Scrapy使用GitHub上的ProxyPool代理池
目录
一、ProxyPoo
1.下载ProxyPoo
2.安装依赖
二、Redis
1.下载Redis
2.启动Redis【设置后台启动】
三,配置ProxyPool
1.setting.py
四、启动测试
1. 启动
2.测试
四、结合Scrapy,配置Scrapy
1,middlewares.py
2,settings.py
3,运行结果
五,参考博客
六,补充
一、ProxyPoo
1.下载ProxyPoo
下载地址:GitHub - jhao104/proxy_pool at release-2.4.0
 |
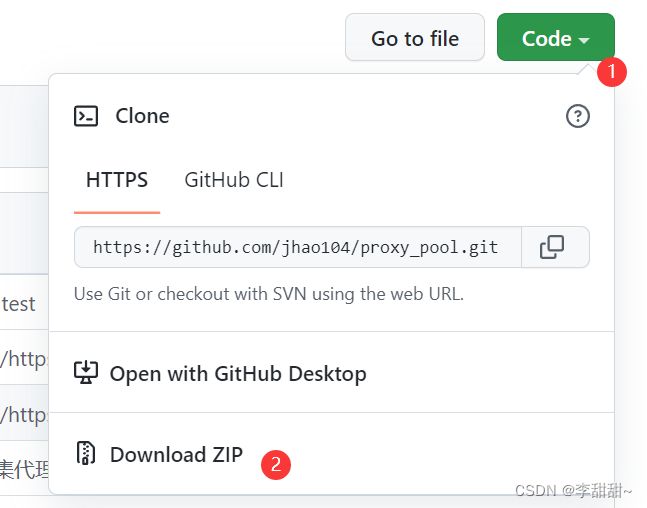 |
||
2.安装依赖
pip install -r requirements.txt二、Redis
1.下载Redis
Github下载地址: Releases · microsoftarchive/redis · GitHub
2.启动Redis【设置后台启动】
1,在redis根目录cmd,启动redis
redis-server.exe redis.windows.conf2,再次redis根目录cmd, 安装redis到 windows服务
redis-server --service-install redis.windows.conf3,再次启动redis服务, 需要先把第一步cmd窗口关闭, 再重新打开一个cmd窗口输入:
redis-server --service-start启动完以后, 直接关闭cmd窗口即可
4,检查状态
redis-cli.exe -h 127.0.0.1 -p 63795,PS:如需停止redis服务
redis-server --service-stop之后启动只需执行第三步即可
三,配置ProxyPool
1.setting.py
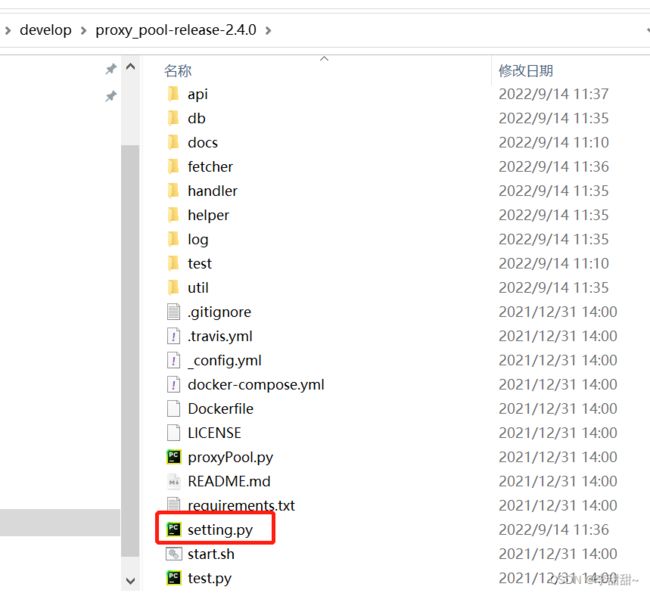

四、启动测试
1. 启动
#启动调度程序 python proxyPool.py schedule
#启动webApi服务 python proxyPool.py server

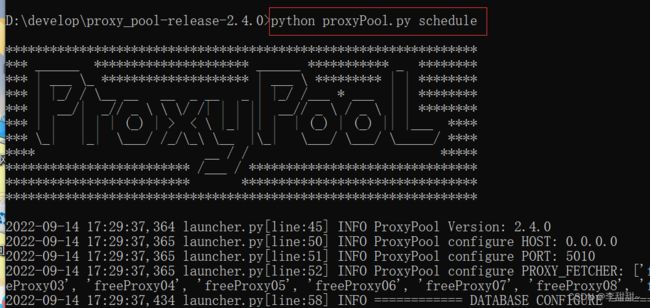
如果报错:ImportError: cannot import name ‘Markup’ from ‘jinja2’ Error
pip install Flask==2.0.3
pip install Jinja2==3.1.12.测试
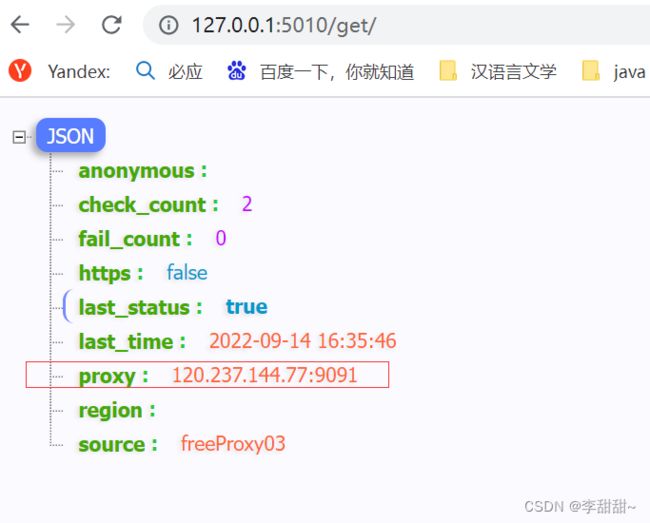
浏览器输入127.0.0.1:5010/get/可以随机获得一条代理
四、结合Scrapy,配置Scrapy
1,middlewares.py
import json
import logging
import requests
from scrapy import signals
# 代理池接口
PROXY_URL = 'http://127.0.0.1:5010/get'
