MyBatis相关信息
文章目录
- 1.开发顺序
-
- 1.1准备工作
- 1.2两种配置文件
- 1.3主要的API
- 1.4api的使用
- 2.进一步操作(其他查询方法和增删改)
-
- 2.1查询(selectOne,selectMap)
- 2.2子查询
-
- 2.2.1association标签和collection标签的区别
- 2.2.2标签属性
- 2.2.3代码示例
- 2.2添加
- 2.3修改
- 2.4删除
- 3.mybatis中日志(监测sql语句)
- 4.多表查询
- 5.其他标记
-
- 5.1sql标签
- 5.2 selectKey标签
- 6.动态sql
-
- 6.1常用的动态sql标记
-
- 6.1.1演示,,,等标记
- 6.1.2演示,标记
- 6.1.3 标记
- 7.分页操作
-
- 7.1自己实现
- 7.2使用插件
- 8.缓存
-
- 8.1延迟加载
- 8.2一级缓存、二级缓存
- 9.基于接口方式访问
mybatis,首先需要jdbc的知识,了解过jdbc技术,发现jdbc有这样的不足:
- 增删改查数据库,都会经历,打开数据库,操作,关闭这3个环节,作为增删改查彼此不同的地方也就是操作数据库,相同的地方开和关都是一样的。频繁的开关数据库
- 查询的时候,从数据库返回的是行,而java中需要的是对象。势必我们有一个行转对象的过程。增加,更新的时候,java中是对象,而数据库中需要的是一列一列的信息(组成的行),势必会出现对象转成列的过程。行转对象,对象转列
1.开发顺序
1.1准备工作
jar包,加入到项目classpath中
一个mybatis.jar;一个mysql-connector-java.jar
1.2两种配置文件
一种是映射文件(mapper),一种是主配置文件(主要是数据库连接等信息,以及加载mapper文件)。
- mapper文件:主要是安放sql语句,并且给它一个逻辑名称。mybatis随后通过逻辑名称调用sql语句。
<mapper namespace="com.yunsi.pojo.User">
<select id="getUsers" resultType="com.yunsi.pojo.User">
select username,password from t_login
select>
mapper>
- 主配置文件:提供数据源,另外管理mapper文件
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">transactionManager>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/yunsi"/>
<property name="username" value="root"/>
<property name="password" value="test"/>
dataSource>
environment>
environments>
<mappers>
<mapper resource="com/yunsi/pojo/UserMapper.xml"/>
mappers>
1.3主要的API
- SqlSessionFactoryBuilder:主要读取(解析)主配置文件
- SqlSessionFactory:上面这个类解析主配置文件返回值
- SqlSession:是SqlSessionFactory这个工厂的“产品”。其实SqlSession可以理解成是Connection.
selectOne获取一个对象
selectList获取一堆对象(多行)
update
delete
insert
close
SqlSession的操作,虽说是底层是jdbc,可以它的所有方法不会报SQLException,而是把SQLException转换成了运行时异常。
1.4api的使用
public static void main(String[] args) {
//mybatis的api(操纵数据库)
//1.读取主配置文件(使用SqlSessionFactoryBuilder)
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
//2.返回读取的结果(SqlSessionFactory)
InputStream inputStream = Test1.class.getResourceAsStream("/mybatis-config.xml");
SqlSessionFactory factory = builder.build(inputStream);
//3.获取SqlSession对象(后续增删改查数据库都是通过它来完成的)
SqlSession session = factory.openSession();
List<User> usersList = session.selectList("getUsers");
for(User user : usersList) {
System.out.println(user.getUsername()+" "+user.getPassword());
}
//4.关闭资源(对比jdbc,就容易多了)
session.close();
}
2.进一步操作(其他查询方法和增删改)
2.1查询(selectOne,selectMap)

