爬虫学习(零散记录)
HTTP基本原理
URL是URI的子集,但是因为URN现在不怎么用了,可以认为URI和URL是一样的了

URL组成
schema同protocol,都是协议的意思
username和password可以尝试一下https://ssr3.scrape.center和https://admin:[email protected]
port除了80(http)和443(https)两个默认端口会忽视外,其他的都要加,其实http://www.baidu.com就是http://www.baidu.com:80

浏览器中分析网络请求





HTTP2.0相比于HTTP1.1的优化
- 二进制分帧层 反正里面涉及到把一些文本数据改成二进制了
- 多路复用
- 流控制
- 服务端推送
requests库只支持HTTP1.1
无状态HTTP

Session维持

Cookie属性

代理





网络爬虫是IO密集型场景

Python中的多进程和多线程

urllib
demo链接
—高级用法—
即自定义handler,他们分别用来处理cookie、设置代理、设置登录密码、认证之类的东西,下面这个是设置代理的,其他的自己去查
—处理异常—
有个URLError类和HTTPError类
—解析链接—
由API如urlparse解析url的各个部分,urlunparse拼成url,urlsplit、urljoin、urlencode、parse_qs、url_qsl、quote等等
—robots协议—
主要就是三种key:User-Agent、Disallow、Allow,就是禁止或允许这个UserAgent(其实就是爬虫名)的访问
然后有RobotFileParser可以解析robot.txt文件




requests学习
demo链接
requests.get()的返回值可以用.json、.text、.content等获得json、文本、二进制数据
requests有个 headers、data、files、timeout
request.codes.not_found是404,除此之外还有其他的可以使用
—获取cookie—
–设置cookie—
—session维持—
因为两次使用requests…相当于开了两个浏览器,Session就不同了,如果要携带相同Cookie会很繁琐,可以维护一个Session对象。这个用在模拟登录成功后进行
—解决SSL证书错误—
—通过网站开启的身份认证—
—代理设置—







正则表达式
demo地址
—语法—
—match—
—匹配目标—
—通用匹配—
—贪婪与非贪婪—
—修饰符—
—转义匹配—
—search—
match是从头开始匹配,search可以从中间开始匹配
好像是有推荐使用search而不是match
search只获得一个,findall就是获得全部的
—sub去除字符串,compile把正则字符串转化为可复用的对象—

httpx的使用
httpx的demo
httpx支持HTTP2.0,前面两个都不支持
同时httpx几乎支持所有requests能做到的事
下面这个就是支持了http2.0的
对于使用了HTTP2.0的就不能使用requests了
安装
pip3 install httpx[http2]
—手动声明支持—
—支持异步请求—





多进程加速案例

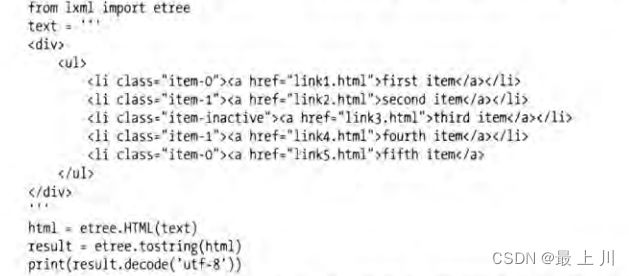
XPath
XPath的demo链接
匹配规则
读取html
使用html.xpath(‘’)获取对应结点


靓汤
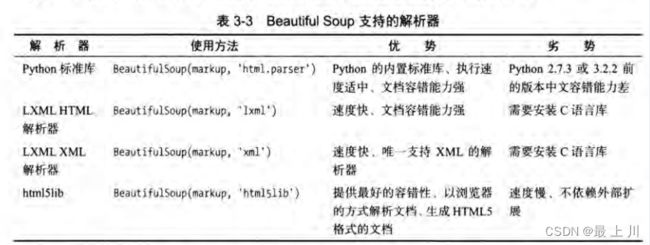
这个用的多,就懒得写了
PyQuery
可以进行remove操作
数据的存取
text、json、csv、mysql、mongodb、redis、es、rabbitmq
AJAX请求
在开发者工具内的网络内的Type为xhr的就是Ajax请求
请求头中X-Rquested-With:XMLHttpRequest的就是Ajax请求
以下demo仅用于记录占位符的用法的
import httpx
baseUrl="https://spa1.scrape.center/api/movie/?limit={limit}&offset={offset}"
def scrape_index(page):
url = baseUrl.format(limit=10,offset=10*(page-1))
return httpx.get(url).json()
if __name__ == '__main__':
print(scrape_index(1))
协程
协程demo


import asyncio
async def execute(x):
print('Number:', x)
if __name__ == '__main__':
# 不马上执行,而是返回一个协程对象
coroutine = execute(1)
print('Coroutine:', coroutine)
print('After calling execute')
# 创建loop
loop = asyncio.get_event_loop()
# 效果同,其实传入协程后还是会包装成task
#task = loop.create_task(coroutine)
#loop.run_until_complete(task)
# 绑定协程
loop.run_until_complete(coroutine)
print('After calling loop')
也可以不使用loop来获得task
task = asyncio.ensure_future(coroutine)
绑定回调函数demo
import asyncio
import httpx
async def request():
url = 'https://www.baidu.com'
status = httpx.get(url)
return status
def callback(task):
print('Status:', task.result())
if __name__ == '__main__':
coroutine = request()
task = asyncio.ensure_future(coroutine)
# 注册回调事件
task.add_done_callback(callback)
print('Task:', task)
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:', task)
task运行完毕之后也可以用
task.result获取结果
多任务协程
注意面对爬虫这种IO密集型时,用协程时要有挂起操作,不然和串行无异。await就是挂起耗时等待的操作,让出控制权给其他协程。同时请求方式也要使用异步请求,所以要用到
aiohttp
demo如下
import asyncio
import aiohttp
import time
start = time.time()
async def get(url):
session = aiohttp.ClientSession()
response = await session.get(url)
await response.text()
await session.close()
return response
async def request():
url = 'https://www.httpbin.org/delay/5'
print('Waiting for', url)
response = await get(url)
print('Get response from', url, 'response',response)
if __name__ == '__main__':
tasks = [asyncio.ensure_future(request()) for _ in range(100)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print('Cost time:', end - start)

