Linux系统编程之我的学习笔记1
gcc(g++)的工作流程:
1 预处理:调用cpp的预处理器,do的工作是:去掉注释,展开头文件,宏替换
gcc -E test.c -o test.i
2 编译:gcc将源代码文件编译为汇编语言代码
gcc -S test.i -o test.s
3 汇编:as,将汇编语言代码编译为了二进制文件(目标代码)
gcc -c test.s -o test.o
4 链接:ld,链接test.c代码中所调用到的库函数
gcc -o test.o test
//要是想一步到位,do上面四步的工作的话,就用:
gcc test.cpp(源文件名)/.c -o test(可执行文件名)
CPP中,库一般都是一些功能相近或者相似的函数和类的集合体
库 分为静态库(static libary) 和 动态(共享)库(shared libary)
//linux下,静态库文件用.a 作为后缀名;动态库文件用.so 作为后缀名
//windows下,静态库文件用.lib 作为后缀名,动态库文件用.dll 作为后缀名
一份库 制作完成后,如何给用户使用呢?
//1-头文件:包含了库函数和类的声明
//2-库文件:包含了库函数和类的代码实现
//注意:库不能单独使用,只能作为其他执行程序的一部分来完成某些功能
//也就是说只能被其他程序调用类才能够使用!!!
//你一个公司自己写的库源代码肯定不能给别人!肯定是给一个头文件和加密了的库文件卖给别人去用而已!
静态库(static library)
静态库可以认为是一些目标代码的集合,是在可执行程序运行前就已经加入到执行代码中的了,
已经成为可执行程序的一部分了(因此,如果生成了可执行程序后,你再删除静态库也不会对可执行程序产生任何的影响!)
按照习惯,linux下的静态库一般都是以.a作为文件的后缀名的
静态库的命名一般分为3个部分:
1-前缀:lib
2-库名称:自定义即可,如test
3-后缀:.a
所有最终的静态库名称为:libtest.a
静态库文件的制作:
以mySwap.cpp和mySwap.h为例子!
第①步:将.c /.cpp源文件编译为.o目标文件
gcc -c mySwap.c //C语言
gcc -c mySwap.c mySwap2.c mySwap3.c ...//C++ 多个.c源文件时
g++ -c mySwap.cpp //C++
g++ -c mySwap.cpp mySwap2.cpp mySwap3.cpp ...//C++ 多个.cpp源文件时第②步:使用linux下的ar工具,将.o文件打包为.a文件
固定格式为:ar rcs lib(静态库's Name).a test1.o test2.o
//比如:
ar rcs libtest1.a mySwap.o 在编译程序时,静态库的调用(使用):(动态库的调用和使用同静态库的一模一样!!!)
//当库中所用到的 .h头文件 和 .a库文件在当前目录下时
格式:
g++ main.cpp -o main -I./ -L./ -ltest1 (注意!-l后要写上静态库真正地名字,也即去掉lib和.a后剩下的名字)
//当然 这里的头文件 和 库文件路径的指定 可以是绝对路径 也可以为相对路径!
//看你怎么方便怎么用了!
//加入.h头文件 和 .a库文件不在同一目录,那么如何调用静态库来编译器源文件呢?
格式:
g++ main.cpp -o main -I(头文件绝对路径/相对路径) -L(库文件绝对路径/相对路径) -ltest1(注意!-l后要写上静态库真正地名字,也即去掉lib和.a后剩下的名字)
//比如:.h头文件在文件夹/Desktop/myTest/myTest2中 .a库文件在文件夹/Desktop/myTest/myTest2中test_codes:
//swap.h
#pragma once
#include
using namespace std;
void mySwap(int& a,int& b);
//swap.cpp
#include"swap.h"
void mySwap(int& a,int& b){
auto t = a;
a = b;
b = t;
}
//main.cpp
#include
#include"swap.h"
using namespace std;
int main(void){
cout<<"before swap:"< 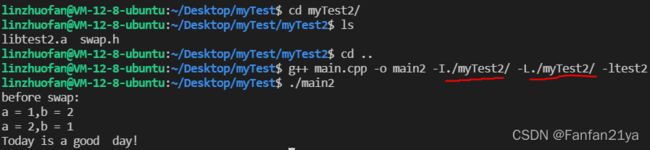


第①步:用gcc -fpic -c 把源文件(*.c/*.cpp)编译为目标文件(*.o)
第②步:用gcc -shared -o 把目标文件(*.o)编译成库(*.so)文件
当然,鉴于我们是Cpp选手,所以所有的源文件为.cpp文件,我们把上述的gcc对应改成g++即可!

//当库中所用到的 .h头文件 和 .a库文件在当前目录下时
格式:
g++ main.cpp -o main -I./ -L./ -ltest1 (注意!-l后要写上动态库真正地名字,也即去掉lib和.so后剩下的名字)
//当然 这里的头文件 和 库文件路径的指定 可以是绝对路径 也可以为相对路径!
//看你怎么方便怎么用了!
//加入.h头文件 和 .a库文件不在同一目录,那么如何调用静态库来编译器源文件呢?
格式:
g++ main.cpp -o main -I(头文件绝对路径/相对路径) -L(库文件绝对路径/相对路径) -ltest1(注意!-l后要写上动态库真正地名字,也即去掉lib和.so后剩下的名字)
//比如:.h头文件在文件夹/Desktop/myTest/myTest2中 .so库文件在文件夹/Desktop/myTest/myTest2中但是,当我按照黑马程序员的教程写完之后,却还是找不到动态库!出现如下error!
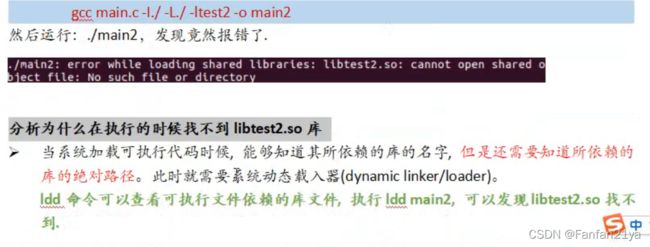
编译运行时,居然说找不到动态库文件!!!
![]()
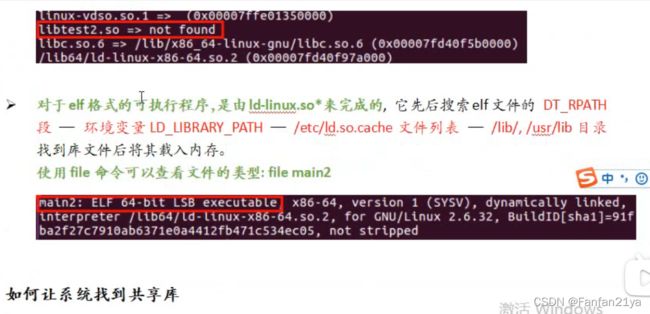
用命令行 ldd main2 可以查看此时的main2可执行文件中的动态库是否连接成功!

从图中我们可以看出来,是链接失败了的!
原因分析:ld提示找不到库文件,而库文件就在当前目录中。链接器ld默认的目录是/lib和/usr/lib;若放在其他路径也可以(当前我这里的报错显然就是我没有把动态库.so文件放在/lib或者/usr/lib中!!!),但是你必须需要让ld知道库文件在哪里。
注意:非常不建议把你自己写的库文件放到/lib或者/usr/lib目录中!因为这2个目录下都是系统级别的库文件,你如果频繁增删库文件到这里的话,肯定会容易造成操作失误!甚至删除or覆盖了原来的系统自己的库文件,那这样你就gg了的!

最佳最常用最推荐的解决方法(实际开发中你自己是linux的普通用户,肯定没有sudo权限!所有学会这种方法就足够了的!):
把动态库.so文件移动到当前普通用户的家目录下的lib文件中去!(即~/lib)
先按cd回到普通用户的家目录下!
1: 先输入命令行vi .bashrc(centos:下是vi ~/.bashrc),并按大G键,滑动到文件尾部,
再添加命令行:export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:库文件的绝对路径
//这里我测试用的路径为 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/Desktop/myTest/lib
按:wq保存并退出.bashrc文件(vim中保存并退出的操作命令)
2: 还是在普通用户的家路径下(~路径下)写上命令行
source .bashrc(centos:下是source ~/.bashrc)
或者
. .bashrc
用来更新配置文件,使得我们刚才更新的配置文件.bashrc生效!
//那么do完这2步之后,你的cpp程序就能正常调用你自己写的动态库文件啦!~以下为关键步骤的截图:

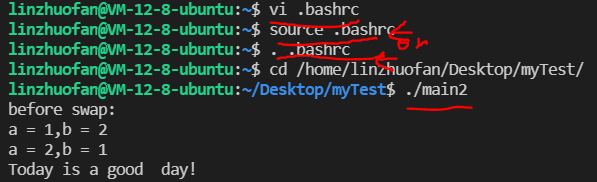
成功运行!解决问题啦!~
当然,这种方法还有一个小小的缺陷(问题不大)。就是,当你别的登录了该普通用户的窗口想指向同一份使用了该动态库的代码的编译成功了的二进制代码时,仍然需要跑到家目录(~目录,即你输入一个cd命令就能去到了),然后使用source .bashrc 或者. .bashrc来更新配置文件,这样你才能继续使用正常链接到动态库文件哈!~
比如:这里我在Xshell中另外登录上的自己的ubuntu时要运行该编译好的二进制文件main2时所要do的工作:(以后工作了,日常cpp开发也是要这么干的哈!~)

一般,你这么改2次后,以后登录该用户下的linux再运行该程序时,就能正常帮你链接到动态库啦~
其他解决方法(这需要修改系统级别lib的权限sudo,但是实际开发中你肯定是没有的,不推荐,但是我还是知道一下为妙~):
原因分析:ld提示找不到库文件,而库文件就在当前目录中。
链接器ld默认的目录是/lib和/usr/lib,如果放在其他路径也可以,但是你需要让ld知道库文件在哪里。
方法1:
编辑/etc/ld.so.conf文件,在新的一行中加入库文件所在目录;
运行ldconfig,以更新/etc/ld.so.cache文件;
方法2:(我自己用的就是这个方法2!记得加sudo 超级管理员的权限来do即可!)
在/etc/ld.so.conf.d/目录下新建任何以.conf为后缀的文件,在该文件中加入库文件所在的目录;
运行ldconfig,以更新/etc/ld.so.cache文件;
//这个方法也是在CSDN上搜的!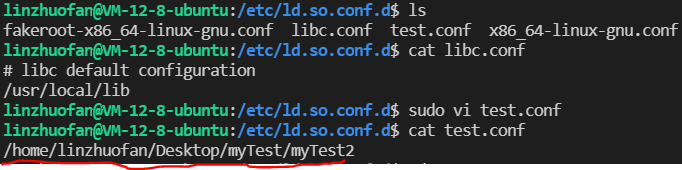
再用sudo ldconfig 更新动态库所在之目录内容 即可大功告成!!!
![]()
用命令行 ldd main2 可以查看此时的main2可执行文件中的动态库是否连接成功!


运行成功!ojbk了!
错误解决error while loading shared libraries: libXXX.so.X: cannot open shared object file: No such file_David_xtd的专栏-CSN博客



接着学~


(当然, 现在我们都是用CMake这个工具来自动编写makefile文件,然后再用make命令对对应之makefile文件进行解析并执行的了!)

makefile编写的规则:
目标名(可执行程序名):依赖项(比如test.cpp test2.cpp 1个or多个.cpp/.c文件)
(按一次tab键)+对应的编译命令
==>
目标:依赖
(tab)命令
1th例子(最简单版本的makefile文件之编写):
my_pj:test.cpp
g++ -o my_pj test.cpp
编写完成后,在保存这些依赖项的目录下,终端输入命令make,即可自动执行g++ -o my_pj test.cpp为你编译生成对应之可执行程序了!


