注意力机制的原理及实现(pytorch)
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052
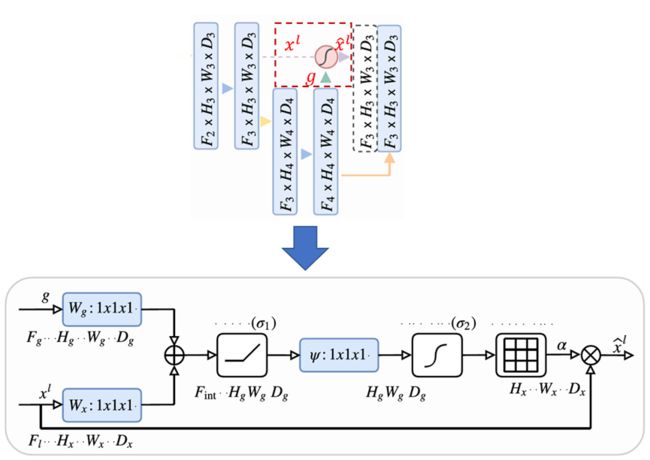
空间注意力机制(attention Unet)

class Attention_block(nn.Module):
def __init__(self, F_g, F_l, F_int):
super(Attention_block, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self, g, x):
# 下采样的gating signal 卷积
g1 = self.W_g(g)
# 上采样的 l 卷积
x1 = self.W_x(x)
# concat + relu
psi = self.relu(g1 + x1)
# channel 减为1,并Sigmoid,得到权重矩阵
psi = self.psi(psi)
print(psi.size())
# 返回加权的 x
return x * psi
Unet。
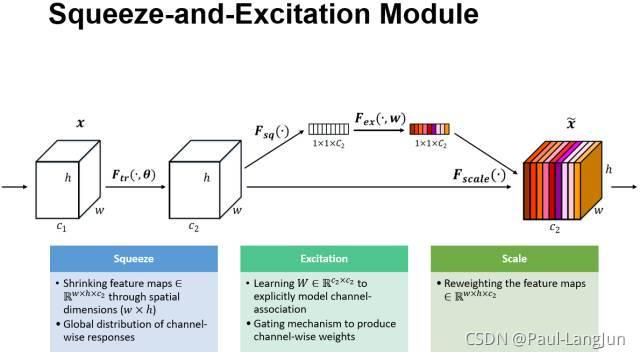
通道注意力(seNet)
from torch import nn
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
#得到输入张量的batch数量和通道数量
b, c, _, _ = x.size()
#通过平均池化,将张量的shape变为1*1
y = self.avg_pool(x).view(b, c)
#通过全连接层学习权重,得到通道上的权值
y = self.fc(y).view(b, c, 1, 1)
#将y的形状与x对齐并相乘得到最后的输出
return x * y.expand_as(x)
给定一个输入 ,其特征通道数为 ,通过一系列卷积等一般变换后得到一个特征通道数为 的特征。与传统的CNN不一样的是,接下来通过三个操作来重标定前面得到的特征。
1) Squeeze(压缩)。顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用。
2) Excitation(激发)。它是一个类似于循环神经网络中门的机制。通过参数来为每个特征通道生成权重,其中参数被学习用来显式地建模特征通道间的相关性。
3)Reweight(缩放)。将Excitation的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定
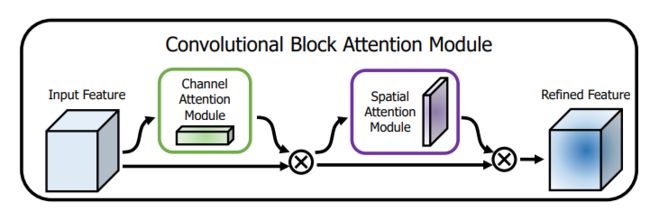
空间注意力+通道注意力(CBAM)
CBAM模块
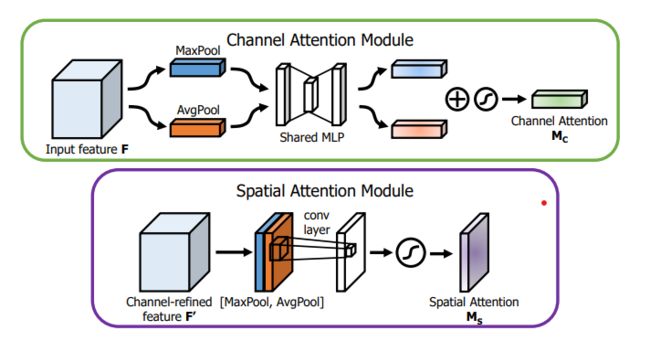
CAM模块和SAM模块
CBAM的Pytorch实现
# ------------------------#
# CBAM模块的Pytorch实现
# ------------------------#
# 通道注意力模块
class ChannelAttentionModule(nn.Module):
def __init__(self, channel, reduction=16):
super(ChannelAttentionModule, self).__init__()
mid_channel = channel // reduction
# 使用自适应池化缩减map的大小,保持通道不变
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Linear(in_features=channel, out_features=mid_channel),
nn.ReLU(),
nn.Linear(in_features=mid_channel, out_features=channel)
)
self.sigmoid = nn.Sigmoid()
# self.act=SiLU()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
maxout = self.shared_MLP(self.max_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
return self.sigmoid(avgout + maxout)
# 空间注意力模块
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
# self.act=SiLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# map尺寸不变,缩减通道
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out
# CBAM模块
class CBAM(nn.Module):
def __init__(self, channel):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(c1)
self.spatial_attention = SpatialAttentionModule()
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
ResNet中与一个ResBlock集成的CBAM的用法
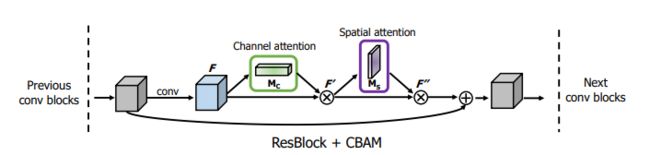
pytorch代码实现
# ------------------#
# ResBlock+CBAM
# ------------------#
import torch
import torch.nn as nn
import torchvision
class ChannelAttentionModule(nn.Module):
def __init__(self, channel, ratio=16):
super(ChannelAttentionModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Conv2d(channel, channel // ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(channel // ratio, channel, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x))
print(avgout.shape)
maxout = self.shared_MLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out
class CBAM(nn.Module):
def __init__(self, channel):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(channel)
self.spatial_attention = SpatialAttentionModule()
def forward(self, x):
out = self.channel_attention(x) * x
print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return out