aiohttp
demo
import asyncio
import aiohttp
async def fetch(session,url):
async with session.get(url) as resp:
return await resp.text(),resp.status
async def func():
async with aiohttp.ClientSession() as session:
html,status = await fetch(session=session,url="https://cuiqingcai.com")
print(f'html:{html[:100]}...')
print(f'status:{status}')
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(func())
# python>=3.7后可以用如下语法
# asyncio.run(func())
—传参—
async with session.get(url=url,params=params) as resp:
async with session.post(url=url,data=params) as resp:
async with session.post(url=url,json=params) as resp:
如果返回的是协程,则字段前要加
await,否则不需要
—超时设置—
timeout = aiohttp.ClientTimeout(total=1)
async with aiohttp.ClientSession(timeout=timeout) as session:
—并发限制—

Selenium
用find_element实现查找
用send_keys输入文字,用clear清空文字,用click点击按钮
动作链

excute_script('alert('qwer')')运行js
.attribute(src')获得src属性
隐式等待:设置implicitly_wait 但是时间是固定的,不太好
显式等待:
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))

前进和后退:调用forward()和back()
操作cookie:get_cookie()、add_cookie()等
选项卡切换:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://python.org')
反屏蔽
因为有些网站会检测浏览器当前窗口下的window.navigator对象中是否包含webdriver属性,因为没用爬虫时那里会是undefined。但是selenium调用脚本删除该属性会是在渲染完毕后才进行,太晚了,所以我们要用一个CDP解决该问题,让页面刚加载时就执行js语句
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=option)
# 让页面刚加载时就执行js语句
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
browser.get('https://antispider1.scrape.cuiqingcai.com/')
无头模式:不弹出窗口。须在配置对象中设置
Splash
一个js渲染服务,一个有httpapi的轻量浏览器

Pyppeteer
似乎是比selenium好用

demo
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
# 启动浏览器
browser = await launch(headless=False,userDataDir='./userdatda')
# 新建一个网页选项卡对象
page = await browser.newPage()
# 访问网站
await page.goto('https://spa2.scrape.center/')
# 一直等到页面上该属性对应的标签加载出来
await page.waitForSelector('.item .name')
doc = pq(await page.content())
names = [item.text() for item in doc('.item .name').items()]
print('Names:', names)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
参数设置:有无头、浏览器窗口大小、用户目录(存储cookie等信息)
还有一些选项卡操作、点击、输入、执行JS等都有API,自己去查
playwright
支持多种浏览器、同步异步、可视化生成代码、截获Ajax、劫持request、response
点击输入获取结点啥的就不用说了
Tesserocr 识别图形验证码
OpenCV识别滑动验证码缺口
深度学习识别图形验证码和滑动验证码
各包的使用代理
代理池
demo
模拟登录
基于session和cookie
- 可以登录自己的账号,直接在浏览器里把Cookie复制下来
- 也可以用POST请求直接登录,但是因为有些网站可能还会附带一些校验参数,而且还要分析怎么设置cookie,有些麻烦
- 用selenium等驱动浏览器模拟登录操作
反正核心就是维护好客户端的cookie,在每次请求时都携带Cookie
基于JWT模拟登录
维护token,如果过期了要重新获取
用账号池实现多账号随机爬取
维护一个账号池,每次随机使用一个来访问。避免了单账号并发量过大导致封号
JS逆向爬虫
对于接口中添加了加密参数的,我们不仅可以用selenium等模拟浏览器操作,还可以使用逆向技术分析JS代码,找到加密逻辑,从而破解该接口。这样就不需要渲染整个前端界面,爬取效率会大大提高
JS加密措施
- URL/API参数加密
- JS压缩、混淆加密


AJAX端断点调试
AST 技术解决代码可读性问题
Scapy!!!
初次使用的demo链接
可以在Spider中重写start_requests方法,自定义请求和回调方法。自定义请求可以设置请求头、cookie之类的东西

post请求设置表单提交和json

关于Request类和Response类可以再去查一下
Downloader Middleware
然后下面这个中间件也是自己去查,而且这个很重要




Spider Middleware

Extension

对接selenium或splash或Pyppeteer
规则化爬虫
如果要爬新闻,但是要爬多个网站,那么item是一样的,但是Spider不一样
所以可以把爬取逻辑作为配置文件内容,单独管理和维护这些规则

分布式爬虫
雏形:多个调度器Scheduler共享一个爬取队列
维护队列:选用redis的多种数据结构可以构建不同特性的队列
去重:Scrapy内置哈希值去重,但是分布式时这个去重的方式应该放到共享队列里而不是各个结点,所以用redis的set
断点重连:在中断后把队列的数据持久化,下次爬取就直接读取这个队列数据,Scrapy可以指定存储路径
基于redis
Scrapy-Redis已经有人实现了
基于RabbitMQ
爬虫的管理和部署
基于Scrapyd(d是deploy)
基于Gerapy
![]()
基于K8s
把Scrapy打包成Docker容器,并迁移到K8S进行管理和维护