检查makefile的生成规则:
若想生成目标文件,先要检查依赖条件是否都存在:
若都存在,则比较目标的(创建/更新)时间和依赖的(创建/更新)时间,如果依赖的时间比目标的新,
则重新生成目标;否则不重新生成
若不存在依赖条件,则从下往上找,看是否有生成对应依赖条件的命令,若有则生成,没有则报错!
注意:若只是某些(极个别)的依赖被更新了,则在重新生成目标时,只会执行对应的依赖项命令以及目标生成的命令而已!
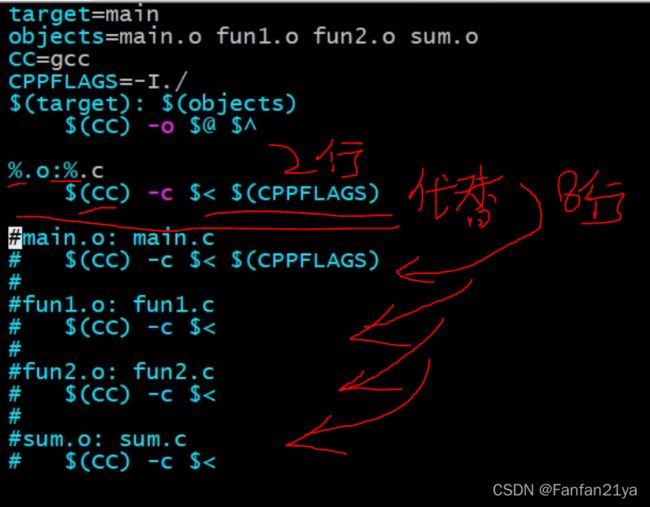
例子2:
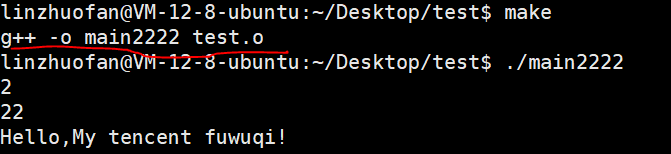
我的makefile:
main222:test.o
g++ -o main222 test.o
test.o:test.cpp
g++ -c test.cpp -I./#表明头文件在当前的目录下!因为test.cpp中用到了自定义的头文件!so得这么干!

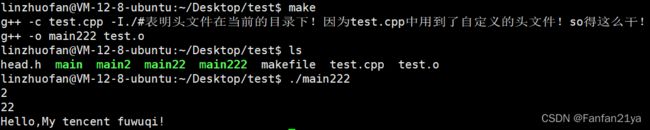
makefile的缺点:冗余,若.c/.cpp文件数量较多时,编写起来非常麻烦!!!
因此,下面引入makefile中的变量!


注意:
CC是选定编译器的意思(linux下,C语言程序用gcc,C++语言程序用g++)
CPPFLAGS是选定你的.c/.cpp源代码在do预处理时所包含的头文件所在的路径,在哪个路径下找到头文件进而do展开呢?
CFLAGS是编译时选定,是否需要添加额外的选项(-Wall会输出warning警告信息,-
g使得你的程序可使用gdb调试,-c目前还不清楚可以干嘛~)
LDFLAGS是do链接时,指定你的静态库/动态库的路径以及名字的!(-L+绝对路径/相对路径 来指定库所在的路径!-I+库真正地名字,掐头lib去尾.a/.so就是库真正地名字了)
test:(makefile的普通变量)

test:(makefile的自带变量)


注意:

其中,$< 表示的是规则中的第一个条件,也即依赖项条件的第一个的意思!比如: 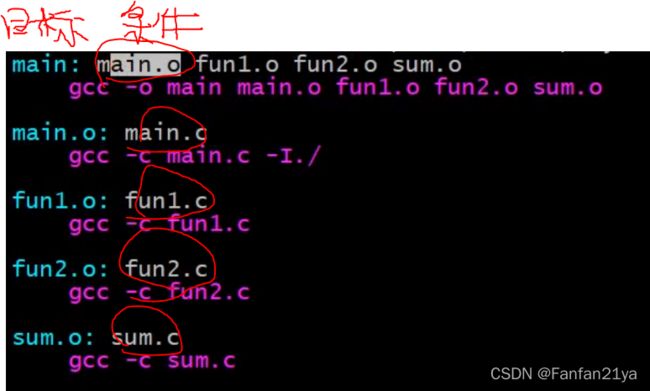
test:(makefile的自动变量)


or

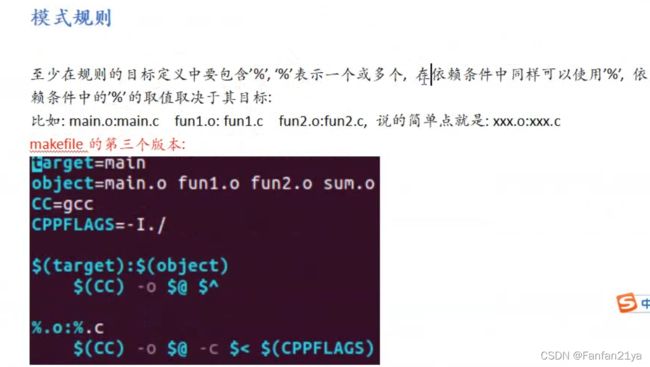
小总结:
变量:
自定义变量:定义--->val = hello;引用--->$(var)
自带变量:CC CFLAGS CPPFLAGS LDFLAGS
自动变量:$@(指向目标) $<(指向第一个依赖项) $^(指向所有依赖项) (注意!自动变量只可以在规则的命令中使用)
模式规则(用来方便把多个重复的makefile语句写成一个万能的可复用的makefile语句):%.o:%.cpp --->前后的%必须一样!当然,makefile中还有存在函数的!

test:makefile中的函数!(并且,这个makefile可以说是一个非常通用的模板!你就改改target目标名(即可执行程序名),CPPFLAGS视情况而定是否需要修改!)

但是,makefile中的函数也是存在缺点的!

最终目标文件就是你要生成的可执行程序这个文件。
最终的通用版本的makefile模板:(我个人觉得不太合适,为啥一定要搞成.o文件呢?)
(当然,对于我们C++程序员来说,.c文件要改为.cpp文件,gcc也要该为g++)
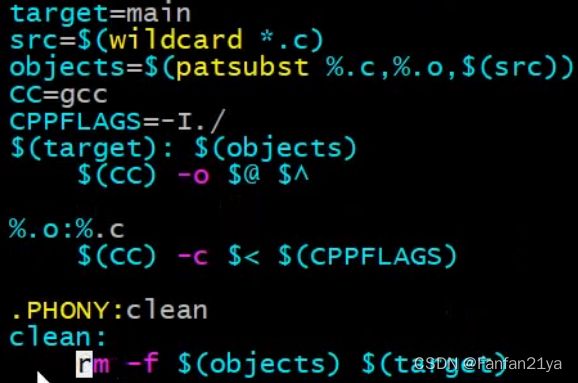
个人认为最适合自己的也最通用的makefile模板是:(个人觉得是适合自己的,推荐自己多用的)

当然,-I路径你得具体情况具体分析!src_cpp也放在当前的目录下,那就可以用该模板套着写makefile了!
把这个最终版本的makefile看懂了之后,就差不太多了!!!

补充:在使用make命令时,也要一个-f参数可选!因为make命令会默认找名为makefile的文件,但是如果改名了,你也可以用-f来make你改名后的不叫makefile的真正makefile文件!(但一般不建议改成乱七八糟的名,就叫makefile是最好的!)
下面我将介绍GDB(GNU Debugger)调试!(不一定要完全掌握,但可能面试会问到!)



or gcc -g hello.c -o hello 一步到位!

在我的某目录下的makefile中,加入-g参数用于编译! 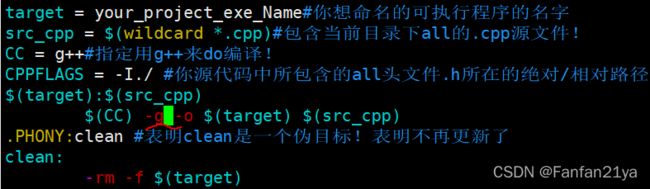
设置运行参数: 
启动gdb:
gdb program_Name
执行程序:
run:会一直执行到第一个断点为止, 没有断点的话,就会一直执行到程序结束处
start:会执行完程序的第一行(代码)语句然后结束


要是想查看断点信息的话,使用命令:info b or i(简写!) b
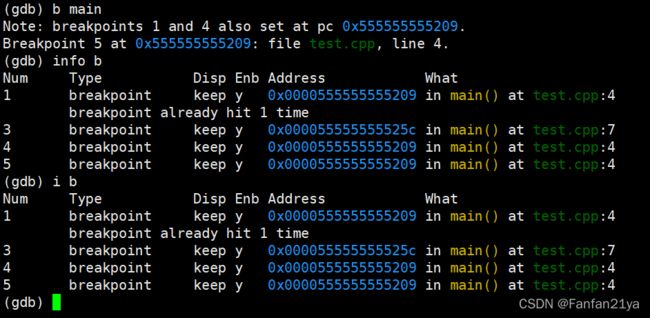
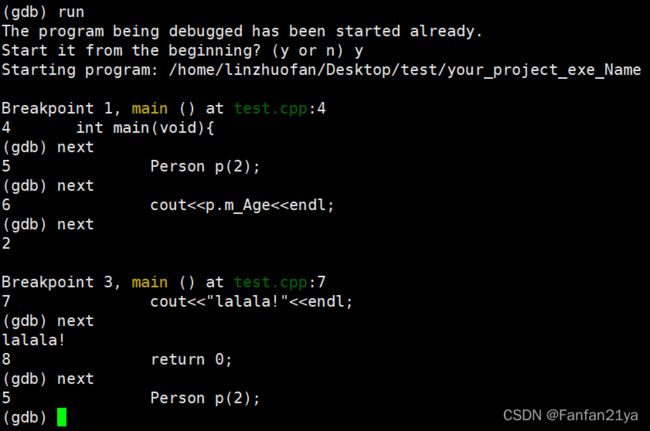
要是想,在遇到断点后,继续往下执行程序的话,则使用命令:next
要是想,让已经设置好了的断点失效(Enable)的话,则使用命令:disable n(为断点的编号!)or disable num1-num2把num1-num2的连续断点给整失效!
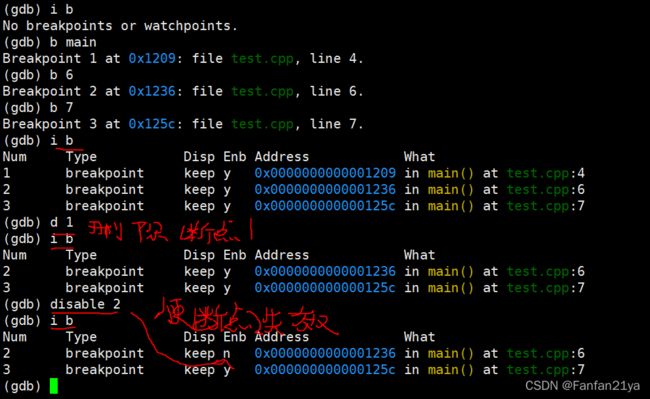
要是想,删除(delete)已经设置好了的断点的话,则使用命令:d n(为断点的编号!)or d num1-num2把num1-num2的连续断点给删除掉!(注意!不连续的话,你可以把断点对应的编号分开写即可)

要是想,恢复(enable使能)已经设置好失效了的断点的话,则使用命令:enable n(为断点的编号!)or enable num1-num2把num1-num2的连续断点给使能!



