【论文笔记】EMBEDDING ENTITIES AND RELATIONS FOR LEARN-ING AND INFERENCE IN KNOWLEDGE BASES
摘要
提出了一个准确率更高的双线性公式,一个利用学习到的关系嵌入来挖掘逻辑规则的方法。
背景
在可扩展到大型知识库的关系学习方法上有张量因子分解和基于神经嵌入的模型两种流行的方法。它们学习使用实体与关系的低维来表示编码关系。
本文重点研究了基于能量目标的神经嵌入模型。最近的嵌入模型TransE比RESCAL等张量因子分解方法预测性能更好。
本文贡献:
(1)提出了一个通用的多关系学习框架,该框架统一了过去开发的大多数多关系嵌入模型,包括NTN (Socher et al., 2013)和TransE (Bordes et al., 2013b)。
(2)经验评估了不同的选择和关系表示实体表示在这个框架规范的链接预测任务,并显示一个简单的双线性公式可以实现任务目前最先进的结果
(3)提出并评估了一种利用学习到的嵌入挖掘逻辑规则的新方法
相关研究
传统的统计学习方法如马尔可夫逻辑网络,通常存在可伸缩性的问题。
最近,各种类型的表示学习方法被提出,将多关系知识嵌入实体和关系的低维表示中,包括张量/矩阵分解(Singh & Gordon, 2008;Nickel et al.,2011;2012),贝叶斯聚类框架(Kemp et al., 2006;Sutskever et al.,2009年)和神经网络(Paccanaro & Hinton, 2001;Bordes et al., 2013;Socher et al.,2013)。
现有的神经嵌入模型都将实体表示为低维向量,并将关系表示为结合两个实体表示的算子。它们的不同之处在于关系算子参数化的不同。
同样,实体表示的变体也存在。大多数方法将每个实体表示为一个单位向量,而NTN将实体表示为单词向量的平均值,并使用外部文本语料库中预训练的向量初始化单词向量。
多关系表示学习
实体表示
第一层将输入实体投影到低维向量。
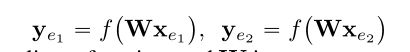 xe1, xe2表示实体e1,e2的输入向量,可以是one-hot表示,或者是实体中单词表示的平均值(NTN 模型)。W表示第一层投影矩阵,可以是随机化的参数矩阵,也可以是预训练的参数矩阵。ye1, ye2表示e1,e2的投影。f可以是线性或非线性函数。
xe1, xe2表示实体e1,e2的输入向量,可以是one-hot表示,或者是实体中单词表示的平均值(NTN 模型)。W表示第一层投影矩阵,可以是随机化的参数矩阵,也可以是预训练的参数矩阵。ye1, ye2表示e1,e2的投影。f可以是线性或非线性函数。
关系表示
关系表示的选择以评分函数的形式反映出来。现有的评分函数可以归结为线性、双线性或它们的组合。线性就是参数矩阵乘以ye1, ye2组成的列矩阵。双线性就是ye1T乘以参数矩阵乘以ye2。
 NTN是提取特征能力最强的模型,因为它同时包含线性和双线性关系运算。就参数数量而言,TransE是最简单的模型,它只对一维向量的线性关系算子进行参数化。
NTN是提取特征能力最强的模型,因为它同时包含线性和双线性关系运算。就参数数量而言,TransE是最简单的模型,它只对一维向量的线性关系算子进行参数化。
本文考虑双线性模型。参数矩阵选择Mr, Mr是一个二维对角矩阵。这样可以将双线性模型的参数量减少到与 TransE 相同。
参数学习
上述所有模型的神经网络参数都可以通过最小化margin-based ranking objective学习。训练目标是最小化margin-based ranking loss。
 三元组的评分函数表示为S(e1,r,e2), T’是通过破坏关系参数中的任意一个得到的负三元组。
三元组的评分函数表示为S(e1,r,e2), T’是通过破坏关系参数中的任意一个得到的负三元组。
实验
链接预测
该任务是预测不可见三元组的正确性。
将链接预测作为一项实体排名任务。对于测试数据中的每个三元组,依次将每个实体视为要预测的目标实体。计算字典中正确实体和所有损坏实体的分数,并按降序排列。用平均倒数排名(MRR),HITS@10(前10名精度)和平均精度(MAP)作为评估指标。
使用AdaGrad的小批量随机梯度下降法进行训练。在每个梯度步骤中,我们为每个正三元组取样两个负三元组,其中一个带有损坏的 主体实体,另一个带有损坏的对象。在每个梯度步骤之后,实体向量被重新规范化为具有单位长度。
对于关系参数,我们使用L2标准正则化。对于所有模型,我们将小批量的数量设置为10,实体向量的维度d=100,正则化参数为0.0001,以及FB15k和FB15k-401上训练次数T=100,在WN上的训练次数T=300(T是根据所有模型性能稳定的学习曲线确定的),学习率最初设定为0.1,然后由AdaGrad在训练期间进行调整。
结果:
 数据显示,在FB上,性能随着模型复杂度的降低而增加。最复杂的模型NTN在FB和WN上的性能都最差,这表明拟合过度。与之前公布的TransE结果相比,使用相同的评估指标,我们的算法取得了更好的结果,我们将这种差异主要归因于SGD优化的不同选择:AdaGrad与恒定学习率。我们还发现,与TransE相比,双线性系统的性能一直相当或更好,尤其是在WN上。我们发现一个简单的双线性变体——bilinear-diag双线性诊断,在FB上明显优于所有基线,在WN上实现了与双线性相当的性能。请注意,双线性诊断在编码关系及其逆之间的差异方面有局限性。尽管如此,由于FB中存在多种关系,且每个关系所看到的平均训练示例数相对较少(与WN相比),因此简单形式的bilinear-diag能够提供良好的预测性能。
数据显示,在FB上,性能随着模型复杂度的降低而增加。最复杂的模型NTN在FB和WN上的性能都最差,这表明拟合过度。与之前公布的TransE结果相比,使用相同的评估指标,我们的算法取得了更好的结果,我们将这种差异主要归因于SGD优化的不同选择:AdaGrad与恒定学习率。我们还发现,与TransE相比,双线性系统的性能一直相当或更好,尤其是在WN上。我们发现一个简单的双线性变体——bilinear-diag双线性诊断,在FB上明显优于所有基线,在WN上实现了与双线性相当的性能。请注意,双线性诊断在编码关系及其逆之间的差异方面有局限性。尽管如此,由于FB中存在多种关系,且每个关系所看到的平均训练示例数相对较少(与WN相比),因此简单形式的bilinear-diag能够提供良好的预测性能。