class ProxyMiddleware(object):
# 初始化
def __init__(self, proxy_url):
self.logger = logging.getLogger(__name__)
self.proxy_url = proxy_url
# 获取随机代理IP
def get_random_proxy(self):
try:
response = requests.get(self.proxy_url)
if response.status_code == 200:
global proxy
p = json.loads(response.text)
proxy = "http://" + "{}".format(p.get('proxy'))
ip = {"http": proxy, "https": proxy}
r = requests.get("http://www.baidu.com", proxies=ip, timeout=60)
if str(r.status_code) == 200:
return proxy
except:
print('get proxy again ...')
return self.get_random_proxy()
def process_request(self, request, spider):
proxy = self.get_random_proxy()
if proxy:
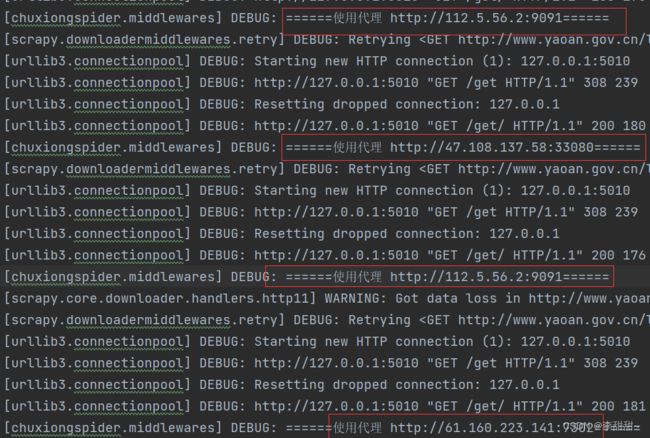
self.logger.debug('======' + '使用代理 ' + str(proxy) + "======")
request.meta['proxy'] = proxy
def process_response(self, request, response, spider):
if response.status != 200:
request.meta['proxy'] = proxy
return request
return response
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
return cls(
proxy_url=settings.get('PROXY_URL')
)
2,settings.py
PROXY_URL = 'http://127.0.0.1:5010/get'
DOWNLOADER_MIDDLEWARES = {
# '项目名.middlewares.middlewares.py里面刚刚写的类名': 543,
'chuxiongspider.middlewares.ProxyMiddleware': 543,
'scrapy.downloadermiddleware.httpproxy.HttpProxyMiddleware': None # 关闭scrapy自带代理服务
}3,运行结果
五,参考博客
参考博客:
参考博客:Scrapy调用proxypool代理_GamersRay的博客-CSDN博客_scrapy使用代理池
六,补充
感觉用这个有点慢...