断点操作之小总结:
设置断点:(当然,必须在程序run执行时才能do这些操作!)
b linenum
b func
b file:linenum
b file:func
查看断点信息:
info break(info b || i b)
使断点失效:
disable m n || m-n
使断点有效:
enable m n || m-n
删除断点:
delete m n || m-n

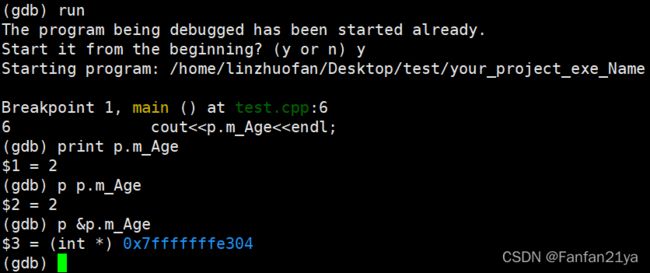

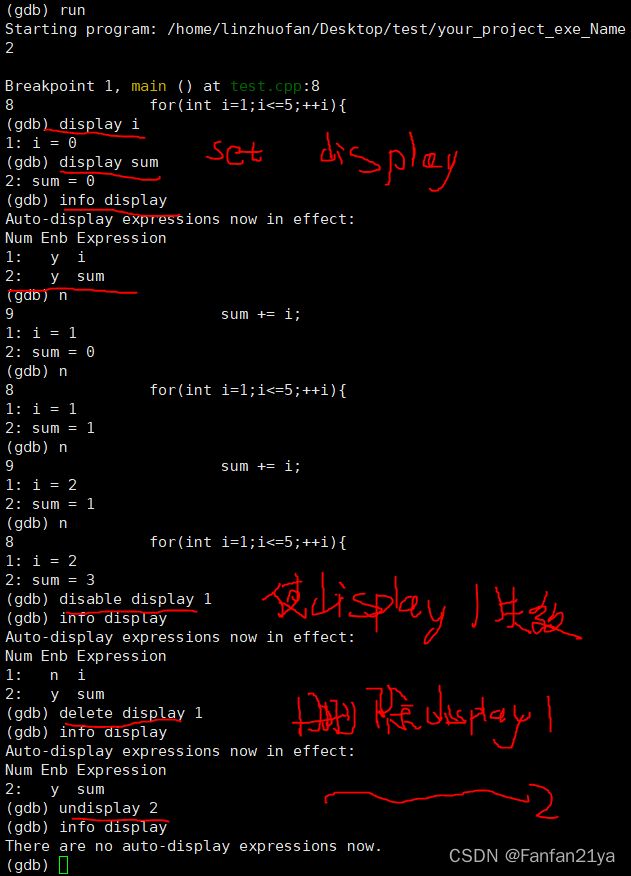
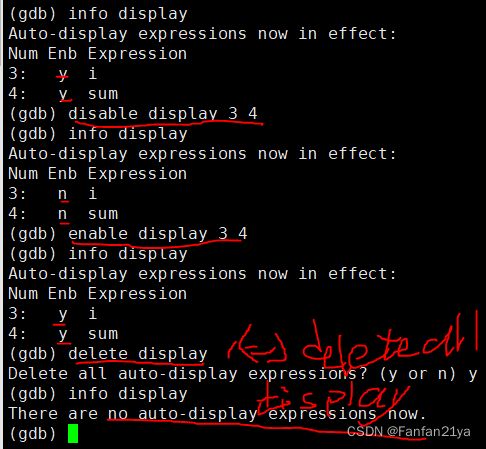
小总结,关于gdb中的自动显示的操作:
自动变量显示:(当然,和设置断点一样,都必须在程序run执行时才能do这些操作!)
display var(生成/创建 对应的自动显示的变量)
info display(展示all的自动显示的变量之信息)
disable display m n | m-n | 空着(使得对应的自动显示的变量 失效)
enable display m n | m-n | 空着(使得对应的自动显示的变量 生效)
delete display m n | m-n | 空着(删除对应的自动显示的变量)
undisplay m n | m-n | 空着(删除对应的自动显示的变量)

注意:在程序运行时修改一些参数,可能会有利于我们调试判断自己写的代码是否是好的,考虑完整完全的!
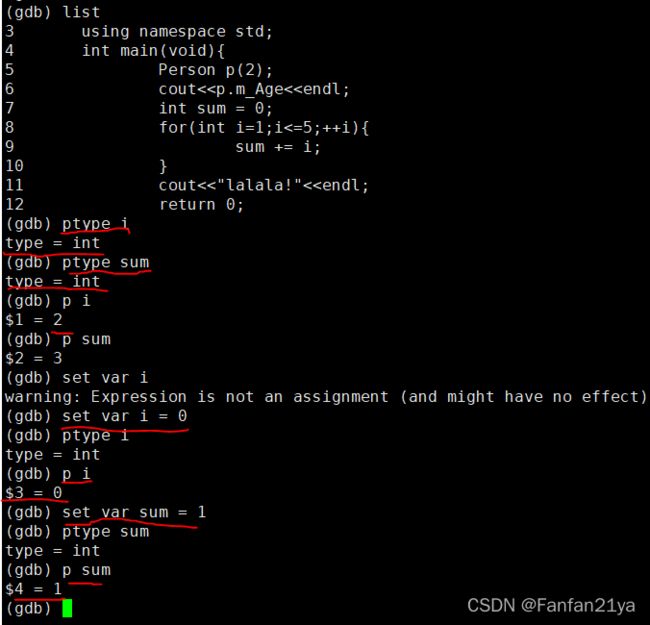
最后,再记住一个,退出GDB(GNU Debugger)调试的命令为:quit


注意:这些linux的各种系统函数其实你不记得也ok(其实也没有必要所有都去记住!!!),只要你会在linux下去查询它们到底是怎么去用的就可以了!(man 2 XXXfuncnName)
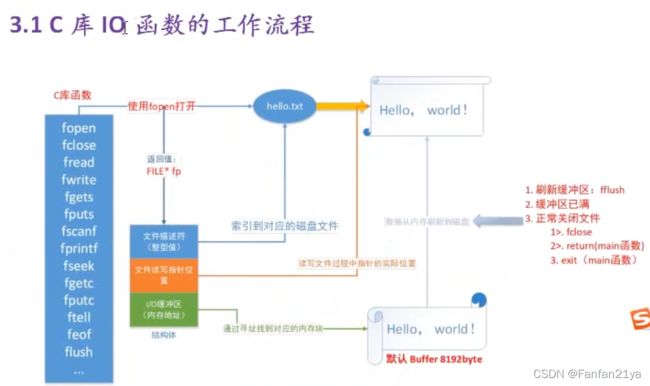




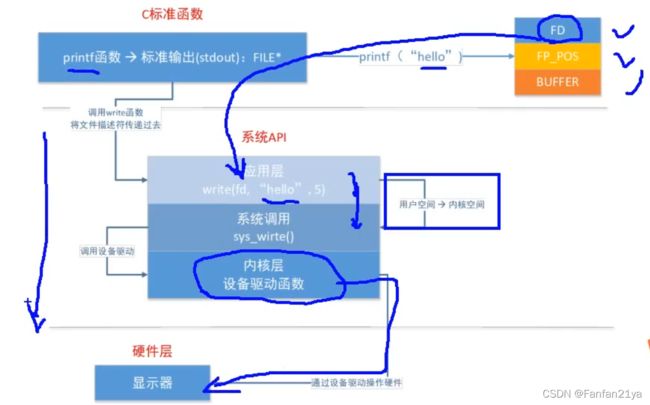
小总结:
库函数和系统函数的关系:是调用和被调用的关系!或者说,库函数是对系统函数的进一步封装!


PCB(进程控制块,这个术语来自于《操作系统》)

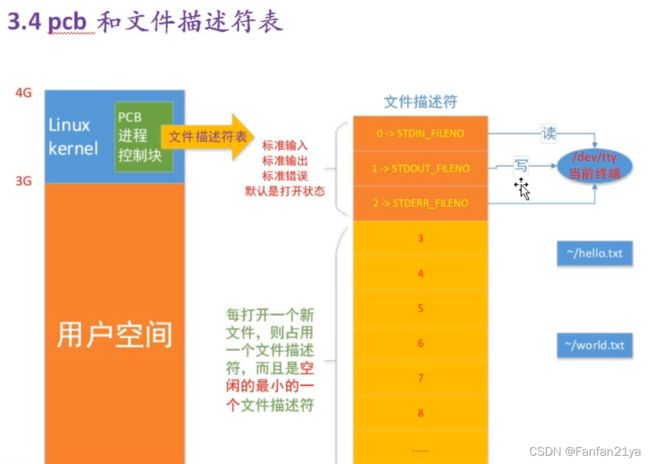

也即通过文件描述符可以找到磁盘的数据块!
下面介绍 Linux 文件IO(输入输出的系统函数):




一般来说,在linux下,大多数的系统函数程序运行成功后,都会返回0!

记住这句话:有open就必须要有close!但凡是你打开的文件,最终都必须要被关闭掉!





Iseek函数的应用:

test_codes:(用来熟悉一下这几个linux IO的系统函数!)
//IO函数测试--->open close read write lseek
//linux下写c语言程序常用的头文件!
#include
#include
#include
#include//include 各种类型声明 比如size_t
#include//这是linux下特有的头文件!
#include
#include
int main(int argc,char* argv[])
{
//读文件
// int open(const char *pathname, int flags);
//int open(const char *pathname, int flags, mode_t mode);
//int creat(const char *pathname, mode_t mode);
//int openat(int dirfd, const char *pathname, int flags);
//int openat(int dirfd, const char *pathname, int flags, mode_t mode);
int fd = open(argv[1],O_RDWR | O_CREAT,0777);//0777代表的是test.log的文件訪問权限的意思!不懂就百度!
if(fd<0){
perror("open error!");
return -1;
}
//写文件
//ssize_t write(int fd, const void *buf, size_t count);
//这些都是在linux终端下,敲下命令:man 2 XXX函数名 然后得知的内容!
write(fd,"hello,world!",strlen("hello,world!"));//hello,world这个字符串是我要写入该文件的内容!
//移动文件指针到文件的开始处
//off_t lseek(int fd, off_t offset, int whence);
lseek(fd,0,SEEK_SET);
//读文件
//ssize_t read(int fd, void *buf, size_t count);
char buf[1024];
memset(buf,0x00,sizeof(buf));
int n = read(fd,buf,sizeof(buf));
printf("n==[%d],buf ==[%s]\n",n,buf);
//关闭文件
//int close(int fd);
close(fd);
return 0;
} 
练习题:
①使用lseek函数 获取文件的大小
//lseek函数获取文件大小之test codes
#include
#include
#include
#include//include 各种类型声明 比如size_t
#include//这是linux下特有的头文件!
#include
#include
int main(int argc,char* argv[]){
//打开文件
int fd = open(argv[1],O_RDWR );
if(fd<0){
perror("open error!");
return -1;
}
//off_t lseek(int fd, off_t offset, int whence);
//调用lseek函数获取文件的大小
int len = lseek(fd,0,SEEK_END);
printf("file size:[%d]\n",len);
//关闭文件
//int close(int fd);
close(fd);
return 0;
}
result: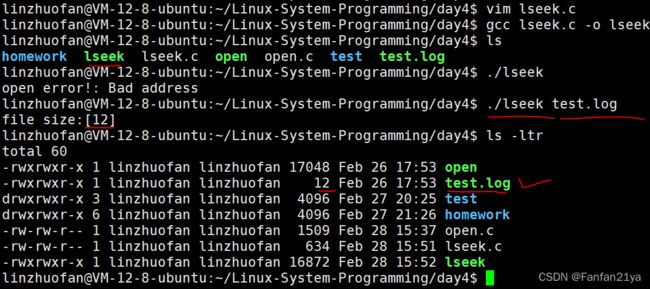
②使用lseek函数 实现文件的拓展
//lseek函数实现文件拓展之test codes
#include
#include
#include
#include//include 各种类型声明 比如size_t
#include//这是linux下特有的头文件!
#include
#include
int main(int argc,char* argv[]){
//打开文件
int fd = open(argv[1],O_RDWR );
if(fd<0){
perror("open error!");
return -1;
}
//移动文件指针到文件的第100个字节处(相对文件的开头处)
//off_t lseek(int fd, off_t offset, int whence);
//调用lseek函数获取文件的大小
lseek(fd,100,SEEK_SET);
//进行1次写入操作
write(fd,"H",1);
//关闭文件
//int close(int fd);
close(fd);
return 0;
}
result:(文件从12个字节变成了101个字节了!)
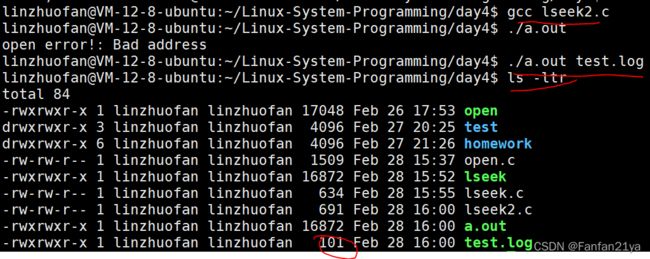
test.log文件:
![]()

test_codes:
是result:

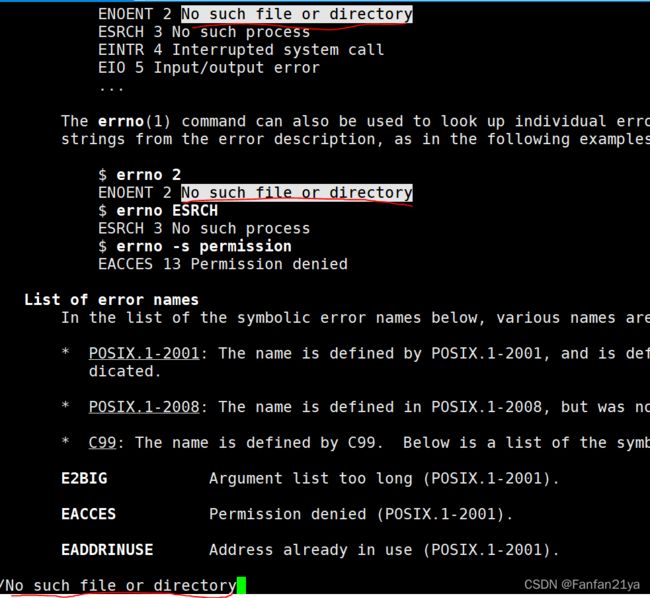
No such file or directory 这个错误信息可以在man errno中查询到!
(先用man errno进入errno的函数源码处,再输入/No such file or directory就可以定位查询到了)
下面我们思考一个问题:
阻塞和非阻塞是文件属性还是read函数得属性呢?也即:read函数到底是阻塞的还是非阻塞的呢?
test_codes:(验证read函数 读普通文件是否 阻塞)
//验证read函数 读普通文件是否 阻塞
#include
#include
#include
#include//include 各种类型声明 比如size_t
#include//这是linux下特有的头文件!
#include
#include
int main(int argc,char* argv[]){
//打开文件
int fd = open(argv[1],O_RDWR);
if(fd<0){
perror("open error!");
return -1;
}
//读文件
char buf[1024];
memset(buf,0x00,sizeof(buf));
int n = read(fd,buf,sizeof(buf));
printf("FIRST:n==[%d],buf ==[%s]\n",n,buf);
//再次读文件,验证read函数是否是阻塞的
memset(buf,0x00,sizeof(buf));
n = read(fd,buf,sizeof(buf));
printf("SECOND:n==[%d],buf ==[%s]\n",n,buf);
//if read函数是阻塞的,则second这行代码根本就输出不了
//若second输出了,则read函数是非阻塞的!
//关闭文件
//int close(int fd);
close(fd);
return 0;
}
result:
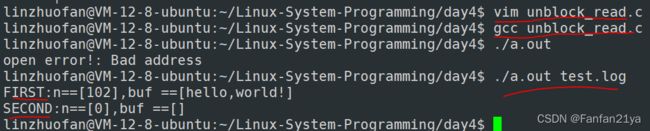
答案:通过读取普通文件测试得知:read函数在读完文件内容之后,若再次read,则read函数会立刻返回,表明read函数读普通文件是非阻塞的!
test_codes2:(验证read函数 读设备文件是否 阻塞)
//验证read函数 读设备文件是否 阻塞
#include
#include
#include
#include//include 各种类型声明 比如size_t
#include//这是linux下特有的头文件!
#include
#include
int main(int argc,char* argv[]){
//打开设备文件
int fd = open("/dev/tty",O_RDWR);
if(fd<0){
perror("open error!");
return -1;
}
//读文件
char buf[1024];
memset(buf,0x00,sizeof(buf));
int n = read(fd,buf,sizeof(buf));
printf("FIRST:n==[%d],buf ==[%s]\n",n,buf);
//关闭文件
//int close(int fd);
close(fd);
return 0;
}
result:

这里只有你敲入hello world!才会返回下面的FIRST。。。否则就一直堵塞在这里不动
答案:通过读取/dev/tty路径下的终端设备文件测试得知:表明read函数读设备文件是阻塞的!
test_codes3:
//验证read函数 读标准输入是否 阻塞
#include
#include
#include
#include//include 各种类型声明 比如size_t
#include//这是linux下特有的头文件!
#include
#include
int main(int argc,char* argv[]){
//读标准输入
char buf[1024];
memset(buf,0x00,sizeof(buf));
int n = read(STDIN_FILENO,buf,sizeof(buf));
printf("FIRST:n==[%d],buf ==[%s]\n",n,buf);
return 0;
}
result:

这里只有你敲入lalala才会返回下面的FIRST。。。否则就一直堵塞在这里不动
答案:通过读取标准输入测试得知:表明read函数读标准输入是阻塞的!
结论:阻塞和非阻塞并不是read函数的属性,而是文件本身的属性!
socket和pipe则两种文件则都是阻塞的!(后面讲到后会描述的!)


stat函数的一些重要参数:(可以通过在终端敲下命令 man 2 stat 来查看!)

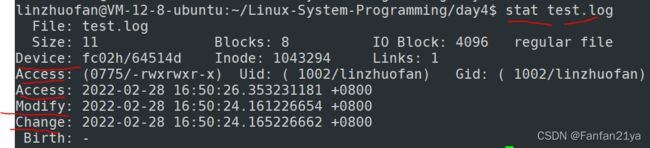
test_codes:
//stat函数测试:获取文件的大小,文件属user和group
//linux下写c语言程序常用的头文件!
#include
#include
#include
#include//include 各种类型声明 比如size_t
#include//这是linux下特有的头文件!
#include
#include
int main(int argc,char* argv[]){
//int stat(const char *pathname, struct stat *statbuf);
struct stat st;
stat(argv[1],&st);
printf("size:[%d],uid:[%d],gid:[%d]\n",st.st_size,st.st_uid,st.st_gid);
return 0;
}
result:
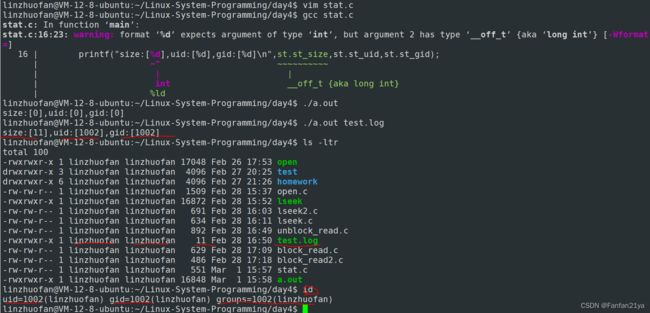
注意:命令id可以输出当前linux用户下的所有用户uid,组gid和组别groups



test_codes:
//stat函数测试:获取文件的类型和权限
#include
#include
#include
#include//include 各种类型声明 比如size_t
#include//这是linux下特有的头文件!
#include
#include
int main(int argc,char* argv[]){
//int stat(const char *pathname, struct stat *statbuf);
//获取文件的属性
struct stat st;
stat(argv[1],&st);
//获取文件类型
if((st.st_mode & S_IFMT) == S_IFREG)
{
printf("普通文件\n");
}
else if((st.st_mode & S_IFMT) == S_IFDIR)
{
printf("目录文件\n");
}
else if((st.st_mode & S_IFMT) == S_IFLNK)
{
printf("链接文件\n");
}
if(S_ISREG(st.st_mode))
{
printf("普通文件\n");
}
else if(S_ISDIR(st.st_mode))
{
printf("目录文件\n");
}
else if(S_ISLNK(st.st_mode))
{
printf("链接文件\n");
}
return 0;
}
result:

注意:对于链接文件而言,不论是软连接softlink还是硬链接hardlink,用stat函数最后都会显示出其所链接到的真正的文件之属性!
改进test_codes:
//stat函数测试:获取文件的类型和权限
#include
#include
#include
#include//include 各种类型声明 比如size_t
#include//这是linux下特有的头文件!
#include
#include
int main(int argc,char* argv[]){
//int stat(const char *pathname, struct stat *statbuf);
//获取文件的属性
struct stat st;
stat(argv[1],&st);
//获取文件类型
if((st.st_mode & S_IFMT) == S_IFREG)
{
printf("普通文件\n");
}
else if((st.st_mode & S_IFMT) == S_IFDIR)
{
printf("目录文件\n");
}
else if((st.st_mode & S_IFMT) == S_IFLNK)
{
printf("链接文件\n");
}
if(S_ISREG(st.st_mode))
{
printf("普通文件\n");
}
else if(S_ISDIR(st.st_mode))
{
printf("目录文件\n");
}
else if(S_ISLNK(st.st_mode))
{
printf("链接文件\n");
}
//判断文件权限
//因为 权限 是可以有多个的,因此不能用if-else语句来判断,而是挨个if语句来判断!
if(st.st_mode & S_IROTH)
{
printf("---R---");
}
if(st.st_mode & S_IWOTH)
{
printf("---W---");
}
if(st.st_mode & S_IXOTH)
{
printf("---x---");
}
printf("\n");
return 0;
}