2.2子查询
查询数据库时,需要以查询结果为查询条件进行关联查询。
在mybatis中通过association标签和collection标签实现子查询。
2.2.1association标签和collection标签的区别
collection用于一对多关系,association用于一对一和多对一。
public class User{
private Card card_one; //一对一,映射时使用association
private List<Card> card_many; //一对多,映射时使用collection
}
2.2.2标签属性
- property:集合属性的名称
- ofType:集合中元素的类型
- select:子查询的ID
- column:传给子查询的参数
- JavaType:一般为ArrayList
<collection property="实体类属性名"
ofType="包名.实体类名"
column="{传入参数名1 = 对应的数据表名称, ...}"
select="子查询ID"
javaType="java.util.ArrayList" />
2.2.3代码示例
mybatis实现部门树结构查询,子查询使用和父查询一样的resultMap,递归查询子部门。
组织结构:
<resultMap id="departmentTreeMap" type="com.cdqd.app.entity.DepartmentEntity">
<id column="department_id" property="departmentId" jdbcType="INTEGER" />
<result column="department_name" property="departmentName" jdbcType="VARCHAR" />
<collection property="children"
ofType="com.cdqd.app.entity.DepartmentEntity"
column="{departmentId = department_id}"
select="selectWithLeader"
javaType="java.util.ArrayList" />
</resultMap>
第一级部门:
<select id="selectWithChildren" resultMap="departmentTreeMap" parameterType="java.util.HashMap">
select
d.*,
u.nick_name,
u.user_name,
u.user_tel
from department d
left join user_info u on d.leader_id = u.user_id
<where>
d.department_status != 2
<!--department_level = 0时为公司,不显示,从公司直属部门开始查询-->
<if test="startDepartmentId == null">
and d.department_level = 1
</if>
<if test="startDepartmentId != null">
and d.department_id = #{startDepartmentId, jdbcType = INTEGER}
</if>
</where>
</select>
子部门查询:
<select id="selectWithLeader" resultMap="departmentTreeMap">
select
d.*,
u.nick_name,
u.user_name,
u.user_tel
from department d
left join user_info u on d.leader_id = u.user_id
<where>
d.department_status != 2
<if test="departmentId != null">
and d.parent_id = #{departmentId}
</if>
</where>
</select>
2.2添加
<insert id=”saveUser” parameterType=”com.yunsi.pojo.User”>
insert into t_login(username,password)
values(#{username},#{pass})
insert>
2.3修改
<update id="updateUser">
update t_login set password=#{pass} where username=#{username}
update>
2.4删除
<delete id="deleteUser">
delete from t_login where username=#{username}
delete>
3.mybatis中日志(监测sql语句)
mybatis中使用了日志框架(log4j)记录了内部执行的状况(步骤),我们只需要“打开”日志开关就可以。
对于log4j的配置,主要有2个步骤:
- 第一步就是加入log4j的jar包(就一个)
- 第二步在classpath(src目录)中添加log4j.properties文件(必须这个名称),里面配置相关的信息(配置大致有2块,一块是日志级别{off>fatal>error>warn>info>debug>trace},还有一块就是日志的输出目的地、格式等配置,具体参照官网资料或者log4j常用配置)
4.多表查询
数据库中标语表之间的关系,可以分成如下3种,多对一(一对多),多对多,一对一这三种。
那么mybatis对于这个问题,它是如何处理的?把数据库中的关系转成java对象之间的关系,就是一个类型中定义另一个类型的属性,至于这个属性是单个对象还是多个对象的问题。
后面的例子使用一套多对一来演示。表就是用学生表和班级表。
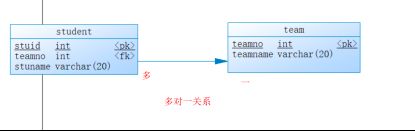

