【腾讯云云上实验室-向量数据库】探索腾讯云向量数据库:全方位管理与高效利用多维向量数据的引领者
目录
- 前言
- 1 腾讯云向量数据库介绍
- 2 向量数据库信息及设置
-
- 2.1 向量数据库实例信息
- 2.2 实例监控
- 2.3 密钥管理
- 2.4 安全组
- 2.5 Embedding
- 2.6 可视化界面
- 3 可视化界面
- 4 Embedding
-
- 4.1 embedding_coll精确查询
- 4.2 unenabled_embedding_coll精确查询
- 5 数据库
-
- 5.1 创建数据库
- 5.2 插入数据
- 5.3 精确检索
- 6 应用场景
-
- 6.1 大模型知识库
- 6.2 推荐系统
- 6.3 问答系统
- 6.4 文本/图像检索
- 7 总结
前言
腾讯云向量数据库(Tencent Cloud VectorDB)是一款专为存储、检索和分析多维向量数据而设计的全托管式企业级分布式数据库服务。其独特之处在于支持多种索引类型和相似度计算方法,拥有卓越的性能优势,包括高QPS(每秒查询率)、毫秒级查询延迟,以及单索引支持数亿级向量数据规模。通过简单易用的可视化界面,用户可以快速创建数据库实例,进行数据操作,执行查询操作,并配置嵌入式数据转换,提供更广泛的数据处理能力。该数据库适用于多种场景,如构建大型知识库、推荐系统、智能问答系统以及文本/图像检索任务,为企业提供了强大的工具,助力各种应用场景下的高效数据管理和智能应用实现。
1 腾讯云向量数据库介绍
腾讯云向量数据库专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持干亿级向量规模,可支持五百万OPS及毫秒级查询延迟。腾讯云向量数据库,助您实现智能数据的快速、高效管理与应用。
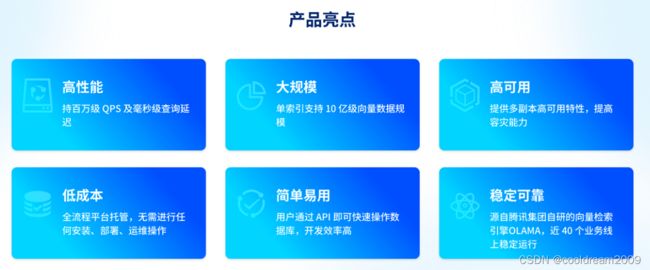
腾讯云向量数据库具备以下几大亮点:
高性能:持百万级 QPS 及毫秒级查询延迟
大规模:单索引支持 10 亿级向量数据规模
高可用:提供多副本高可用特性,提高容灾能力