stat函数小总结:
使用st_mode成员来判断文件的类型 之模板代码:
//int stat(const char *pathname, struct stat *statbuf);
//获取文件的属性
struct stat st;
stat(argv[1],&st);
//获取文件类型
if((st.st_mode & S_IFMT) == S_IFREG)
{
printf("普通文件\n");
}
else if((st.st_mode & S_IFMT) == S_IFDIR)
{
printf("目录文件\n");
}
else if((st.st_mode & S_IFMT) == S_IFLNK)
{
printf("链接文件\n");
}
if(S_ISREG(st.st_mode))
{
printf("普通文件\n");
}
else if(S_ISDIR(st.st_mode))
{
printf("目录文件\n");
}
else if(S_ISLNK(st.st_mode))
{
printf("链接文件\n");
}
//判断文件权限
//因为 权限 是可以有多个的,因此不能用if-else语句来判断,而是挨个if语句来判断!
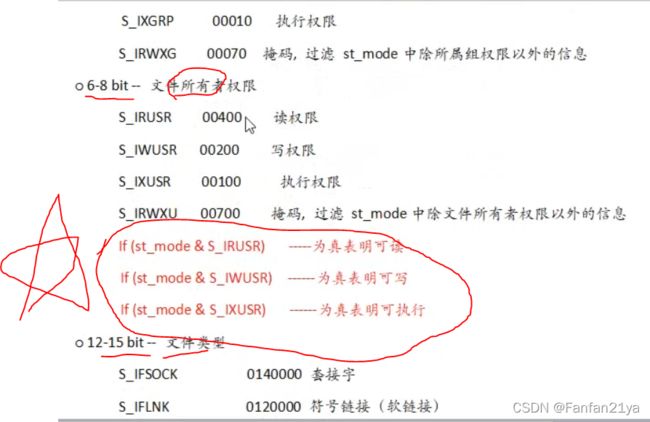
if(st.st_mode & S_IROTH)//读权限R
{
printf("---R---");
}
if(st.st_mode & S_IWOTH)//写权限W
{
printf("---W---");
}
if(st.st_mode & S_IXOTH)//执行权限X
{
printf("---x---");
}
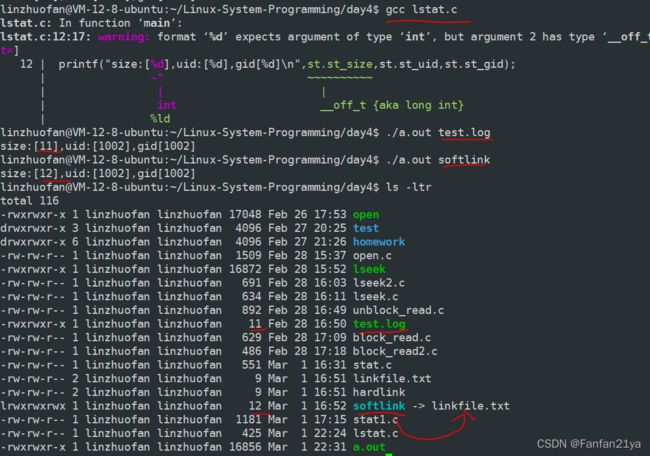
printf("\n");对于lstat,在获取 文件的权限和类型上 与stat无大的区别。但在获取文件的属性上,有
小区别:
1 对于普通文件来说,使用lstat函数和stat函数来获取文件属性的效果是一致的!
2 对于软连接文件来说,lstat函数获取的是软连接文件本身的属性,而stat函数获取的则是链接文件所指向的那个文件的属性!
这个结果记住即可!~以后遇到lstat和stat这2个系统函数不懂得如何区分时再翻回来我的这个笔记看看就行。
test_codes:
//lstat函数测试:获取文件的属性
#include
#include
#include
#include//include 各种类型声明 比如size_t
#include//这是linux下特有的头文件!
#include
#include
int main(int argc,char* argv[]){
struct stat st;
lstat(argv[1],&st);
printf("size:[%d],uid:[%d],gid[%d]\n",st.st_size,st.st_uid,st.st_gid);
return 0;
}

test_codes:
//目录操作测试: opendir readdir closedir
#include
#include
#include
#include
#include
#include
int main(int argc,char* argv[])
{
//打开目录
//DIR *opendir(const char *name);
DIR* pDir = opendir(argv[1]);//pDir为指向该目录的指针
if(pDir == NULL)
{
perror("opendir error!");
return -1;
}
//循环读取目录中的每一项内容
//struct dirent *readdir(DIR *dirp);
struct dirent* pDent = NULL;
while((pDent=readdir(pDir)) != NULL)
{
printf("[%s]\n",pDent->d_name);
//判断文件类型
switch(pDent->d_type)
{
case DT_REG:printf("普通文件");break;
case DT_DIR:printf("目录文件");break;
case DT_LNK:printf("链接文件");break;
default:printf("未知文件");
}
printf("\n");
}
//关闭目录
closedir(pDir);
return 0;
}
result:
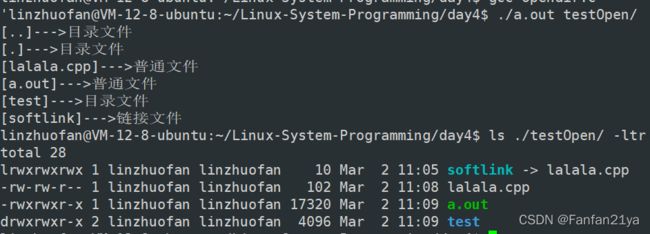
if在上面的测试代码中你想过滤掉.和..这两种隐藏文件的话,那么你就需要加上这一行代码:
//过滤掉.和..文件
if(strcmp(".",pDent->d_name) == 0 || strcmp("..",pDent->d_name) == 0)continue;
result:

目录操作小总结:
目录操作:
1 打开目录:opendir
2 循环读目录:readdir
3 关闭目录:closedir
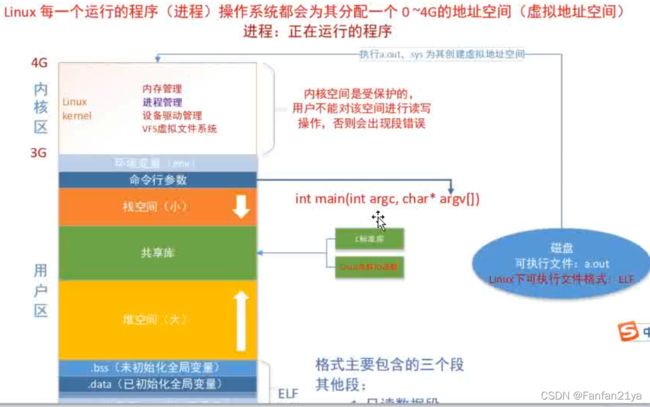
linux操作系统会为每一个进程(运行中的程序)分配一个虚拟的地址空间。
如何验证fd和newfd都指向同一份文件呢?
答:通过fd对文件进行写操作,再使用newfd对文件进行读操作,若读到了文件内容,则认为fd和newfd都指向相同的文件,否则就认为它们指向的是不相同的文件。
test_codes:
//测试dup函数
#include
#include
#include
#include
#include
#include
#include
int main(int argc,char*argv[] )
{
//打开一个已存在的文件
int fd = open(argv[1],O_RDWR);
//若fd<0则表明打开文件失败的意思!
if(fd < 0){
perror("open error!");
return -1;
}
//调用dup函数来复制一个fd文件描述符
int newfd = dup(fd);
printf("newfd:[%d],fd:[%d]\n",newfd,fd);//打印一下fd和newfd的值
//使用fd对文件进行写操作
char * inputStr = "hello,world!";
write(fd,inputStr,strlen(inputStr));
//调用lseek函数移动文件指针到开头处
lseek(fd,0,SEEK_SET);
//使用newfd对文件进行读操作(以验证newfd和fd是否是指向同一份文件的
char buf[1024];//规定这个函数最多可以读到1024个字节的字符串数据!
memset(buf,0x00,sizeof(buf));//数组使用前,记得对其进行初始化!
int size = read(newfd,buf,sizeof(buf));
printf("read over: size==[%d],buf==[%s]\n",size,buf);
//读完后,记得
//关闭文件
close(fd);
close(newfd);
return 0;
}
result:

下面将学习dup2函数,这个函数的功能和dup函数一样(也是复制文件描述符的功能),但是dup2函数比dup函数会更加的好用!

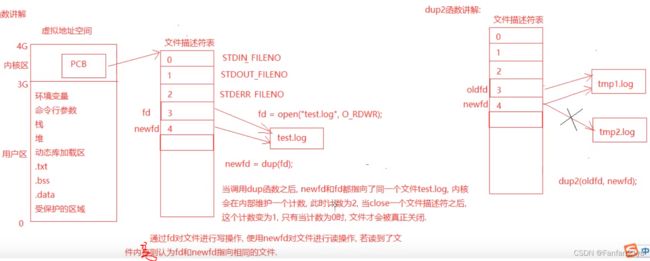
当调用dup2(oldfd,newfd);之后:
若newfd原来已经打开了一个文件,则该函数会关闭这个文件,然后将newfd指向和oldfd相同的文件。
若newfd原来并没有打开文件,则newfd会直接指向 oldfd所指向的那个文件,即此时newfd和oldfd指向了相同文件了。
调用dup2函数之后,内核会修改内部的计数,就比如此时的计数会变成2。当close了newfd/oldfd这两个其中之一个文件描述符后,计数减为1。有且只有当计数为0时,该文件才会被真正地删除掉!
下面通过一个test_codes来验证dup2函数的工作流程是否符合上述描述:
1 打开两个文件,得到oldfd和newfd这两个文件描述符
2 调用dup2(oldfd,newfd);
3 使用newfd写(东西)入文件 /oldfd
4 使用oldfd读文件 /newfd
若oldfd读到了newfd写入了的文件内容,则认为newfd和oldfd指向了相同的文件
test_codes:
//测试dup2函数
#include
#include
#include
#include
#include
#include
#include
int main(int argc,char*argv[] )
{
//打开一个已存在的文件
int oldfd = open(argv[1],O_RDWR);
//若fd<0则表明打开文件失败的意思!
if(oldfd < 0){
perror("open error!");
return -1;
}
//打开另一个已存在的文件
int newfd = open(argv[2],O_RDWR);
//若fd<0则表明打开文件失败的意思!
if(newfd < 0){
perror("open error!");
return -1;
}
//调用dup2函数来复制一个fd文件描述符
dup2(oldfd,newfd);
printf("newfd:[%d],oldfd:[%d]\n",newfd,oldfd);//打印一下oldfd和newfd的值
//使用newfd对文件进行写操作
char * inputStr = "You make me happy!";
write(newfd,inputStr,strlen(inputStr));
//调用lseek函数移动文件指针到开头处
lseek(newfd,0,SEEK_SET);
//使用oldfd对文件进行读操作(以验证newfd和oldfd是否是指向同一份文件的
char buf[1024];//规定这个函数最多可以读到1024个字节的字符串数据!
memset(buf,0x00,sizeof(buf));//数组使用前,记得对其进行初始化!
int size = read(oldfd,buf,sizeof(buf));
printf("read over: size==[%d],buf==[%s]\n",size,buf);
//读完后,记得
//关闭文件
close(oldfd);
close(newfd);
return 0;
}
result:

下面再测试,使用dup2函数实现标准输出重定向的操作。(将printf的输出从终端输出到指定文件中输出去)
所谓的重定向操作,其实很容易理解,
就比如:命令ls -ltr > test.log2,会将ls显示的内容都“输出”到test.log2文件中去,其实就是把ls -ltr命令显示到终端的内容全都定向地输入到test.log2文件中去而已!
(这个命令中,>这个大于号就是重定向的操作符!)
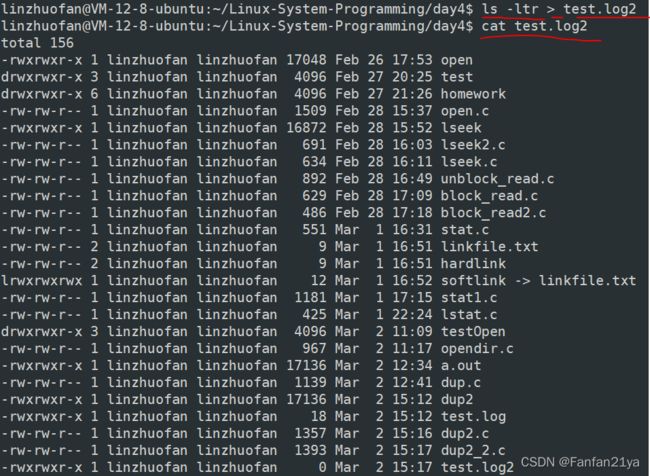
>>符号,可以把字符串追加写入到文件末尾!

test_codes2:
//测试dup2函数实现标准的输出重定向操作
#include
#include
#include
#include
#include
#include
#include
int main(int argc,char*argv[] )
{
//打开一个已存在的文件
int fd = open(argv[1],O_RDWR);
//若fd<0则表明打开文件失败的意思!
if(fd < 0){
perror("open error!");
return -1;
}
//调用dup2函数来复制一个fd文件描述符到文件中去!
dup2(fd,STDOUT_FILENO);
//printf("today is a good day!\n");
char* inputStr= "today is a good day!\n";
write(STDOUT_FILENO,inputStr,strlen(inputStr));
//关闭文件
close(fd);
return 0;
} result:

这个例子的重定向原理图:

解释:本来STDOUT_FILENO是指向/dev/tty(这是linux的屏幕设备文件)的,但是使用dup2(fd,STDOUT_FILENO);之后,因为STDOUT_FILENO最终会指向fd所指向的文件。那么此时,再用标准输出函数printf输出内容的话,就不会再向屏幕设备文件输出了,就会自动地把printf的内容输出(打印给)到fd所指向的文件test.log中了!此时就完成了dup2函数的重定向工作!
最后,再介绍一个IO函数,那么linux的IO系统函数就讲完啦!~
fcntl函数:(功能非常之强大!)