class ResBlock_CBAM(nn.Module):
def __init__(self,in_places, places, stride=1,downsampling=False, expansion = 4):
super(ResBlock_CBAM,self).__init__()
self.expansion = expansion
self.downsampling = downsampling
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels=in_places,out_channels=places,kernel_size=1,stride=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=places, out_channels=places, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=places, out_channels=places*self.expansion, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(places*self.expansion),
)
self.cbam = CBAM(channel=places*self.expansion)
if self.downsampling:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels=in_places, out_channels=places*self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(places*self.expansion)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
out = self.bottleneck(x)
print(x.shape)
out = self.cbam(out)
if self.downsampling:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
model = ResBlock_CBAM(in_places=16, places=4)
print(model)
input = torch.randn(2, 16, 64, 64)
out = model(input)
print(out.shape)
自注意力机制(self-attention)
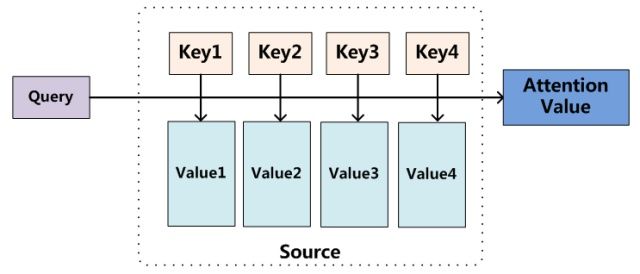
# Muti-head Attention 机制的实现
from math import sqrt
import torch
import torch.nn
class Self_Attention(nn.Module):
# input : batch_size * seq_len * input_dim
# q : batch_size * input_dim * dim_k
# k : batch_size * input_dim * dim_k
# v : batch_size * input_dim * dim_v
def __init__(self,input_dim,dim_k,dim_v):
super(Self_Attention,self).__init__()
self.q = nn.Linear(input_dim,dim_k)
self.k = nn.Linear(input_dim,dim_k)
self.v = nn.Linear(input_dim,dim_v)
self._norm_fact = 1 / sqrt(dim_k)
def forward(self,x):
Q = self.q(x) # Q: batch_size * seq_len * dim_k
K = self.k(x) # K: batch_size * seq_len * dim_k
V = self.v(x) # V: batch_size * seq_len * dim_v
atten = nn.Softmax(dim=-1)(torch.bmm(Q,K.permute(0,2,1))) * self._norm_fact # Q * K.T() # batch_size * seq_len * seq_len
output = torch.bmm(atten,V) # Q * K.T() * V # batch_size * seq_len * dim_v
return outputvison transformer实现
input:[2,3,256,256]
划分小patch:patch_szie:32*32,num_patches=(256//32)**2
n,c,w,h --> n,w*h//(32*32), 32*32*c
linear: n,w*h//(32*32), 32*32*c -->n,w*h//(32*32), 32*32
position_embeding
class_token
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# helpers
#返回一个tuple,宽高信息
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# classes
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
测试脚本
import torch
from vit_pytorch import ViT
import numpy as np
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(2, 3, 256, 256)
preds = v(img) # (1, 1000)
print(preds.shape)
print(np.argmax(preds.detach().numpy(), 1))空间注意力
https://blog.csdn.net/weixin_37737254/article/details/125863392
代码 https://github.com/Andy-zhujunwen/UNET-ZOO/blob/master/attention_unet.py
通道注意力
https://blog.csdn.net/gaoxueyi551/article/details/120233959
代码 https://github.com/moskomule/senet.pytorch/blob/master/senet/se_module.py
空间注意力加通道注意力(CBAM):
https://blog.csdn.net/weixin_41790863/article/details/123413303
论文: https://arxiv.org/pdf/1807.06521.pdf
自注意力机制(vision transformer)
论文: https://arxiv.org/pdf/2010.11929.pdf
参考博客:
https://blog.csdn.net/weixin_42392454/article/details/122667271
https://zhuanlan.zhihu.com/p/410776234