低成本:全流程平台托管,无需进行任何安装、部署、运维操作
简单易用:用户通过 API 即可快速操作数据库,开发效率高
稳定可靠:源自腾讯集团自研的向量检索引擎 OLAMA,近 40 个业务线上稳定运行。
2 向量数据库信息及设置
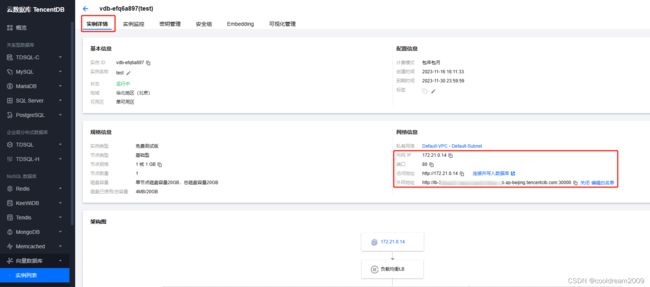
2.1 向量数据库实例信息
显示有关数据库实例的关键详细信息,例如实例 ID、地域、容量、配置等。
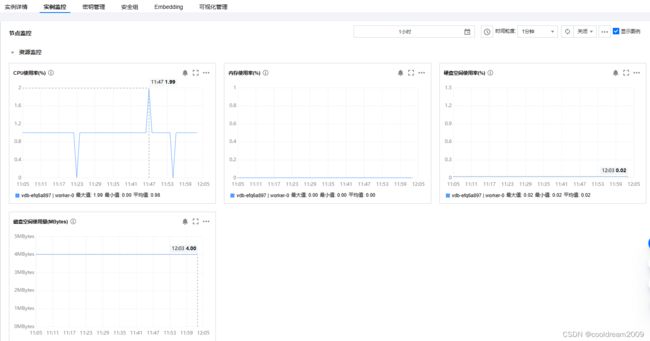
2.2 实例监控
实时或历史性能指标和监控功能,允许用户跟踪数据库使用情况、性能以及资源利用情况。
2.3 密钥管理
管理访问密钥、身份验证令牌或加密密钥,以保护数据库实例并控制访问权限。

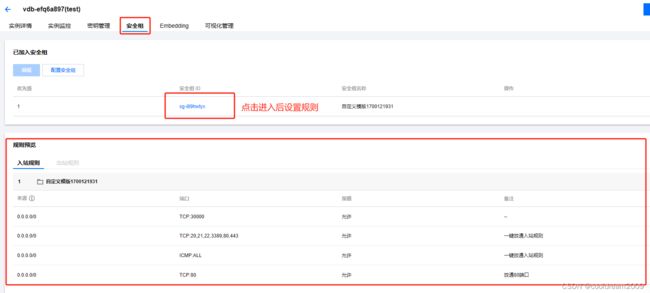
2.4 安全组
定义和管理安全规则和配置,包括网络访问控制列表(ACL)或防火墙设置,以保护数据库实例。
2.5 Embedding
与嵌入式数据相关的配置,可能包括将非结构化数据转换为向量格式的设置,并在数据库中管理这些嵌入式数据。
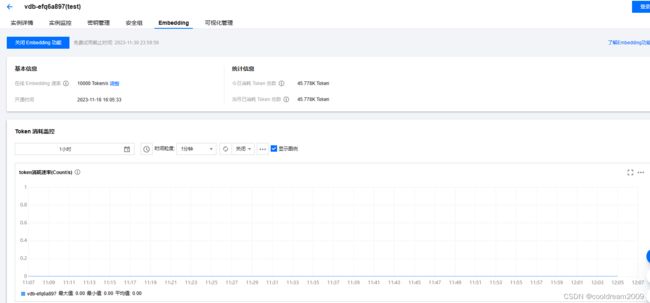
2.6 可视化界面
以图形方式呈现数据库实例的整体状态、统计信息或其他数据,以用户友好的方式展示信息,便于快速理解和决策。
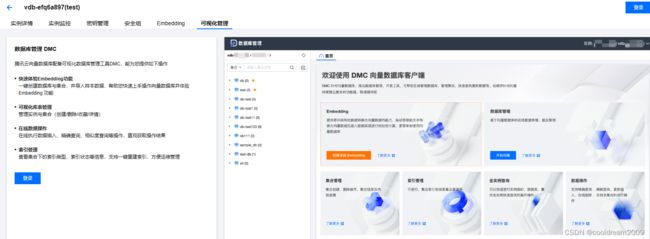
3 可视化界面
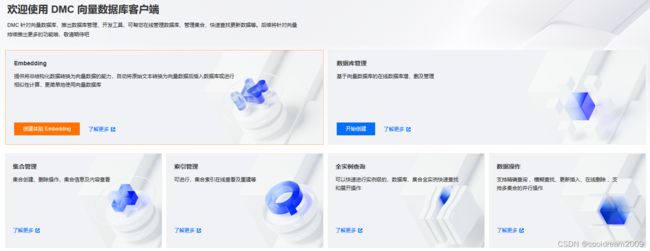
Embedding提供了将非结构化数据转换为向量数据的功能,自动将原始文本转换为向量数据并插入数据库,或者执行相似性计算,使向量数据库的使用更加简单便捷。
数据库管理方面基于向量数据库可进行在线的数据库增加、删除和管理。
集合管理涵盖了集合的创建、删除操作,以及查看集合信息和内容。
索引管理方面可进行集合索引在线查看及重建等操作。
全实例查询能够快速进行实例级的数据库和集合全实例查找和展开操作。