java中组织关系-就是通过属性
对多的一方中标记中的子标记
一的一方中标记中的子标记
5.其他标记
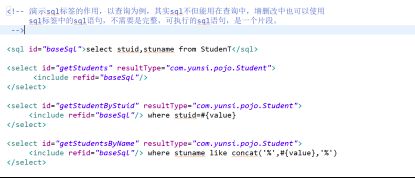
5.1sql标签
它是标记中的子标记,它的作用就是类似java中的变量,可以被多次使用。例子:查询所有学生,还有一个查询按照主键列(学号)查询某个学生。大家在编写sql语句的时候,可以看到sql几乎差不多,不同的地方就是where子句。
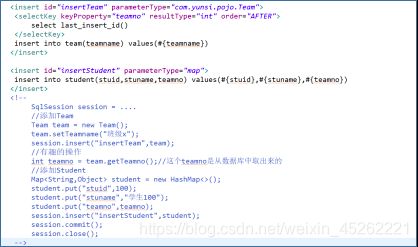
5.2 selectKey标签
我们之前使用过标记,它的作用就是添加一条记录,返回一个int型数据(表示添加的行数)。
假设:班级表(主键列是自增长的),学生表外检(班级编号)引用班级表主键列。业务需求是这样,添加班级这一瞬间,随后添加一位同学。添加同学的时候,如何处理学生表中的这个外键列的值(班级编号)。
6.动态sql
mybatis另一个强大的功能就是动态sql(继获取关联对象之后有一个重要的技术),所谓的动态sql就是sql语句中某些部分是可变的,例如where子句中的信息。
6.1常用的动态sql标记

6.1.1演示,,,等标记

6.1.2演示,标记
标记的使用,上一个例子中的分支判断的使用,里面有一个小问题,就是重复编写where关键字
其实可以使用标记消除上面片段中的where关键字。
消除之后的结果如下:
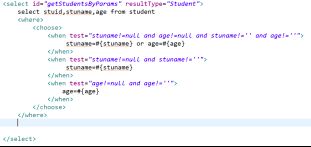
之前使用可以看出还有一个不足,就是分支有多余现象,请同学改进一下,改进的过程中会碰到where 后面跟随者or关键字这种情形,其实这个问题的出现,正好体现出标记的另一个价值,它可以检测where之后是否有多余的or或者and关键字,一旦有,就会替我们删除它们。

标签使用在update语句中,它的一个基本作用就是变成set关键字(这一点与标签变成where关键字一样),看下面示例:
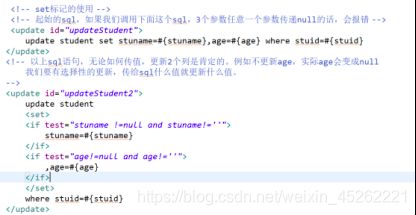
演示之后得出结论:有2个功能,一个会生成set关键字,另一个功能,会根据后面逗号是否多余,而进行删除。
6.1.3 标记
这个标记的作用,就是循环拼接sql片段。什么情况下会用到循环拼接sql片段?
例子:当我们执行删除的时候,语句会这样写
delete from student where stuid=#{value}
以上这个语句满足删除任意一个学生的需求,可以如果有这样的需求该如何?
一次性删除大量的学生,如果还是上面的sql语句,那么java代码会如下这样:
@Test
public void test(){
SqlSession session = ...
String[] stuids = {“1”,”2”,”3”.....};
for(String stuid : stuids){
session.delete(“deleteStudentByStuid”,stuid);
}
session.commit();
session.close();
}
以上的做法正确没问题,可是性能不好。了解有这样的sql之后,应该知道如何改进。
delete from student where stuid in(1,2,3,4,…)
标记往大了说,在完成批量操作(批量删除,批量添加)上面还可以贡献一份力
批量操作:SqlSessionFactory
SqlSession openSession(ExecutorType)
ExecutorType:
- SIMPLE:默认行为,直接构造PreparedStatement,每构造一个,发送一条sql。
- REUSE:共享PreparedStatement,有多条语句,只会构造一个它。
- BATCH:在REUSE的基础上,利用jdbc中batch操作
7.分页操作
分页操作,在web开发过程中,还是挺常用的,而在jdbc访问数据库的时候,分页操作,大致有2种方式,一种在内存中分页,还有一种直接查询当前页需要的数据(数据库内部分页),对于前一种方式,停留在理论阶段(学习)都是可以,生产中不能采取这种分页方式(生产中表中数据很多,一旦全部抓取到内存中,内存会奔溃),通常都是采取后一种方式,而采取后一种方式(精髓)就是能定位多少行到多少行记录,对于这个要求,不同的数据库采取的方式是不一样的,例如:mysql中使用关键字limit,oracle中采用2层子查询嵌套的方式搭配rownum(伪列)
7.1自己实现
其实就是针对不同的数据库,在mapper文件中编写相对应的sql语句。不过除了分页的sql语句之外,我们还需要一个辅助的sql,这条语句专门负责查询表中行的数量,以便计算分页中需要用到的信息。
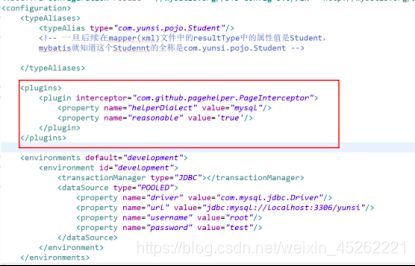
7.2使用插件
pagehelper
使用步骤:
- 导入jar包(2个jar,pagehelper,jsqlparser)
- mybatis主配置文件中配置plugin(插件),pagehelper提供的一个拦截器。
- 在正常查询之前(java代码中),使用pagehelper中的关于分页的api。在查询数据之前调用:PageHelper.startPage(当前页码,每页记录数)