从定义式:int fcntl(int fd,int cmd,.../*arg*/);
就可以看出来:这里的...表明这个fcntl函数是一个变参函数
比如:printf就是一个最常见的变参函数,参数是变化着的,不固定的!


test_codes:
//测试fcntl函数 来复制一个文件描述符
#include
#include
#include
#include
#include
#include
#include
//int fcntl(int fd,int cmd,.../*arg*/);//这里的...表明这个fcntl函数是一个变参函数
//就比如printf就是一个最常见的变参函数,参数是变化着的,不固定的!
int main(int argc,char*argv[] )
{
//打开文件
int fd = open(argv[1],O_RDWR);
if(fd < 0)
{
perror("open error!");
return -1;
}
//调用fcntl函数复制fd 这个文件描述符
int newfd = fcntl(fd,F_DUPFD,0);
printf("newfd:[%d],fd:[%d]\n",newfd,fd);
//使用fd对文件进行写的操作
char* inputStr = "today is friday yeah~";
write(fd,inputStr,strlen(inputStr));
//使用lseek函数移动文件指针到开始处
lseek(fd,0,SEEK_SET);
//使用newfd来读取文件
char buf[64];
memset(buf,0x00,sizeof(buf));
int n = read(newfd,buf,sizeof(buf));
printf("read over: n==[%d],buf==[%s]\n",n,buf);
//关闭文件
close(fd);
close(newfd);
return 0;
}
result:

test2_codes:
//用fcntl函数来修改文件描述符的flag属性
//使得在打开的文件末尾去添加内容,而不是覆盖原内容!
#include
#include
#include
#include//include 各种类型声明 比如size_t
#include//这是linux下特有的头文件!
#include
#include
int main(int argc,char* argv[]){
//读文件(或者说是,打开一个已经存在了的文件)
int fd = open(argv[1],O_RDWR);
if(fd<0){
perror("open error!");
return -1;
}
//获得fd的flags属性
int flags = fcntl(fd,F_GETFL,0);
flags = flags | O_APPEND;// 用 |或表示添加属性的意思!因为在内核这是用的二进制来do |操作的!这就相当于加上某某属性的意思了!
//这样子set了flags属性后,你再写文件的话就是往该文件的末尾添加文件而已了!
fcntl(fd,F_SETFL,flags);
//之前我们没有设置flags属性时,你往一个文件中写入文件后肯定是会自动 覆盖 原有内容的!
//写文件
//ssize_t write(int fd, const void *buf, size_t count);
//这些都是在linux终端下,敲下命令:man 2 XXX函数名 然后得知的内容!
write(fd,"hello,my pretty girl!!!\n",strlen("hello,my pretty girl!!!\n"));//hello,world这个字符串是我要写入该文件的内容!
//关闭文件
//int close(int fd);
close(fd);
return 0;
}
result:

注意:这里使用make + 对应源文件名(除去后缀.c/.cpp的名字),就可以对应快速编译某个源文件了!而不用每一次都 gcc/g++ XXX.c/.cpp -o XXX 敲多这么多代码了!
小总结:
dup和dup2函数:
复制文件描述符----详情看图(我的截图,红色笔记)
fcntl(fcontrol)函数:
1 复制文件描述符:int fd = fcntl(oldfd,F_DUPFD,0);
2 获得和设置文件的flag属性:
int flag = fcntl(fd,F_GETFL,0);
flag = flag | O_APPEND;//flag |= O_APPEND;
fcntl(fd,F_SETFL,flag);
int flag = fcntl(fd,F_GETFL,0);
flag = flag | O_NONBLOCK;//flag |= O_NONBLOCK;
fcntl(fd,F_SETFL,flag);
注:这些都是固定的写法了,如果不会,直接去linux的终端输入命令man func or man 2 func 查即可!
就算在工作中,也不一定说所有的系统函数你都得记住,但最起码你知道怎么去查找!怎么去查如何使用这些函数!知道怎么去查才是王道!下面学习,
目录操作相关的函数:







test_codes:
//测试目录相关的函数 opendir readdir closedir
#include
#include
#include
#include
#include
#include
#include
int checkdir(char* path);
int main(int argc,char* argv[])
{
int n = checkdir(argv[1]);//传递一个路径给main函数!
printf("n==[%d]\n",n);
}
int checkdir(char* path)
{
//打开一个目录
//DIR* opendir(const char* name));
DIR * pDir = opendir(path);
if(pDir == NULL){
perror("opendir error!");
return -1;
}
//循环读取目录项
//struct dirent* readdir(DIR* dirp);
int n = 0;
char sFullPath[1024];
struct dirent* p = NULL;
while((p=readdir(pDir)) != NULL){
//过滤掉.和..文件
if(strcmp(p->d_name,".") == 0 || strcmp(p->d_name,"..") == 0)continue;
printf("文件名:[%s/%s]--->",path,p->d_name);
//判断文件所什么类型
switch(p->d_type){
case DT_DIR:
printf("目录文件\n");
memset(sFullPath,0x00,sizeof(sFullPath));
sprintf(sFullPath,"%s/%s",path,p->d_name);
n += checkdir(sFullPath);//自己调用自己!
break;
case DT_REG:
printf("普通文件\n");n++;
break;
case DT_LNK:
printf("链接文件\n");
break;
}
}
//关闭目录
closedir(pDir);//只要你打开一个目录,就必须要关闭一个目录!这是必须要写的!
return n;
}
result:
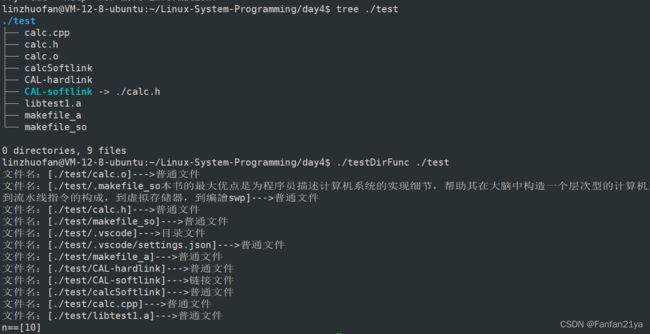
接下来,我们将学习:
了解进程相关的概念
掌握fork/getpid/getppid函数的使用
熟练掌握ps/kill命令的使用
熟练掌握execl/execlp函数的使用(往往是配合fork来使用)
什么是孤儿进程,什么是僵尸进程
父进程回收子进程:
熟练掌握wait函数的使用
熟练掌握waitpid函数的使用
2 进程相关的概念:
2.1 程序和进程
程序,是指编译好的二进制文件,在磁盘上,占用磁盘空间,是一个静态的概念。
进程,一个启动着的程序,进程占用的是系统资源,如:物理内存,CPU,终端等,是一个动态的概念,
程序 ---》剧本(纸)
进程 ---》戏(需要:舞台、演员、灯光、道具...)
同一个剧本,可以在多个舞台上同时出演。同样的,同一个程序也可以加载为不同的进程(但彼此之间互不影响)
注意:每启动一个程序,都对应会有一个进程的PID(processing ID进程号),即使是相同的程序,多次启动,也会有不同的PID。
2.2 并发和并行
并发:在一个时间段内,是在同一个cpu上,同时运行多个程序(每个程序只在一个时间片内执行,CPU肯定不可能只执行一个程序,所有程序都会照顾到~),这就是并发的的概念。
如:若将CPU的1S钟的时间,分成1000个时间片,每个进程执行完一个时间片后都必须无条件让出CPU的使用权,这样1S钟内就可以执行1000个进程了。

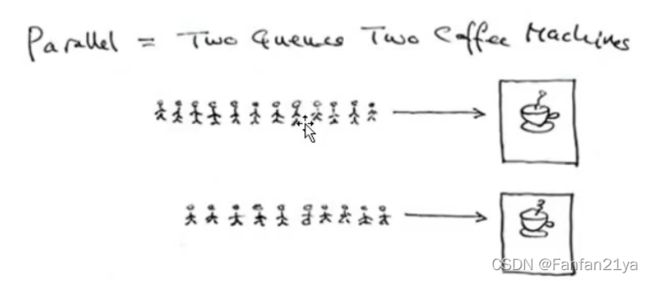
现在不能并行,一次只能做一杯咖啡让人喝。

(一个时间片内,只有一个进程在执行!)
并行:指,在同一个时刻(时间片)内,有两个或两个以上的程序在执行(前提是:有多个CPU或者只有一个CPU但有多个内核才能做到)
现在并行,可以一次做两杯咖啡让人喝了。
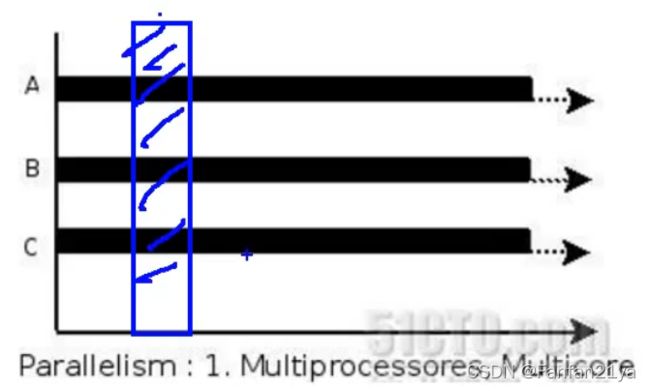
同一个时间片中,有多个进程在执行。(要想实现并行,这至少需要多内核或者两个或以上个的CPU才能达到这样的效果~)
概念小总结:
并发:在同一个时间段内(一个时间段内分为很多个时间片),一个CPU上,有多个程序在执行。
并行:在同一个时间片(时刻)内,有多个程序在同时执行(前提是有多个CPU或者多核)
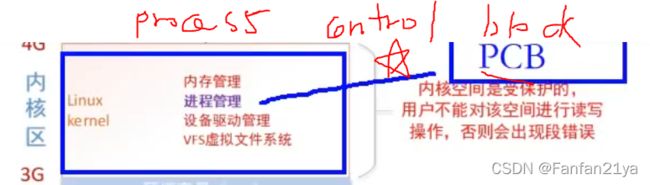
cpu会将一个大的时间段分为多个小的时间片,让 进程 轮流地 使用cpu的时间片2.3 PCB-进程控制块
每个进程在内核中,都有一个进程控制块(PCB,process control block)来维护进程相关的信息,Linux内核的进程控制块是task_struct结构体。
/usr/src/linux-headers-XXX/include/linux/sched.h这个文件中,就可以查看struct task_struct结构体的定义。其内部成员有很多,我们重点掌握以下部分即可:
1 进程id(相当于进程的身份证)。系统中的每个进程都会有唯一的id,在C语言中,用pid_t类型来表示,其实就是一个非负的整数而已。
2 进程的状态,有 就绪、运行、挂起、停止等状态。(面试问)(这些状态是操作系统来调度的,你自己是操作不了的)
3 进程切换时需要保存和恢复的一些CPU寄存器。
4 描述虚拟地址空间的信息
5 描述控制终端的信息
6 当前工作目录(Current Working Directory)
7 umask掩码
8 文件描述符表,包括很多指向file结构体的指针
9 和信号相关的信息(都保存在内核中)
10 用户 id 和 组 id(一个进程启动了之后,一定是属于某个用户的,而该用户肯定又是属于某一个组的,因此该进程既属于某个用户,也属于某个组)
11 会话(Session)和进程组
12 进程可以使用的资源上限(Resource Limit)
可使用命令:ulimit -a 来查看当前用户可使用资源的上限