bilinear-diag在几乎所有类别里都优于TransE。

还研究了实体表示的学习,并介绍了两个进一步的改进:使用非线性投影和使用预训练向量初始化实体向量。 考虑预训练的向量对结果的影响,发现实体级的预训练向量有利于提升实验的性能,但是单词级的预训练向量往往起到不好的作用,原因是和数据集有较大关系,在FB15k-401数据集中,73%的实体是姓名、地点、机构和电影名等等,因此我们怀疑这是因为单词向量不适合非组合短语描述的实体建模。
规则提取(这个部分没太读懂,有待后续学习)
重点介绍一个互补推理任务,在该任务中,我们利用所学的嵌入从知识库中提取逻辑规则。介绍一种新的基于嵌入的规则挖掘方法,其效率不受知识库图的大小影响,而是受知识库中不同类型关系的数量(通常相对较小)的影响。
本文提出基于embedding的方法和知识图谱的规模无关,和关系的数量有关,因此具有更广泛的意义。
通常实体有自己的类型,一个关系适用的实体通常只是部分实体类型,因此可以使用实体类型作为约束条件来减少搜索空间。

在长度为2的规则提取方面,EmbedRule(DISTMULT)的表现好于其他算法。在长度为3的规则提取方面,由EmbeddeRule提取的初始长度为3的规则通常可以提供很好的精度。我们还可以看到,在前1K预测中,双线性始终优于DISTMULT和DISTADD,并且随着生成更多预测,DISTMULT-TANH-EV-INIT往往优于其他方法。我们认为,在提取更长的规则方面,双线性开始显示出比DISTMULT更大的优势,这一事实证实了用对角矩阵表示关系的局限性,因为更长的规则需要对更复杂的关系语义进行建模。