8.缓存
缓存这个技术,就是可以减少查询次数,把查询出来的信息暂时存储在内存(或者磁盘),等待下一次查询的时候,我们可以从缓存中获取,从而避免再次从数据库中查询。(减少数据库访问次数)
缓存积极的一面就是提高查询效率(有些时候,并没有查询数据库,而是从缓存中获取数据),不足的一面,就是缓存中的数据可能是过期的。
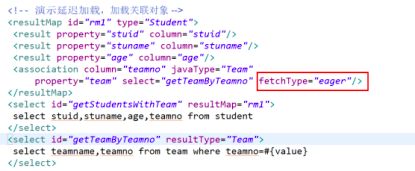
8.1延迟加载
延迟加载,当查询的时候,涉及到关联对象(多对一,一对一)一的一端,先前我们随着查询基本信息的发生,一也会被查询出来(单独一个查询),(多对多)多的一端,我们查询基本信息的时候,多的一端也会发送sql查询。
配置方式:
- 进行全局配置(lazyLoadingEnabled=true),一旦设置对整个mybatis管理的mapper文件中的sql语句但凡涉及到关联对象(association,collection),都会使用延迟加载。
- 通过在某个mapper文件中中的**fetchType=“lazy”**属性覆盖全局的设置。

8.2一级缓存、二级缓存
mybatis有一级缓存和二级缓存区分,默认一级缓存是开启的,二级缓存是关闭(可以通过手动开启)。
这边所说的一级缓存,其实就是SqlSession,原来一级缓存就在SqlSession内部。
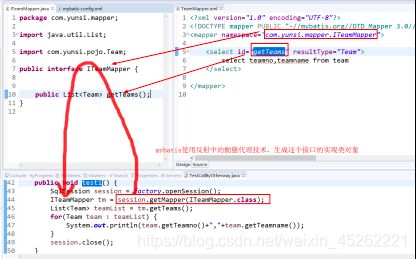
9.基于接口方式访问
原来我们使用mybatis是这样:session.update(“updateStudent”,stu); session.selectList(“getStudents”)
以上这样的访问方式由一个问题,就是java程序在编译的时候,并不能对立面的sql逻辑名称做有效的检查。(万一手误大小写打错了或者漏打了,都会导致运行的时候出现错误)
mybatis在这个问题上,又提供了一个有效的解决方法,原理:它把所有的sql逻辑名称全部映射到java中的一个接口中的方法名称上面,以至于我们实际调用的时候,都是针对接口中的方法进行编程,这样一来,就避免了名称敲错了,漏写了等情形。
具体做法:
- 在原先的mapper(xml)文件中,根元素以前推荐大家使用所操作的类的全名作为namespace属性值。例如:. 既然准备使用基于接口访问的方式,把namespace属性值改成一个接口的全称。
- 为mapper文件中的所有sql逻辑名称定义一套接口,并且接口中方法的名称与mapper文件中sql的逻辑名称一致(字符串equals为true)
- 就废弃了类似这样的api调用,session.update(“…”,param),session.selectOne(“…”,param);
使用 T session.getMapper(Class 接口的Class)