在数据操作方面,支持精确查询、模糊查找、更新插入、在线删除,并且支持多集合的并行操作。
这些功能集合为用户提供了更灵活、高效地管理和操作向量数据库的能力。
4 Embedding
提供将非结构化数据转换为向量数据的能力,自动将原始文本转换为向量数据后插入数据库或进行相似性计算,更简单地使用向量数据库
4.1 embedding_coll精确查询
在进行embedding_coll的精确查询时,使用JSON数据进行查询,可能包括按照特定的条件或字段,对数据库中存储的向量数据进行准确的检索。这种查询方式可以帮助用户快速找到所需的向量数据或相关信息,提供了高效、精确的搜索功能。
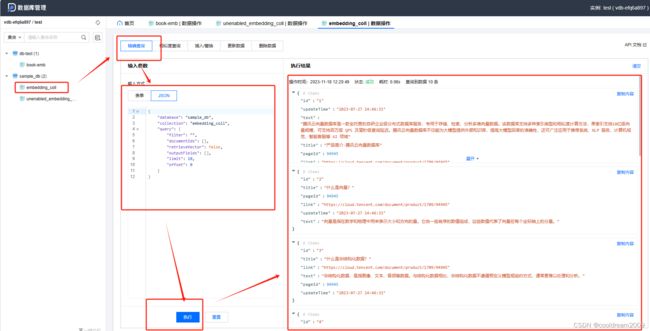
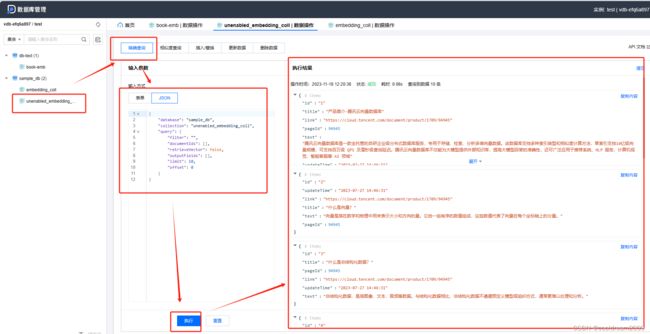
4.2 unenabled_embedding_coll精确查询
在unenabled_embedding_coll精确查询中,同样使用JSON数据对数据进行查询。这个查询操作可能是在某些特定条件下执行的,与enabled_embedding_coll相比,可能有些功能或特性处于未启用状态。这种查询可能针对某些特定集合或数据,提供了对数据库中信息的更多探索或筛选功能,使用户能够更全面地利用数据库资源。
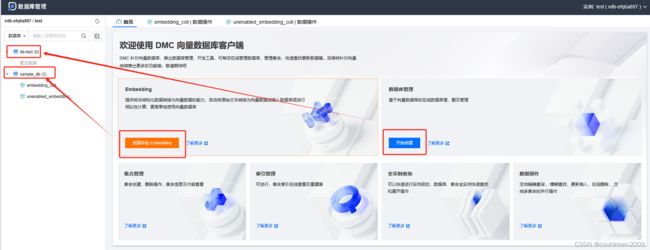
5 数据库
(如图中所示)。此外,(如图中的数据插入界面展示了这一点)。
5.1 创建数据库
基于向量数据库的在线增加、删除和管理数据库是腾讯云向量数据库的关键功能之一。通过可视化界面,用户可以轻松地创建新的数据库实例。
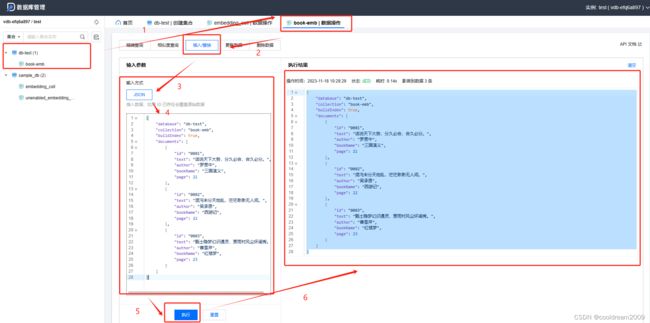
5.2 插入数据
向量数据库允许用户通过JSON数据将信息插入数据库,这提供了一种灵活且可扩展的方法,使用户能够将各种数据以向量形式存储在数据库中
5.3 精确检索
在进行数据检索时,向量数据库提供了多种方式。用户可以通过表单形式输入搜索条件,也可以通过JSON数据进行检索
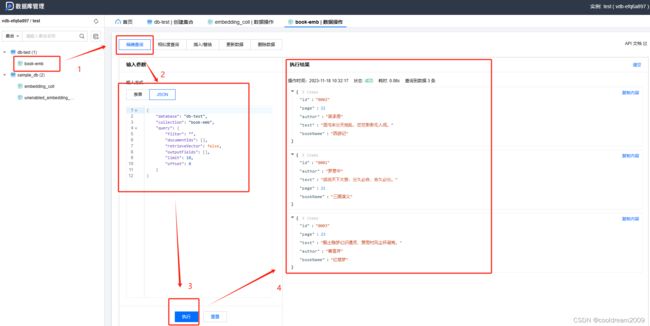
