elasticSearch小记
搜索引擎一般由索引组件(比如:Lucene)和搜索组件(比如:ElasticSearch)两部分组成

文档是Lucene索引和搜索的原子单位,它是包含一个或多个域的容器,而域的值是真正被搜索的内容
在 Elasticsearch 中,术语文档 有着特定的含义。它是指最顶层或者根对象, 这个根对象被序列化成 JSON 并存储到 Elasticsearch 中,指定了唯一 ID

elastic顶层单位就叫_index(类似数据表),index里面的单条记录称为文档
document可以分组,即属于不同的_type,分组是虚拟的逻辑分组(相当于“分区”),用来过滤document
在Elasticsearch索引中,不同_type中具有相同名称的字段在内部由相同的Lucene字段支持
所以在同一个索引里,即使有不同的_type也应该有相似的结构
举例来说,_id字段不能在这个组是字符串,在另一个组是数值
_id可以自定义生成,或者让index API自动生成
***
创建操作可以使用POST,也可以使用PUT,区别在于POST 是作用在一个集合资源之上的(/uri),而PUT操作是作用在一个具体资源之上的(/uri/xxx),再通俗点说,如果URL可以在客户端确定,那么就使用PUT,如果是在服务端确定,那么就使用POST,比如说很多资源使用数据库自增主键作为标识信息,而创建的资源的标识信息到底是什么只能由服务端提供,这个时候就必须使用POST。
如果你的数据没有自然的 ID, Elasticsearch 可以帮我们自动生成 ID 。 请求的结构调整为: 不再使用PUT 谓词(“使用这个 URL 存储这个文档”), 而是使用 POST 谓词(“存储文档在这个 URL 命名空间下”)
***
在Elasticsearch中唯一标识一个文档的是,文档元数据里面的_index、_type、_id
在Elasticsearch中文档是不可改变的,不能修改它们。相反,如果想要更新现有的文档,需要重建索引或者进行替换
虽然update内部还是 检索-修改-重建索引 的处理过程,但是这个过程是发生在内部,避免了多次请求的网络开销
update 请求最简单的一种形式是接收文档的一部分作为 doc 的参数, 它只是与现有的文档进行合并。对象被合并到一起,覆盖现有的字段,增加新的字段
POST /website/blog/1/_update
{
"doc" : {
"tags" : [ "testing" ],
"views": 0
}
}***
在Elasticsearch中每个文档都有一个版本号_version。并发控制是在index、Get和delete请求时,都带一个_version(版本)号,每次对文档进行修改时(包括删除),_version的值会递增
***
elasticSearch3个重要的概念
- 映射(Mapping):描述数据在每个字段内如何存储(类似mysql的Scheme)
- 分析(Analysis):全文是如何处理使之可以被搜索的
- 领域特定查询语句(Query DSL)
Elasticsearch中的数据分为两类:精确值和全文
为了促进这类全文域的查询,Elasticsearch会首先分析文档,之后根据结果创建倒排索引(一个倒排索引由文档中所有不重复词的列表构成)。为了创建倒排索引,我们首先将每个文档的content域分成单独的词,创建一个包含所有不重复词条的排序列表,然后列出词条出现在哪些文档
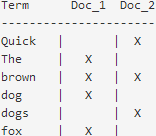
只能搜索在索引中出现的词条,所以索引文本和查询字符串必须标准化为相同格式
全文查询,理解每个域是如何定义的,因此它们可以做正确的事:
- 当你查询一个 全文 域时, 会对查询字符串应用相同的分析器,以产生正确的搜索词条列表
***
Elasticsearch中存在两种DSL:查询DSL(query DSL,领域查询语句)和过滤DSL(filter DSL)
请求正文是一个json对象,除了其他属性以外,他还要包含一个名称为"query"的属性,这就可使用ElasticSearch的查询DSL
{
"query": {
//Query DSL here
}
}GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}query context才参与打分
|
|
The |
|
|
The |
constant_score可以用来取代只有filter语句的bool查询
{
"constant_score": {
"filter": {
"term": { "category": "ebooks" }
}
}
}***
query DSL语句的形式:
- 叶子语句(Leaf clauses) (就像
match语句) 被用于将查询字符串和一个字段(或者多个字段)对比 - 复合(Compound) 语句 主要用于 合并其它查询语句。 比如,一个
bool语句 允许在你需要的时候组合其它语句,无论是must匹配、must_not匹配还是should匹配,同时它可以包含不评分的过滤器(filters)
一个查询语句 的典型结构:
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}如果是针对某个字段,那么它的结构如下:
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}***
terms查询和term查询一样,被用于精确值匹配,但terms它允许你指定多值进行匹配,如果这个字段包含了指定值的任何一个值,那么这个文档满足条件
{ "terms": { "tag": [ "search", "full_text", "nosql" ] }}The terms foo, Foo, FOO are NOT equivalent. Terms (i.e. exact values) can be searched for using term queries
如果没有must语句,那么至少需要能够匹配其中的一条should语句。但,如果存在至少一条must语句,则对should语句的匹配没有需求
对于一个多值的字段,仅仅是多个值的包装,这些值并没有固定的顺序
对于一个字段,想用于搜索(analyzed)又想用于排序(not analyzed),我们可以使用两种方式索引它
"tweet": {
"type": "string",
"analyzer": "english",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed"
}
}
}tweet主字段与之前一样:是一个analyzed全文字段,新的tweet.raw子字段是not analyzed
***
bool相当于()
must相当于and
should相当于or
***
父文档和子文档必须索引在同一个shard上。这意味着在获取、删除或更新子文档时需要提供相同的路由值
这个子文档必须位于与其祖父文档和父文档相同的shard上,索引孙子文档需要路由值routing等于祖父(谱系的较大父)
父文档和子文档本身是彼此独立并且可被单独查询的
***
cluster->node->shard
主分片和副本分片不在一个node上面