_size], train_x[split_size:]
train_y, val_y = train_y[:split_size], train_y[split_size:]- 让我们开始我们的调整吧!让我们将模型更改为“宽”,即增加隐藏层中的神经元数量
# define vars
input_num_units = 784
hidden_num_units = 500
output_num_units = 10
epochs = 5
batch_size = 128
model = Sequential([
Dense(output_dim=hidden_num_units, input_dim=input_num_units, activation='relu'),
Dense(output_dim=output_num_units, input_dim=hidden_num_units, activation='softmax'),
])- 我们来测试一下这个模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_500 = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y))m
- 我们看到这个模型的表现明显比以前好!现在,我们尝试使模型变得“深”,而不是“宽”。我们添加了四个隐藏层,每个隐藏层有 50 个神经元
#
# define vars
input_num_units = 784
hidden1_num_units = 50
hidden2_num_units = 50
hidden3_num_units = 50
hidden4_num_units = 50
hidden5_num_units = 50
output_num_units = 10
epochs = 5
batch_size = 128
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])- 对这个模型的表现有什么猜测吗?
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y)) 看来我们没有得到我们所期望的。这可能是因为我们的模型可能过度拟合。为了解决这个问题,我们使用了一种称为 dropout 的方法。Dropout 本质上是随机关闭模型的某些部分,这样它就不会“过度学习”某个概念(要了解有关 Dropout 的更多信息,请查看有关神经网络核心概念的文章)
看来我们没有得到我们所期望的。这可能是因为我们的模型可能过度拟合。为了解决这个问题,我们使用了一种称为 dropout 的方法。Dropout 本质上是随机关闭模型的某些部分,这样它就不会“过度学习”某个概念(要了解有关 Dropout 的更多信息,请查看有关神经网络核心概念的文章)
# define vars
input_num_units = 784
hidden1_num_units = 50
hidden2_num_units = 50
hidden3_num_units = 50
hidden4_num_units = 50
hidden5_num_units = 50
output_num_units = 10
epochs = 5
batch_size = 128
dropout_ratio = 0.2
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(dropout_ratio),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dropout(dropout_ratio),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dropout(dropout_ratio),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dropout(dropout_ratio),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dropout(dropout_ratio),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])- 现在让我们检查一下我们的准确性
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d_with_drop = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y))m
- 似乎有些不对劲。看来我们的模型表现得不够好。原因之一可能是我们没有充分发挥模型的潜力。将我们的训练周期增加到 50 并检查一下!
#
input_num_units = 784
hidden1_num_units = 50
hidden2_num_units = 50
hidden3_num_units = 50
hidden4_num_units = 50
hidden5_num_units = 50
output_num_units = 10
epochs = 50
batch_size = 128
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.2),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dropout(0.2),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dropout(0.2),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dropout(0.2),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dropout(0.2),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])- 嗯,我很高兴看到会发生什么。你是?
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_5d_with_drop_more_epochs = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y)) 是的!这很好。我们看到准确性有所提高。(作为一项可选任务,您可以尝试增加纪元数来训练更多)让我们尝试另一件事,我们使我们的模型既深又广!我们还实施了之前学到的所有调整。为了更快地获得结果,我们减少了训练次数。但如果您愿意,您可以自由增加它们。
是的!这很好。我们看到准确性有所提高。(作为一项可选任务,您可以尝试增加纪元数来训练更多)让我们尝试另一件事,我们使我们的模型既深又广!我们还实施了之前学到的所有调整。为了更快地获得结果,我们减少了训练次数。但如果您愿意,您可以自由增加它们。
input_num_units = 784
hidden1_num_units = 500
hidden2_num_units = 500
hidden3_num_units = 500
hidden4_num_units = 500
hidden5_num_units = 500
output_num_units = 10
epochs = 25
batch_size = 128
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.2),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),
Dropout(0.2),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),
Dropout(0.2),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),
Dropout(0.2),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),
Dropout(0.2),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])- #请原谅我的剧透,但很明显我们的模型会比之前所有的模型都要好。
- 还是让我们检查一下
m
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_deep_n_wide = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y))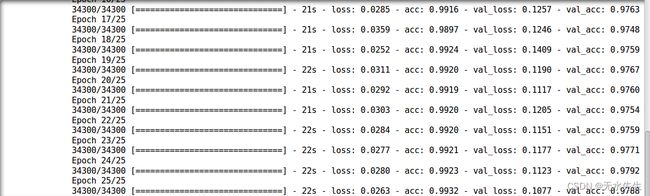
看来我们打破了所有记录!让我们将此模型提交给解决方案检查器
pred = model.predict_classes(test_x)
sample_submission.filename = test.filename; sample_submission.label = pred
sample_submission.to_csv(os.path.join(sub_dir, 'sub03.csv'), index=False)p
- 作为最后的调整,我们将尝试更改模型的类型。到目前为止,我们制作了多层感知器(MLP)。现在让我们将其更改为卷积神经网络。(要深入了解卷积神经网络 (CNN),请阅读本文)。运行 CNN 所必需的一件事是它需要以特定的格式进行排列。因此,让我们重塑数据并将其输入 CNN。
# reshape data
train_x_temp = train_x.reshape(-1, 28, 28, 1)
val_x_temp = val_x.reshape(-1, 28, 28, 1)
# define vars
input_shape = (784,)
input_reshape = (28, 28, 1)
conv_num_filters = 5
conv_filter_size = 5
pool_size = (2, 2)
hidden_num_units = 50
output_num_units = 10
epochs = 5
batch_size = 128
model = Sequential([
InputLayer(input_shape=input_reshape),
Convolution2D(25, 5, 5, activation='relu'),
MaxPooling2D(pool_size=pool_size),
Convolution2D(25, 5, 5, activation='relu'),
MaxPooling2D(pool_size=pool_size),
Convolution2D(25, 4, 4, activation='relu'),
Flatten(),
Dense(output_dim=hidden_num_units, activation='relu'),
Dense(output_dim=output_num_units, input_dim=hidden_num_units, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
trained_model_conv = model.fit(train_x_temp, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x_temp, val_y))#
这个结果让你大吃一惊,不是吗?即使训练时间如此短,表现却好得多!这证明更好的架构肯定可以提高处理神经网络时的性能。
是时候放下辅助轮了。您可以尝试很多事情,需要进行很多调整。尝试一下,让我们知道效果如何!
七、下一步该去哪里?
现在,您已经了解了 Keras 的基本概述以及实现神经网络的实践经验。您还有很多事情可以做。例如,我非常喜欢使用keras 来构建图像类比。在这个项目中,作者训练一个神经网络来理解图像,并将学习到的属性重新创建到另一个图像。如下所示,前两张图像作为输入给出,模型在第一张图像上进行训练,并在将输入作为第二张图像时给出输出作为第三张图像。

神经网络调优仍然被认为是“黑暗艺术”。因此,不要期望在第一次尝试中就能获得最好的模型。构建、评估和重申,这就是你成为更好的神经网络实践者的方法。
您应该知道的另一点是,还有其他方法可以确保您获得“足够好”的神经网络模型,而无需从头开始训练。预训练和迁移学习等技术对于了解何时实施神经网络模型来解决现实生活问题至关重要。
八、其他资源
- Keras 官方存储库
- keras 资源精选列表
- Keras 用户组