2.4 进程状态图(面试考)
进程基本的状态有5种。分别是初始态,就绪态,运行态,挂起态,终止态。其中,初始态为进程的准备阶段,常与就绪态结合来看。
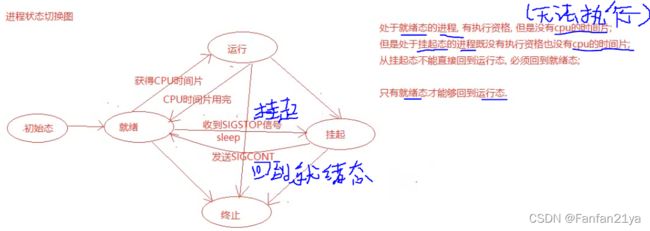
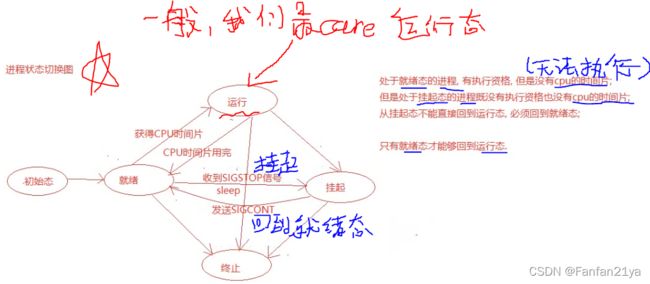
面试时,能把这个图讲个大概就行了!就足够了!
3 创建进程
3.1 fork 函数(very 重要!)
函数作用:创建子进程
原型:pid_t fork(void);
函数参数:无
返回值: 若调用成功:父进程返回子进程的PID(这个PID一定是个大于0的数),子进程则返回数字0;
若调用失败:返回-1,并设置errno值。

同样是进程,但父进程和子进程执行同一段代码时,会产生不一样的结果! 原因就是因为它们的PID不同!

fork 函数test codes:
//fork函数测试代码
#include
#include
#include
#include
#include
int main(int argc,char* argv[])
{
printf("before fork,pid==[%d]\n",getpid());
//创建子进程函数原型:
//pid_t fork(void);
pid_t pid = fork();
if(pid < 0)//fork失败的case
{
perror("fork error!");
return -1;
}
else if(pid == 0)//pid == 0 时,则当前进程为子进程
{
printf("child process: pid==[%d]\n",getpid());
}
else//pid > 0 时,则当前进程为父进程
{
//pid_t getpid(void);
//这个函数会返回调用该函数的进程的ID
//(哪个进程调用它,它就返回谁的PID)
printf("father process: pid==[%d]\n",getpid());
sleep(2);//此時休眠2s钟
}
printf("after fork,pid==[%d]\n",getpid());
return 0;
}
result:

解释:从结果我们可以看出来。在一开始的代码中,父进程还没有创建子进程,此时只有父进程会执行before fork的输出代码。当父进程调用fork函数创建了子进程后,虽然说父子进程会拥有相同的代码(因为这些代码都是处于用户区的,而父进程的用户区就是完全copy一份给到子进程的),但是子进程并不会往上倒着执行上面的before fork代码,而是跟着父进程的脚步,继续往下去执行下面的代码。所以我们可以看到的结果是,不论父进程还是子进程,它们都执行了下面after fork的输出代码!而before fork的输出代码则只有父进程执行了而已!
test codes2:
//fork函数测试代码
#include
#include
#include
#include
#include
int main(int argc,char* argv)
{
printf("before fork,pid==[%d]\n",getpid());
//创建子进程函数原型:
//pid_t fork(void);
pid_t pid = fork();
if(pid < 0)//fork失败的case
{
perror("fork error!");
return -1;
}
else if(pid == 0)//pid == 0 时,则当前进程为子进程
{
printf("child process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
}
else//pid > 0 时,则当前进程为父进程
{
//pid_t getpid(void);
//这个函数会返回调用该函数的进程的ID
//(哪个进程调用它,它就返回谁的PID)
printf("father process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
sleep(2);//此時休眠2s钟
}
printf("after fork,pid==[%d]\n",getpid());
return 0;
}
result2:

![]()
当我把让父进程休息2s的代码sleep(2);注释掉之后,可能会出现父进程先执行完成并退出的case,也有可能出现子进程先执行完成并退出的case。后者这个case的结果和上述结果截图无差,然而前者这种case的结果将会不同!
注意:此时则是处于,哪个进程先抢到CPU的时间片 它就先执行,这样的的局面。(不受我们人为控制)
result3:(注释test codes2中的sleep(2);这一行代码后的结果)

此时是什么情况呢?是这样的,因为此时父进程先抢到CPU的时间片,因此父进程会先执行,执行完成后退出,然后子进程再抢到CPU的时间片执行,后退出。那么对于子进程来说,一旦其原父进程先退出,也即其父进程先死去了,那么这个子进程就变成一个“孤儿”进程了,因此只能给一个PID==1的进程领养了,也就是失去了父进程的子进程会给一个PID==1的进程领养,PID==1的进程就是现在该子进程的父进程了!
而这个PID==1的进程是谁呢?答:init进程(init进程可以回收任何子进程!)

案例:循环创建子进程

test codes:
//fork函数测试代码,让父进程循环创建n个子进程
#include
#include
#include
#include
#include
int main(int argc,char* argv)
{
int i = 0;
for(i=0;i<3;++i)
{
//创建子进程函数原型:
//pid_t fork(void);
pid_t pid = fork();
if(pid < 0)//fork失败的case
{
perror("fork error!");
return -1;
}
else if(pid == 0)//pid == 0 时,则当前进程为子进程
{
printf("child process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
}
else//pid > 0 时,则当前进程为父进程
{
//pid_t getpid(void);
//这个函数会返回调用该函数的进程的ID
//(哪个进程调用它,它就返回谁的PID)
printf("father process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
}
}
return 0;
}
result:
此时循环fork创建子进程的logic是这样子的:
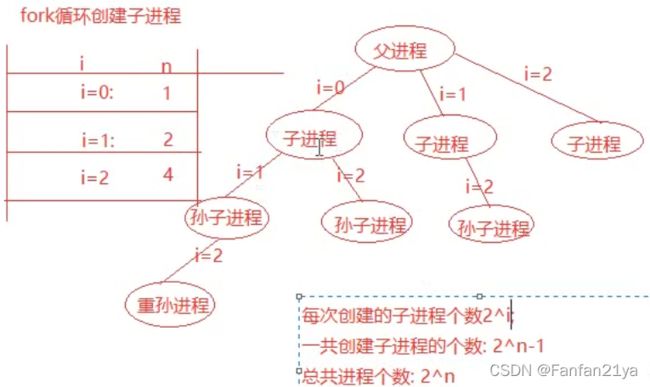 此时,由原父进程通过循环fork创建的子进程之间,就不是互为兄弟关系了。而是复杂的关系!我们一般都不想也不希望达到这种效果。
此时,由原父进程通过循环fork创建的子进程之间,就不是互为兄弟关系了。而是复杂的关系!我们一般都不想也不希望达到这种效果。
通常,我们希望的效果是,由原父进程创建的子进程之间是互相独立的兄弟进程关系!
想要达到这种关系,就必须在创建了一个子进程的代码后加上break语句,此时直接跳出循环!
test codes2:(这种用循环fork创建多个兄弟子进程的代码才是标准的代码!才是我们想要写出的好代码!)
//fork函数测试代码,让父进程循环创建n个子进程
#include
#include
#include
#include
#include
int main(int argc,char* argv)
{
int i = 0;
for(i=0;i<3;++i)
{
//创建子进程函数原型:
//pid_t fork(void);
pid_t pid = fork();
if(pid < 0)//fork失败的case
{
perror("fork error!");
return -1;
}
else if(pid == 0)//pid == 0 时,则当前进程为子进程
{
printf("child process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
break;//加个break 就可以防止子进程再创建孙子进程,防止孙子进程创建重孙进程了
}
else//pid > 0 时,则当前进程为父进程
{
//pid_t getpid(void);
//这个函数会返回调用该函数的进程的ID
//(哪个进程调用它,它就返回谁的PID)
printf("father process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
sleep(2);//此時休眠2s钟
}
}
//第1个子进程
if(i==0){
printf("this is [%d]th child,PID==[%d]\n",i+1,getpid());
}
//第2个子进程
if(i==1){
printf("this is [%d]th child,PID==[%d]\n",i+1,getpid());
}
//第3个子进程
if(i==2){
printf("this is [%d]th child,PID==[%d]\n",i+1,getpid());
}
//父进程
if(i==3){
printf("this is father,PID==[%d]\n",getpid());
}
return 0;
}
result2:
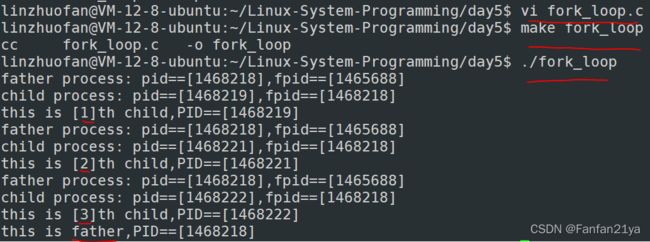
此时,我们创建出来的就都是兄弟进程了,它们互为兄弟进程,互相独立!好~
案例2:写出测试程序,判断父子进程中的全局变量是否为同一个(也即父子进程是否共享同一个全局变量)。

答:不能!
正确且全面地,应该说:父子进程之间在进行
写操作时不能共享同一全局变量!此时if是父进程do写操作,则是额外在物理内存上开辟一块内存,把写入后全局变量的值写进去,最后再映射回父进程的虚拟地址空间上g_var的值上!让g_var的值发生改变!if是子进程do写操作,则也是额外在物理内存上开辟另一块内存,把写入后全局变量的值写进去,最后再映射回子进程的虚拟地址空间上g_var的值上!让g_var的值发生改变!
但进行读操作时,可以共享同一全局变量!此时不论是父还是子进程,它们读取g_var时,都是拿的同一块物理内存上的值!
简记为:对于同一全局变量,父子进程,写时复制(copy这个全局变量),读时共享(这个全局变量)。
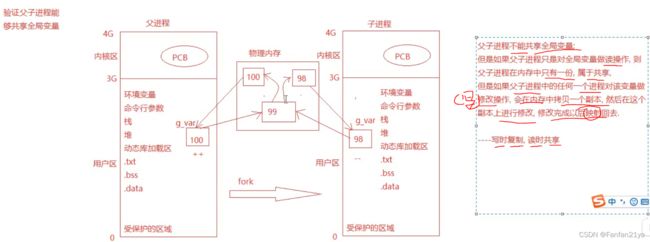
test codes:
//fork函数测试代码,测试父子进程是否共享同一个全局变量
#include
#include
#include
#include
#include
//定义一个 全局变量
int global_var = 99;
int main()
{
//创建子进程函数原型:
//pid_t fork(void);
pid_t pid = fork();
if(pid < 0)//fork失败的case
{
perror("fork error!");
return -1;
}
else if(pid == 0)//pid == 0 时,则当前进程为子进程
{
sleep(1);//为了避免父进程还没执行呢,子进程就执行完成了的case!
//if子进程抢到CPU的时间片先执行了,就让其休眠1s
//确保执行顺序是:父进程执行完成后,再执行子进程
printf("child process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
printf("child process's global_var==[%d]\n",global_var);
}
else//pid > 0 时,则当前进程为父进程
{
//pid_t getpid(void);
//这个函数会返回调用该函数的进程的ID
//(哪个进程调用它,它就返回谁的PID)
printf("father process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
global_var++;
printf("father process's global_var==[%d]\n",global_var);
//或者让父进程执行后先休眠2s,这样子也可以达到父进程优先执行到效果
}
return 0;
} result:
子进程先sleep 可以达到让父进程等子进程执行完成的效果!

or
父进程后sleep 可以达到让父进程等子进程执行完成的效果!
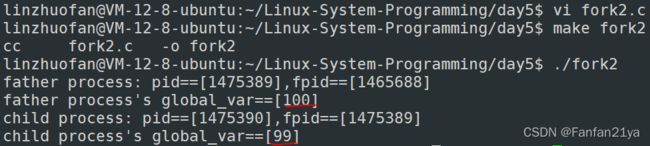
从结果我们可以看出来,虽然父进程对全局变量global_var进行++读写入操作,但是子进程的global_var并没有发生变化,也就是说父子进程之间do写操作时不能共享同一全局变量!√
if只是读操作,则可以共享同一全局变量! (把上述的global_var++;的代码注释掉!)