这种多样性的检索方式可以让用户根据不同的需求和偏好选择最适合的查询方法,无论是简单的数据查询还是更复杂的搜索需求。这种灵活性有助于用户更有效地管理数据库,以及更方便地访问和利用所存储的向量数据。
6 应用场景
6.1 大模型知识库
腾讯云向量数据库与大语言模型LLM协同使用。将企业私域数据经过文本分割和向量化后存储在向量数据库中,形成企业专属的外部知识库。这为大模型提供了提示信息,在后续检索任务中辅助生成更准确的答案。
6.2 推荐系统
推荐系统根据用户历史行为和偏好向用户推荐可能感兴趣的物品。在这种情况下,用户行为特征向量化存储在向量数据库中。系统根据用户特征进行相似度计算,并返回可能感兴趣的物品作为推荐结果。
6.3 问答系统
智能问答系统能够回答用户提出的问题,通常使用NLP服务和深度学习等技术实现。问题和答案通常被转换为向量表示,并存储在向量数据库中。问答系统可通过计算向量之间的相似度,检索最相关的问题信息并返回答案。向量数据库存储和检索相关的向量数据,提高问答系统的检索效率和准确性。
6.4 文本/图像检索
文本/图像检索任务在大规模文本/图像数据库中搜索与指定图像最相似的结果。存储在向量数据库中的文本/图像特征通过高性能索引实现高效的相似度计算,返回匹配的文本/图像结果。
7 总结
腾讯云向量数据库是一全托管的企业级分布式数据库服务,专注于多维向量数据的存储、检索和分析。该数据库支持多种索引类型和相似度计算方法,拥有高性能、大规模、高可用、低成本、简单易用等特点。通过其可视化界面,用户可以轻松管理实例信息、监控性能、进行密钥管理、设置安全组,以及使用Embedding功能将非结构化数据转换为向量数据并插入数据库。
应用场景广泛,包括构建大型知识库、推荐系统、智能问答系统以及文本/图像检索等。例如,与大语言模型配合使用可构建企业专属的知识库,推荐系统可基于用户特征向量化进行相似度计算,问答系统通过向量存储和检索提高响应速度和准确性,文本/图像检索任务可以高效搜索相似内容。腾讯云向量数据库为企业提供了强大的工具,助力各种应用场景下的高效数据管理和智能应用实现。