注意:父子进程的全局变量的虚拟地址空间是一样的!
在上述的test codes中的每个if语句后加入代码:
printf("child process's global_var==[%d],&global_var==[%d]\n",global_var,&global_var);
result:

下面学习ps命令和kill命令:
ps命令:是指,查看进程相关信息的命令。
最常用的ps命令是:
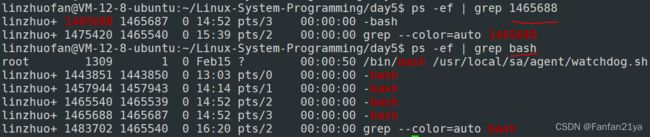
ps -ef | grep pid
这个命令就是用来找进程id==pid的某个进程的!这是 very 常用的!
ps aux | grep "xxx"
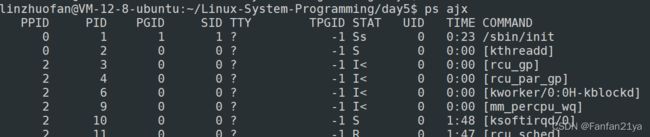
ps ajx | grep "xxx"
-a:(all)当前系统所有用户的进程
-u:查看进程所有者及其他一些信息
-x:显示没有控制终端的进程(所谓的没有控制终端的进程,即:不能与用户进行交互(输入/输出)的进程)
-j:列出与作业控制相关的信息
-A:显示所有进程
-e:等于“-A”
-f:表达程序间的相互关系
ps -ef //显示所有进程信息,连同命令行
kill命令:是指,杀死(终止)某进程的命令。
kill -l 查看系统有哪些信号
kill -9 pid 杀死进程id==pid的某个进程例子:
ps aux:(== ps -aux,不写-也OK)
(带?问号的就是没有控制终端的进程,不能与用户进行交互输入/输出)
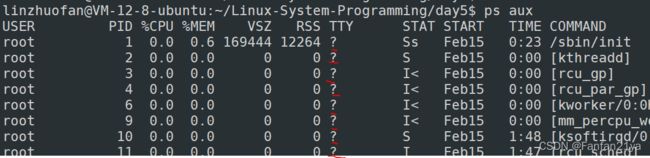
补充: 一些英文缩写符号的意思是:



ps ajx:(== ps -ajx,不写-也OK)ajx就能看到更多的信息,比如PPID,表示的是这个进程的父进程id
ps -ef | grep bash:
kill -l(这是-小L即-l,不是-大ai即-I,虽然长得一样,但是得区分清楚!):

kill -9 pid: (在终端开一个sleep 350休眠350s的进程)
![]()
再输入 ps ajx命令来查看sleep 350这个进程的PID,然后就可以通过kill -9 pid来杀死对应PID的某个进程了!

![]()
下面我们将继续学习:
4 exec函数族:
4.1 函数作用和函数介绍
有的时候,我们需要在一个进程中,执行其他的命令或者是运行用户自定义的应用程序,此时就用到了exec函数族中的函数了。
使用方法一般都是在父进程里面调用fork函数创建子进程,然后再在子进程中调用exec函数。
注意:我们这里,只学习exec函数族中,用得最多的2个函数!学会这2个函数即可。万一后续你要用到另外一些函数的话,你大可以用man exec命令来查看对应的函数原型和用法,然后你就无师自通了!
①execl函数:int execl(path,"命令名称","命令对应的参数",NULL));

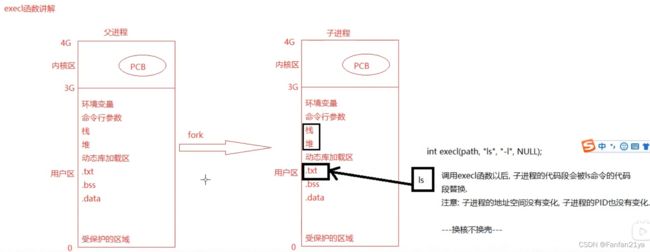
那么,什么时候这个函数会执行失败呢?答,最直观最简单的case就是:当你要拉起来的这个应用程序根本就不存在时,那肯定是执行失败的!
其次,这里的路径path其实也可以是相对路径,只要你写的路径能找到对应的应用程序or命令即可!
只要你想在一个进程内部,去执行linux系统的命令或者说应用程序的话,应优先想到如下方式:
先fork,然后再在子进程中用execl函数拉起一个可执行程序or命令
//codes:
pid = fork();
if(pid == 0)
{
execl(...);
}总结:
exec函数是用一个新程序替换了当前进程的代码段,数据段、堆和栈;原有的进程空间并没有发生变化,也并没有创建新的进程,且进程的PID也没有发生变化。
test codes:
//execl函数的测试代码,测试用execl函数拉起一个应用程序or命令
#include
#include
#include
#include
#include
int main()
{
//创建子进程函数原型:
//pid_t fork(void);
pid_t pid = fork();
if(pid < 0)//fork失败的case
{
perror("fork error!");
return -1;
}
else if(pid == 0)//pid == 0 时,则当前进程为子进程
{
printf("child process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
// linzhuofan@VM-12-8-ubuntu:~$ which ls
// /usr/bin/ls
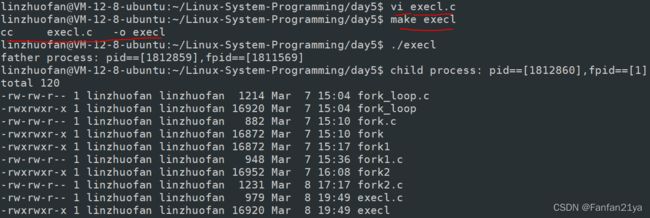
execl("/usr/bin/ls","ls","-ltr",NULL);
//if成功拉起这个ls命令的话,则execl函数后序的代码并不会给执行!
perror("execl error!\n");
}
else//pid > 0 时,则当前进程为父进程
{
//pid_t getpid(void);
//这个函数会返回调用该函数的进程的ID
//(哪个进程调用它,它就返回谁的PID)
printf("father process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
}
return 0;
} result:
test codes2:
//execl函数的测试代码,测试用execl函数拉起一个应用程序or命令
#include
#include
#include
#include
#include
int main()
{
//创建子进程函数原型:
//pid_t fork(void);
pid_t pid = fork();
if(pid < 0)//fork失败的case
{
perror("fork error!");
return -1;
}
else if(pid == 0)//pid == 0 时,则当前进程为子进程
{
printf("child process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
// linzhuofan@VM-12-8-ubuntu:~$ which ls
// /usr/bin/ls
//execl("/usr/bin/ls","ls","-ltr",NULL);
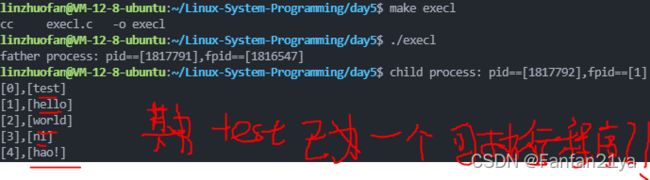
execl("./test","test","hello","world","ni","hao!",NULL);
//if成功拉起这个ls命令的话,则execl函数后序的代码并不会给执行!
perror("execl error!\n");
}
else//pid > 0 时,则当前进程为父进程
{
//pid_t getpid(void);
//这个函数会返回调用该函数的进程的ID
//(哪个进程调用它,它就返回谁的PID)
printf("father process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
}
return 0;
}
test.c:
#include
int main(int argc,char* argv[])
{
int i = 0;
for(i=0;i result2:
先do

后do
②execlp函数:int execl(const char* file,const char* arg,.../*(char *)NULL*/);
(命令名字/可执行程序名字,命令,命令的参数1,命令的参数2,....,NULL)


test codes:
//execlp函数的测试代码,测试用execlp函数拉起一个应用程序or命令
#include
#include
#include
#include
#include
int main()
{
//创建子进程函数原型:
//pid_t fork(void);
pid_t pid = fork();
if(pid < 0)//fork失败的case
{
perror("fork error!");
return -1;
}
else if(pid == 0)//pid == 0 时,则当前进程为子进程
{
printf("child process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
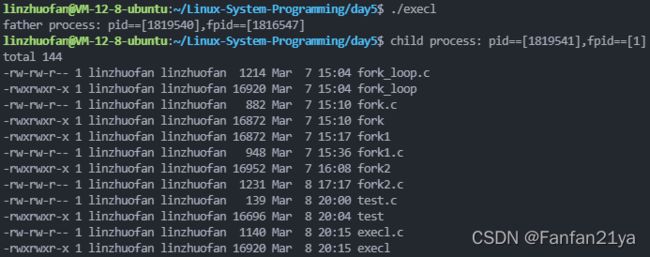
execlp("ls","ls","-ltr",NULL);
execlp("./test","test","hello","world","ni","hao!",NULL);
//if成功拉起这个ls命令的话,则execl函数后序的代码并不会给执行!
perror("execl error!\n");
}
else//pid > 0 时,则当前进程为父进程
{
//pid_t getpid(void);
//这个函数会返回调用该函数的进程的ID
//(哪个进程调用它,它就返回谁的PID)
printf("father process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
}
return 0;
} result:
test codes2:
//execlp函数的测试代码,测试用execlp函数拉起一个应用程序or命令
#include
#include
#include
#include
#include
int main()
{
//创建子进程函数原型:
//pid_t fork(void);
pid_t pid = fork();
if(pid < 0)//fork失败的case
{
perror("fork error!");
return -1;
}
else if(pid == 0)//pid == 0 时,则当前进程为子进程
{
printf("child process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
//execlp("ls","ls","-ltr",NULL);
execlp("./test","test","hello","world","ni","hao!",NULL);
//==> execlp("test","hello","world","ni","hao!",NULL);
//if成功拉起这个ls命令的话,则execl函数后序的代码并不会给执行!
perror("execl error!\n");
}
else//pid > 0 时,则当前进程为父进程
{
//pid_t getpid(void);
//这个函数会返回调用该函数的进程的ID
//(哪个进程调用它,它就返回谁的PID)
printf("father process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
}
return 0;
} result:

test codes3:
//execlp函数的测试代码,测试用execlp函数拉起一个应用程序or命令
#include
#include
#include
#include
#include
int main()
{
//创建子进程函数原型:
//pid_t fork(void);
pid_t pid = fork();
if(pid < 0)//fork失败的case
{
perror("fork error!");
return -1;
}
else if(pid == 0)//pid == 0 时,则当前进程为子进程
{
printf("child process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
execlp("test222","hello","world","ni","hao!",NULL);
//==> execlp("test222","hello","world","ni","hao!",NULL);
//注意:test222文件夹我并没有创建!这肯定会执行perror的!
//if成功拉起这个ls命令的话,则execl函数后序的代码并不会给执行!
perror("execl error!\n");
}
else//pid > 0 时,则当前进程为父进程
{
//pid_t getpid(void);
//这个函数会返回调用该函数的进程的ID
//(哪个进程调用它,它就返回谁的PID)
printf("father process: pid==[%d],fpid==[%d]\n",getpid(),getppid());
}
return 0;
} result3:
